はじめに
DeepLが次世代LLMモデルの翻訳を発表したことが話題になっています。
ChatGPTやGemini、ClaudeといったLLMでも翻訳ができ、それなりの精度でしたが
、それらを上回るサービスということで注目が集まっています。
従来のLLMだと、「インターネット上の公開情報を学習する汎用モデル」だったのに対して、DeepLの次世代LLMモデルは「翻訳や校正といった言語分野向けにチューニングされている」ためより人による翻訳に近い訳文がアウトプットされるそうです。
上記公式ドキュメントを見ていきましょう。
公式ドキュメントの概要
1. DeepLの次世代言語モデルとは
DeepL独自の画期的な大規模言語モデル(LLM)です。高品質な訓練データとAI技術を組み合わせ、より自然で正確な翻訳を実現します。翻訳の質を新たなレベルに引き上げることを目的としています。
2. 従来のモデルとの違い
翻訳の質が大幅に向上
必要な編集量が減少し、生産性が向上
偽情報や誤情報のリスクが軽減
DeepL Proと同等のセキュリティとプライバシーを確保
3. トレーニングデータについて
7年分以上の独自データを使用し、翻訳とコンテンツ作成に特化してトレーニングされています。インターネット上の公開情報を学習する汎用モデルとは異なり、高品質な翻訳提供に重点を置いています。
4. 翻訳品質の向上
プロの翻訳者によるブラインドテストで、Google翻訳、ChatGPT-4、Microsoftを上回る評価
従来のDeepL翻訳と比較して、日本語、中国語、ドイツ語で1.4倍から1.7倍の品質向上
5. セキュリティ対策
DeepL Proと同等の高いセキュリティ基準
専有データセンターの使用
高水準の認証とコンプライアンス基準(ISO 27001認証、GDPR準拠、SOC 2 Type 2レポートなど)
6. 対応言語
現在対応している言語ペア:
日本語⇔英語
ドイツ語⇔英語
中国語(簡体字)⇔英語
今後、対応言語は順次拡大予定。
7. 利用方法
DeepL Proユーザーは、翻訳設定画面でボタンひとつで次世代言語モデルに切り替え可能。
8. DeepL Pro未利用者の場合
DeepL Proプランにアップグレードすることで、次世代言語モデルを含むすべての機能を利用可能。
使い方
現状、Web版のみ次世代LLMが利用可能なようです。また、Pro版(有料版)のみ利用可能なようです。
まずは、DeepLのサイトにアクセスしてログインします。

