RAGシステムのサンプル実装アプリ
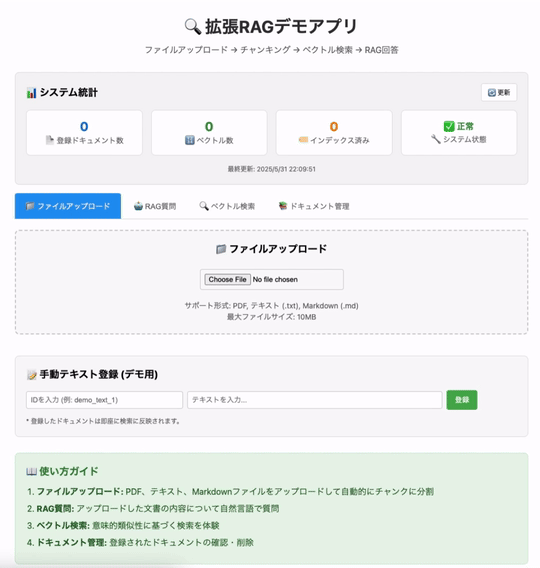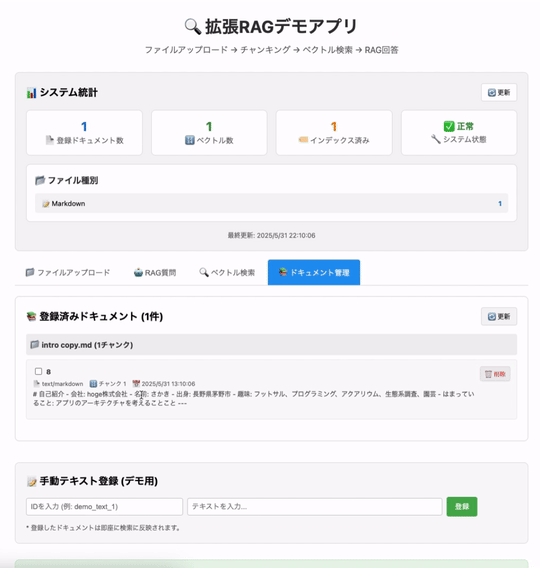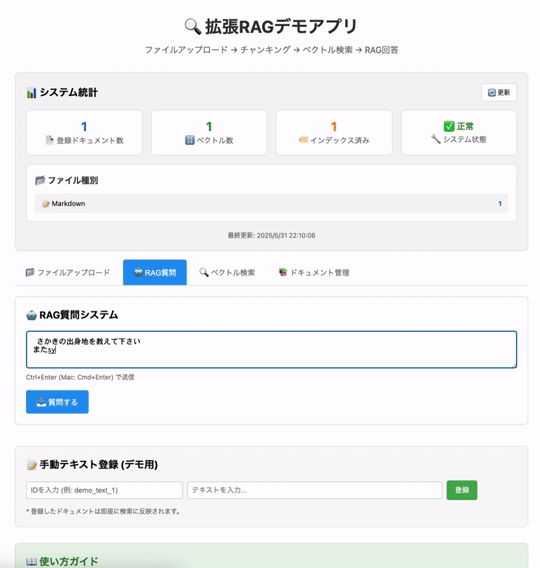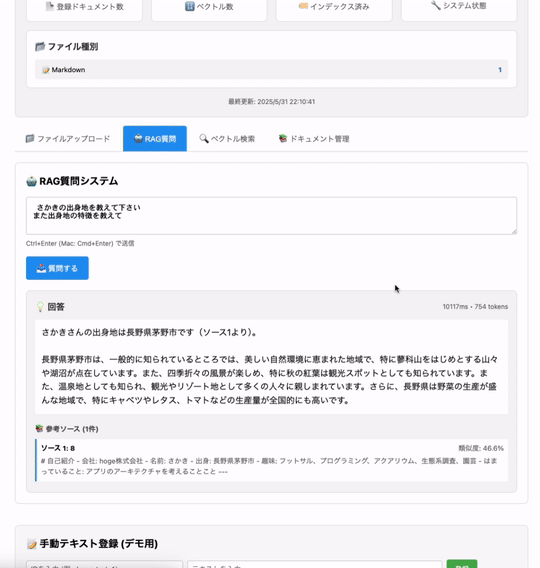
前半で学んだRAGとベクトル検索の概念を、実際のコードでどう実現しているか解説します。
このアプリは、以下がメインの機能になってます。
- ファイルを取り込んでベクトル化してDBに保存
- 質問の回答を作る時に、取り込んだファイルの内容から関連情報を参照して、gptが回答を作成する
ソースはGitHubで公開しています!
