1. はじめに
日本時間2025年8月6日未明にOpenAIからgpt-ossが発表されました。gpt-ossは、gpt-oss-120b(1170億パラメータ)とgpt-oss-20b(210億パラメータ)の2つのモデルが発表されました。 120bはo4-mini相当、20bはo3-mini相当と言われています。 この辺の性能は、Introducing gpt-ossに詳しく記載されているのでぜひご参照ください。
2. 実際の精度
実際に試してみましょう。
下記プロンプトでgpt-oss-120b、gpt-oss-20bそれぞれに聞いてみます。
Rdbmsで管理しているチケットのステータスのトランザクション情報を活用したい。自然言語によるデータ検索や、傾向分析はどのような方法で実現できそう?
結果は、下記でした。
かなりの精度、、、すごいですね!
gpt-oss-120bの出力結果
1. 全体像 ― 何をしたいか、どんな課題があるか
| 目的 | 具体的にやりたいこと |
|---|---|
| 自然言語検索 | 「過去1週間でステータスが Open → In‑Progress に遷移したチケットは?」「“支払いエラー” を含むクローズ済みチケットの一覧」など、ユーザーが日本語で質問できるようにしたい。 |
| 傾向分析 | ステータス遷移頻度の時系列推移、平均解決時間の変化、遅延が多いステータス遷移パターンなどを可視化/予測したい。 |
| 前提 | チケット情報は RDBMS(例:PostgreSQL / MySQL / Oracle)に格納され、ステータス遷移ログ(トランザクション情報)を別テーブルで管理している。 |
この 2 つの要件は、(1)データの整形・集計 と (2)自然言語 → SQL/ベクトル検索 の橋渡しがキーになります。以下では、実装フローと具体的な技術・コード例を示します。
2. データモデルの整理 ― トランザクション情報を分析しやすくする
-- チケットマスタ
CREATE TABLE tickets (
ticket_id BIGINT PRIMARY KEY,
title TEXT,
description TEXT,
created_at TIMESTAMP,
created_by VARCHAR(64)
);
-- ステータス遷移履歴 (トランザクションテーブル)
CREATE TABLE ticket_status_history (
history_id BIGINT PRIMARY KEY,
ticket_id BIGINT REFERENCES tickets(ticket_id),
from_status VARCHAR(32), -- NULL の場合は「作成時」(NULL → Open)
to_status VARCHAR(32) NOT NULL,
changed_at TIMESTAMP NOT NULL,
changed_by VARCHAR(64) NOT NULL,
comment TEXT
);
分析しやすくするための追加テーブル/ビュー
| 用途 | 例 |
|---|---|
| 集計ビュー |
daily_status_counts – 1 日ごとのステータス別チケット数 |
| マテリアライズド・ビュー |
ticket_latest_status – 現在のステータス(高速検索用) |
| ウィンドウ関数 | 各チケットのステータス遷移間の時間差 (lead/lag) を計算した列 |
| ETL/ELT | 定期的に ticket_status_history から「滞在時間」「遅延回数」などを算出し、分析用 DW にコピー |
-- 例: チケットごとの最新ステータスを取得するマテリアライズドビュー
CREATE MATERIALIZED VIEW ticket_latest_status AS
SELECT h.ticket_id,
first_value(h.to_status) OVER (PARTITION BY h.ticket_id ORDER BY h.changed_at DESC) AS latest_status,
max(h.changed_at) OVER (PARTITION BY h.ticket_id) AS latest_at
FROM ticket_status_history h;
3. 自然言語検索(NL → SQL)を実装するパターン
3‑1. LLM(大言語モデル)で NL → SQL 変換
| メリット | デメリット |
|---|---|
| ・日本語を含む自然な質問がそのまま SQL に変換できる ・汎用的で拡張が楽 |
・LLM の出力を SQL インジェクション から守る必要がある ・生成される SQL の正確性を検証する工程が必須 |
主なツール・ライブラリ
| ツール | 主な特徴 |
|---|---|
| OpenAI GPT‑4 / ChatGPT | 高精度な NL→SQL 変換。プロンプト設計次第で日本語対応も可能。 |
| Google Gemini | 日本語に強い。API 経由での利用が可能。 |
| LangChain | LLM 呼び出し、プロンプトテンプレート、SQL データベースチェーンを簡単に構築できる Python ライブラリ。 |
| LlamaIndex (GPT Index) | ドキュメントインデックスと LLM を統合し、質問とデータベースへのクエリを自動マッピング。 |
Fine‑tuned Text‑to‑SQL モデル (e.g., SQLova, T5‑SQL, UnifiedSKG) |
オープンソースで自前のモデルを走らせられる。 |
実装例(Python + LangChain + OpenAI)
# pip install langchain openai psycopg2-binary
import os
from langchain import OpenAI, SQLDatabase, SQLDatabaseChain
# 1) 環境変数に OpenAI API キー
os.environ["OPENAI_API_KEY"] = "sk-..."
