はじめに
SNSでInception LabsのMercury Coderが話題になっていたので、ChatGPTのDeepResearch等を使って調べてみました。
Mercuryは「Diffusion large language models」(以降、dLLMs)で、従来の「Transformer」に基づく仕組みのLLMとは異なるアプローチだそうです。
下記、池田朋弘さんの挙動比較のイメージがわかりやすいです。
また、実際の挙動は下記となります。生成スピードに驚きですし、見ていて面白い!
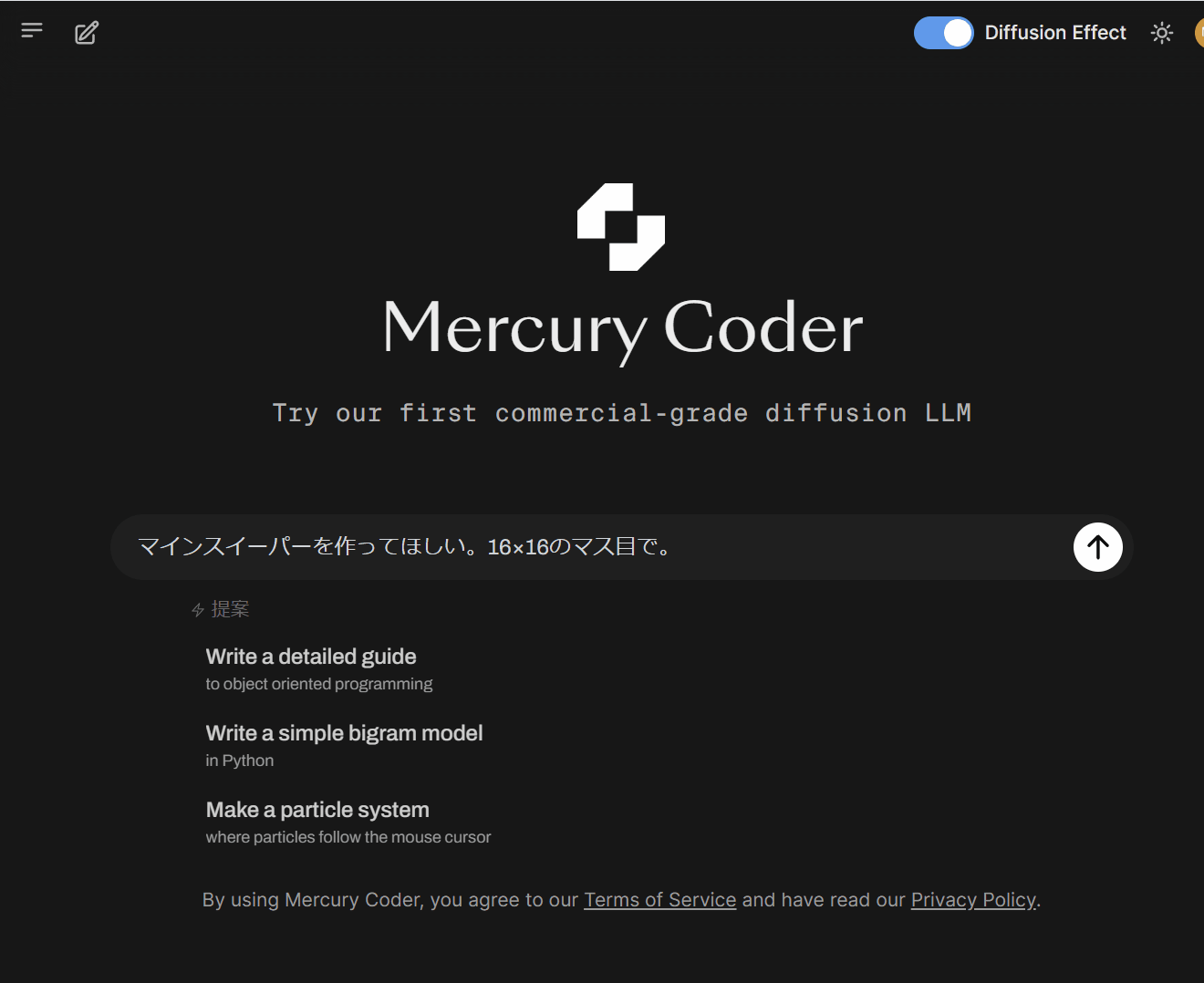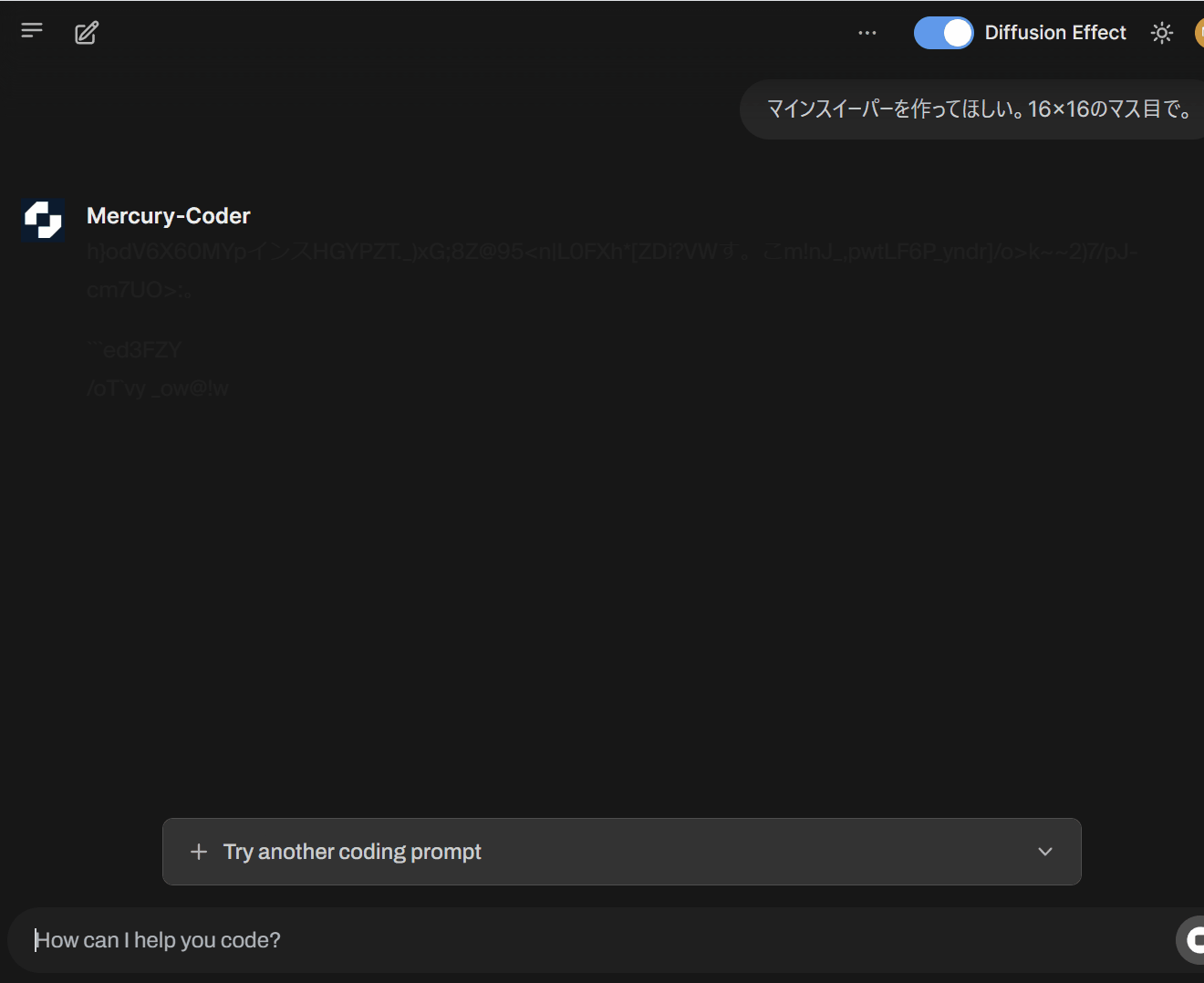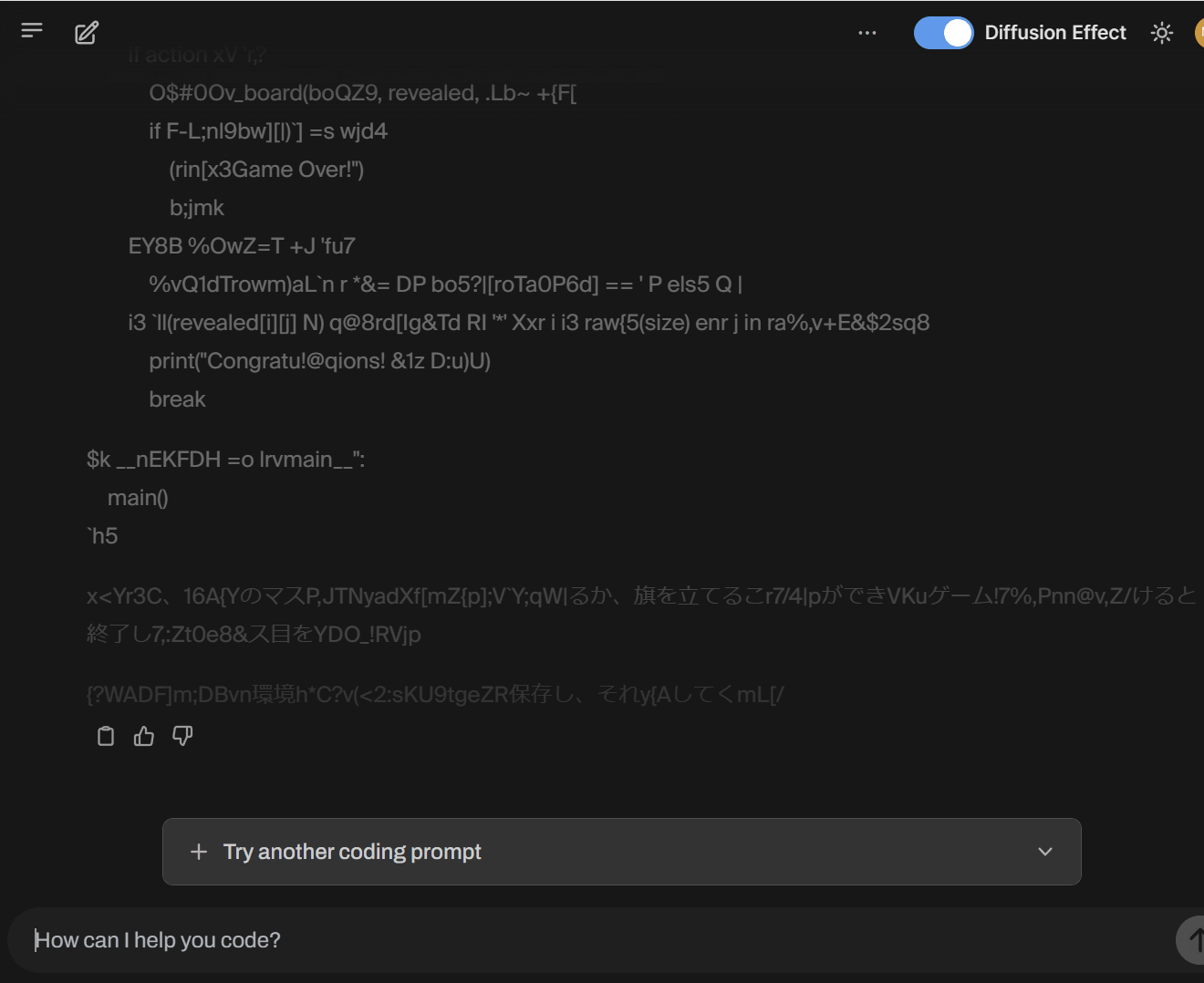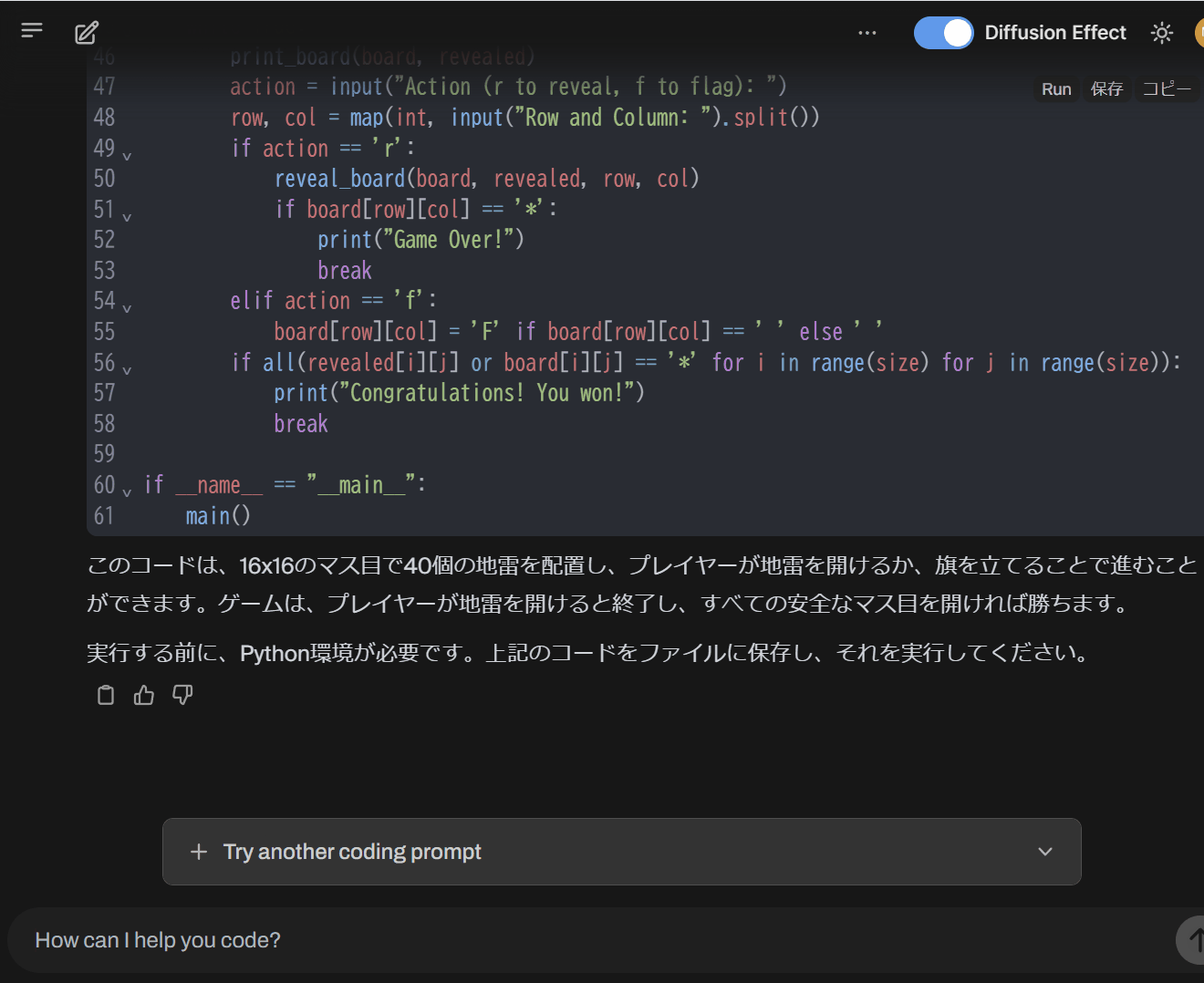
個人的には、このニュースを見て1990年代後半のJPEGで徐々に表示されるProgressive JPEGを思い出しました😄
概要
Mercury(マーキュリー) Coderは、スタンフォード大学の教授陣が中心となって立ち上げたスタートアップ企業Inception Labs(インセプション・ラボ)が、2025年2月に発表したDiffusion Modelをベースとした大規模言語モデル(LLM)です。従来はTransformer(トランスフォーマー)という仕組みに基づくモデルが主流でしたが、MercuryはdLLMsによって高速かつ高品質にテキストを生成する新しいアプローチを採用しています。
