1. はじめに
経理業務では、新しい取引先や商品・サービスが日々登場し、従来のルールベース(例:「〇〇会社は交通費」のような固定ルール)では対応しきれないケースが増えています。例えば、「Uber」の経費は交通費?会議費?それとも接待費?このような判断は、利用シーンによって変わり、単純なルールでは分類困難です。こうした課題に対して、過去の分類実績から学習し、文脈を理解して予測する機械学習(テキスト分類モデル)が有効な解決策となります。
この記事では、FastTextというライブラリを使ってテキスト分類モデルを実現します。
2. 予測の概要
予測には、「予測対象データ」と「学習済みモデル」を使います。ルールベースではないので、100点満点の精度はでません。複数の候補を確信度が高い順に提示するのが一般的です。

3. 学習済みモデルを作る
それでは、「学習済みモデル」どのように作るのでしょうか。
- 学習対象データを「前処理」で加工して教師データを作る
- FastTextのモデル定義とアルゴリズム設定を行う
- 学習プロセスを実行して「学習済みモデル」がアウトプットされる
3.1. 教師データを作る
FastTextの教師データの形式へ変換します。
「テキストの結合 → Janomeで分かち書き → FastText形式に変換」という流れで進めます。
「カテゴリー」→「勘定科目」と読み替えてください。

3.1.1. テキスト結合
文脈情報を充実にして、精度を上げます。例えば、「スターバックス」だけでは判断困難でも、「スターバックス コーヒー購入」なら「食費」と判断しやすいですね。
3.1.2. Janomeで分かち書き
知識の再利用性を高められます。
日本語は単語間にスペースがないです。意味単位で単語を抽出します。(例:東京駅から品川駅」→「東京」「駅」「から」「品川」「駅」)
これは、FastTextが意味単位での入力を前提としているのも理由の1つですが、未知の単語から類推できるようにもなります。(例:「○○マート」という新しい店を見たとき、「マート」という部分からコンビニやスーパーを連想する)
3.2. 学習済みモデルを作る
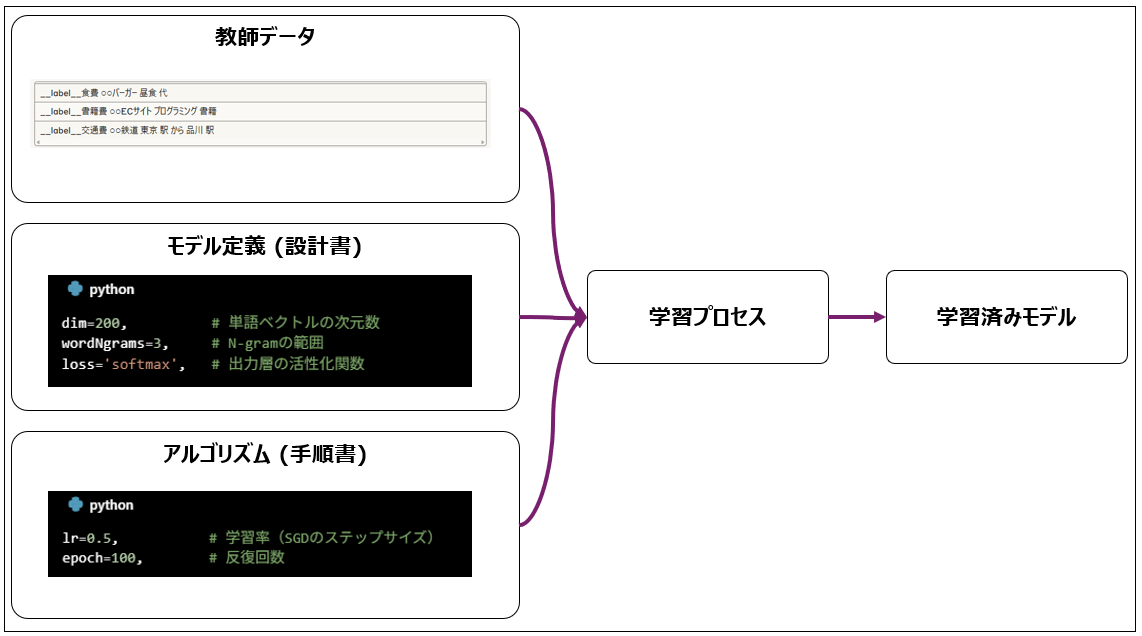
3.2.1. モデル定義(設計書)
学習済みモデルを作るための設定をします。
dim=200, # 単語ベクトルの次元数
wordNgrams=3, # N-gramの範囲
loss='softmax', # 出力層の活性化関数
dim=200 → 入力層のベクトル次元数:
次元数を増やすことで豊富な特徴表現が可能になります。
# このパラメータが決定すること
単語埋め込み行列のサイズ = 語彙数 × 200
# 例:語彙数1000の場合
埋め込み行列 = [[0.12, -0.34, ..., 0.89], # "スターバックス"のベクトル
[0.45, 0.23, ..., -0.67], # "コーヒー"のベクトル
... # 1000単語分
[-0.08, 0.67, ..., 0.34]] # 各行が200次元
wordNgrams=3 → 入力層で扱う特徴量の種類:
「東京_駅_新幹線」のような複合概念を学習します。
# N-gramが生成する追加の特徴
テキスト: "東京 駅 新幹線"
N-gram=1: ["東京", "駅", "新幹線"] # 単語のみ(デフォルト)
N-gram=2: ["東京", "駅", "新幹線", "東京_駅", "駅_新幹線"]
N-gram=3: ["東京", "駅", "新幹線", "東京_駅", "駅_新幹線", "東京_駅_新幹線"]
loss='softmax' → 出力層の設計:
確率的な予測が可能になります。
# softmax損失関数が決定する出力層の構造
出力層 = {
"活性化関数": softmax,
"損失計算": cross_entropy_loss,
"出力": 確率分布(合計1.0)
}
# 内部計算
logits = W × doc_vector + b # 線形変換(200次元→8次元(FastTextの固定値))
probabilities = softmax(logits) # 確率に変換
3.2.2. アルゴリズム(手順書)
学習済みモデルを作るための手順を設定します。
lr=0.5, # 学習率(SGDのステップサイズ)
epoch=100, # 反復回数
学習率 lr=0.5:
# SGDの重み更新式
新しい重み = 現在の重み - lr × 勾配
# 具体例
現在の重み = 1.0
勾配 = 0.4 (誤差を減らすための方向)
lr = 0.5