# 2) データベース接続情報
db = SQLDatabase.from_uri(
"postgresql+psycopg2://user:pwd@host:5432/ticket_db"
)
# 3) LLM(GPT‑4)設定
llm = OpenAI(temperature=0, model_name="gpt-4") # 低温度で「決定的」な出力
# 4) NL → SQL チェーンの構築
db_chain = SQLDatabaseChain.from_llm(
llm,
db,
verbose=True,
# 例示的な「シラバス」プロンプト。テーブル構造を先に伝えると精度が上がります。
prompt=(
"以下のテーブル構造を考慮して、質問をSQLに変換してください。\n"
"テーブル: tickets(id, title, description, created_at, created_by)\n"
"テーブル: ticket_status_history(id, ticket_id, from_status, to_status, changed_at, changed_by, comment)\n"
"質問: {question}\n"
"SQL:"
)
)
# 5) 質問例
question = "過去1週間でステータスが Open → In-Progress に遷移したチケットの ID とタイトルを教えて"
result = db_chain.run(question)
print(result)
ポイント
-
promptでテーブル構造(スキーマ)を明示的に渡すと、LLM が生成する SQL が正確になります。 -
verbose=Trueにすると、LLM が生成した SQL 文がログに出力され、デバッグがしやすくなります。 - 取得した SQL を パラメータ化(
%sなど)して、SQLインジェクション対策を必ず行います。
3‑2. 生成された SQL の安全性検証
-
正規表現チェック –
SELECT,INSERT,UPDATE,DELETEのみ許可し、DROP,ALTERなどは禁止。 -
クエリプランの取得 –
EXPLAINで実行計画を取得し、意図しないフルテーブルスキャンが起きていないかチェック。 -
ロールベース制御 – ユーザーごとに実行できるテーブル・カラムを制限(PostgreSQL の
ROW LEVEL SECURITYなど)
def safe_execute(sql: str, db):
# 禁止文字列チェック
forbidden = ["DROP", "ALTER", "TRUNCATE", "CREATE"]
if any(word in sql.upper() for word in forbidden):
raise ValueError("Forbidden SQL detected")
# パラメータ化されたクエリに変換 (例:psycopg2 の execute)
with db._engine.connect() as conn:
result = conn.execute(sql) # 本番では `conn.execute(text(sql))` とする
return result
3‑3. Embedding+ベクトル検索で「意味的」な検索
NL → SQL が 完全に特定の構造(例:集計)を求める場合は有効ですが、「支払いエラーが起きたチケットを探したい」 のように自由テキスト検索が主眼になるケースはベクトル検索が適しています。
構成例
| コンポーネント | 役割 |
|---|---|
Embeddingモデル(OpenAI text-embedding-ada-002、Sentence‑BERT、日本語に特化した cl-tohoku/bert-base-japanese) |
チケットの title・description・comment をベクトル化 |
| ベクトルDB(Pinecone、Milvus、Weaviate、pgvector) | ベクトルインデックス+フィルタ(status, changed_at など) |
| RDBMS(PostgreSQL) | 正規化データ・トランザクション履歴の保持、集計 |
| API層(FastAPI) | NL クエリ → Embedding → ベクトル検索 + RDB フィルタ → 結果返却 |
実装例(Python + pgvector + OpenAI embeddings)
# pip install psycopg2-binary openai pgvector fastapi uvicorn
import os, openai, psycopg2
from pgvector.psycopg import register_vector
from fastapi import FastAPI, Query
os.environ["OPENAI_API_KEY"] = "sk-..."
# DB 接続
conn = psycopg2.connect("dbname=ticket_db user=pguser password=pgpwd host=localhost")
register_vector(conn)
# ベクトル列を持つテーブル(例: ticket_embeddings)
# CREATE TABLE ticket_embeddings (
# ticket_id BIGINT PRIMARY KEY,
# embedding vector(1536) -- OpenAI ada 1536-dim
# );
def get_embedding(text: str):
resp = openai.Embedding.create(model="text-embedding-ada-002", input=text)
return resp["data"][0]["embedding"]
app = FastAPI()
@app.get("/search")
def semantic_search(q: str = Query(...), top_k: int = 5):
emb = get_embedding(q)
cur = conn.cursor()
cur.execute("""
SELECT t.ticket_id, t.title, t.description,
1 - (e.embedding <=> %s) AS cosine_similarity
FROM tickets t
JOIN ticket_embeddings e ON t.ticket_id = e.ticket_id
ORDER BY cosine_similarity DESC
LIMIT %s
""", (emb, top_k))
rows = cur.fetchall()
return [{"ticket_id": r[0], "title": r[1], "desc": r[2], "score": r[3]}]
-
ベクトル検索はコサイン類似度 (
<=>) で高速に計算できます(pgvector がサポート)。 -
RDB のフィルタ(例:
WHERE e.changed_at >= now() - interval '7 days' AND e.to_status = 'In-Progress')は通常の SQL 条件として追加可能。
4. 傾向分析(Trend Analysis)を実装する流れ
4‑1. 必要な指標(KPI)例
| 指標 | 計算例 | 用途 |
|---|---|---|
| ステータス遷移件数(日次) |
COUNT(*) を changed_at::date と to_status で集計 |
時系列トラフィック把握 |
| 平均滞在時間 | AVG(lead(changed_at) OVER (PARTITION BY ticket_id ORDER BY changed_at) - changed_at) |
ボトルネック発見 |
| 遅延率 | COUNT(*) FILTER (WHERE to_status='Closed' AND (changed_at - created_at) > interval '7 days') / COUNT(*) |
SLA 達成度 |
| 遷移パターン頻度 | COUNT(*) GROUP BY from_status, to_status |
主要トランジションの可視化 |
| 予測 | 時系列モデル(Prophet / ARIMA / LSTM)で次月の Open 件数を予測 | リソース計画 |
