はじめに
おれの名前は樋口恭介。Phi-3というMicrosoftから2024年4月23日にリリースされた小規模LLMが、ギリCPUでも動くうえにGPT-3.5よりも精度が高いということで、触ってみることにした。
まずはGoogle Colab上でCPUを選択し、動きを確認したところ、通常モデルでも20分~30分程度で、かなり精度が高い回答が得られ、4bit量子化モデルだと、2分~3分程度で、それなりの出力が得られることがわかった。
そこで、気分がもりあがってきたので、自身のローカルPC(Windows11、GPUなし、メモリ16GB)でも動かしてみることにした。以下はそのときの試行錯誤のメモである(ほぼ趣味の領域の活動だが、業務時間中に行ったので、こうしてちゃんと会社のブログで手順をまとめているというわけだ)。
何も考えずにやるとけっこうハマりポイントが多かった気がするので、ぜひ参考にしていただきたい。
手順
まずは以下の記事を参照。基本の考え方のすべてはここにある。Llama.cppを使わないとLLMはCPUオンリーのローカルマシンでは動かない! Llama.cppをインストール。
しかし、初心者がいきなりふつうに「pip install llama-cpp-python」を実行すると、「ERROR: Could not build wheels for llama-cpp-python, which is required to install pyproject.toml-based projects」というエラーが出るので、エラー内容でググり、出てくる以下を参考にする。