新しい重み = 1.0 - 0.5 × 0.4 = 0.8
# ↑
# 更新量の大きさを制御
エポック数 epoch=100
# 1エポック = 全データを1回学習
データ数: 410件
1エポック = 410件全てを1回ずつ学習
# 100エポック
= 410件 × 100回 = 41,000回の重み更新
学習進行のイメージ
- エポック1-10: 急速に改善(大きな誤差を修正)
- エポック11-50: 着実に改善(細かい調整)
- エポック51-100: 微調整(収束に向かう)
学習曲線のイメージ
精度
100% | ━━━━━━━━━ (収束)
| ━━━╱
| ━━━╱ lr=0.5, epoch=100
| ━━━╱ (素早く上昇、十分に収束)
| ━━━╱
50% |━━━╱________________lr=0.01, epoch=100
| (ゆっくり上昇、未収束)
|
0% |━━━━━━━━━━━━━━━━━━━━
0 50 100 エポック
lr と epoch の関係性
| 状況 | lr調整 | epoch調整 | 理由 |
|---|---|---|---|
| 学習が遅い | ↑ 増やす | - | 更新を大きく |
| 精度が不安定 | ↓ 減らす | - | 安定化 |
| まだ改善の余地 | - | ↑ 増やす | より長く学習 |
| 過学習の兆候 | - | ↓ 減らす | 早めに停止 |
4. 予測するまでの流れ
予測は、「予測対象データ」「学習済みモデル」「予測方法」を使って予測します。「予測対象データ」はFastTextで定められているフォーマットに変換したうえで予測します。

# 入力
company = "○○ECサイト"
description = "プログラミング書籍"
# 処理
text = "○○ECサイト プログラミング書籍"
processed = "○○ECサイト プログラミング 書籍"
# 予測結果
prediction = model.predict(processed, k=3)
# 結果:
# 1. 書籍費 (0.85)
# 2. 備品費 (0.10)
# 3. 教育費 (0.03)
5. 実際のソースコード
それでは、実際のPythonのソースコードをご紹介します。
フォルダ構成は下記です。
/
├── Data/ # データセット格納ディレクトリ
│ ├── expense_data.csv # 経費データ(訓練用データ、16KB、411行)
│ └── test_data.csv # テスト用データ(3.1KB、113行)
│
├── models/ # 学習済みモデル格納ディレクトリ
│ ├── expense_classifier.bin # 経費分類器の学習済みモデル(1.5GB)
│ └── training_data.txt # 訓練データのテキスト形式(21KB、411行)
│
├── src/ # ソースコード格納ディレクトリ
│ ├── train.py # モデル訓練用スクリプト(4.0KB、137行)
│ ├── evaluate.py # モデル評価用スクリプト(5.1KB、170行)
│ └── predict.py # 予測実行用スクリプト(4.1KB、139行)
│
├── .git/ # Gitバージョン管理ディレクトリ
├── .venv/ # Python仮想環境ディレクトリ
└── requirements.txt # Python依存パッケージリスト(479B、30行)
5.1. train.py
train.py
import pandas as pd
import fasttext
from janome.tokenizer import Tokenizer
import os
def preprocess_text(text):
"""
日本語テキストの前処理
"""
if pd.isna(text):
return ""
# 日本語トークナイザーの初期化
tokenizer = Tokenizer()
# 形態素解析
tokens = tokenizer.tokenize(text, wakati=True)
# スペースで結合
return " ".join(tokens)
def create_training_data():
"""
学習用データの作成
"""
print("📊 学習用データを読み込み中...")
# CSVファイルの読み込み
df = pd.read_csv('data/expense_data.csv')
print(f"データ件数: {len(df)}")