Inception Labsによると、MercuryはNVIDIA H100クラスのGPU上で1秒あたり1000トークン以上という高速なテキスト生成を実現し、GPT-4などのTransformer型モデルと比べて最大10倍速いと報じられています。また、コード生成に特化したMercury Coderが最初にリリースされ、高速なプログラミング支援能力を示して話題になりました。将来的にはチャット向けLLMも投入予定で、対話や長文生成を行うAIアシスタントとして幅広く応用される見込みです。
技術的特徴と仕組み
Diffusion Modelによるテキスト生成
Diffusion Modelでは、ノイズだらけの初期状態からスタートし、ノイズを少しずつ取り除きながら最終的な文書を洗練していきます。これをcoarse-to-fine 粗から細へという考え方で説明することが多く、「最初はぼんやりしたアイデアしかないけど、徐々に正しい単語を当てはめてはっきりとした文章にしていく」イメージです。
- 従来のTransformer型LLM:左から右へ文章を1単語ずつ予測し、次の単語を順番に決めていきます(自己回帰型生成)
- Mercury CodeのようなdLLMs:初めに文章全体の大まかな下書きを用意し、そこから全トークン(文の一部)を並列的に少しずつ修正しながら完成形に近づけていきます(非自己回帰型生成)
この手法のメリットは、文章の中盤や後半で矛盾が生じた場合にも後から修正しやすい点です。通常のTransformer型は「次の単語を確定すると、もう前に戻って書き換えができない」ことが多いのですが、Diffusion Modelは各ステップで全文を見直してノイズを消去するので、一貫性のある出力を得やすいとされています。
