

DIFYをPython(WEBアプリ)から使ってみた
DIFYの存在は知っていましたが、なかなか手が出ず触っていなかったのですが、連休もあり時間がたっぷりとれたのでDIFY入門してみました。
DIFY自体の使い方はいろんな記事が出ているので、今回は、PythonからDIFY上で定義したワークフローを実行し、さらにそれをDjangoアプリケーションに統合することで、インプットとアウトプットのデザインをカスタマイズして、裏でDIFYのフローを実行できるようにしてみました。
Djangoアプリのデモ動画
1. DIFYフローの概要
まず、今回使用するDIFYのフローについて簡単に説明します。
今回は、ITシステム運用におけるインシデント対応時の過去インシデントの情報を分析するシナリオを想定した簡易的なフローを作成しました。

- 入力として「カテゴリ」「サブカテゴリ」「詳細情報」「質問内容」を受け取ります。
- 知識検索(Knowledge Retrieval)を使用して過去のインシデントチケット情報を取得(いわゆるRAG)します。
- GPT-4o-miniモデルを使用して、インシデントの分析と回答を生成します。
- 出力として、状況概要、類似過去インシデント、初期対応手順、考えられる原因、詳細な解決ステップ、参照した過去事例の情報を提供します。
下記リンクにインシデント分析.ymlがあるので、このファイルをDIFY上の「DSLファイルをインポート」からインポートしてもらえばすぐにフローを作成することができます。
※ナレッジは別途作成が必要
過去のインシデント情報は以下のテキスト情報(生成AIに作成してもらいました)をアップロードして知識取得で利用するようにします。
## 1. インフラストラクチャ関連
### サーバーダウン
インシデントID: INF-SD-001
発生日時: 2024-03-15 14:30 JST
影響範囲: 主要Webアプリケーションサーバー2台
原因: ハードウェア故障(RAIDコントローラー)
解決時間: 4時間
詳細:
主要Webアプリケーションサーバー2台が突然ダウンし、サービスが完全に停止。監視システムからアラートを受信後、即座に調査を開始。ハードウェア診断の結果、RAIDコントローラーの故障が判明。
解決策:
1. 冗長化されたバックアップサーバーへトラフィックを切り替え
2. 故障したRAIDコントローラーを交換
3. OSとアプリケーションの再起動、動作確認
4. 正常性確認後、元のサーバーへトラフィックを戻す
学習点:
- ハードウェア冗長化の重要性
- 迅速なフェイルオーバー手順の確立
- 定期的なハードウェア診断の実施
### ネットワーク障害
インシデントID: INF-ND-002
発生日時: 2024-04-02 09:15 JST
影響範囲: データセンター内の全サーバー
原因: コアスイッチの設定ミス
解決時間: 2時間30分
詳細:
データセンター内の全サーバーへの接続が突然失われ、外部からのアクセスが不可能になった。調査の結果、ネットワークチームが行った直前のコアスイッチ設定変更が原因と判明。
解決策:
1. コアスイッチの設定を前回の正常動作時の状態にロールバック
2. ネットワーク接続の復旧を確認
3. 各サーバーの接続状態と機能を順次確認
4. 問題のあった設定変更を修正して再適用
学習点:
- 重要な設定変更前のバックアップと検証環境でのテストの徹底
- 変更管理プロセスの見直しと承認フローの強化
- ネットワーク構成図と設定ドキュメントの最新化
### ストレージ障害
インシデントID: INF-ST-003
発生日時: 2024-05-10 23:45 JST
影響範囲: 主要データベースサーバーのストレージシステム
原因: ストレージアレイのファームウェアバグ
解決時間: 6時間
詳細:
深夜にストレージシステムが突然応答しなくなり、主要データベースサーバーがデータにアクセスできなくなった。調査の結果、最近適用したファームウェアアップデートに含まれるバグが原因と判明。
解決策:
1. ストレージベンダーのサポートチームと協力して緊急パッチを適用
2. ストレージシステムの再起動と正常性確認
3. データベースサーバーの再起動とデータ整合性チェック
4. バックアップからの部分リストアによるデータ復旧
学習点:
- クリティカルシステムへのファームウェアアップデート前の十分なテストと検証
- 複数のストレージシステム間でのデータレプリケーション導入の検討
- 24時間体制のモニタリングと迅速な障害対応プロセスの確立
---
## 2. アプリケーション関連
### アプリケーションクラッシュ
インシデントID: APP-CR-001
発生日時: 2024-06-20 13:00 JST
影響範囲: 顧客向けWebアプリケーション全体
原因: メモリリーク
解決時間: 3時間
詳細:
ピーク時間帯に顧客向けWebアプリケーションが突然クラッシュ。再起動後も短時間で再発。調査の結果、最新のアップデートで導入された新機能にメモリリークが存在することが判明。
