はじめに
前編では、Cloud FunctionsとBigQueryを使ってGitHub Trendingデータを自動収集する基盤を構築しました。今回はPDE試験でも中心のような気がする(他の機能はややマニアックな気もする)DataflowとLooker Studioの実装に入ります。
直面した課題:
- 同じリポジトリが1日に複数回収集されて重複する(10:00、13:00、16:00など)
- 過去のJSONファイルにフォーマットが崩れているものが混ざる
このままLooker Studioで可視化してもノイズだらけになってしまいます。
中編では、Dataflowを使ってデータをクレンジングし、分析可能な状態に整えるところまで進めていきます。
なぜDataflowが必要なのか?
前編のCloud Functionsは「イベント駆動」の処理には向いていますが、次のような用途には不向きです:
- 複数ファイルを横断して集計・加工したい
- 重複除去やクリーニングなどのバッチ処理を行いたい
- 過去データをまとめて再処理したい
- パイプラインの可観測性(モニタリング・ログ)が欲しい
Dataflowは、Apache Beamをベースにした分散処理基盤で、こうした「データ全体を見渡して加工する」処理に適しています。
アーキテクチャ(中編)
[Cloud Scheduler]
↓ 定期実行
[Dataflow Batch Job]
↓ 読み込み
[GCS: raw/*.json]
↓ 重複除去・整形
[BigQuery: deduped table]
↓ 可視化
[Looker Studio Dashboard]
Dataflowの実行は、プログラムを一本作り、それをスクリプト実行で呼び出しています。
ポイント:
- GCS上の生データを一度すべて読み込み、重複を排除してからBigQueryに書き込む
- 毎回テーブルを作り直す構成(WRITE_TRUNCATE)で、シンプルさと冪等性を両立
- Looker Studioから参照するのは、クレンジング済みの
dedupedテーブル
パイプラインの設計思想
今回のDataflowパイプラインの目的は明確です:
🎯 「article_id × 日付」の組み合わせで、その日の最新レコードだけを残す
具体例
同じarticle_idに対して、1日の中で複数回収集されたデータがあるとします:
| article_id | collected_at | today_stars |
|---|---|---|
| foo | 2025-12-01T10:12:00 | 100 |
| foo | 2025-12-01T13:02:00 | 150 |
| foo | 2025-12-01T16:44:00 | 200 |
この場合、最も新しい16:44のレコードだけ残すことで、「その日の最終状態」を正確に記録できます。
パイプラインの処理フロー
今回のDataflowパイプラインは、以下のステップで構成されています:
Dataflow実行ログのイメージ
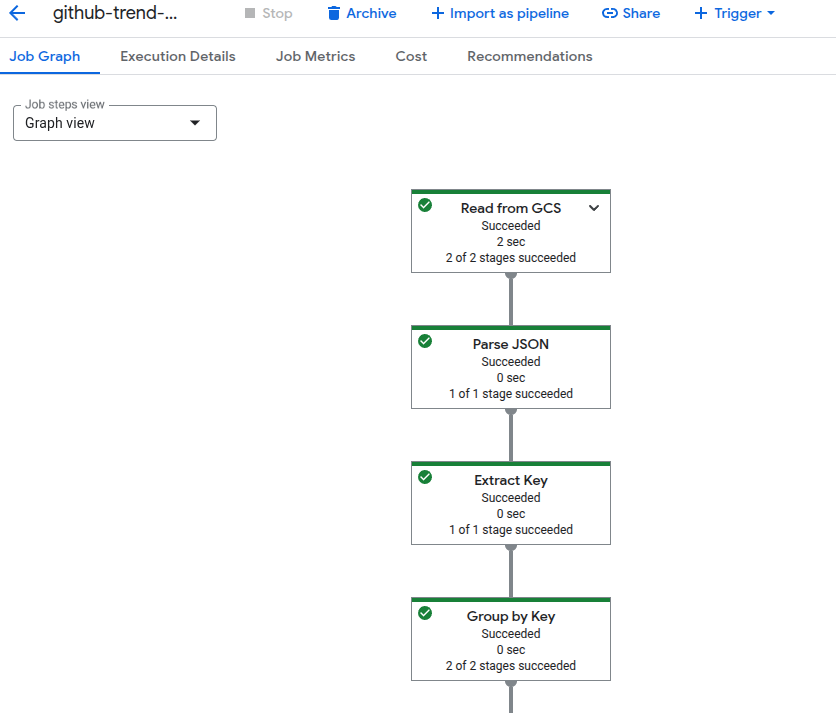

① GCS から JSON Lines を読み込み
↓