4‑2. データウェアハウス(DW)を活用した分析基盤
-
ETL(Airflow、Prefect、dbt)で
ticket_status_history→analyticsスキーマへコピー。 - マテリアライズドビューで日次・週次集計テーブルを作成(SQL のみでロジックが完結)。
- BI ツール(Metabase、Superset、Power BI、Tableau)と連携し、自然言語クエリ機能を活用(例:Metabase の「Ask a Question」機能)。
ポイント:分析用テーブルは インデックスと パーティショニング(date 列で)を施すと、数十万件規模でも瞬時に集計できます。
例: 日次ステータス件数のマテリアライズドビュー
CREATE MATERIALIZED VIEW daily_status_counts AS
SELECT
DATE(changed_at) AS day,
to_status,
COUNT(*) AS cnt
FROM ticket_status_history
GROUP BY DATE(changed_at), to_status
WITH DATA;
-- 毎日自動リフレッシュ(PostgreSQL の cron + pg_cron)
SELECT cron.schedule('0 2 * * *', $$REFRESH MATERIALIZED VIEW CONCURRENTLY daily_status_counts$$);
4‑3. 時系列予測の実装例(Python + Prophet)
# pip install prophet pandas psycopg2-binary
import pandas as pd
from prophet import Prophet
import psycopg2
conn = psycopg2.connect("dbname=ticket_db user=pguser password=pgpwd host=localhost")
sql = """
SELECT day::date AS ds, cnt AS y
FROM daily_status_counts
WHERE to_status = 'Open'
ORDER BY ds;
"""
df = pd.read_sql(sql, conn)
m = Prophet(yearly_seasonality=False, weekly_seasonality=True, daily_seasonality=False)
m.fit(df)
future = m.make_future_dataframe(periods=30) # 30日先まで予測
forecast = m.predict(future)
# 結果を DataFrame で表示
print(forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].tail(10))
-
結果を可視化するだけでなく、予測値を DB に書き戻す(例:
forecast_open_ticketsテーブル)ことで、BI ダッシュボードで「予測」タブを追加できます。
4‑4. クラスタリングで「遅延パターン」を抽出
-
特徴量設計
-
duration_open_to_inprogress,duration_inprogress_to_resolved,total_time_to_close,num_reopens,priority,category等。
-
-
スケーリング →
StandardScaler - K‑Means / DBSCAN でクラスタリング
- 可視化 → t‑SNE / UMAP + matplotlib
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import seaborn as sns
# 例: ticket_features テーブルに集計済み特徴量が入っていると仮定
df = pd.read_sql("SELECT * FROM ticket_features", conn)
features = df[['duration_open_to_inprogress',
'duration_inprogress_to_resolved',
'total_time_to_close',
'num_reopens']]
scaler = StandardScaler()
X = scaler.fit_transform(features)
kmeans = KMeans(n_clusters=4, random_state=42)
df['cluster'] = kmeans.fit_predict(X)
# 可視化(2Dに削減)
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
proj = pca.fit_transform(X)
plt.figure(figsize=(8,6))
sns.scatterplot(x=proj[:,0], y=proj[:,1], hue=df['cluster'], palette='Set2')
plt.title('Ticket Delay Patterns (KMeans)')
plt.show()
-
結果の活用例:
cluster=2が「長期遅延かつ再オープン頻度高」パターンと判明したら、担当チームへアラートを自動送信。
5. エンドツーエンドのアーキテクチャ例
┌───────────────────────┐
│ ユーザー(Web / Slack)│
└───────┬───────────────┘
│ (自然言語クエリ)
▼
┌───────────────────────┐ ┌─────────────────────┐
│ API Gateway (FastAPI)│──►│ LLM (OpenAI/Gemini)│
│ - NL→SQL 変換 │ │ - Prompt: テーブル構造│
│ - Embedding 呼び出し │ │ - 出力: SQL/ベクトル │
└───────┬───────────────┘ └───────┬─────────────┘
│ │
│ (SQL or ベクトル検索) │
▼ ▼
┌───────────────────────┐ ┌─────────────────────┐
│ RDBMS (PostgreSQL) │ │ Vector DB (pgvector│
│ - 事実データ・集計 │ │ / Milvus) │
└───────┬───────────────┘ └───────┬─────────────┘
│ │
│ (集計結果/検索結果) │
▼ ▼
┌───────────────────────┐ ┌─────────────────────┐
│ データウェアハウス │ │ BI / ダッシュボード │
│ (Snowflake/BigQuery)│ │ (Metabase, Superset)│
│ - 時系列予測・集計 │ │ - NLクエリ機能 │
└───────────────────────┘ └─────────────────────┘
-
バッチ ETL(Airflow)で
ticket_status_history→DWとVectorDBの両方へデータをコピー。 -
リアルタイム(Kafka → Flink)でステータス遷移が起きたら即座にベクトル埋め込みを生成し
VectorDBに追加。 - 認証・認可は API Gateway で JWT/OAuth2 によりユーザーごとにアクセス権を制御。
6. セキュリティ・ガバナンスのベストプラクティス
| 項目 | 推奨策 |
|---|---|
| SQLインジェクション防止 | 生成された SQL は必ず プレースホルダー(%s / :param)で実行し、ホワイトリスト化したテーブル名・カラム名のみ許可。 |
| データマスキング | 個人情報(名前、メール)を含む列はビューでマスクし、LLM に渡す際は匿名化(***)したテキストを利用。 |
| 監査ログ |
api_gateway → query_log テーブルに ユーザーID、クエリ、実行時間、結果件数 を記録。 |
| LLM 出力検証 | LLM が生成した SQL が EXPLAIN できるか確認し、エラー時はユーザーに「質問が曖昧です」とリファインを促す。 |
| アクセス制御 |
pg_vector のインデックスは READ ONLY ロールに限定し、書き込みは ETL/Batch のみ。 |
