


1. はじめに
SOCで検知ルールを構築する際、"端末のタイプごとに検知ルールを設定したい"、"端末の通常と違うアクティビティを検知したい"という課題に直面することがあります。
端末が正常ではないことをどのように判定するかが重要になりますが、どのような端末がどのような通信を行うのが正常といえるのかは端末を操作する当人の所属する会社・部門や当人の職位・勤務形態など様々な要素が影響するため、通常のルールベースでは難しい課題といえます。
今回はそのような課題を解決するための一歩となる、マシンラーニングの手法であるクラスタリングによる端末分類について紹介します。
2. 特徴選択
マシンラーニングで分類や予測を行う際、その対象を表す数値化されたデータが必要になります。これを特徴量と呼びます。まずは何を特徴として使用すべきかを選定していきます。
端末の特徴はSIEMで収集されるログから集計可能な下記のようなものが候補となります。
- 通信回数
- 通信データ量
- 通信発生時間(通信開始~通信終了時間)
- 通信ポート数(ユニーク数)
- ログオン回数
各特徴を均衡させるため標準化すると、端末は下記のように表現することができます。
| 通信回数 | 通信データ量 | 通信発生時間 | 通信ポート数 | ログオン回数 | |
|---|---|---|---|---|---|
| 端末A | -0.582 | 0.797 | -1.063 | -0.533 | 1.177 |
| 端末B | -0.575 | -0.936 | -0.935 | -0.415 | 0.784 |
| 端末C | 1.732 | 1.183 | 0.999 | 1.718 | -0.784 |
| 端末D | -0.576 | -1.044 | 0.999 | -0.770 | -1.177 |
今回はクラスタリングした際の可視性を重視して2次元の特徴平面上に端末をプロットしようと思います。そのため、これらの特徴から2種を選択します。
特徴選択には様々な手法があります。教師あり学習では目的変数への重要度を計算したりしますが、クラスタリングのような教師なし学習には目的変数がないため別の手法が必要となります。一般に特徴同士の相関性が低いほうが特徴種類数あたりの表現力が高くなることに着目し、今回は特徴同士の相関係数から特徴を2種選択します。(もっと本格的な特徴の生成や選択手法は別の回で行います。)
各特徴同士の相関係数を計算すると下記の通りとなりました。
| 通信回数 | 通信データ量 | 通信発生時間 | 通信ポート数 | ログオン回数 | |
|---|---|---|---|---|---|
| 通信回数 | 1.000 | 0.683 | 0.577 | 0.993 | -0.600 |
| 通信データ量 | 0.683 | 1.000 | 0.069 | 0.726 | -0.092 |
| 通信発生時間 | 0.577 | 0.069 | 1.000 | 0.474 | -1.000 |
| 通信ポート数 | 0.993 | 0.726 | 0.474 | 1.000 | -0.499 |
| ログオン回数 | -0.600 | -0.092 | -1.000 | -0.499 | 1.000 |
表から今回の特徴候補のうち相関性が低い特徴は通信データ量と通信時間と言えます。言い換えると端末の通信データ量は端末の通信時間とほとんど関係ないということになります。逆に、負の相関性が高いログオン回数と通信発生回数の間にはログオン回数が少ないほど通信発生回数は多いということを意味します。(業務端末以外のログオン操作を行わない常時起動されている機器が想定されます)
今回は相関性が低い通信データ量と通信時間の2種類の特徴量で端末をクラスタリングすることにします。
特徴量で端末をプロットすると下記の通りとなりました。
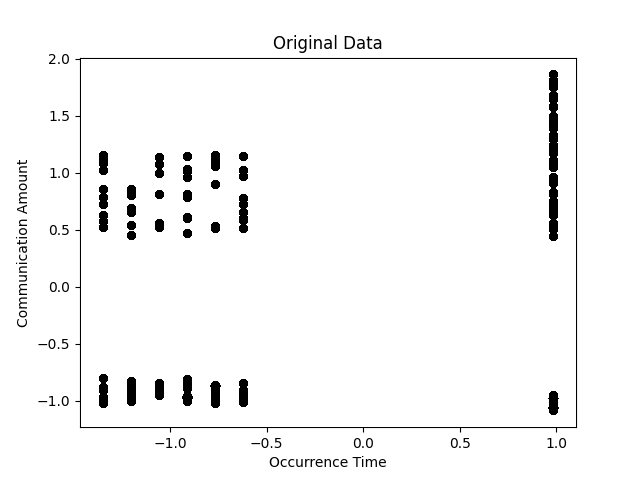
通信データ量と通信時間による各端末のプロット
3. クラスタリング
選択した特徴量でプロットした端末をクラスタリングによって分類します。
クラスタリング結果は下記の通りになりました。
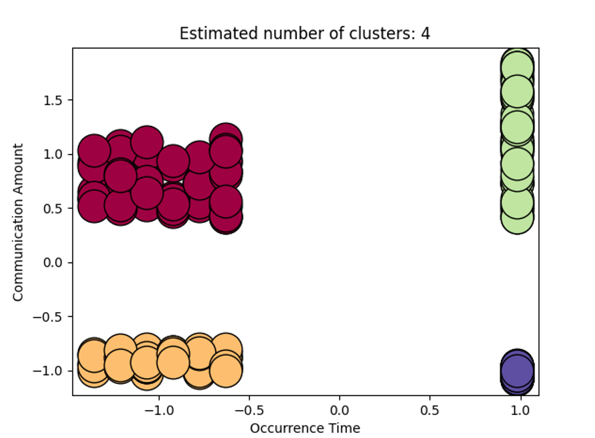
DBSCANによるクラスタリング結果
この結果を解釈すると各端末は下記のように分類されたと推測できます。

クラスタリング結果の解釈
4. まとめ
今回はログから端末のタイプをクラスタリングによって分類する手法について紹介しました。
端末をクラスタリングすることでクラスターごとに検知ルールを作成したり、端末のクラスターが変化した場合に不審アクティビティとするなど応用的な活用を行うことができます。
今回の特徴選択では感覚的・視覚的に理解しやすいように人間にとってわかりやすい特徴を2種選択しましたが、PCAなどの手法を用いて多数の特徴から生成した複雑な特徴を組み合わせる方が精度は良いです。一方で、人間にとってわかりやすい特徴を用いたほうが検知についてSOCアナリストが分析しやすいというメリットもあります。SOCの検知ルールでのAI活用はこのようなことを総合的に考えていく必要があります。

アクセンチュア株式会社所属の社員有志による運営です。アクセンチュアの社員による様々な発信をまとめています。なお、投稿内容は社員個人の見解であり、所属する組織を代表するものではありません。
Discussion