② JSON を Python の dict にパース
↓
③ article_id + 日付でキーを抽出
(例: "foo_2025-12-01")
↓
④ GroupByKey でキーごとにレコードを集約
↓
⑤ collected_at が最大のレコードだけ残す
↓
⑥ BigQuery用のフォーマットに整形
↓
⑦ BigQuery に書き込み(WRITE_TRUNCATE)
各ステップの役割
① JSON Linesの読み込み
GCS上のraw/*.jsonファイルを全件読み込みます。1行1JSONの形式(NDJSON)です。
② パース処理
JSONをPythonの辞書型に変換します。過去ファイルにはフォーマット崩れがあるため、try/exceptで保護して「読めたレコードだけ通す」設計にしています。
③ キーの抽出
article_idとcollected_atから日付部分を取り出し、foo_2025-12-01のような複合キーを作ります。
④ GroupByKey
同じキーに属するレコードをグループ化します。ここで「1日の間に何回も収集されたデータ」が1箇所に集まります。
Apache BeamのGroupByKeyは、Key-Value形式のPCollectionを受け取り、同じキーを持つ値をリストにまとめます:
入力: ("foo_2025-12-01", record1)
("foo_2025-12-01", record2)
("bar_2025-12-01", record3)
出力: ("foo_2025-12-01", [record1, record2])
("bar_2025-12-01", [record3])
⑤ 最新レコードの選択
グループ化されたレコードの中から、collected_atが最大のものだけを残します。これで「その日の最新状態」が確定します。record["collected_at"]の中には引き続き時刻の情報も残っているので、その時刻を活用します。
⑥ フォーマット整形
collected_atをBigQueryのTIMESTAMP型に変換するなど、スキーマに合わせて整形します。
⑦ BigQueryへの書き込み
WRITE_TRUNCATEモードで書き込むことで、毎回テーブルを完全に入れ替えます。
- メリット: シンプルで冪等性が保たれる(何度実行しても同じ結果)
- 注意点: 過去の履歴は残らないので、履歴管理が必要な場合は別途テーブルを用意
実装のポイント
バッチ処理の冪等性
Dataflowのバッチジョブは「何度実行しても同じ結果になる」ように設計しています。
- GCS上の全ファイルを読み込むため、過去データの追加・修正があっても再実行すれば最新状態に
-
WRITE_TRUNCATEにより、途中で失敗しても次回の実行で正しい状態に戻る
ハマったポイント
リソース枯渇エラー
Dataflowジョブを実行したところ、以下のエラーに遭遇しました:
ZONE_RESOURCE_POOL_EXHAUSTED: The zone 'asia-northeast1-b'
does not have enough resources available to fulfill the request.
