1. はじめに
Anthropic提唱のContextual Retrievalは、従来のRAG(Retrieval Augmented Generation)が抱える文脈の理解不足や情報の断片化といった課題を解決するための新たな手法です。
この手法は、特に指示語の多い文章に対する正確な回答生成を目指します。
2. 結論(精度)
いきなり結論になりますが、Anthropic公式によると、下図のようにContextual Retrievalを用いたRAGの精度(failure rate)が5.7% → 1.9%に改善されると発表されています。(BM25やRerankeも併用)

3. RAGの課題
従来のRAGは、外部データベースや知識ベースを参照して生成モデルが回答を出すアプローチですが、次のような課題がありました。
-
断片化の問題
- 情報が複数の断片(チャンク)に分割されて検索されるため、文脈が損なわれやすい。
- 複数の情報を統合する際に、情報の意味が切断されてしまい、回答が本来の意図とずれる可能性がある。
-
文脈の欠如
- 各チャンクが独立して処理されるため、文脈の繋がりが保たれず、結果として回答が文脈から逸脱することが多い。
- 指示代名詞や代名詞を含む質問において、参照先が不明確になり、誤った回答が生成されるリスクがある。
-
誤解や誤回答の発生
- 特に複雑な質問や長い質問に対して、情報が適切に整理されないため、誤解を招く回答が生じやすい。
- 情報が断片化されてしまうことで、複雑な質問に対して正確な回答を生成する能力が限られている。
4. Contextual Retrievalのアプローチ
Contextual Retrievalは、上記の課題を解決するための手法で、以下のような特徴を持ちます。
-
文脈情報の付与と保持
- 検索した情報に対して文脈を補完し、情報の断片化による意味の損失を防ぐ。
- 断片的な情報でも、その背景となる文脈情報が一貫して保持されるよう工夫されており、文脈を意識した応答生成が可能。
- 各チャンクが独立しているRAGとは異なり、複数の情報断片が連携して一貫性を保つよう設計されている。
-
相互参照の保持
- 質問内に含まれる指示代名詞や代名詞が指す先が明確になるよう、情報の一貫性を保持。
- 長文や指示代名詞が多用された質問でも、各情報断片が適切に相互参照されるよう工夫。
- これにより、代名詞が何を指しているのかが明確になり、文脈に沿った回答が可能となる。
-
検索結果の統合と連携強化
- 複数の情報断片が単一の文脈に統合され、全体としての意味が失われないようになっている。
- これにより、複雑な質問や複数の参照先がある質問に対しても、回答が自然で一貫した流れを持つようになる。
-
具体例
-
各チャンクに対し文脈情報を付加します。以下の太字がContextual Retrievalにより付加される文脈情報の例です。(Anthropic公式の例を一部アレンジ)
-
チャンク1:
「ACME社の2023年第2四半期の業績に関する書類がSECから提出されました。売上高は~ 、営業利益は~でした。 この会社は、2023年第2四半期の業績を発表しました。売上高は前年同期比10%増でした。」
⇒太字の文脈情報がないと「ACME社の業績を教えてください」の質問に答えられない(ACME社?)
-
チャンク2:
「ACME社の2023年第2四半期の業績に関する書類がSECから提出されました。売上高は~ 、営業利益は~でした。 前四半期と比較して、この会社の収益は3%増加しました。」
⇒太字の文脈情報がないと「ACME社の業績を教えてください」の質問に答えられない(ACME社?)
-
チャンク3:
「ACME社の2023年第2四半期の業績に関する書類がSECから提出されました。売上高は~ 、営業利益は~でした。 これは、新製品の販売が好調だったことによるものです。」
⇒太字の文脈情報がないと「新製品の販売が好調だった会社を教えてください」の質問に答えられない(新製品の販売が好調だった会社?)