解決策:
1. 問題の新機能を一時的に無効化
2. アプリケーションサーバーの再起動とメモリ使用量の監視強化
3. 開発チームによるコードレビューとメモリリークの修正
4. ホットフィックスの適用と段階的な新機能の再有効化
学習点:
- 本番環境へのデプロイ前の徹底的な負荷テストとメモリプロファイリング
- 段階的なロールアウトとモニタリング強化の重要性
- 緊急時の機能切り戻しプロセスの確立
### パフォーマンス低下
インシデントID: APP-PF-002
発生日時: 2024-07-05 10:30 JST
影響範囲: 社内業務システム全般
原因: データベースクエリの非効率性
解決時間: 5時間
詳細:
朝のピーク時間帯に社内業務システム全体の応答が極端に遅くなり、一部のユーザーがタイムアウトエラーを経験。調査の結果、最近のアップデートで導入された新しいレポート機能が非効率なクエリを大量に発行していることが判明。
解決策:
1. 問題のレポート機能を一時的に無効化
2. データベース管理者と開発チームによるクエリの最適化
3. インデックスの追加とクエリプランの調整
4. 最適化されたクエリの段階的な再導入と性能モニタリング
学習点:
- 大規模データ処理を伴う新機能導入時の事前性能テストの重要性
- データベースクエリの定期的な監査と最適化プロセスの確立
- アプリケーションとデータベースの連携を考慮した開発プラクティスの強化
### 機能障害
インシデントID: APP-FN-003
発生日時: 2024-08-12 15:45 JST
影響範囲: オンライン決済システム
原因: サードパーティAPI連携の不具合
解決時間: 4時間
詳細:
オンライン決済システムで特定の決済方法が突然利用できなくなった。調査の結果、決済プロバイダのAPIに変更が加えられたが、アプリケーション側の更新が行われていなかったことが判明。
解決策:
1. 影響を受ける決済方法を一時的に無効化し、代替手段を案内
2. APIの変更に対応するためのコード修正を緊急で実施
3. テスト環境での検証後、修正をプロダクション環境に適用
4. 決済機能の段階的な再有効化と取引の監視
学習点:
- サードパーティAPIの変更通知を確実に受け取り、対応するプロセスの確立
- 重要な外部連携に対する定期的な健全性チェックの実施
- 障害時の代替手段や縮退運転モードの事前準備の重要性
---
## 3. データベース関連
### データベースサーバーダウン
インシデントID: DB-SD-001
発生日時: 2024-09-03 08:00 JST
影響範囲: 主要顧客データベース
原因: ディスク容量の枯渇
解決時間: 3時間
詳細:
朝の業務開始時に主要顧客データベースへの接続が不可能になった。調査の結果、予期せぬログファイルの急激な増大によりディスク容量が枯渇し、データベースサーバーがシャットダウンしたことが判明。
解決策:
1. 不要なログファイルの緊急削除によるディスク容量の確保
2. データベースサーバーの再起動と整合性チェック
3. ログローテーション設定の見直しと自動アーカイブプロセスの導入
4. ディスク使用量の監視強化とアラートしきい値の調整
学習点:
- ディスク使用量の予測と自動スケーリングメカニズムの導入
- クリティカルシステムにおける24時間監視体制の強化
- 定期的なログ管理とクリーンアッププロセスの確立
### クエリパフォーマンス低下
インシデントID: DB-QP-002
発生日時: 2024-10-15 14:20 JST
影響範囲: 分析レポートシステム
原因: インデックスの欠如と統計情報の古さ
解決時間: 4時間
詳細:
定期的な分析レポートの生成時間が通常の10倍以上に増加。ユーザーからの苦情が多数寄せられる。調査の結果、最近のデータ構造変更後にインデックスが適切に更新されておらず、また統計情報が古いままであることが判明。
解決策:
1. クリティカルなクエリに対する適切なインデックスの緊急作成
2. データベース統計情報の強制更新
3. 問題のあるクエリの最適化と実行計画の見直し
4. パフォーマンス改善後の段階的なレポート再生成
学習点:
- データ構造変更時のインデックス戦略の見直しプロセスの確立
- 定期的な統計情報更新ジョブの導入
- クエリパフォーマンスの継続的なモニタリングとアラート設定
### データ破損
インシデントID: DB-DC-003
発生日時: 2024-11-22 19:30 JST
影響範囲: 財務データベース
原因: ストレージサブシステムの一時的な障害
解決時間: 8時間
詳細:
夜間バッチ処理中に財務データベースの一部テーブルでデータ破損が発生。朝の業務開始時に異常が発覚。調査の結果、ストレージサブシステムの一時的な障害が原因で、書き込み操作の一部が失敗していたことが判明。
解決策:
1. 破損したテーブルの特定と影響範囲の確認
2. 前日のバックアップからの部分リストア
3. トランザクションログを使用した破損発生時点までのリカバリ