| プライバシー | 埋め込み生成時に PII を除去(正規表現で電話番号・クレジットカード番号除去)してから OpenAI API に送信。 |
7. 具体的な実装ステップまとめ
-
スキーマの整理
-
ticket_status_historyにタイムスタンプ・ステータス遷移を正規化。 - 集計用マテリアライズドビュー/パーティションテーブルを作る。
-
-
ETL/ELT パイプライン構築
- Airflow DAG:
extract → transform (dbt) → load to DW & VectorDB。 - 必要なら Change Data Capture (CDC)(Debezium)でリアルタイムにベクトル化。
- Airflow DAG:
-
自然言語インタフェース
- LLM + LangChain で NL → SQL 変換エンドポイントを作る。
- Embedding + pgvector で意味検索 API を提供。
- プロンプトは「テーブル構造」「許可するステータス」「日付フィルタ」などを明示的に書く。
-
傾向分析基盤
- 日次・週次の集計ビューを作り、BI に接続。
- Prophet/ARIMA で時系列予測、K‑Means で遅延パターンクラスタリング。
- 予測結果やクラスタラベルを DW に保存し、ダッシュボードで可視化。
-
フロントエンド / UI
- Web UI(React/Vue)や Slack ボットで「/ticket 〇〇」と打つだけで結果が返る。
- BI ツールの「Ask a question」機能と連携し、非エンジニアでも自然言語で分析可能に。
-
テスト・デプロイ
- ユニットテスト:NL→SQL 変換ロジックの期待出力テスト。
- 統合テスト:LLM → DB → 結果の一貫性チェック。
- CI/CD(GitHub Actions / GitLab CI)でコンテナ化(Docker)した API と ETL ジョブを自動デプロイ。
-
運用・モニタリング
- Prometheus + Grafana で API レイテンシ、クエリ実行時間、ベクトル検索 QPS を監視。
- Alert:予測された Open 件数が閾値を超えたら自動的に Slack/メールで通知。
8. 参考リソース・学習リンク
| カテゴリ | リンク |
|---|---|
| LLM と NL→SQL | - OpenAI Cookbook: https://github.com/openai/openai-cookbook/blob/main/examples/SQL_Chatbot.ipynb - LangChain → SQLDatabaseChain ドキュメント |
| テキスト埋め込み | - OpenAI Embeddings API: https://platform.openai.com/docs/guides/embeddings - SBERT (Japanese) : https://github.com/cl-tohoku/bert-japanese |
| ベクトルDB | - pgvector: https://github.com/pgvector/pgvector - Milvus: https://milvus.io/ |
| 時系列予測 | - Prophet (Python) : https://facebook.github.io/prophet/docs/quick_start.html |
| ETL/BI | - dbt (Data Build Tool) : https://www.getdbt.com/ - Metabase NL query: https://www.metabase.com/docs/latest/questions/native |
| セキュリティ | - OWASP SQL Injection Prevention Cheat Sheet: https://cheatsheetseries.owasp.org/cheatsheets/SQL_Injection_Prevention_Cheat_Sheet.html |
9. まとめ
- 自然言語検索は「LLM に NL→SQL を生成させる」か「テキスト埋め込み+ベクトル検索」で実装でき、どちらも RDB のスキーマ情報を活かすことが重要です。
- 傾向分析は、ステータス履歴から 集計ビュー/マテリアライズドビュー を作り、DW と BI ツールで可視化・予測モデルに供給すれば実現できます。
- リアルタイム性が必要なら CDC + ベクトル埋め込みパイプラインを構築し、バッチは dbt+Airflow で安定運用すると効果的です。
- 安全性(SQLインジェクション防止・PII マスキング)は、LLM の出力を必ず検証し、データアクセスはロールベースで制限することでリスクを低減できます。
上記の構成・ツール・コード例をベースに、まずは 「NL→SQL API」 と 「ベクトル検索エンドポイント」 をプロトタイプとして作り、そこから ETL → DW → BI のパイプラインを拡張していくと、段階的に要件を満たす堅牢な分析基盤が構築できます。ぜひ実装を進めてみてください! 🚀
ご不明点や、特定の技術スタック(例:Oracle、MySQL、Snowflake)に合わせた実装例が必要な場合は遠慮なく質問してください。
gpt-oss-20bの出力結果
① 目的と前提
-
DB構造例
ticket_transactions ├── id (PK) ├── ticket_id (FK → tickets) ├── status (VARCHAR) -- e.g. "open", "in_progress", "resolved" … ├── updated_at (TIMESTAMP) ├── changed_by (VARCHAR) ├── comment_text (TEXT) -- 変更理由や備考 └── additional_meta (JSONB) -- カスタムメタ情報 -
期待する機能
-
自然言語検索 → 「昨日のステータスが
resolvedだったチケットを教えて」 - 傾向分析 → ステータス遷移頻度、平均解決時間、異常検知などを可視化
-
自然言語検索 → 「昨日のステータスが
-
利用可能技術
- RDBMS (PostgreSQL / MySQL / MSSQL)
- 拡張機能・サンドボックス (pgvector, PostgreSQL → ElasticSearch, Azure Cognitive Search)
- 生成系 LLM (OpenAI GPT, Azure OpenAI, Claude, LlamaIndex 等)
- データパイプライン (Airflow, dbt, Kafka)
- 分析/可視化 (Grafana, Metabase, Superset, Power BI)
以下では「① データ設計・パイプライン構築」「② 自然言語検索実装」「③ 傾向分析/可視化」という3軸で説明します。
② ① データ設計・パイプライン構築
| 目的 | アプローチ | 実装例 |
|---|---|---|
| 全ステータス遷移の履歴保存 | すべての変更をアプリレイヤーでトリガー付きテーブルに書き込む |
AFTER UPDATE トリガー、もしくはアプリ側で INSERT
|
| 検索用テキストカラム | テキスト検索は comment_text と additional_meta を統合 |
concat_ws(' ', comment_text, additional_meta::text) |
| ベクトル埋め込みの生成 | 生成済みテキストを埋め込みベクトル化 | Python ↔ SentenceTransformers → pgvector へのINSERT |
| 時系列管理 |
updated_at をインデックスに |
CREATE INDEX idx_ticket_time ON ticket_transactions(updated_at DESC); |
パイプライン例(Airflow + Python)
# dag.py
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime, timedelta
def embed_and_store(**context):
import psycopg2, pandas as pd, sentence_transformers
conn = psycopg2.connect(...)