GCPは今忙しいから放っといてほしいようです。
これは、Dataflow Workerを起動するゾーンのリソースが不足していることが原因です。
解決策:
ゾーンとワーカーマシンタイプ(低スペックのほうが空いていることが多いらしい)を明示的に指定することで回避できました:
--worker_zone=asia-northeast1-a
--worker_machine_type=e2-small
今回の環境では、asia-northeast1-aが比較的安定していました。
Looker Studioでの可視化
Dataflowでデータ品質が整ったことで、Looker Studioでの可視化がだいぶ扱いやすくなりました。
作成したチャート例:
-
日別スター推移:
collected_atをベースに、日ごとのトレンドを可視化 -
言語別の当日のスター数:
languageフィールドで日ごとのトレンドを可視化
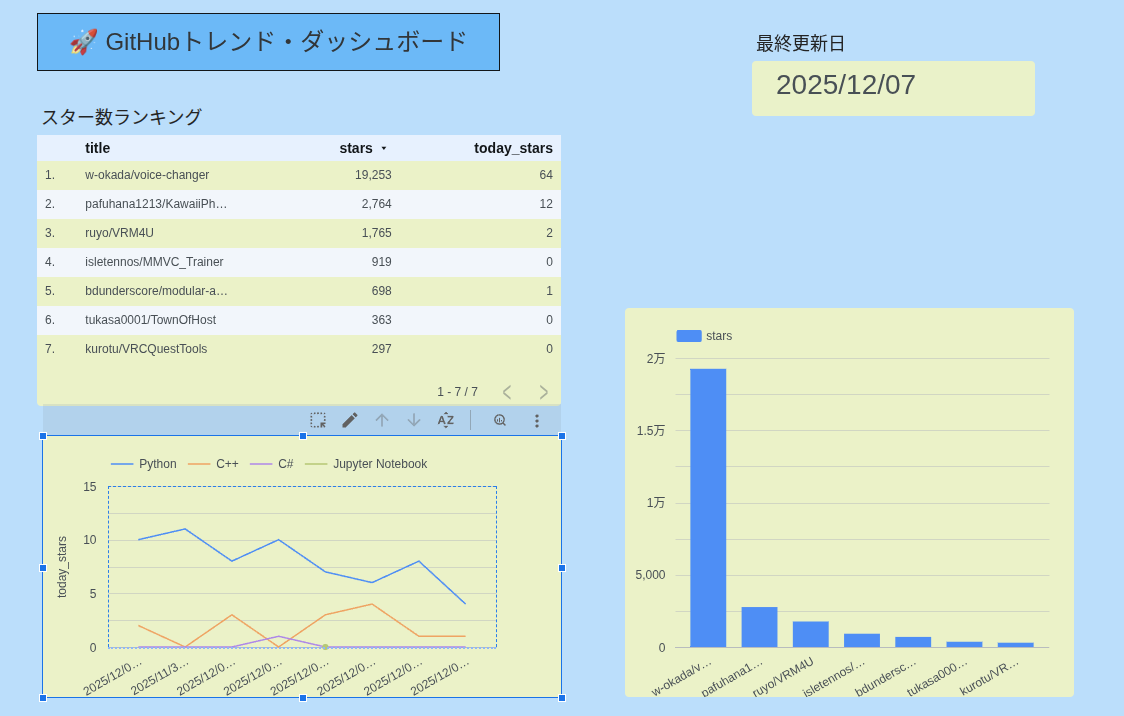
参考:貯めた元データ

特に、**「1日の最新状態だけ残す」**ようにしたことで、ランキング系のグラフが実態に近い形で表示できるようになりました。
重複データがあると、同じリポジトリが複数回カウントされて順位が歪んでしまいます。今回の重複除去により、正確なランキングが可視化できるようになったのは大きな成果です。
まとめ
中編では、Dataflowを導入してGitHub Trendingデータをクレンジングし、分析可能な状態に整えました。
実現できたこと:
- ✅ Dataflowを使った重複除去とデータクレンジング
- ✅
article_id × 日付単位で最新レコードを自動抽出 - ✅ BigQueryテーブルを毎回作り直す構造で、シンプルで安定した運用
- ✅ Looker Studioでの可視化がノイズなく実現
- ✅ 「ちゃんと使えるデータ基盤」に一段階進化
学びになったこと:
- バッチ処理の冪等性設計の重要性
- GCPのリソース制約への対処方法
- Dataflowバッチ処理は継続的に用意しようとするともう少し手がかかる(今回は対応を割愛)
PDE試験で学んだ知識(GroupByKey、バッチ処理、スキーマ整形など)を、実際のプロジェクトで使えたのも大きな収穫でした。
次回予告:ストリーミングDataflowに挑戦
後編では、ストリーミング処理に踏み込みます:
Dataflowといえば、バッチ処理とストリーミングの両輪で動いているという触れ込みなので、最後の検証として挑戦しました。
関連記事:

アクセンチュア株式会社に所属する社員有志による運営です。アクセンチュアの社員による様々な発信をまとめています。なお、投稿内容は社員個人の見解であり、所属する組織を代表するものではありません。
Discussion