-
-
このように、各チャンクが同じ文脈情報(例えば「2023年第2四半期の業績」や「SEC提出書類からのもの」など)を保持することで、回答においても一貫した文脈が維持されます。この方法により、指示語を含むチャンクに対しても適切に回答ができるようになります。
5. Contextual Retrievalの利点
Contextual Retrievalの導入により、従来のRAGと比較して精度が向上し、次のような利点が得られます。
-
複雑な質問への対応力向上
- 文脈依存の高い複雑な質問や長文の質問にも適切に対応できる。
- 情報が適切に統合され、文脈に沿った回答が生成されるため、精度が向上。
-
指示代名詞や代名詞の適切な理解
- 質問文中の代名詞がどの情報を指しているかを正確に理解できるようになり、文脈の一貫性が保持される。
- これにより、情報が分断されている場合でも、誤解や誤回答のリスクが低減。
-
自然で一貫した回答生成
- 各チャンクが統合されて処理されるため、断片的な情報の一貫性が保たれ、流れのある回答が可能に。
- これにより、ユーザーにとってより自然で分かりやすい回答が得られる。
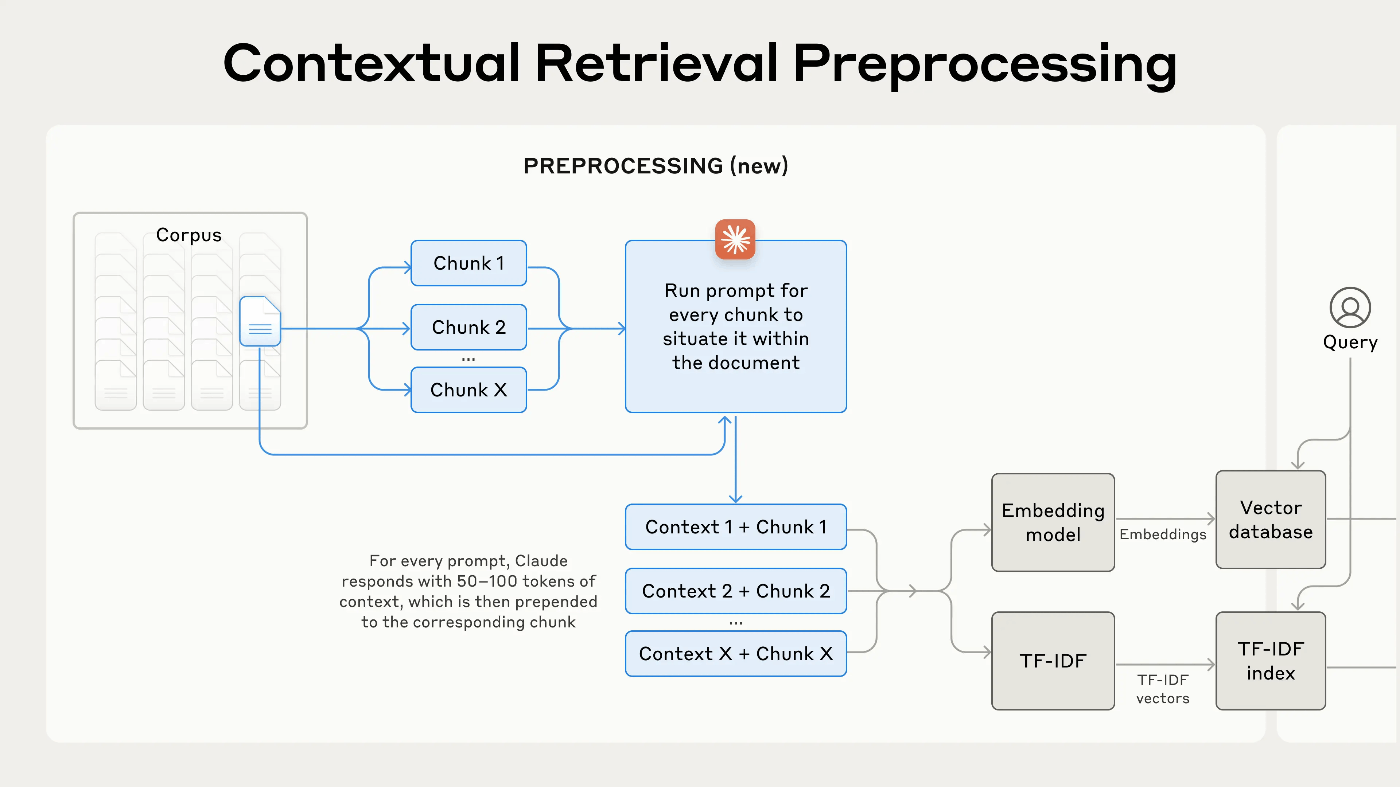
6. Contextual Retrievalの実装イメージ
LLMにより、以下のプロンプトで各チャンクに付加する文脈情報を生成します。
<document>
{{WHOLE_DOCUMENT}}
</document>
Here is the chunk we want to situate within the whole document
<chunk>
{{CHUNK_CONTENT}}
</chunk>
Please give a short succinct context to situate this chunk within the overall document for the purposes of improving search retrieval of the chunk. Answer only with the succinct context and nothing else.
各チャンクに付加する文脈情報は、下図の Context 1、Context 2、… Context X になります。
7. おわりに
Anthropic提唱のContextual Retrievalは、従来のRAGの課題を克服し、文脈を保持しながら正確で自然な回答を生成する手法として注目されています。この手法により、複雑な質問や長文の質問にも適切に対応し、情報の断片化による意味の損失を防ぎます。
次回は、Contextual Retrievalによる文脈情報生成のコストについて深掘りしていけたらと思います。

アクセンチュア株式会社に所属する社員有志による運営です。アクセンチュアの社員による様々な発信をまとめています。なお、投稿内容は社員個人の見解であり、所属する組織を代表するものではありません。
Discussion