df = pd.read_sql_query("""
SELECT id, concat_ws(' ', comment_text, additional_meta::text) AS ct
FROM ticket_transactions
WHERE updated_at > now() - interval '5 min';
""", conn)
model = sentence_transformers.SentenceTransformer('all-MiniLM-L6-v2')
df['vec'] = model.encode(df['ct'].tolist(), show_progress_bar=True, convert_to_numpy=True)
# pgvector へ bulk insert/update
cur = conn.cursor()
for _, row in df.iterrows():
cur.execute("""
UPDATE ticket_transactions SET embedding = %s WHERE id = %s;
""", (row['vec'].tobytes(), row['id']))
conn.commit()
cur.close()
conn.close()
dag = DAG(
'ticket_embeddings',
default_args={'owner': 'airflow', 'retries': 1},
schedule_interval=timedelta(minutes=5),
)
task = PythonOperator(
task_id='embed_step',
python_callable=embed_and_store,
dag=dag,
)
- 頻度:5min など短周期で実行し、検索は常に最新に。
-
スケール:大規模なら
Debezium+ Kafka で CDC を流し、Kafka Streams で埋め込み生成。
③ ② 自然言語検索実装
① Semantic Search(ベクトル検索)
-
インデックス
ALTER TABLE ticket_transactions ADD COLUMN embedding vector(384); CREATE INDEX idx_ticket_embedding ON ticket_transactions USING ivfflat(embedding vector_l2_ops) WITH (lists = 100); -
検索フロー
- ユーザーが入力
q = "昨日の resolved ステータスのチケット" -
前処理 →
tqdmで埋め込みquery_vec = model.encode([q])[0].tobytes() -
ベクトル検索
SELECT id, ticket_id, status, updated_at, comment_text FROM ticket_transactions ORDER BY embedding <#> query_vec ASC -- L2 distance LIMIT 10; - 近傍 10件をフロントエンドで表示
- ユーザーが入力
-
利点
- 形態素解析やキーワード一致に依存せず、意味相違に強い
-
embeddingカラムをpgvectorで管理すると Postgres 内部で高速
② LLM を用いた質問→SQLへの変換
| ステップ | 例 |
|---|---|
| 1 | ユーザー質問:「最近3日間で解決したチケット数は?」 |
| 2 | LLM (例: GPT4) に SQL 生成を依頼 (プロンプトにサンプルSQLを含める) |