print(f"カテゴリ数: {df['category'].nunique()}")
print(f"カテゴリ: {df['category'].unique()}")
# テキストの前処理
print("🔧 テキストの前処理中...")
df['processed_text'] = df['company'].astype(str) + " " + df['description'].astype(str)
df['processed_text'] = df['processed_text'].apply(preprocess_text)
# FastText形式のデータ作成
print("📝 FastText形式のデータを作成中...")
training_data = []
for _, row in df.iterrows():
label = "__label__" + row['category']
text = row['processed_text']
training_data.append(f"{label} {text}")
# 学習用ファイルの保存
os.makedirs('models', exist_ok=True)
with open('models/training_data.txt', 'w', encoding='utf-8') as f:
for line in training_data:
f.write(line + '\n')
print("✅ 学習用データの準備完了")
return 'models/training_data.txt'
def train_model(training_file):
"""
モデルの学習
"""
print("🤖 モデルの学習を開始...")
# FastTextモデルの学習
model = fasttext.train_supervised(
input=training_file,
lr=0.5, # 学習率を上げる
epoch=100, # エポック数を増やす
wordNgrams=3, # N-gramを増やす
dim=200, # ベクトル次元を増やす
minCount=1, # 最小出現回数を設定
loss='softmax', # 損失関数を明示
verbose=2 # 詳細ログ
)
# モデルの保存
model_path = 'models/expense_classifier.bin'
model.save_model(model_path)
print(f"✅ モデルが保存されました: {model_path}")
return model, model_path
def evaluate_model(model):
"""
モデルの簡易評価
"""
print("📈 モデルの簡易評価中...")
# 学習データでの簡易評価
result = model.test('models/training_data.txt')
print(f"サンプル数: {result[0]}")
print(f"精度: {result[1]:.4f}")
print(f"再現率: {result[2]:.4f}")
# 予測例の表示
print("\n🔍 予測例:")
test_examples = [
"スターバックス コーヒー",
"Amazon 書籍",
"JR東日本 電車",
"ホテル 宿泊"
]
for text in test_examples:
processed = preprocess_text(text)
prediction = model.predict(processed, k=3)
print(f"入力: {text}")
for i, (label, prob) in enumerate(zip(prediction[0], prediction[1])):
clean_label = label.replace('__label__', '')
print(f" 予測{i+1}: {clean_label} (確信度: {prob:.4f})")
print()
def main():
"""
メイン処理
"""
print("🎯 経費分類システムの学習開始")
print("=" * 50)
# 学習データの準備
training_file = create_training_data()
# モデルの学習
model, model_path = train_model(training_file)
# モデルの簡易評価
evaluate_model(model)
print("=" * 50)
print("🎉 学習完了!")