Diffusion Modelを実現するための工夫
画像などの連続的なデータではDiffusion Modelが成功を収めてきましたが、テキストのような離散的なデータではうまく動かない課題が長らく存在しました。Mercuryを開発したInception LabsはScore Entropyと呼ばれる新しい損失関数(学習のための数式)を考案し、この問題を突破しています。
この研究によって、従来は画像に比べて難しいとされたテキストの拡散生成が一気に実用レベルに近づき、GPT-2レベルの性能をScore Entropy Discrete Diffusion models(SEDD)で出すという学術的なブレークスルーが起こりました。Mercury Codeはその成果を商用向けに大規模化し、最適化した最初の例と言えます。
既存のLLM(Transformerベース等)との違い
テキスト生成プロセスの違い
- 従来: 左から右へ順番に単語を生成
- Mercury Code: 文章全体を一括で並列生成し、段階を追って洗練
誤り訂正のしやすさ
- Transformerベース: 一度確定した単語列を後から変更しにくい
- dLLMs: 途中で全文を見直し、矛盾や誤りを修正可能
生成速度(レイテンシ)の大幅な短縮
- 長文を出力するとき、自己回帰型ではステップが増え時間がかかる
- dLLMsでは決まった回数の「デノイズ(ノイズ除去)ステップ」を回すだけなので、文章が長くても比較的一定時間で生成できます
- Mercuryはこの仕組みを活かし、1秒間に1000トークン以上の出力速度を報告しています
ユースケース