4. データの整合性チェックと修復
学習点:
- よりきめ細かいバックアップスケジュールの導入(特に重要データ)
- ストレージシステムの冗長化とフェイルオーバーメカニズムの強化
- データ破損を早期に検出するための定期的な整合性チェックプロセスの確立
フローの設定概要
開始ブロック
入力フィールドに以下を設定
category(カテゴリ)
subcategory(サブカテゴリ)
details(詳細内容)
query(質問内容)

知識取得
事前にアップロードしたインシデント情報を指定

LLMブロック
gpt-4o-miniを指定し、以下のプロンプトを設定する。

終了ブロック
LLMの出力(text)を設定する。

2. PythonからDIFYフローを実行する
事前に、DIFY上でAPIキーを発行しておきます。
APIキーはフロー毎に発行する必要があるようです。
フローを実行する際にフローIDなどを指定する必要がなくAPIキーとエンドポイント(https://api.dify.ai/v1) だけ指定すればフローを実行できるようになっています。
※フロー毎にAPIキーを用意する必要があるようなので、そこはちょっと管理がめんどくさい印象を受けました。
以下は、Pythonコードから上記で作成したDIFYフローを実行するサンプルコードです。
APIキーの部分はご自身の情報に置き換えてください。
※以下のコードはDIFY上のAPIリファレンス情報をClaudeに投げて自動生成してもらいました。
import requests
import time
import json
import logging
# ロギングの設定
logging.basicConfig(level=logging.DEBUG, format='%(asctime)s - %(levelname)s - %(message)s')
API_KEY = "DIFY上で発行したAPIキーを設定"
BASE_URL = "https://api.dify.ai/v1"
HEADERS = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
def run_workflow(inputs, user_id):
url = f"{BASE_URL}/workflows/run"
payload = {
"inputs": inputs,
"response_mode": "blocking",
"user": user_id
}
logging.debug(f"Request URL: {url}")
logging.debug(f"Request Headers: {json.dumps(HEADERS, indent=2)}")
logging.debug(f"Request Payload: {json.dumps(payload, indent=2)}")
try:
response = requests.post(url, headers=HEADERS, json=payload)
logging.debug(f"Response Status Code: {response.status_code}")
logging.debug(f"Response Headers: {json.dumps(dict(response.headers), indent=2)}")
logging.debug(f"Response Content: {response.text}")
response.raise_for_status()
result = response.json()
return result.get('workflow_run_id'), result.get('task_id')
except requests.RequestException as e:
logging.error(f"Error running workflow: {e}")
if hasattr(e, 'response'):
logging.error(f"Response Status Code: {e.response.status_code}")
logging.error(f"Response Content: {e.response.text}")
return None
def get_workflow_result(workflow_run_id):
url = f"{BASE_URL}/workflows/run/{workflow_run_id}"
logging.debug(f"Request URL: {url}")
logging.debug(f"Request Headers: {json.dumps(HEADERS, indent=2)}")
try:
response = requests.get(url, headers=HEADERS)
logging.debug(f"Response Status Code: {response.status_code}")