print(f"モデルファイル: {model_path}")
if __name__ == "__main__":
main()
このプログラムは、経費データから勘定科目を自動分類するモデルを学習します。主要な処理は4つの関数で構成されています。
「preprocess_text()」は、日本語テキストをJanomeで形態素解析し、単語単位に分割します。これにより「スターバックスコーヒー」が「スターバックス コーヒー」のように分かち書きされ、FastTextが処理可能な形式になります。
「create_training_data()」では、CSVファイルから会社名・説明・カテゴリを読み込み、FastText形式(__label__食費 スターバックス コーヒー)に変換します。会社名と説明を結合することで、より豊富な文脈情報を学習に活用できます。
「train_model()」が学習の中核で、lr=0.5(高い学習率)とepoch=100(十分な反復回数)により高速かつ高精度な学習を実現。dim=200で単語を200次元ベクトルとして表現し、wordNgrams=3で「東京_駅_新幹線」のような単語の組み合わせも学習します。
「evaluate_model()」では、学習したモデルの精度を確認し、実際の予測例を表示します。これにより、モデルが正しく動作していることを即座に確認できます。
プログラムは絵文字を使った進捗表示により、処理状況を視覚的に把握できる工夫もされています。最終的にexpense_classifier.binという学習済みモデルファイルが生成され、予測プログラムで利用可能になります。
5.2. predict.py
predict.py
import pandas as pd
import fasttext
from janome.tokenizer import Tokenizer
import sys
def preprocess_text(text):
"""
日本語テキストの前処理
"""
if pd.isna(text):
return ""
tokenizer = Tokenizer()
tokens = tokenizer.tokenize(text, wakati=True)
return " ".join(tokens)
def load_model():
"""
学習済みモデルの読み込み
"""
model_path = 'models/expense_classifier.bin'
try:
model = fasttext.load_model(model_path)
print(f"✅ モデルを読み込みました: {model_path}")
return model
except FileNotFoundError:
print(f"❌ モデルファイルが見つかりません: {model_path}")
print("先に学習を実行してください: python src/train.py")
sys.exit(1)
def predict_single(model, company, description):
"""
単一データの予測
"""
# テキストの結合と前処理
text = f"{company} {description}"
processed_text = preprocess_text(text)
# 予測実行
prediction = model.predict(processed_text, k=3)
# 結果の整形
results = []
for label, prob in zip(prediction[0], prediction[1]):
clean_label = label.replace('__label__', '')
results.append({
'category': clean_label,
'confidence': prob
})
return results
def predict_batch(model, csv_file):
"""
バッチ予測
"""
print(f"📊 バッチ予測を開始: {csv_file}")
# CSVファイルの読み込み
df = pd.read_csv(csv_file)
# 予測結果の列を追加
df['predicted_category'] = ''
df['confidence'] = 0.0
# 各行に対して予測
for idx, row in df.iterrows():
results = predict_single(model, row['company'], row['description'])
df.loc[idx, 'predicted_category'] = results[0]['category']
df.loc[idx, 'confidence'] = results[0]['confidence']
# 結果の保存
output_file = 'predictions.csv'
df.to_csv(output_file, index=False, encoding='utf-8-sig')
print(f"✅ 予測結果を保存しました: {output_file}")
return df
def interactive_mode(model):
"""
対話モード
"""
print("\n🎮 対話モードを開始")
print("会社名と説明を入力してください(終了: 'quit')")
print("-" * 40)
while True:
try:
company = input("会社名: ").strip()
if company.lower() == 'quit':
break
description = input("説明: ").strip()
if description.lower() == 'quit':
break
# 予測実行
results = predict_single(model, company, description)
print(f"\n📊 予測結果:")
for i, result in enumerate(results, 1):
print(f" {i}. {result['category']} (確信度: {result['confidence']:.4f})")
print("-" * 40)
except KeyboardInterrupt:
print("\n👋 対話モードを終了します")
break
except Exception as e:
print(f"❌ エラーが発生しました: {e}")
def main():
"""
メイン処理
"""
print("🔮 経費分類システム - 予測モード")
print("=" * 50)
# モデルの読み込み
model = load_model()
