はじめに
アクセンチュア株式会社 テクノロジーコンサルティング本部の銭谷(ぜにや)です。
今回、業務の一環で「Red Hat OpenShift Service on AWS(ROSA)」の「ROSA with hosted control planes(ROSA with HCP)」 に触れる機会があり、いくつか検証してみたのでその内容を記事にします。検証内容は何回かに分けて記事にする予定で、本記事はシリーズ1本目です(何本書くかは未定です)。
なお、ROSAには「ROSA classic」と「ROSA with HCP」の2つがあります。前述のとおり当記事のシリーズで扱うのは「ROSA with HCP」となりますので、あらかじめご了承ください。
ROSA with HCPとは?
ROSAとは、Kubernetesベースのコンテナ実行基盤である「OpenShift」を、AWS上でマネージドサービスとして利用できるサービスです。この記事で扱うROSA with HCPとは、OpenShiftのコントロールプレーンもマネージド型で提供されるサービスで、2023年12月からGAになった比較的新しいサービスです。最小構成で必要なEC2インスタンスの台数が少ないため、従来提供されてきたROSA classicよりも検証等を行いやすくなっています。
結論
ROSA with HCPでクラスタを構築するとNLBとWorker Nodeが作成されますが、NLBのヘルスチェックで同時にHealthyになるWorker Nodeは2台までとなります。
これは、NLBのヘルスチェックターゲットとなるRouter Podが、2台のWorker Node上で1個ずつ稼働するようになっているためです(挙動を見る限りこれはROSAのデフォルト動作のようです)。今回の場合3つのAZに各1台ずつWorker Nodeを配置する構成でクラスタを作成したため、1AZは必ずヘルスチェックNGとなる状態でした。なお、手動でRouter Podを増やすことで全AZのヘルスチェックがOKとなることも確認できました。
NLBのヘルスチェックがNGになっていても見え方の問題だけであり、運用上の問題はないものと考えています。Router Podが稼働しているWorker NodeでヘルスチェックNGとなった場合、Router Podは他の(これまでUnhealthyだった)Worker Nodeに自動的に再配置されます。また、後述しますがRouter Podが存在しないWorker Nodeであってもクラスタ外からのトラフィックは問題なくルーティングされます。
検証のきっかけ
ROSA with HCPで3AZにまたがるクラスタを作成しました。クラスタを作成すると手前にNLBが作成されます。このNLBのヘルスチェックが、なぜか1AZだけUnhealthyになることに気づきました。
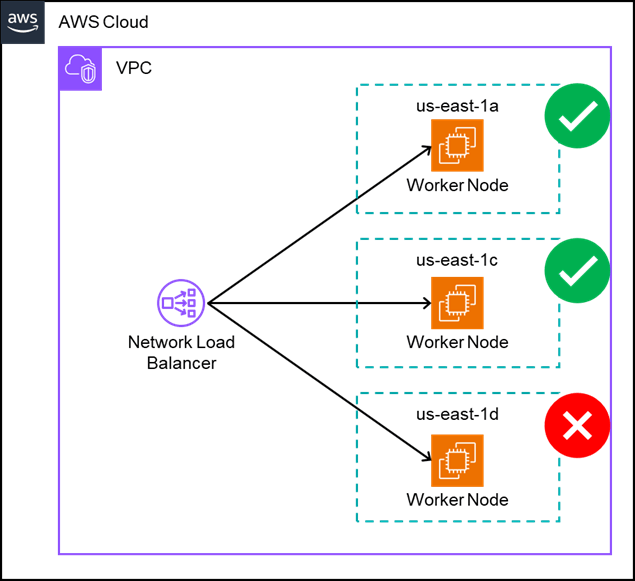

以下、試してみたことと結果です。
- クラスタの再作成(複数回)
⇒状況変わらず - セキュリティグループのルール確認等
⇒問題なし - HealthyなWorker Nodeを手動STOP(ちょっと乱暴ですが)
⇒しばらく待った後、UnhealthyだったWorker NodeがHealthyになった
なお、No.3で手動STOPしたWorker Nodeを手動起動させたところ、即座にTerminatedになり、新しいEC2インスタンスがWorker Nodeとして自動的に追加されていました(そして今度はこの追加されたWorker NodeがUnhealthyになりました)。
以上の観察の結果(特にNo.3から)1AZだけUnhealthyになっているのは私の設定ミスではなく、ROSA with HCPが意図をもって行っていることではないかと推測しました。
ここからちょっと飛躍してしまうのですが、有識者に質問した結果、NLBのヘルスチェック対象がRouter Podだということに辿り着いた次第です。
Router Podがなくてもルーティングできるの?
