2024年5月に開催されたMicrosoft BuildでGPT-4oが発表されました。
GPT-4oではテキスト入力に加えて画像をインプットにすることが可能になっています。
Azure上でもGPT-4oが利用可能になったようなので、実際に試してみました。
まだ少し触っただけですが、画像を直接インプットにして分析結果を出させたり、設計図やフロー図などを直接インプットしてコードを出させるといったマルチモーダルな利活用がいよいよ現実味を帯びてきたかも?と少し感じさせられました。
画像認識を実務レベルで活用するにはもう一段上のレベルに行く必要はありそうですが、昨今のテクノロジーの発展スピードはすさまじいので、実務で十分活用できるレベルに達する日もそう遠くないかもしれませんね。
1.AzureOpenAIでGPT-4oを利用する
Azure上でGPT-4oを利用することができますが、リージョンが限定されています。
現状サポートされているリージョンの最新情報は下記リンク先のStandard deployment model availabilityを参照してください。
2.インプットに使った画像(3種類)
今回は以下のようなPNGファイルを3種類用意して実験してみました。
1つ目:円グラフ

2つ目:散布図
3つ目:プログラムフロー図
上記のPNGファイルをインプットとして与え、与えられた画像から正しく情報を抽出して分析できるかを試してみました。
3.サンプルコード
AzureOpenAIにデプロイしたモデルを使ってシンプルなリクエストを投げるサンプルコードです。
モデルがGPT-4oの場合でもリクエストの投げ方は今までと基本的に同じです。
画像をインプットにしたい場合は、リクエストに投げる際のuserロールのcontent内にtype=textに加えてtype=image_urlを与えて画像のURLかbase64エンコードした情報を指定すればOKです。
※利用しているopenaiのバージョンは0.28.0です。最新バージョンだとエラーになるため修正が必要。
import openai
import base64
# OpenAI APIの各種キーを設定
API_KEY = "APIキーをここに指定"
API_BASE = "エンドポイントを指定"
API_TYPE = "azure"
API_VERSION = "2023-05-15"
GPT_MODEL_NAME = "GPT-4oのデプロイ名をここに指定"
# Azure OpenAIにリクエストを送信し、レスポンスを取得する関数
def send_request_to_azure_openai(messages):
try:
openai.api_key = API_KEY
openai.api_base = API_BASE
openai.api_type = API_TYPE
openai.api_version = API_VERSION
response = openai.ChatCompletion.create(
engine=GPT_MODEL_NAME,
temperature=0.5,
stream=False,
top_p=1.0,
stop=None,
presence_penalty=0,
frequency_penalty=0,
messages=messages
)
return response
except Exception as e:
return {"error": str(e)}
# メイン関数
def main():
# PNGファイルのパスを指定
file_path = '<ここにインプットしたいPNGファイルパスを指定'
# ファイルをバイナリモードで開いて読み込む
with open(file_path, 'rb') as image_file:
# ファイルの内容を読み込む
encoded_string = base64.b64encode(image_file.read()).decode('utf-8')
# data URIスキームに従ってフォーマットする
image_url = f"data:image/png;base64,{encoded_string}"
# メッセージリストを作成
messages = [
{
"role": "user",
"content": [
{
"type": "text",
"text": "<ここに指示文を記載する>"
},
{
"type": "image_url",
"image_url": {
"url": image_url
}
}
]
}
]
# Azure OpenAIにリクエストを送信し、レスポンスを取得する
response = send_request_to_azure_openai(messages)
# レスポンスにエラーが含まれているかチェックする
if 'error' in response:
print(response['error'])
else:
# 応答内容を取得する
response_content = response['choices'][0]['message']['content']
print(response_content)
if __name__ == '__main__':
main()
4.実行結果
4-1.円グラフの実行結果
以下の指示内容と円グラフのPNGファイルを与えてみました。
与えられた画像からわかる情報を抽出してMarkdown表形式でまとめてください。また、抽出した情報から課題を洗い出し、課題とアクションプランをMarkdown表形式でまとめてください。
以下のような回答が返ってきました。
### 抽出した情報
| 理解度 | 割合 |
|----------------------|--------|
| 全く理解していない | 9.4% |
| あまり理解していない | 59.4% |
| 基本的な知識はある | 31.2% |
### 課題とアクションプラン
| 課題 | アクションプラン
|
|----------------------------------------------------------------------|----------------------------------------------------------------------------------|
| 生成AIに対する理解が低い(あまり理解していない、全く理解していないが68.8%) | 1. 生成AIに関する基礎講座を開催する<br>2. 社内で生成AIの活用事例を共有する<br>3. 生成AIに関するFAQを作成し、社員に配布する |
| 基本的な知識を持つ人が31.2%に留まっている | 1. 生成AIの応用講座を開催する<br>2. 生成AIの実践的 なワークショップを実施する<br>3. 生成AIに関するオンラインリソース(動画、記事など)を提供する |
ちょっとみずらいので、きれいに可視化すると以下のような感じになりました。
分析結果