# 引数の確認
if len(sys.argv) > 1:
if sys.argv[1] == 'batch':
# バッチ予測
predict_batch(model, 'data/test_data.csv')
elif sys.argv[1] == 'interactive':
# 対話モード
interactive_mode(model)
else:
print("使用方法:")
print(" python src/predict.py batch # バッチ予測")
print(" python src/predict.py interactive # 対話モード")
else:
# デフォルトは対話モード
interactive_mode(model)
if __name__ == "__main__":
main()
このプログラムは、train.pyで作成した学習済みモデルを使って、新しい経費データの勘定科目を予測します。3つの動作モードを提供し、様々な利用シーンに対応しています。
「load_model()」で学習済みモデル(expense_classifier.bin)を読み込みます。モデルファイルが存在しない場合は、親切なエラーメッセージを表示して終了します。
「predict_single()」は予測の核となる関数で、会社名と説明を受け取り、前処理後にモデルで予測を実行。k=3により上位3つの候補を確信度付きで返します。例えば「書籍費(0.85)、備品費(0.10)、教育費(0.03)」のような結果が得られます。
対話モード(デフォルト)では、ユーザーが会社名と説明を入力すると、リアルタイムで予測結果を表示。開発時のテストや少量データの確認に便利です。
バッチモード(python predict.py batch)では、CSVファイル内の全データを一括予測し、結果をpredictions.csvとして保存。UTF-8 BOM付きで出力するため、Excelでも文字化けせずに開けます。
プログラムは柔軟な利用方法を提供し、単発の確認から大量処理まで幅広いニーズに対応。確信度付きの予測により、結果の信頼性も判断できる実用的な設計になっています。エラーハンドリングも適切に実装され、安定した動作を実現しています。
5.3. evaluate.py
evaluate.py
import pandas as pd
import fasttext
from janome.tokenizer import Tokenizer
import numpy as np
from sklearn.metrics import classification_report, confusion_matrix
import matplotlib.pyplot as plt
import seaborn as sns
def preprocess_text(text):
"""
日本語テキストの前処理
"""
if pd.isna(text):
return ""
tokenizer = Tokenizer()
tokens = tokenizer.tokenize(text, wakati=True)
return " ".join(tokens)
def load_model():
"""
学習済みモデルの読み込み
"""
model_path = 'models/expense_classifier.bin'
model = fasttext.load_model(model_path)
return model
def evaluate_model():
"""
モデルの詳細評価
"""
print("📈 モデルの詳細評価を開始")
print("=" * 50)
# モデルとデータの読み込み
model = load_model()
df = pd.read_csv('data/expense_data.csv')
# 予測の実行
y_true = []
y_pred = []
for _, row in df.iterrows():
text = f"{row['company']} {row['description']}"
processed_text = preprocess_text(text)
# 予測
prediction = model.predict(processed_text, k=1)
predicted_category = prediction[0][0].replace('__label__', '')
y_true.append(row['category'])
y_pred.append(predicted_category)
# 分類レポートの生成
print("📊 分類レポート:")
print(classification_report(y_true, y_pred, zero_division=0))
# 混同行列の生成
cm = confusion_matrix(y_true, y_pred)
categories = sorted(df['category'].unique())
print("\n🔍 混同行列:")
cm_df = pd.DataFrame(cm, index=categories, columns=categories)
print(cm_df)
# 精度の計算
accuracy = np.mean(np.array(y_true) == np.array(y_pred))
print(f"\n✅ 全体精度: {accuracy:.4f}")
# カテゴリ別の精度
print("\n📋 カテゴリ別精度:")
for category in categories:
mask = np.array(y_true) == category
if mask.sum() > 0:
category_accuracy = np.mean(np.array(y_pred)[mask] == category)
print(f" {category}: {category_accuracy:.4f}")
return y_true, y_pred, categories
def show_prediction_examples():
"""
予測例の表示
"""
print("\n🔍 予測例:")
print("=" * 50)
model = load_model()
# テスト例
test_examples = [
("マクドナルド", "ハンバーガー"),
("Amazon", "プログラミング本"),
("JR東日本", "新幹線"),
("東横イン", "出張宿泊"),
("スターバックス", "会議コーヒー"),
("ヨドバシカメラ", "マウス"),
("NTTドコモ", "携帯電話"),
("病院", "健康診断")