環境構築手順
前提: Docker(Compose)、Node.js、OpenAI API キー を用意済みとする
-
リポジトリをクローン
git clone <repository-url> cd sample-rag-app -
バックエンドの環境変数を設定
cd backend cat > .env << EOF DATABASE_URL=postgresql://postgres:password@localhost:5433/rag_db OPENAI_API_KEY=your_openai_api_key PORT=5001 EOF -
PostgreSQL+pgvector を立ち上げ
cd .. docker-compose up -d docker-compose ps -
バックエンドを起動
cd backend npm install npm start -
フロントエンドを起動
cd frontend npm install npm run dev -
ブラウザでアクセス
- フロントエンド → http://localhost:5173
- バックエンド API → http://localhost:5001
1. アプリケーションの技術スタック
(以下、元ドキュメントそのまま)
1. アプリケーションの技術スタック
バックエンド
| 技術 | 用途 |
|---|---|
| Node.js + TypeScript | APIサーバー実装 |
| Express.js | RESTful API |
| PostgreSQL + pgvector | ベクトルデータベース |
| OpenAI API | 埋め込み生成・回答生成 |
| pdf-parse | PDF処理 |
| multer | ファイルアップロード |
フロントエンド
| 技術 | 用途 |
|---|---|
| React + TypeScript | UI実装 |
| Vite | ビルドツール |
| Axios | API通信 |
簡易アーキテクチャ図
テーブル設計
ベクトルデータベースの選定
なぜPostgreSQL + pgvectorを選んだのか?
主要な選択肢を比較してます:
| ベクトルDB候補 | 特徴 | コスト | 導入難易度 | エンタープライズ適性 |
|---|---|---|---|---|
| PostgreSQL + pgvector | 既存PostgreSQLに拡張追加・SQLで操作可能・トランザクション対応 | 無料(OSS) | 低(既存DBに追加) | ◎ |
| Pinecone | フルマネージド・超高速・自動スケーリング | 有料($70~/月) | 低(SaaS) | ○ |
| Weaviate | GraphQL対応・ハイブリッド検索・メタデータフィルタ充実 | 無料(OSS) | 中 | ○ |
| Qdrant | Rust製高性能・REST/gRPC対応・軽量 | 無料(OSS) | 中 | ○ |
| Milvus | 大規模対応・GPU対応・高性能 | 無料(OSS) | 高 | △ |
| Chroma | 開発向け・シンプル・Pythonフレンドリー | 無料(OSS) | 低 | △ |
PostgreSQL + pgvectorを選定した理由
- 既存インフラの活用: 多くの企業は既にPostgreSQLを運用
- 運用スキルの転用: DBAチームの既存スキルをそのまま活用
- トランザクション対応: ベクトルデータと通常データの一貫性を保証
- コンプライアンス: データを外部サービスに送信しない
# docker-compose.yml
services:
postgres:
image: pgvector/pgvector:pg16
environment:
POSTGRES_DB: rag_db
POSTGRES_USER: postgres
POSTGRES_PASSWORD: password
ports:
- "5433:5432" # ローカルの5433ポートで接続
2. RAG作成のフローと実装
RAGシステムの全体フロー
4.1 文書の前処理(チャンキング)
チャンキングとは: 大きなテキストをベクトル検索に適したサイズに分割する処理です。適切なチャンクサイズにすることで、検索精度とコストのバランスを取ります。
なぜチャンキングが必要なのか?