元画像
シンプルな円グラフの画像データだと、かなり正確に情報を読み取って分析してくれてますね!
4-2.散布図の実行結果
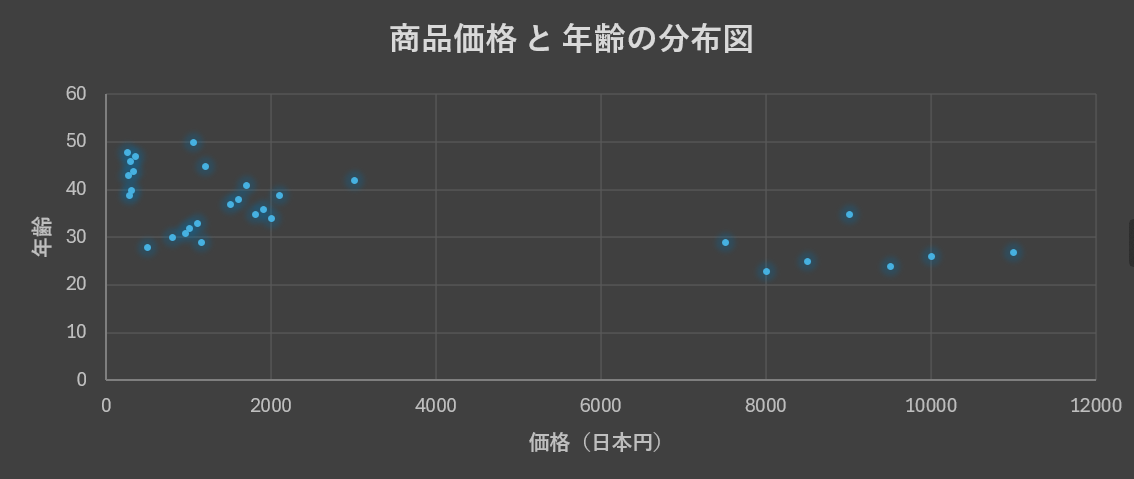
次に商品販売実績データの散布図を与えてみました。
指示内容は先ほどと同様です。
分析結果は以下のようになりました。