]
for company, description in test_examples:
text = f"{company} {description}"
processed_text = preprocess_text(text)
prediction = model.predict(processed_text, k=3)
print(f"入力: {company} - {description}")
for i, (label, prob) in enumerate(zip(prediction[0], prediction[1])):
clean_label = label.replace('__label__', '')
print(f" 予測{i+1}: {clean_label} (確信度: {prob:.4f})")
print()
def analyze_errors():
"""
エラー分析
"""
print("\n🔍 エラー分析:")
print("=" * 50)
model = load_model()
df = pd.read_csv('data/expense_data.csv')
errors = []
for _, row in df.iterrows():
text = f"{row['company']} {row['description']}"
processed_text = preprocess_text(text)
# 予測
prediction = model.predict(processed_text, k=1)
predicted_category = prediction[0][0].replace('__label__', '')
if predicted_category != row['category']:
errors.append({
'company': row['company'],
'description': row['description'],
'true_category': row['category'],
'predicted_category': predicted_category,
'confidence': prediction[1][0]
})
if errors:
print(f"❌ 分類エラー数: {len(errors)}")
print("\n間違いやすい例:")
for error in errors[:10]: # 最初の10件を表示
print(f" {error['company']} - {error['description']}")
print(f" 正解: {error['true_category']} → 予測: {error['predicted_category']}")
print(f" 確信度: {error['confidence']:.4f}")
print()
else:
print("✅ 分類エラーはありません")
def main():
"""
メイン処理
"""
print("📊 経費分類システム - 評価モード")
# モデルの評価
y_true, y_pred, categories = evaluate_model()
# 予測例の表示
show_prediction_examples()
# エラー分析
analyze_errors()
print("\n🎉 評価完了")
if __name__ == "__main__":
main()
学習済みモデルを評価するPythonとなります。
6. 導入方法
6.1. クイックスタート
下記で、導入できます。
# 1. uvのインストール(初回のみ)
pip install uv
# 2. プロジェクトディレクトリで仮想環境を作成
uv venv
# 3. 仮想環境をアクティベート
# Windows PowerShell
.\.venv\Scripts\Activate.ps1
# Windows Command Prompt
.\.venv\Scripts\activate.bat
# Mac/Linux
source .venv/bin/activate
# 4. 必要なライブラリをインストール
uv pip install pandas fasttext janome
# 5. 評価スクリプト用の追加ライブラリ(オプション)
# evaluate.pyを実行する場合は必要
uv pip install scikit-learn matplotlib seaborn joblib
# 6. 学習の実行
python src/train.py
6.2. 注意事項
Windows環境の場合の注意事項:
fasttextのインストールにはMicrosoft Visual C++ Build Toolsが必要です。
-
Visual C++ Build Toolsのインストール(Windows環境で必要)
- Microsoft C++ Build Toolsをダウンロード
- インストーラーを実行し、「C++によるデスクトップ開発」を選択してインストール
- インストール完了後、PowerShellを再起動
Windows環境でfasttextのインストールエラーが発生する場合は、以下の手順を試してください:
# 1. 必要なビルドツールをアップグレード
uv pip install --upgrade pip setuptools wheel build cmake pybind11
# 2. 環境変数を設定(PowerShell)
$env:CL='/Dssize_t=Py_ssize_t'
# 3. fasttextをインストール
uv pip install --no-build-isolation -vvv fasttext==0.9.2
# 4. 他のライブラリをインストール
uv pip install pandas janome
# 5. 評価スクリプト用の追加ライブラリ(オプション)
uv pip install scikit-learn matplotlib seaborn joblib
教師データはAIに作らせると楽にできます。
company,description,category
マクドナルド,昼食代,食費
スターバックス,コーヒー代,食費
セブンイレブン,弁当代,食費
ドトールコーヒー,資料作成時の軽食,食費
タリーズコーヒー,朝食代,食費
吉野家,牛丼,食費
7. おわりに
実業務で使えそうなユースケースの機械学習となります!ぜひ、ご参考にしてください!

アクセンチュア株式会社に所属する社員有志による運営です。アクセンチュアの社員による様々な発信をまとめています。なお、投稿内容は社員個人の見解であり、所属する組織を代表するものではありません。
Discussion