コード自動生成:Mercury Coder
- Mercuryの最初の製品「Mercury Coder」は、プログラムコードを自動生成するのに特化したモデルです
- 既に公開デモが行われており、JavaScriptやPythonなど幅広い言語を高速かつ高精度で生成できると報告されています
- 従来の大規模モデル(例: GPT-4やClaudeなど)に負けない品質を、より短い推論時間で提供できる点が評価されています
今後の展望:チャットや文章生成
- 現在はコード向けが中心ですが、対話型チャットモデルのリリースも準備中
- クローズドβテスト段階で、企業へのAPI提供やオンプレミス(自社サーバー)導入などの導入形態も想定されています
- スマホやノートPC上でも動作が可能になるよう研究が進められており、将来的にはエッジデバイスで動く高度なAIアシスタントになる可能性も示唆されています
メリット・デメリット
メリット
高速なテキスト生成
- 1秒あたり1000トークン以上と、従来のモデルに比べて最大10倍の生成速度
- リアルタイム性が重要なチャットやコード補完で待ち時間を大幅に短縮できる
効率性&コスト削減
- 特別なハードウェアではなく汎用GPUで高速動作するため、推論コストが下がる
- 同じサーバー資源でより多くのユーザを同時に処理しやすい
応答の一貫性と訂正能力
- 文章全体を繰り返し見直すことで、途中の矛盾や誤りを後から修正しやすい
- 「最後まで読んだら辻褄が合う」長文生成が期待される
エッジデバイスでの動作
- 将来的にスマホやPC上で動かせる小型版モデルが開発される見通し
- ネット接続なしでも動くAIアシスタントなどが可能になるかもしれない
