はじめに
生成AIの回答精度を上げる方法をインターネットで調べると様々でてきます。
まずアクセンチュアの最近の記事にも記載されています。
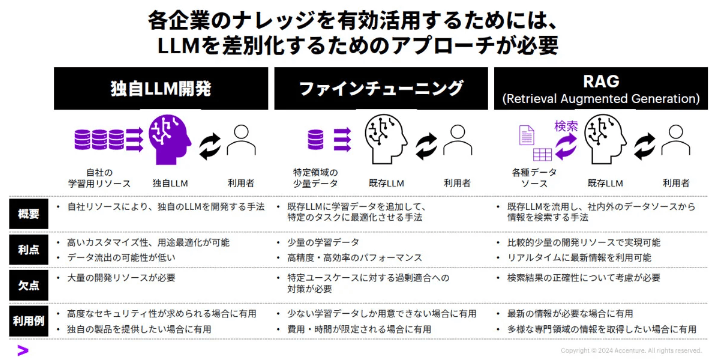
上記を見ると、「独自のLLM構築」「ファインチューニング」「RAG」の3パターンがあげられています。
要件により応えていくには、「独自のLLM構築」が一番良いと考えられますが、時間もお金も掛りかなりハードルが高いアプローチと考えています。
一方で、「ファインチューニング」「RAG」はGPT-4oなどのLLMを利用しながらチューニングするアプローチとなります。
アクセンチュアの資料には記載がなかったですが、上記に加えて「プロンプト」を工夫するというアプローチもあると考えています。
それでは、「プロンプト」「RAG」「ファインチューニング」の違いや、メリット/デメリットを見ていきましょう。
Geminiに聞いてみる
Geminiに聞いたところ下記回答でした。
1. プロンプト
概要: 生成AIに指示を与えるための文章のこと。質問や指示を具体的に記述することで、AIが適切な回答を生成できるようにします。
特徴:
柔軟性: さまざまな質問や指示に対応できます。
手軽さ: 別途設定や学習が不要で、すぐに利用できます。
メリット:
ユーザーの意図を反映しやすい: 適切なプロンプトを作成することで、ユーザーが求める回答を得やすくなります。
迅速な回答生成: 学習や設定が不要なため、すぐに回答を得られます。
デメリット:
プロンプト作成が難しい: 適切なプロンプトを作成するには、AIの挙動を理解する必要があり、初心者には難しい場合があります。
精度の限界: プロンプトの質によって回答の精度が大きく左右されます。
チューニングポイント:
ステップ1: 画面から質問送信: ユーザーが送信した質問がプロンプトとして扱われます。
ステップ2: LLMが回答生成: LLMはプロンプトに基づいて回答を生成します。
例:
プロンプト: 「東京でおすすめのラーメン屋を教えてください。」
回答: 「東京でおすすめのラーメン屋は、〇〇ラーメン、△△ラーメン、□□ラーメンなどがあります。〇〇ラーメンは、豚骨スープが濃厚で、△△ラーメンは、あっさり醤油スープが特徴です。」
2. RAG (Retrieval-Augmented Generation)
概要: 生成AIが外部の知識ベースから必要な情報を検索し、その情報に基づいて回答を生成する手法です。
特徴:
情報に基づいた回答: 知識ベースの情報を利用することで、より正確で信頼性の高い回答を生成できます。
最新の情報を反映可能: 知識ベースを更新することで、最新の情報を反映した回答を生成できます。
メリット:
回答の精度向上: 知識ベースの情報を利用することで、回答の精度が向上します。
最新情報の活用: 知識ベースを最新の状態に保つことで、最新の情報を反映した回答を生成できます。
デメリット:
知識ベースの作成・管理が複雑: 知識ベースの作成・管理には、専門的な知識や労力が必要となります。
知識ベースの偏り: 知識ベースの偏りによって、回答に偏りが生じる可能性があります。
チューニングポイント:
ステップ2: LLMが回答生成: LLMはRAGを用いて、知識ベースから関連する情報を検索し、その情報に基づいて回答を生成します。
例:
質問: 「地球温暖化の原因は何ですか?」
RAG: 地球温暖化に関する学術論文やレポートを検索し、その情報を元に回答を生成します。
回答: 「地球温暖化の原因は、人間の活動によって排出される温室効果ガスによるものです。温室効果ガスには、二酸化炭素、メタン、フロンなどがあります。」
3. ファインチューニング
概要: 特定のタスクやデータセットに合わせて、生成AIモデルを再学習する手法です。
特徴:
高い専門性: 特定のタスクに特化したモデルを作成することで、より専門性の高い回答を生成できます。
データ依存性: 特定のデータセットで学習するため、データの質や量によってモデルの性能が大きく左右されます。
メリット:
タスクに特化した回答: 特定のタスクに最適化されたモデルは、より適切な回答を生成できます。
精度の向上: 特定のデータセットで学習することで、回答の精度を向上させることができます。
デメリット:
学習コストが高い: ファインチューニングには、大量のデータと計算資源が必要となります。
汎用性の低下: 特定のタスクに特化するため、他のタスクへの応用が難しくなる場合があります。
チューニングポイント:
ステップ2: LLMが回答生成: ファインチューニングされたLLMは、学習したデータに基づいて回答を生成します。
例:
タスク: 医療文書の要約
ファインチューニング: 医療文書のデータセットを用いて、生成AIモデルを再学習
回答: 医療文書の内容を正確に要約した文章を生成します。
まとめ
プロンプト、RAG、ファインチューニングは、それぞれ異なるアプローチで生成AIの回答生成をチューニングします。
プロンプト: 質問や指示を調整することで、ユーザーの意図を反映した回答を得られます。
RAG: 知識ベースを活用することで、より正確で信頼性の高い回答を生成できます。
ファインチューニング: 特定のタスクに特化することで、より専門性の高い回答を生成できます。
これらのテクニックを組み合わせることで、より精度の高い回答を生成できるようになります。
さいごに
いかがでしたでしょうか。次回「プロンプト」「RAG」「ファインチューニング」についてもう少し見て行こうと思います!

アクセンチュア株式会社に所属する社員有志による運営です。アクセンチュアの社員による様々な発信をまとめています。なお、投稿内容は社員個人の見解であり、所属する組織を代表するものではありません。
Discussion