NLBのヘルスチェックとRouter Podの関係が見えたところで、1つ疑問を持ちました。Red Hat様のブログによるとクラスタ外からのルーティングは下図のようになっています。これを見ると、外部からユーザーアプリへのトラフィックはRouter Podが存在するWorker Nodeにしかルーティングされないようにも思えます。
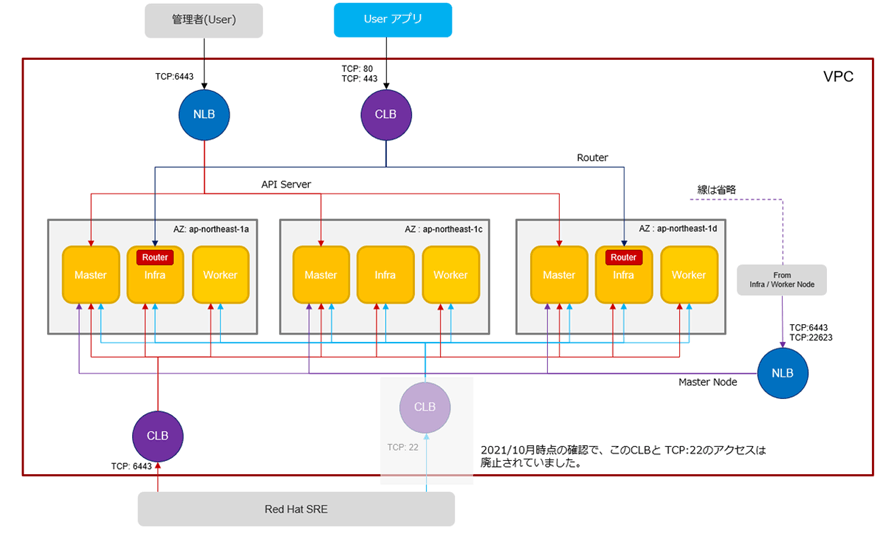
そこで、Router Podが存在しないWorker Nodeでもクラスタ外からのトラフィックがルーティングされるのか検証してみました。検証には、HTTPでアクセスすると「Welcome from a Node.js app!」と表示するだけのシンプルなアプリを使用しました。
このDockerイメージをDeploymentとしてクラスタ上に作成しました。まずは検証の準備としてexposeして動作確認します。
$ oc expose deployment/node --port=8080 --target-port=8080 --type=LoadBalancer
service/node exposed
$ oc get svc node -n nodejs
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
node LoadBalancer 172.30.67.60 xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx-xxxxxxxxx.us-east-1.elb.amazonaws.com 8080:32548/TCP 27s
$ curl http://xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx-xxxxxxxxx.us-east-1.elb.amazonaws.com:8080
Welcome from a Node.js app!