LLMには入力トークン数の制限があり、また長すぎる文書は検索精度を下げます。適切なサイズに分割することで:
- 検索精度の向上
- コンテキストウィンドウの有効活用
- 処理コストの最適化
を実現します。
このRAGシステムの実装について、ソースコードの前に各機能の説明を追加していきます。
実装のポイント:
- 段落単位での分割を基本とし、自然な文脈の区切りを維持
- チャンクサイズ(1500文字)は、OpenAIのトークン制限と検索精度を考慮して設定
- オーバーラップ(150文字)により、チャンク境界での文脈の断絶を防ぐ
export function chunkText(text: string, chunkSize: number = 1500, overlapSize: number = 150): string[] {
// 段落で分割(空行で区切られた部分)
const paragraphs = text.split(/\n\s*\n/).filter(p => p.trim().length > 0);
const chunks: string[] = [];
let currentChunk = '';
for (const paragraph of paragraphs) {
if ((currentChunk + '\n\n' + paragraph).length <= chunkSize) {
currentChunk = currentChunk ? currentChunk + '\n\n' + paragraph : paragraph;
} else {
// チャンクサイズを超える場合は保存して新しいチャンクを開始
if (currentChunk.trim()) {
chunks.push(currentChunk.trim());
}
currentChunk = paragraph;
}
}
// オーバーラップ処理で文脈を保持
return addOverlapToChunks(chunks, overlapSize);
}
4.2 埋め込みベクトルの生成
埋め込みベクトルとは: テキストの意味を数値ベクトルとして表現したものです。類似した意味のテキストは、ベクトル空間上で近い位置に配置されます。
技術的な詳細:
- OpenAIの
text-embedding-3-smallモデルを使用 - 出力は1536次元の密ベクトル
- このベクトルが後の類似度検索の基礎となる
export async function embedText(text: string): Promise<number[]> {
const response = await openai.embeddings.create({
model: 'text-embedding-3-small',
input: text,
});
return response.data[0].embedding;
}
4.3 データベースへの保存
pgvectorの活用: PostgreSQLの拡張機能であるpgvectorを使用して、ベクトルデータを効率的に保存・検索します。
テーブル設計の工夫:
-
vector(1536)型でOpenAIの埋め込みベクトルを保存 - HNSWインデックスによる高速な近似最近傍探索
- JSONBフィールドで柔軟なメタデータ管理
// pgvector拡張をインストール
await client.query('CREATE EXTENSION IF NOT EXISTS vector;');
// ベクトル検索用のテーブル作成
await client.query(`
CREATE TABLE IF NOT EXISTS documents (
id SERIAL PRIMARY KEY,
content TEXT NOT NULL,
embedding vector(1536), -- OpenAIの埋め込みベクトル次元数
metadata JSONB DEFAULT '{}'
);
`);
// 高速検索のためのHNSWインデックス
await client.query(`
CREATE INDEX documents_embedding_hnsw_idx
ON documents
USING hnsw (embedding vector_cosine_ops)
WITH (m = 16, ef_construction = 64);
`);
ドキュメント保存処理: テキストをベクトル化してデータベースに保存する一連の流れを実装します。
export async function upsertDocumentWithMetadata(
id: string,
text: string,
metadata: any = {}
): Promise<void> {
const client: PoolClient = await pool.connect();
try {
// テキストをベクトル化
const embedding = await embedText(text);
const query = `
INSERT INTO documents (title, content, metadata, embedding)
VALUES ($1, $2, $3, $4)
RETURNING id
`;
const result = await client.query(query, [
metadata.filename || id,
text,
JSON.stringify(metadata),
`[${embedding.join(',')}]`, // PostgreSQLのvector型として保存
]);
console.log(`✅ ドキュメントを保存しました (ID: ${result.rows[0].id})`);
} finally {
client.release();
}
}
4.4 RAG回答生成の実装
RAGパイプライン: 検索(Retrieval)→ 拡張(Augmentation)→ 生成(Generation)の3段階を統合した処理です。
処理フローの詳細:
- ユーザーの質問をベクトル化
- 類似度の高いドキュメントを検索
- 検索結果をコンテキストとしてプロンプトに組み込み
- LLMが検索結果と自身の知識を組み合わせて回答生成
- 出典情報と共に結果を返す
export async function generateRAGAnswer(question: string, maxSources: number = 3): Promise<RAGResponse> {
const startTime = Date.now();
try {
// 1. 関連ドキュメントを検索
console.log('\n🔍 検索クエリ:', question);
const searchResults = await searchSimilarDocuments(question, maxSources);
if (searchResults.length === 0) {
return {
answer: '申し訳ございませんが、関連する情報が見つかりませんでした。',
sources: [],
responseTime: Date.now() - startTime
};
}
// 2. コンテキストを構築
const context = searchResults
.map((doc, index) => `[ソース${index + 1}] (関連度: ${(doc.score * 100).toFixed(1)}%)\n${doc.text}`)
.join('\n\n---\n\n');
// 3. プロンプトを構築
const systemPrompt = `あなたは提供された情報に基づいて回答する専門アシスタントです。
以下のルールに従って回答してください:
1. 提供された情報を優先的に使用してください
2. 提供された情報に不足がある場合は、あなたの知識を補完的に使用して回答を充実させてください
3. 情報の出典を明確にしてください:
- 提供された情報からの場合は「ソースXによると...」と明記
- あなたの知識からの場合は「一般的に...」や「知られているところでは...」と明記
4. 推測や憶測は避け、事実に基づいて回答してください
5. 回答は分かりやすく、構造化して提供してください`;
const userPrompt = `以下の情報を参考にして質問に答えてください。
必要に応じて、あなたの知識も活用して回答を充実させてください。
【参考情報】
${context}
【質問】
${question}
【回答】`;
// 4. OpenAI APIで回答生成
console.log('\n🤖 AI回答生成中...');
const response = await openai.chat.completions.create({
model: 'gpt-4',
messages: [
{ role: 'system', content: systemPrompt },
{ role: 'user', content: userPrompt }
],
temperature: 0.2, // 低めの温度で一貫性のある回答を生成
max_tokens: 1500,
});
const answer = response.choices[0].message.content || 'エラーが発生しました';
const tokensUsed = response.usage?.total_tokens;
// 5. レスポンスを構築
const sources = searchResults.map(doc => ({
id: doc.id,
score: doc.score,
text: doc.text,
chunk_preview: doc.text.length > 150
? doc.text.substring(0, 150) + '...'