logging.debug(f"Response Headers: {json.dumps(dict(response.headers), indent=2)}")
logging.debug(f"Response Content: {response.text}")
response.raise_for_status()
return response.json()
except requests.RequestException as e:
logging.error(f"Error getting workflow result: {e}")
if hasattr(e, 'response'):
logging.error(f"Response Status Code: {e.response.status_code}")
logging.error(f"Response Content: {e.response.text}")
return None
if __name__ == "__main__":
user_inputs = {
"category": "接続障害",
"subcategory": "財務データベースへの接続",
"details": "財務データベースへの接続が不可能",
"query": "何が原因か知りたい。過去に類似障害があればそれも知りたい。",
}
user_id = "batch_user"
result = run_workflow(user_inputs, user_id)
if result:
workflow_run_id, _ = result
for _ in range(10):
time.sleep(5)
workflow_result = get_workflow_result(workflow_run_id)
if workflow_result:
status = workflow_result.get('status')
logging.info(f"ワークフローの状態: {status}")
if status == 'succeeded':
logging.info("ワークフローが正常に完了しました。")
outputs = workflow_result.get('outputs')
if isinstance(outputs, str):
try:
outputs_dict = json.loads(outputs)
text_output = outputs_dict.get('text', '')
except json.JSONDecodeError:
text_output = outputs
elif isinstance(outputs, dict):
text_output = outputs.get('text', '')
else:
text_output = str(outputs)
logging.info(f"出力テキスト: {text_output}")
break
elif status in ['failed', 'stopped']:
logging.error(f"ワークフローが{status}しました。エラー: {workflow_result.get('error')}")
break
else:
logging.warning("ワークフローが予想時間内に完了しませんでした。")
else:
logging.error("ワークフローの開始に失敗しました。")
ポイント解説
- フローを実行するエンドポイント:
def run_workflow(inputs, user_id):
url = f"{BASE_URL}/workflows/run"
payload = {
"inputs": inputs,
"response_mode": "blocking",
"user": user_id
}
response = requests.post(url, headers=HEADERS, json=payload)
# ...
このエンドポイント (/workflows/run) は、フローを実行するために使用されます。
- HTTPメソッド: POST
- URL:
https://api.dify.ai/v1/workflows/run - ペイロード:
-
inputs: フローに渡す入力データ -
response_mode: "blocking"に設定(同期的な応答を要求) -
user: ユーザーID(任意の名称を指定)
-
このエンドポイントは、フローの実行を開始し、実行IDとタスクIDを返します。
- フローの情報を取得するエンドポイント:
def get_workflow_result(workflow_run_id):
url = f"{BASE_URL}/workflows/run/{workflow_run_id}"
response = requests.get(url, headers=HEADERS)