| 3 | 生成されたSQLを RDBMS に送信し、結果を返す |
prompt = f"""
You are a database assistant. Convert this question into SQL:
Question: {question}
Database schema: ticket_transactions(id, ticket_id, status, updated_at, comment_text)
Answer in plain SQL without any explanation:
"""
generated_sql = openai.ChatCompletion.create(
model="gpt-4",
messages=[{"role":"user","content":prompt}],
temperature=0
).choices[0].message.content.strip()
-
メリット
- 非技術者でも自然言語で検索可能
-
pgvectorベクトル検索結果と組み合わせれば “Semantic + SQL” のハイブリッド検索
③ RAG(Retrieval-Augmented Generation)
- 文脈検索: 先ほどのベクトル検索でトップ N を取得
-
LLM で回答生成:
prompt = f"以下の情報をもとに質問に答えて:\n{docs}\n質問:{question}" answer = openai.ChatCompletion.create(model="gpt-4", messages=[{"role":"user","content":prompt}])
- 応用: チケットのステータスチェーンを説明、原因を推理、アクション案を提案
④ ③ 傾向分析/可視化
① 時系列データを扱う SQL
| 目的 | SQL例 |
|---|---|
| ステータス別平均解決時間 |
avg + date_trunc
|
| 日次解決件数 |
count + group by
|
| 異常検知 | 3σ閾値、Moving Average, Prophet など |
-- ステータスごとの平均解決時間(分)
WITH resolved AS (
SELECT ticket_id,
min(updated_at) FILTER (WHERE status = 'open') AS opened_at,
max(updated_at) FILTER (WHERE status = 'resolved') AS resolved_at
FROM ticket_transactions
GROUP BY ticket_id
)
SELECT status,
avg(EXTRACT(EPOCH FROM (resolved_at - opened_at))/60) AS avg_minutes
FROM ticket_transactions t
JOIN resolved r ON t.ticket_id = r.ticket_id
WHERE status = 'resolved'
GROUP BY status;
② ダッシュボード
| ツール | 特徴 |
|---|---|
| Grafana | Prometheus, PostgreSQL, TimescaleDB 連携。アラート機能付き。 |
| Metabase | シンプルな質問インタフェース。SQL自動生成。 |
| Superset | SQL Lab + Visual Editor。スケジューリング。 |
| Power BI / Tableau | 商用。高度な分析機能。 |
TimescaleDB へ移行すると
time_bucket関数を使って高速に集計できます。