議論をたどると、どうやらMicrosoft C++ Build Toolsのインストールが必要らしい。
「c++によるデスクトップ開発」および右側のオプションを上から7つ選択して、インストール。
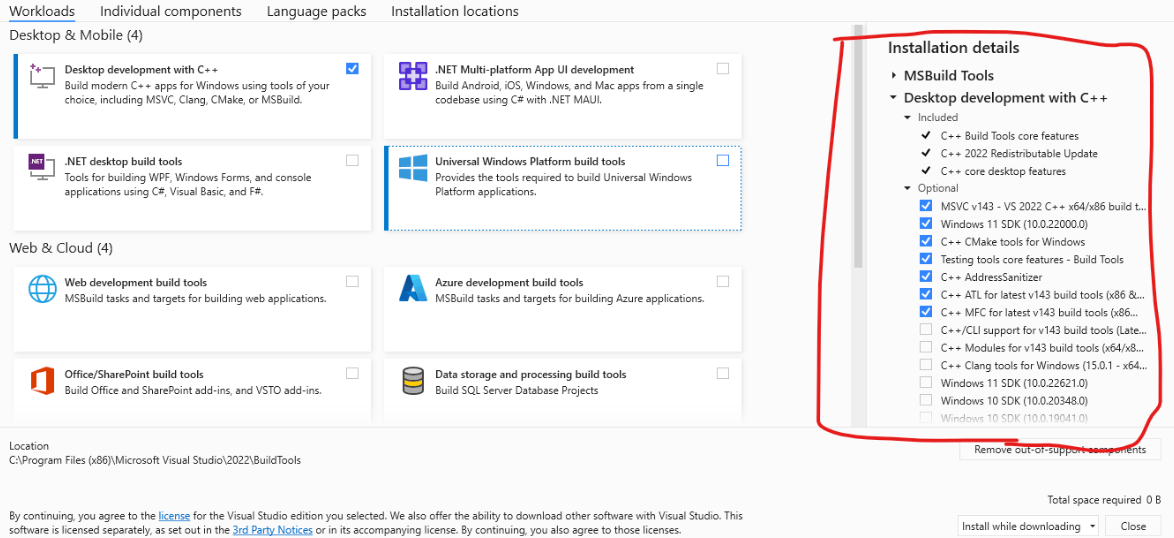
無事にインストールできたらPCを再起動し、ここで初めて「pip install llama-cpp-python」を実行。成功するはず。※スクショ撮り忘れましたが成功しました。
次にLLMをhuggingfaceからダウンロードする。Phi-3-mini-4k-instruct-q4.ggufというやつが4bit量子化モデルなので、これを選択する。
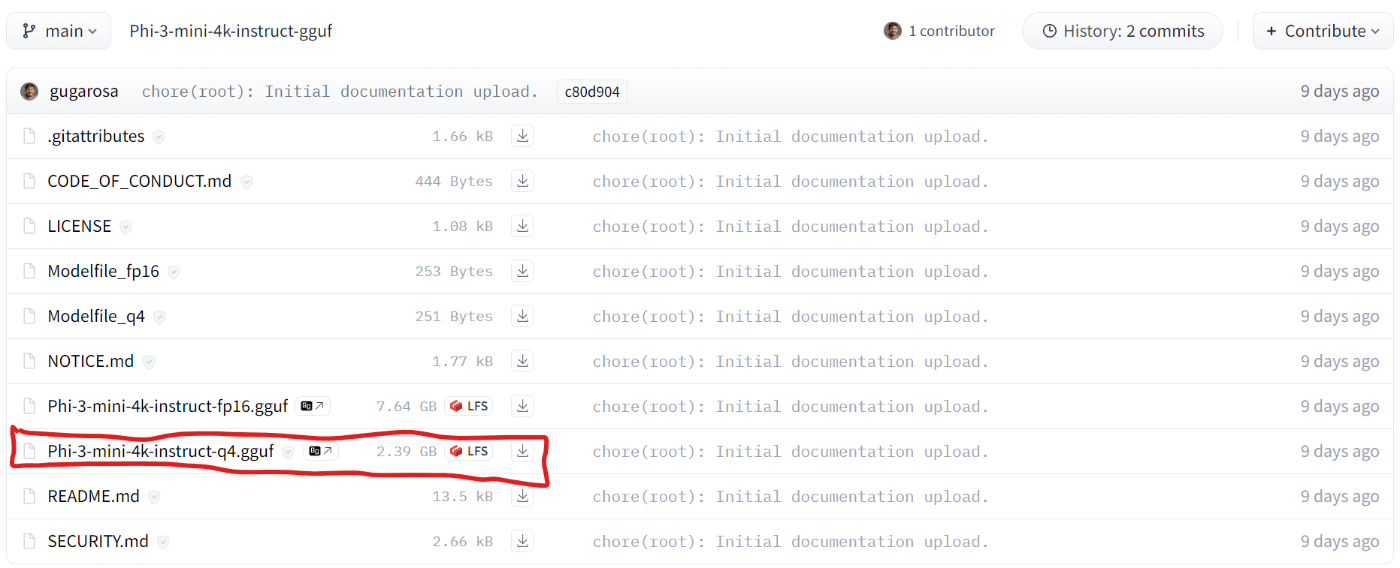
2.4GBのサイズで、たぶん1時間もあればダウンロードできる。ダウンロードが終わったら、いよいよ実行! 次のソースコードを入力する。
from llama_cpp import Llama
llm = Llama(
model_path="(ここにモデルのファイルを格納したパスを記入)/Phi-3-mini-4k-instruct-q4.gguf", # path to GGUF file
n_gpu_layers=0, # The number of layers to offload to GPU, if you have GPU acceleration available. Set to 0 if no GPU acceleration is available on your system.