: doc.text
}));
const responseTime = Date.now() - startTime;
console.log('\n✅ 回答生成完了');
console.log(`⏱️ 処理時間: ${responseTime}ms`);
console.log(`📊 使用トークン数: ${tokensUsed}`);
return {
answer,
sources,
responseTime,
tokensUsed
};
} catch (error) {
console.error('\n❌ RAG回答生成エラー:', error);
throw new Error(`回答の生成に失敗しました: ${error}`);
}
}
3. ベクトルデータベースの検索ロジック詳解
コサイン類似度検索の仕組み
ベクトル検索の原理: 埋め込みベクトル間のコサイン類似度を計算し、意味的に近い文書を高速に検索します。
SQLクエリの詳細解説:
SELECT
id,
title,
content,
metadata,
1 - (embedding <=> $1) as similarity
FROM documents
WHERE 1 - (embedding <=> $1) > 0.3
ORDER BY embedding <=> $1
LIMIT $2
各要素の役割:
-
<=>演算子: pgvectorのコサイン距離演算子(0〜2の範囲) -
1 - (embedding <=> $1): 距離を類似度(0〜1)に変換 -
WHERE句: 類似度30%以上でフィルタリング(ノイズ除去) -
ORDER BY: 最も類似度の高い順にソート -
LIMIT: 指定された件数のみ返す
TypeScriptでの実装
検索処理の実装: クエリのベクトル化から類似文書の取得まで、エラーハンドリングを含めた堅牢な実装です。
実装の特徴:
- 閾値による2段階検索(結果がない場合は自動的に閾値を緩和)
- ベクトルの文字列変換処理
- 適切なリソース管理(コネクションプールの使用)
export async function searchSimilarDocuments(
query: string,
limit: number = 5,
threshold: number = 0.3
): Promise<Array<{ id: string; score: number; text: string }>> {
const client: PoolClient = await pool.connect();
try {
// クエリをベクトル化
console.log('🔄 クエリをベクトル化中...');
const queryEmbedding = await embedText(query);
// コサイン類似度で検索
const searchQuery = `
SELECT
id,
content,
1 - (embedding <=> $1) as similarity
FROM documents
WHERE 1 - (embedding <=> $1) > $2
ORDER BY embedding <=> $1
LIMIT $3
`;
const result = await client.query(searchQuery, [
`[${queryEmbedding.join(',')}]`, // ベクトルを文字列として渡す
threshold,
limit
]);
// 結果がない場合は閾値を下げて再検索
if (result.rows.length === 0) {
console.log('⚠️ 検索結果なし。閾値を下げて再検索します...');
const retryResult = await client.query(
`SELECT id, content, 1 - (embedding <=> $1) as similarity
FROM documents ORDER BY embedding <=> $1 LIMIT $2`,
[`[${queryEmbedding.join(',')}]`, limit]
);
return retryResult.rows.map(row => ({
id: row.id.toString(),
score: parseFloat(row.similarity),
text: row.content
}));
}
return result.rows.map(row => ({
id: row.id.toString(),
score: parseFloat(row.similarity),
text: row.content
}));
} finally {
client.release();
}
}
おわりに
実際に実装してみて、ベクトル検索やRAG作成の実装が結構簡単だなと思ったのと、いろんな場面で実装したいなと思いました。是非皆さんも一回実装してみてはいかがでしょうか!

アクセンチュア株式会社に所属する社員有志による運営です。アクセンチュアの社員による様々な発信をまとめています。なお、投稿内容は社員個人の見解であり、所属する組織を代表するものではありません。
Discussion