# ...
このエンドポイント (/workflows/run/{workflow_run_id}) は、実行中または完了したフローの状態と結果を取得するために使用されます。
- HTTPメソッド: GET
- URL:
https://api.dify.ai/v1/workflows/run/{workflow_run_id} - URLパラメータ:
-
workflow_run_id: 確認したいフロー実行のID
-
このエンドポイントは、フローの現在の状態(実行中、完了、失敗など)と、完了している場合はその結果を返します。
これらのエンドポイントを使用することで、フローを非同期で実行し、その進行状況や結果を定期的に確認することができます。メインの処理部分では、run_workflowでフローを開始し、その後get_workflow_resultを繰り返し呼び出して完了を待ち、結果を取得しています。
このコードを以下の様に実行すると事前に定義したインシデント分析フローを実行し、処理結果を表示することができます。
python sample.py
実行結果例
DIFYのフローを正しく実行できれば、以下の様にLLMブロックで指定した出力フォーマット(Markdown形式)の結果が返ってきます。
2024-09-23 15:45:04,048 - INFO - ワークフローの状態: succeeded
2024-09-23 15:45:04,063 - INFO - ワークフローが正常に完了しました。
2024-09-23 15:45:04,063 - INFO - 出力テキスト: ## 状況概要
現在、財務データベースへの接続が不可能な状況が発生しています。ユーザーからの報告により、業務に支 障をきたしているため、早急な原因特定と解決が求められています。
## 類似過去インシデント(概要と解決策)
1. **インシデントID: DB-DC-003**
- **発生日時:** 2024-11-22 19:30 JST
- **影響範囲:** 財務データベース
- **原因:** ストレージサブシステムの一時的な障害
- **解決策:**
1. 破損したテーブルの特定と影響範囲の確認
2. 前日のバックアップからの部分リストア
3. トランザクションログを使用したリカバリ
4. データの整合性チェックと修復