# 正常に動作しています。
次に、Router PodとアプリのPodが動作しているWorker Nodeをそれぞれ確認します。その後、taintを設定してアプリのPodをRouter Podが存在しないWorker Nodeへ移動させます。
# Router PodのWorker Node
$ oc get pods -n openshift-ingress -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
router-default-6dbc586d85-b67mh 1/1 Running 0 89m 10.129.0.8 ip-10-0-12-141.ec2.internal <none> <none>
router-default-6dbc586d85-b6qws 1/1 Running 0 89m 10.130.0.9 ip-10-0-2-142.ec2.internal <none> <none>
# ip-10-0-12-141とip-10-0-2-142で動作しています
# アプリのPodのWorker Node
$ oc get pod -n nodejs -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
node-9df9b9dc6-6vl5n 1/1 Running 0 25m 10.130.0.45 ip-10-0-2-142.ec2.internal <none> <none>
# アプリはip-10-0-2-142で動作しています(Router Podが存在するWorker Nodeです)
# Router Podが存在するWorker Nodeにtaintを設定
$ oc adm taint nodes ip-10-0-12-141.ec2.internal ndtype=notrt:NoSchedule
node/ip-10-0-12-141.ec2.internal tainted
$ oc adm taint nodes ip-10-0-2-142.ec2.internal ndtype=notrt:NoSchedule
node/ip-10-0-2-142.ec2.internal tainted
# アプリのPodをtaintされていないWorker Nodeへ移動させるため、手動Delete
$ oc delete pod node-9df9b9dc6-6vl5n -n nodejs
pod "node-9df9b9dc6-6vl5n" deleted
# アプリのPodが移動したか確認
$ oc get pod -n nodejs -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
node-9df9b9dc6-9qqff 1/1 Running 0 35s 10.128.0.30 ip-10-0-22-94.ec2.internal <none> <none>
# ip-10-0-22-94に移動しました(Router Podが存在していないWorker Nodeです)
アプリをRouter Podが存在しないWorker Nodeに移動できたので、再度動作確認を行います。
$ curl http://xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx-xxxxxxxxx.us-east-1.elb.amazonaws.com:8080
Welcome from a Node.js app!
無事にアプリからのメッセージが表示されました。このことから、Router Podが存在しないWorker Nodeであってもクラスタ外からのトラフィックがルーティングされることが分かりました。
Router Podを増やしたらどうなる?
Router PodがないWorker NodeがUnhealthyになるということは、全部のWorker NodeにRouter Podを配置すれば全部Healthyになるはずです。
Red Hat様のブログ記事を参考に試してみました。
まずは現在のRouter Podの状態を確認します。
$ oc get pods -n openshift-ingress -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
router-default-6dbc586d85-b67mh 1/1 Running 0 89m 10.129.0.8 ip-10-0-12-141.ec2.internal <none> <none>
router-default-6dbc586d85-b6qws 1/1 Running 0 89m 10.130.0.9 ip-10-0-2-142.ec2.internal <none> <none>
作成直後のクラスタでは2台のRouter Podが動作していることがわかります。

マネジメントコンソールを見ると、NLBのヘルスチェックでも1AZがUnhealthyになっています。ここからRouter Podの数を2→3に増加させます。
$ oc edit ingresscontroller/default -n openshift-ingress-operator
# ⇒エディタでreplicasの値を2から3に変更
$ oc get pods -n openshift-ingress -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
router-default-6dbc586d85-9jcwk 1/1 Running 0 6s 10.128.0.31 ip-10-0-22-94.ec2.internal <none> <none>
router-default-6dbc586d85-b67mh 1/1 Running 0 126m 10.129.0.8 ip-10-0-12-141.ec2.internal <none> <none>
router-default-6dbc586d85-b6qws 1/1 Running 0 126m 10.130.0.9 ip-10-0-2-142.ec2.internal <none> <none>
Router Podが3台に増えました。

先ほどまでは一番上のWorker NodeがUnhealthyでしたが、3つに増やしたところすべてHealthyになったことが確認できました。このことから、Router Podが存在していればNLBのヘルスチェックがHealthyになることが確認できました。
まとめ
NLBのヘルスチェック結果をきっかけに、Router Podとヘルスチェックの関係、クラスタ外からのトラフィックのルーティングについて検証を行いました。有識者の協力もあって比較的スムーズに検証することができました。
この記事がどなたかのお役に立てれば幸いです。
以上、アクセンチュアの銭谷がお届けしました。
アクセンチュア株式会社ではエンジニア職の積極採用を行っています。私たちと一緒に働きませんか?

アクセンチュア株式会社に所属する社員有志による運営です。アクセンチュアの社員による様々な発信をまとめています。なお、投稿内容は社員個人の見解であり、所属する組織を代表するものではありません。
Discussion