③ 異常検知 / 予測
-
統計ベース
# Python from statsmodels.tsa.seasonal import STL series = pd.read_sql("SELECT date, count FROM daily_resolved") stl = STL(series['count'], period=7).fit() stl.plot() -
ML ベース
- Prophet、SARIMA、AutoARIMA
- Scikit-learn で RandomForestRegressor, XGBoost
-
アラート例
- 平均解決時間が 1.5倍以上上昇 → オペレーターへ通知
-
resolvedステータスの遅延率 5% 超 → スキル向上の検討
⑤ 推奨構成例
┌──────────────────────┐ ┌──────────────────────┐
│ Frontend (React/Web) │ │ GraphQL / REST API │
│ (natural language │ │ (Node.js/Python) │
│ query入力) │ │ (LLM & DB Query) │
└───────▲───────────────┘ └───────▲───────────────┘
│ │
┌───────▼───────┐ ┌──────────┴─────────────┐
│ pgvector │ │ LangChain (LLM,RAG) │
│ + Postgres ├────────►│ + OpenAI │
│ + Timescale │ │ + Redis Cache │
└───────▲───────┘ └───────▲─────────────────┘
│ │
┌───────▼───────┐ ┌──────────┴─────────────┐
│ Airflow / │ │ Grafana / Metabase │
│ dbt / Kafka │ │ (Dashboard) │
└───────────────┘ └──────────────────────────┘
-
主なフロー
- チケットステータス変更 →
ticket_transactionsに INSERT/UPDATE - Airflow で 5 min でテキスト → ベクトル化 →
embedding列へ書き込み - フロントで自然言語を入力 → LLM/pgvector で検索 → フロントへ結果返却
- ダッシュボードで日次/週次統計・異常を可視化
- チケットステータス変更 →
⑥ まとめ
| やりたいこと | 技術選択 | ざっくりしたフロー |
|---|---|---|
| 自然言語検索 | pgvector + ベクトル検索 / LLM→SQL | テキスト → 埋め込み → Postgres ベクトル検索 → 結果 |
| 傾向分析 | PostgreSQL / TimescaleDB + SQL + Tableau / Grafana |
date_trunc, avg, count などで集計 → ビジュアル化 |
| 異常検知 | StatsModels / Prophet / XGBoost | 時系列を抽出 → モデルで予測 → アラート |
| LLM支援 | LangChain + OpenAI | 質問 → LLM で SQL 生成 → 実行・結果返却 |
ポイント
- 埋め込みは 300 次元以内(
pgvectorは 300 で安定)- 検索はインデックス化 (
ivfflat,hnsw)- データ更新頻度 は「変更時瞬時」ではなく「バッチ化」推奨
- ダッシュボードは 1 日 1 回の集計 で十分