)
prompt= [
{"role": "system", "content": "あなたはAIアシスタントです。ユーザーの質問に対して適切な情報を提供してください。"},
{"role": "user", "content": "あなたは何ができますか?網羅的かつ箇条書きで教えてください。"},
]
output = llm(
f"<|user|>\n{prompt}<|end|>\n<|assistant|>",
max_tokens=512,
stop=["<|end|>"],
echo=True,
)
print(output['choices'][0]['text'])
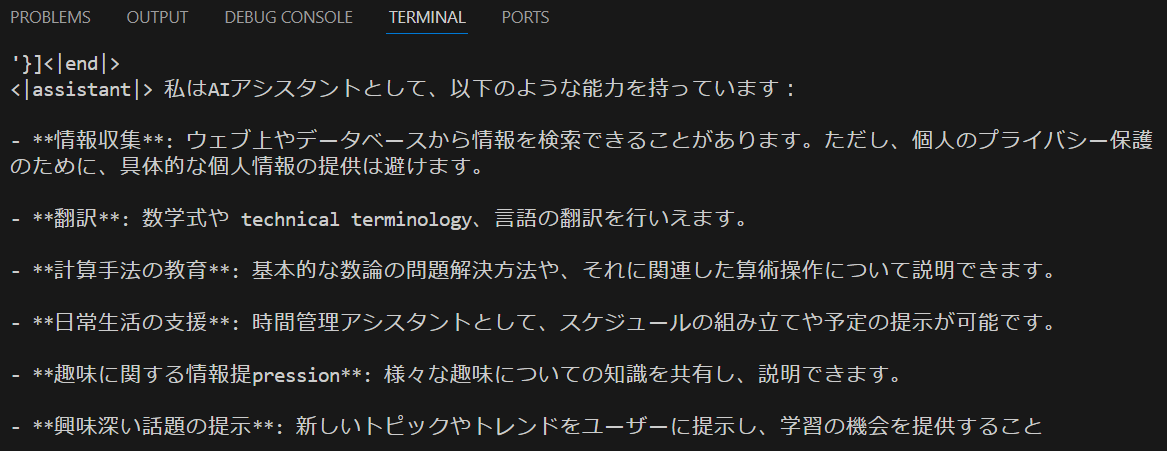
すると……答えが返ってくる!!!!!
感動。1分くらいで返ってきました。普通に速いです。
さいごに
量子化モデルはちょっと精度が悪く、微妙に日本語崩壊気味なので、あとはプロンプトをがんばったり、使い道を検討する。しかしクローズドネットワークの業務環境なんてやまほどあるので、活躍できるシーンはいっぱいありそう。ユースケースを考えるとわくわくします。
しかしね、本当のことを言えば、そんなことはどうでもよくて、何よりもまず、自分の手元のふつうのPCでLLMが動くなんて……超感動だ!!!!! ということが言いたかったんだ!!!!!
おまけ
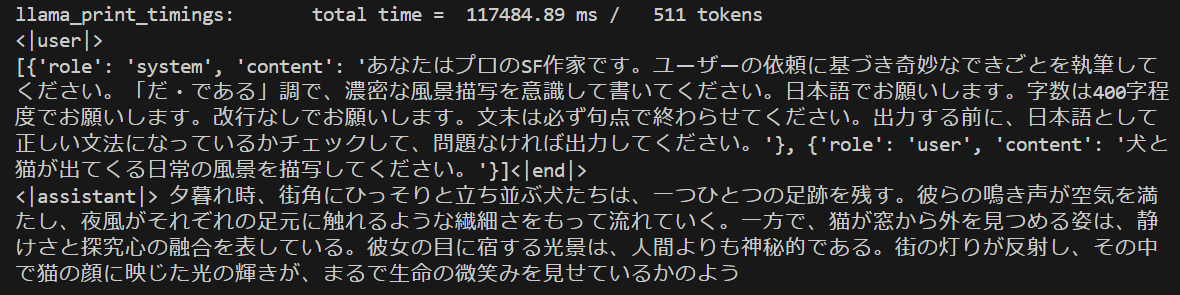
小説を書かせてみた。なんとも味わい深い感じ。
5/2追記
StreamlitでWebアプリ化もしてみました。最新の、地球外life……。

※2024年5月15日に名古屋で生成AIイベントやります!よろしくお願いします!

アクセンチュア株式会社に所属する社員有志による運営です。アクセンチュアの社員による様々な発信をまとめています。なお、投稿内容は社員個人の見解であり、所属する組織を代表するものではありません。
Discussion
どのくらいの速度で出るんですか?
トークン/秒が知りたい