デメリット
新技術ゆえの未知数
- 世界初の大規模dLLMsであり、実運用例がまだ少ない
- 超大規模なタスクでの実力や、GPT-4クラスの汎用的な知能に肉薄できるかは現時点で未知
学習・開発の複雑さ
- Discrete Diffusion modelsは学習が難しく、特殊な損失関数や最適化が必要
- ノウハウが未成熟で、Transformer型よりも研究・調整に手間がかかる可能性がある
性能上限の検証不足
- コード生成で大きな成果を示しているが、常識推論や大規模知識が必要なタスクへの適用検証は進行中
- 高度な課題に挑戦する段階で、新たな欠点が見つかる可能性もある
おわりに
Mercury Codeは、Diffusion Modelで文章を生成するという新しいアプローチを、世界で初めて商用規模で実装した挑戦的なプロジェクトです。従来のTransformer型LLMにはない高速性や柔軟な訂正能力を武器に、コード生成やチャットアシスタントなど様々な分野に応用が期待されています。
一方で、まだ登場したばかりの技術であるため、本当にすべての分野で従来型LLMを置き換えられるのかや、大規模運用時の安定性・汎用性といった点は今後の課題でもあります。Inception LabsはDiffusion ModelがAIの新しい可能性を切り開くと強気に発信しており、多くの企業も採用を検討中とのこと。ぜひぜひdLLMsにも注目していきましょう!

アクセンチュア株式会社に所属する社員有志による運営です。アクセンチュアの社員による様々な発信をまとめています。なお、投稿内容は社員個人の見解であり、所属する組織を代表するものではありません。
Discussion