この構成をベースに、業務プロセスや規模に合わせてスケールアウト(分割テーブル、Sharding、クラウド RDS/Redshift など)を検討してください。
質問や細かな実装調整が必要なら、ぜひ具体的な DB スキーマやテストケースを共有してください。Happy coding! 🚀
3. 試してみる
いくつかの方法でgpt-ossを試してみました。3.1. 気軽に試す(Playground) 3.2. 高速出力を体感する(Groq/Cerebras) は外部Cloudで試す方法です。3.3. PC(Copilot+PC)で動かしてみる(Ollamaを使用) は自身のPC上で試す方法です。これら以外にも様々なアプローチがあるようです。
gpt-ossのcookbook に様々なアプローチが紹介されているので、ぜひご覧ください!
3.1. 気軽に試す(Playground)
下記でプレイグラウンドが公開されていて、120bおよび20bを試すことができます。
gpt-ossのPlayground
実際の画面は下記となります。

Playground上でgpt-oss-120bを使っている様子
3.2. 高速出力を体感する(Groq/Cerebras)
AI推論およびトレーニングのための高性能なAIハードウェアを開発する企業で有名な Groq と Cerebras について、それぞれのPlaygroudで高速処理させることができます。Cerebrasでは1300T/s超えのパフォーマンスがでました。gpt-oss-120bがo4-mini相当の精度と言われている中でこのパフォーマンスは驚異的ですね!
Groq
Cerebras

Cerebrasでgpt-oss-120bを使っている様子
3.3. PC(Copilot+PC)で動かす(Ollamaを使用)
昨年(2024年)6月に購入したCopilot+PCで動かしてみました。今回Ollamaを使っています。
Ollamaのインストール手順は下記を参考にしてください。
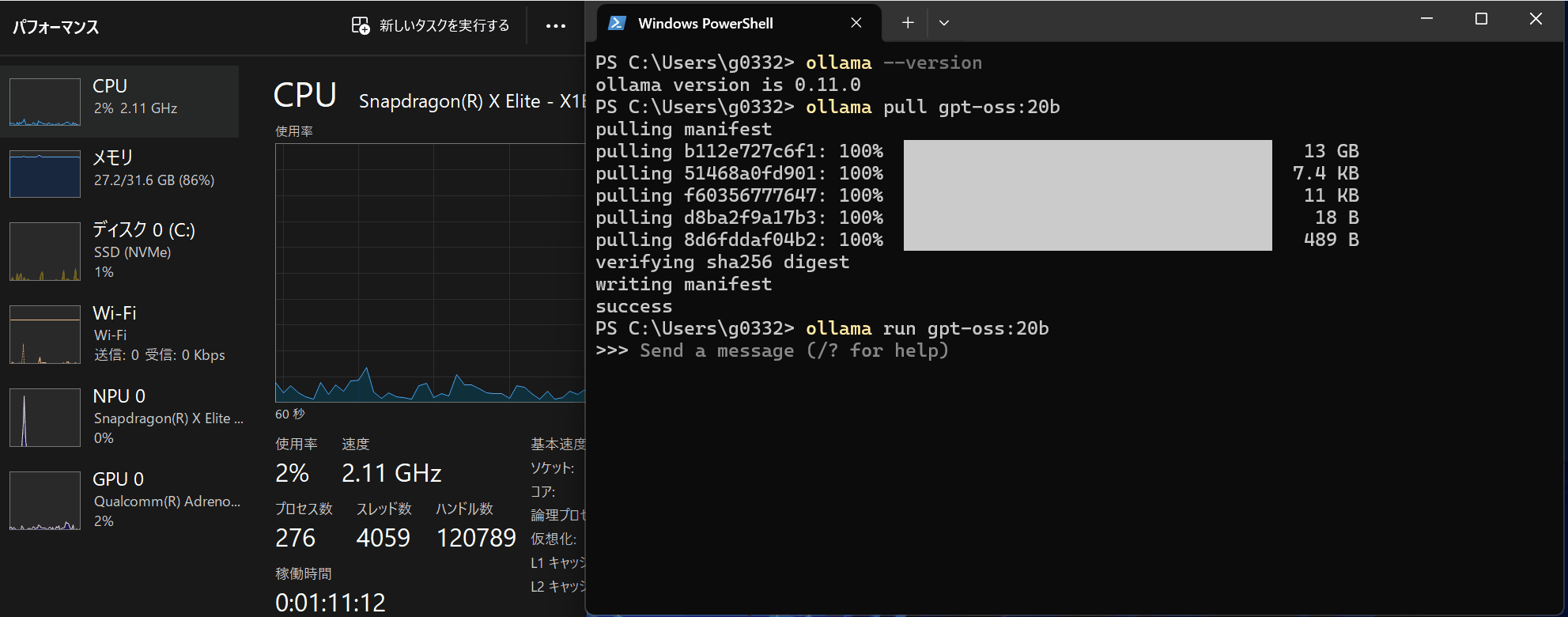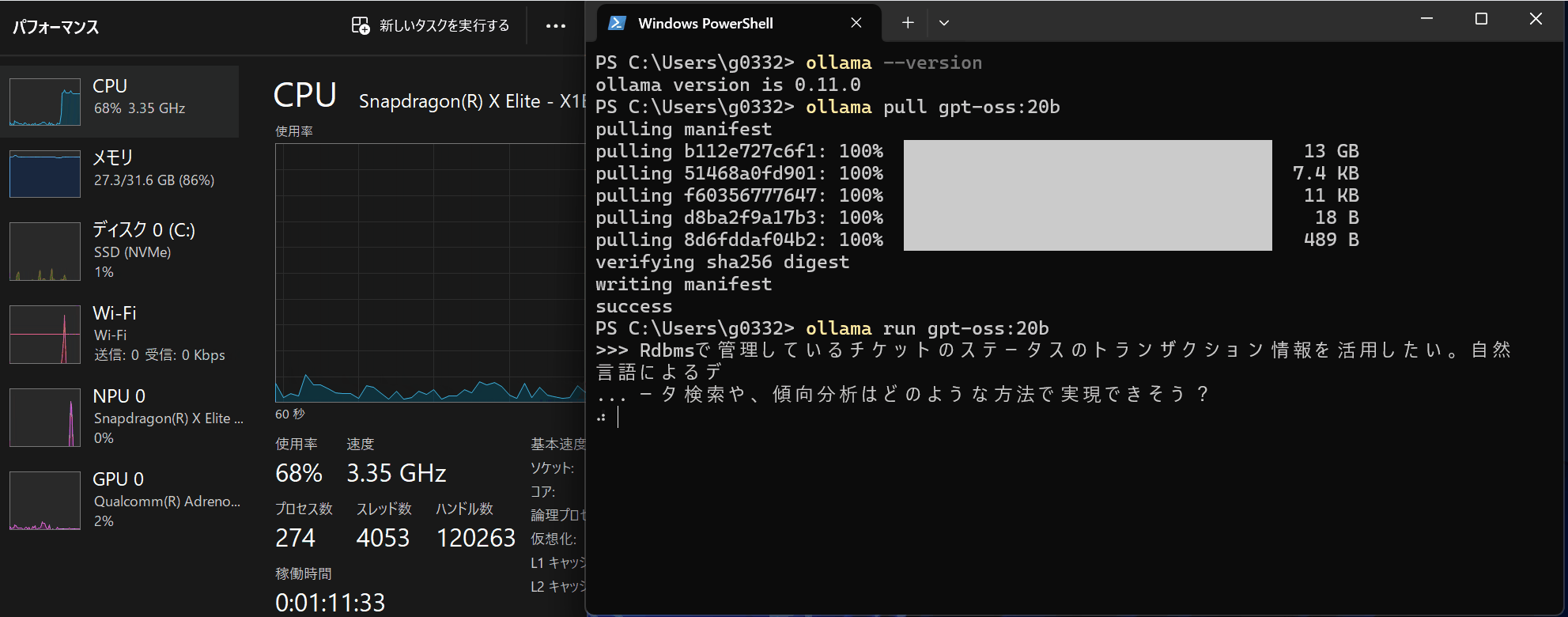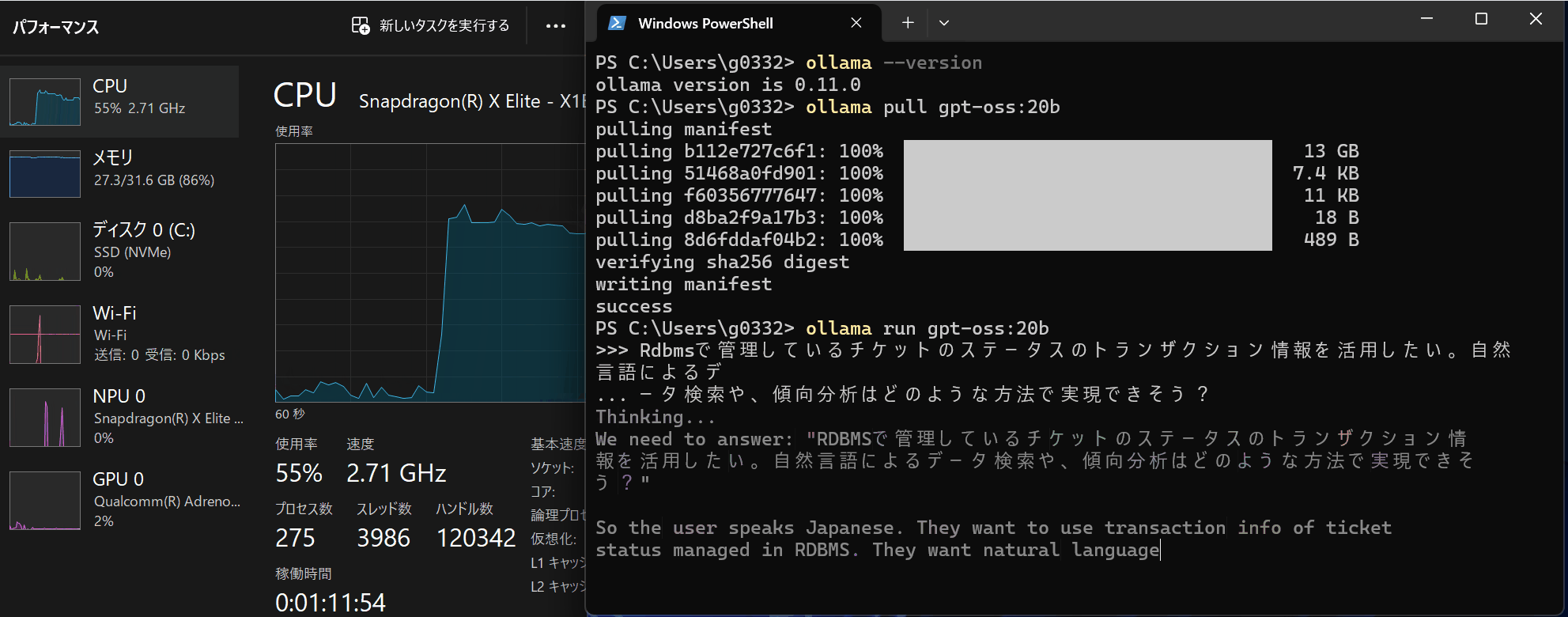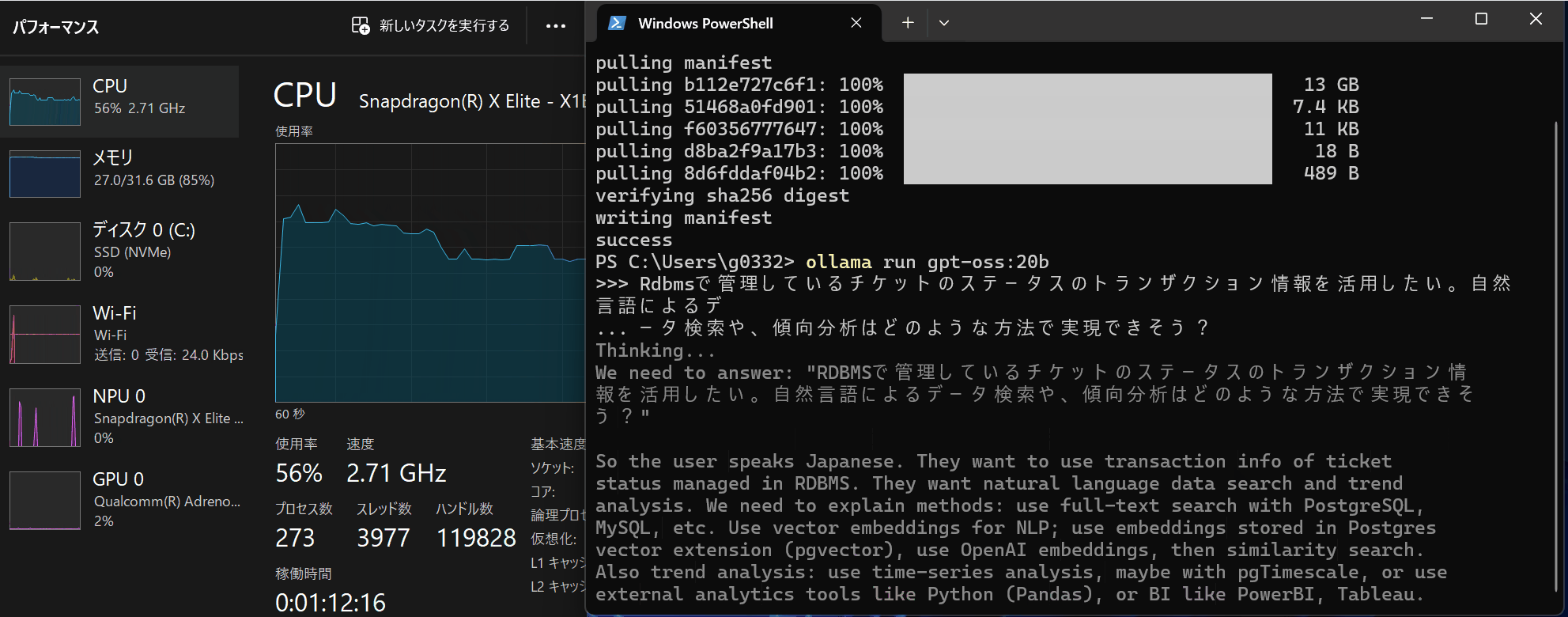
このPCのGPUメモリが16GBなので、gpt-oss-20bがギリギリ動く算段です。Copilot+PCが持つAIチップ NPU に対応するとまた状況が変わってくると考えています。(心待ち)
それでは、Ollamaにgpt-oss-20bをインストールしてみましょう。
ollama pull gpt-oss:20b
インストールしたら起動します。
ollama run gpt-oss:20b
実際に動いている様子は下記です。NPUを使わないCopilot+PCだとまだまだ厳しい様子。。。
4. おわりに
gpt-ossの登場により、精度が高いモデルが比較的安価なスペックでローカル上で動く世界観が見えてきました!また、OpenAIがリリースしたOSSということで、信頼性が高いものとなっているのがポイントかなと考えています。今後、ローカルLLMの活用がさらに進んでいくと考えられます。私含めて、ローカルLLMでどのように業務を変えていくか考えるターニングポイントが到来したと考えています。引き続き、追って試行錯誤して考えていきましょう!

アクセンチュア株式会社に所属する社員有志による運営です。アクセンチュアの社員による様々な発信をまとめています。なお、投稿内容は社員個人の見解であり、所属する組織を代表するものではありません。
Discussion