元画像
[抽出した情報]の[傾向]の部分の説明が若干誤っています(価格が高い商品の購入層は30~50歳ではなく20~40歳のレンジが正しい)が,全体的にはいい感じの分析結果を提示してくれてる感じかなと思います。
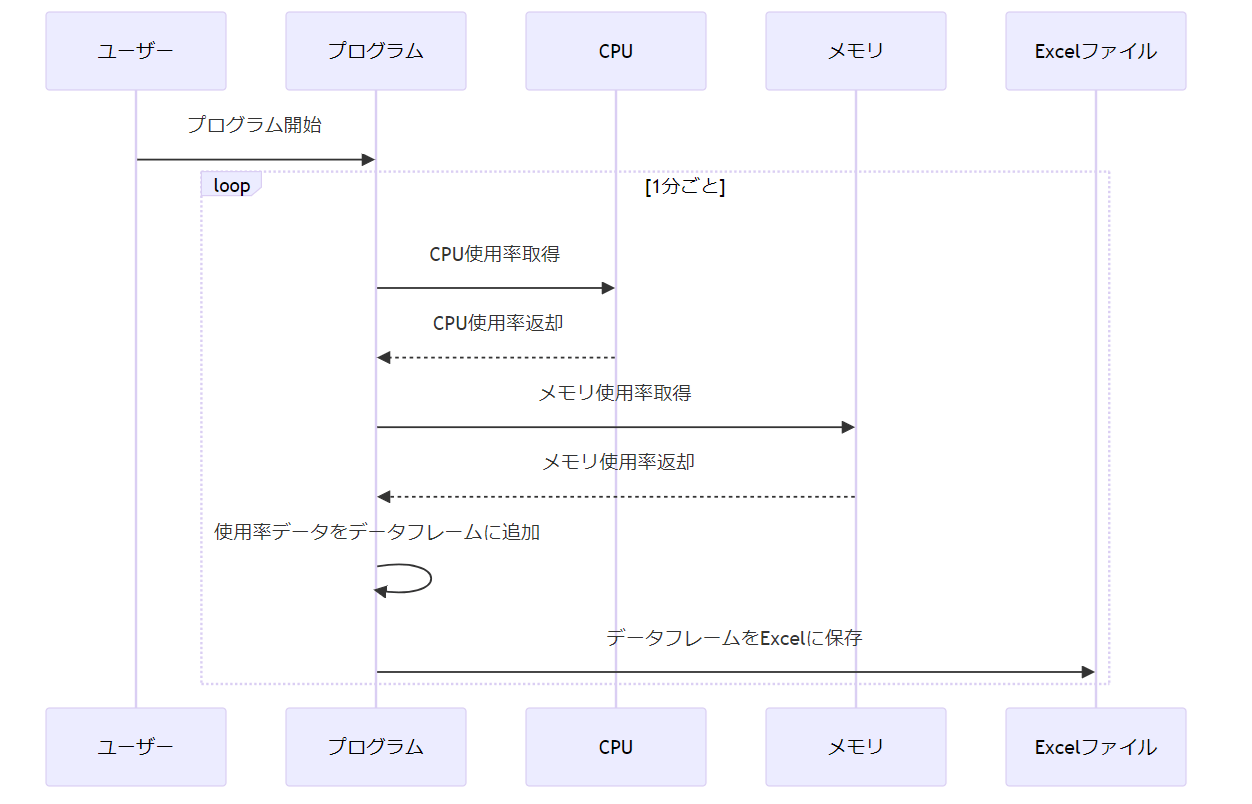
4-3.プログラムフロー図の実行結果
最後に、以下の指示内容とプログラムのフロー図(PCのリソース情報を自動収集)を与えてPythonコードを生成させてみました。
フロー図
指示内容
与えられたフロー図を実現するPythonコードを作成して下さい。
ここから下が返ってきた内容
与えられたフロー図に基づいて、PythonでCPUとメモリの使用率を1分ごとに取得し、それらのデータをデータフレームに追加し、最終的にExcelファイルに保存するプログラムを作成します。以下にそのPythonコードを示します。
import psutil
import pandas as pd
import time
def get_cpu_usage():
return psutil.cpu_percent(interval=1)
def get_memory_usage():
return psutil.virtual_memory().percent
def main():
# データフレームの初期化
data = {
"Time": [],
"CPU Usage (%)": [],
"Memory Usage (%)": []
}
df = pd.DataFrame(data)
try:
while True:
# 現在時刻の取得
current_time = pd.Timestamp.now()
# CPU使用率の取得
cpu_usage = get_cpu_usage()
# メモリ使用率の取得
memory_usage = get_memory_usage()
# データフレームにデータを追加
df = df.append({
"Time": current_time,
"CPU Usage (%)": cpu_usage,
"Memory Usage (%)": memory_usage
}, ignore_index=True)
# データフレームをExcelに保存
df.to_excel("usage_data.xlsx", index=False)
# 1分待機
time.sleep(60)
except KeyboardInterrupt:
print("プログラムが中断されました。")
if __name__ == "__main__":
main()
このコードは以下の手順で動作します:
-
psutilライブラリを使用してCPUとメモリの使用率を取得します。 -
pandasライブラリを使用してデータをデータフレームに格納します。 - 1分ごとにCPUとメモリの使用率を取得し、データフレームに追加します。
- データフレームをExcelファイルに保存します。
- プログラムは無限ループで動作しますが、
KeyboardInterrupt(Ctrl+C)で中断できます。
このプログラムを実行する前に、psutilとpandasライブラリをインストールする必要があります。以下のコマンドでインストールできます:
pip install psutil pandas openpyxl
このコードを実行すると、usage_data.xlsxという名前のExcelファイルにCPUとメモリの使用率データが1分ごとに記録されます。
ここまでが返ってきた内容
生成してもらったPythonコードをそのまま実行したところ以下のエラーが出てしまいましたが、最新のpandasではappendメソッドがなくなっていることを学習してないっぽいので、そこだけ修正したら問題なく動作しました。
AttributeError: 'DataFrame' object has no attribute 'append'. Did you mean: '_append'?
修正版のコード(待機時間は1分→10秒に修正してます)
import psutil
import pandas as pd
import time
def get_cpu_usage():
return psutil.cpu_percent(interval=1)
def get_memory_usage():
return psutil.virtual_memory().percent
def main():
# データフレームの初期化
data = {
"Time": [],
"CPU Usage (%)": [],
"Memory Usage (%)": []
}
df = pd.DataFrame(data)
try:
while True:
# 現在時刻の取得
current_time = pd.Timestamp.now()
# CPU使用率の取得
cpu_usage = get_cpu_usage()
# メモリ使用率の取得
memory_usage = get_memory_usage()
# 新しいデータを含むデータフレームを作成
new_row = pd.DataFrame({
"Time": [current_time],
"CPU Usage (%)": [cpu_usage],
"Memory Usage (%)": [memory_usage]
})
# データフレームに新しい行を追加
df = pd.concat([df, new_row], ignore_index=True)
# データフレームをExcelに保存
df.to_excel("usage_data.xlsx", index=False)
# 1分待機
time.sleep(10)
except KeyboardInterrupt:
print("プログラムが中断されました。")
if __name__ == "__main__":
main()
上記コードをローカルPCで実行するとusage_data.xlsxが自動生成されてCPUとメモリ使用率のデータががちゃんと記録されてました。
試しにグラフ化した結果

5.まとめ
※以下のまとめは生成AIによる自動生成された情報です。
- GPT-4oは、テキストと画像の両方を入力として受け取ることができる。
- Azure上でGPT-4oを利用可能だが、使用できるリージョンが限定されている。
- 実験では円グラフ、散布図、プログラムフロー図の3種類の画像を使用。
- GPT-4oは画像から情報を正確に抽出し、分析する能力を持つ。
- 生成されたコードにはライブラリの最新の変更点を反映する必要がある場合がある。
- GPT-4oの自動化と分析の応用が期待されるが、アップデートによる機能改善が必要。

アクセンチュア株式会社に所属する社員有志による運営です。アクセンチュアの社員による様々な発信をまとめています。なお、投稿内容は社員個人の見解であり、所属する組織を代表するものではありません。
Discussion