## 初期対応手順
1. **接続状況の確認**: 財務データベースへの接続が本当に不可能か、他のクライアントからの接続状況も確認する。
2. **ログの確認**: データベースのエラーログ、接続ログを確認し、エラーメッセージや異常が発生していないかを調査する。
3. **リソースモニタリング**: サーバーのCPU、メモリ、ストレージの使用状況を監視し、リソースが枯渇 していないか確認する。
## 考えられる原因
- **ストレージ障害**: 過去のインシデントから、ストレージサブシステムの問題が接続障害の一因となっ ている可能性があります。
- **データベースの設定ミス**: 設定変更やアップデート後に接続設定が誤っている場合。
- **ネットワーク障害**: サーバーとクライアント間のネットワークに問題がある場合。
- **データベースの過負荷**: 同時接続数が限界を超えている場合。
## 詳細な解決ステップ
1. **ストレージの健全性チェック**:
- ストレージサブシステムの状態を確認し、障害が発生していないかを調査。
- 必要に応じて、ストレージの再起動や、冗長化された構成への切り替えを実施。
2. **データベースのリスタート**:
- データベースサービスを再起動して、接続状況が改善されるかを確認。
3. **バックアップからのリカバリ**:
- もしデータベースのデータ破損が疑われる場合、前日のバックアップからリカバリを実施。
4. **ネットワークのトラブルシューティング**:
- ネットワーク接続の確認を行い、ファイアウォールやルーターの設定をチェックする。
5. **パフォーマンスモニタリング**:
- データベースのパフォーマンスを監視し、必要に応じて、リソースのスケーリングや最適化を行う。
## 参照した過去事例のインシデント情報
### データ破損
インシデントID: DB-DC-003
発生日時: 2024-11-22 19:30 JST
影響範囲: 財務データベース
原因: ストレージサブシステムの一時的な障害
解決時間: 8時間
詳細:
夜間バッチ処理中に財務データベースの一部テーブルでデータ破損が発生。朝の業務開始時に異常が発覚。 調査の結果、ストレージサブシステムの一時的な障害が原因で、書き込み操作の一部が失敗していたことが 判明。
解決策:
1. 破損したテーブルの特定と影響範囲の確認
2. 前日のバックアップからの部分リストア
3. トランザクションログを使用した破損発生時点までのリカバリ
4. データの整合性チェックと修復
学習点:
- よりきめ細かいバックアップスケジュールの導入(特に重要データ)
- ストレージシステムの冗長化とフェイルオーバーメカニズムの強化
- データ破損を早期に検出するための定期的な整合性チェックプロセスの確立
3. Djangoアプリケーションへの統合
最後に、上記のPythonスクリプトをDjangoアプリケーションに組み込んで、インプットとアウトプットのデザインを下図のようにカスタマイズしてみました。
DIFYの画面

Djangoアプリ画面
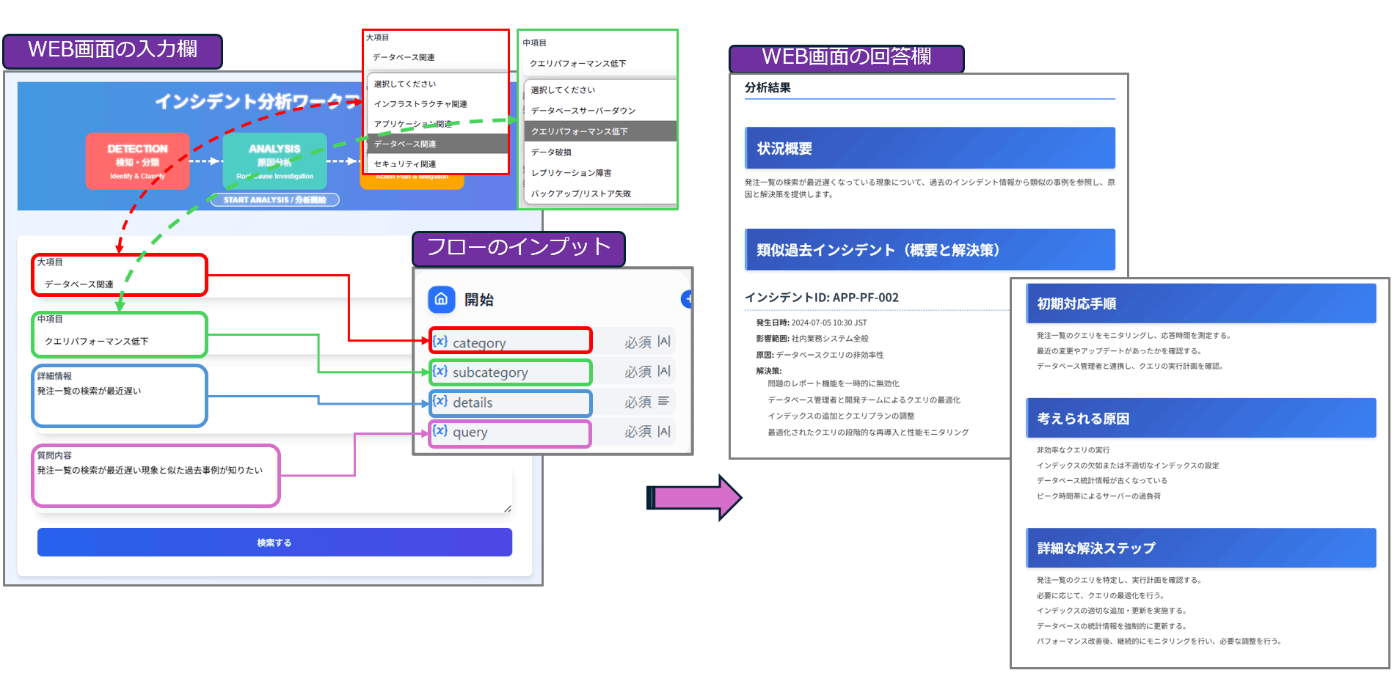
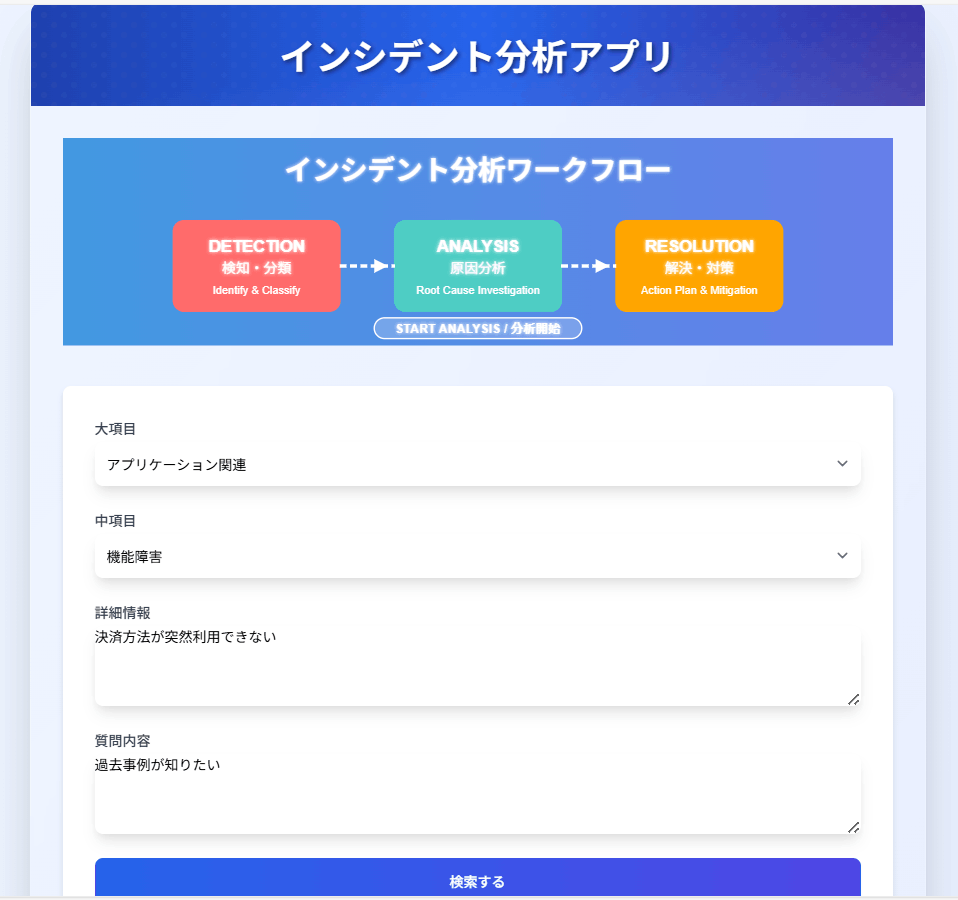
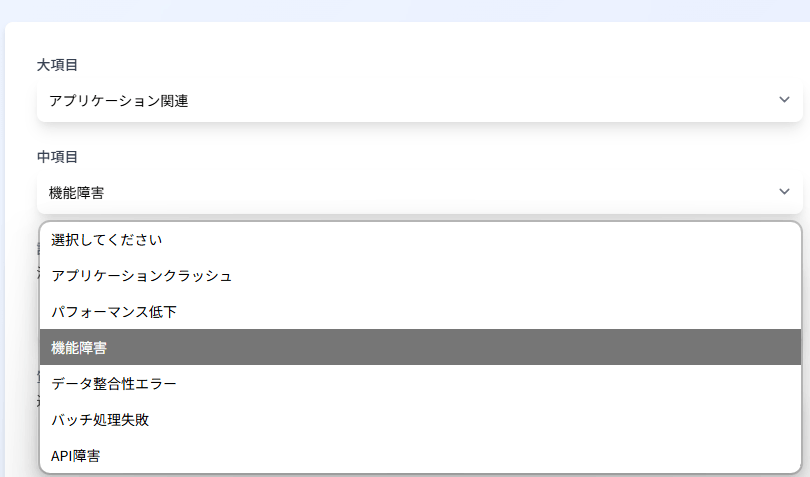
大項目(category)、中項目(subcategory)は画面上でリスト形式で簡単に選択できるようにしてみました。
※大項目を選択すると関連する中項目だけがリスト表示される。
分析結果画面は、DIFYのフローが出力したMarkdown形式のデータを視覚的に見やすいデザイン(下図)で表示されるようにしています。

今回試作した上記のDjangoアプリのコードは以下にありますので、興味がある方は実装してみてください。
感想とまとめ
今回は、DIFYのワークフローをPythonから実行し、それをDjangoアプリケーションに統合する方法を紹介しました。
WEBアプリからDIFYのフローを実行するのは比較的簡単に実装できることがわかりました。
以下のような役割分担をすることで、効率よく複雑なロジックを含む生成AIを組み込んだアプリが作れると感じました。
✅複雑な分岐を含む生成AIを組み込んだフローはDIFYにお任せ
✅フロントエンドをDjango等で作り込む(インプット、アプトプットを自由にカスタマイズ)

アクセンチュア株式会社に所属する社員有志による運営です。アクセンチュアの社員による様々な発信をまとめています。なお、投稿内容は社員個人の見解であり、所属する組織を代表するものではありません。
Discussion