翻訳したい文を入力してみましょう。

すると下記のように「言語モデル」が選択できるようになります。
「次世代言語モデル」をクリックして選択しましょう。

翻訳してみる!(次世代言語モデル、クラシック(従来))
下記のOpen AIが発表したインストラクションヒエラルキーの論文の冒頭を翻訳してみましょう。
翻訳前の英文
Today’s LLMs are susceptible to prompt injections, jailbreaks, and other
attacks that allow adversaries to overwrite a model’s original instructions
with their own malicious prompts. In this work, we argue that one of the
primary vulnerabilities underlying these attacks is that LLMs often consider
system prompts (e.g., text from an application developer) to be the same
priority as text from untrusted users and third parties. To address this, we
propose an instruction hierarchy that explicitly defines how models should
behave when instructions of different priorities conflict. We then propose
an automated data generation method to demonstrate this hierarchical
instruction following behavior, which teaches LLMs to selectively ignore
lower-privileged instructions. We apply this method to LLMs, showing that
it drastically increases robustness—even for attack types not seen during
training—while imposing minimal degradations on standard capabilities.
翻訳結果(クラシック(従来))
今日のLLMは、プロンプト・インジェクション、ジェイルブレイク、その他の攻撃の影響を受けやすい。
敵がモデルの元の命令を独自の悪意のあるプロンプトで上書きすることを可能にする攻撃
の影響を受けやすい。本研究では、これらの攻撃の根底にある主要な脆弱性の1つは
これらの攻撃の根底にある主要な脆弱性の一つは、LLMがしばしばシステムプロンプト(例えば
システムのプロンプト(例えば、アプリケーション開発者からのテキスト)は、信頼できないユーザーからのテキストと同じ優先順位である。
優先順位が、信頼できないユーザーや第三者からのテキストと同じであることである。これに対処するため、我々は
モデルがどのように振る舞うべきかを明示的に定義する命令階層を提案する。
を明示的に定義する命令階層を提案する。そして
自動データ生成法を提案する。
LLMが優先順位の低い命令を選択的に無視することを教えます。
優先順位の低い命令を選択的に無視するようにLLMに教える。この方法をLLMに適用し、以下のことを示す。
この方法をLLMに適用することで、ロバスト性が劇的に向上することを示す。
この方法をLLMに適用することで、標準的な機能の劣化を最小限に抑えながら、訓練時には見られなかった攻撃タイプに対しても堅牢性が飛躍的に向上することを示す。
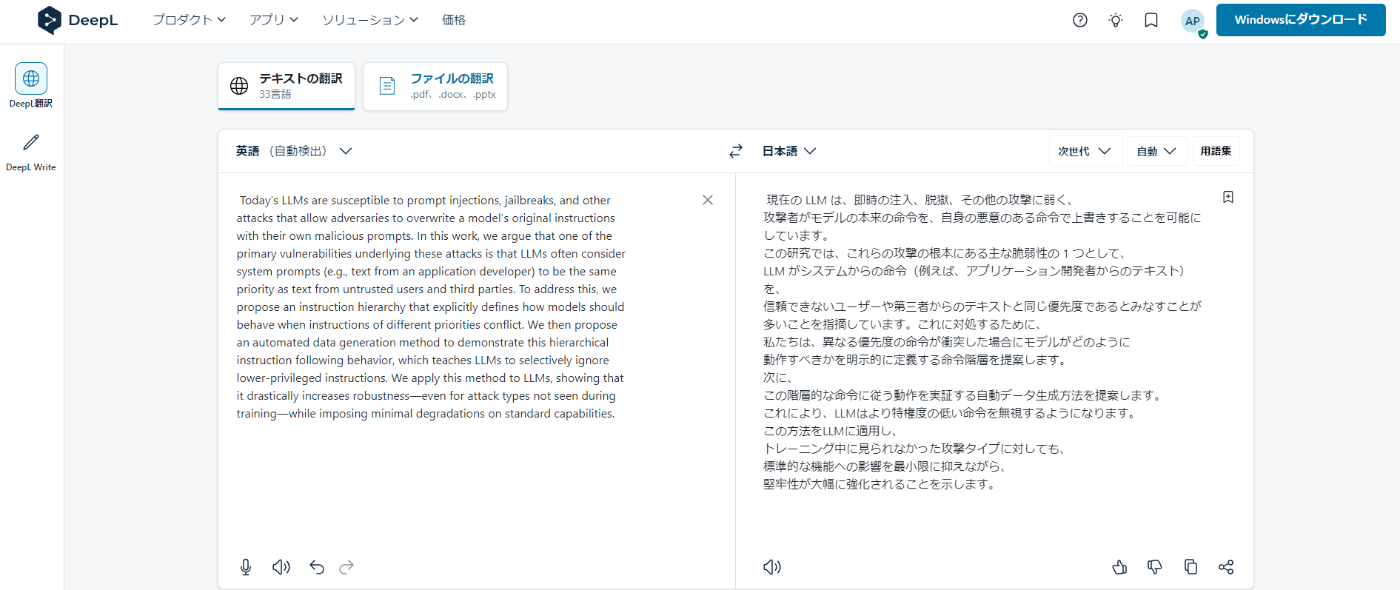
翻訳結果(次世代言語モデル)
現在の LLM は、即時の注入、脱獄、その他の攻撃に弱く、
攻撃者がモデルの本来の命令を、自身の悪意のある命令で上書きすることを可能にしています。
この研究では、これらの攻撃の根本にある主な脆弱性の 1 つとして、
LLM がシステムからの命令(例えば、アプリケーション開発者からのテキスト)を、
信頼できないユーザーや第三者からのテキストと同じ優先度であるとみなすことが多いことを指摘しています。これに対処するために、
私たちは、異なる優先度の命令が衝突した場合にモデルがどのように動作すべきかを明示的に定義する命令階層を提案します。
次に、
この階層的な命令に従う動作を実証する自動データ生成方法を提案します。
これにより、LLMはより特権度の低い命令を無視するようになります。
この方法をLLMに適用し、
トレーニング中に見られなかった攻撃タイプに対しても、
標準的な機能への影響を最小限に抑えながら、
堅牢性が大幅に強化されることを示します。
所感
「プロンプト・インジェクション、ジェイルブレイク」のところが次世代言語モデルだと「即時の注入、脱獄」と無理やり日本語に訳されていてわかりづらくなっています。一方で他の箇所はクラシックより次世代言語モデルの方が頭にすっと入ってきやすい印象でした。
翻訳結果の比較・評価をClaudeに聞いてみる
Claude 3.5 Sonnetにそれぞれ翻訳結果を入力して比較・評価してもらいました。
結果は、下記となります。
Claude 3.5 Sonnetの次世代言語モデルの評価は上々でした!
正確性:
次世代言語モデルの翻訳の方が、より正確で原文の意味をよく捉えています。例えば、"prompt injection"を「プロンプト・インジェクション」ではなく「即時の注入」と訳していますが、これはより適切な表現です。また、"jailbreak"を「ジェイルブレイク」ではなく「脱獄」と訳しており、これも日本語としてより自然です。
一貫性:
次世代モデルの翻訳は、用語の使用がより一貫しています。例えば、"LLM"という略語を一貫して使用しています。
流暢さ:
次世代モデルの翻訳の方が、より自然で流暢な日本語になっています。文章の構造がより明確で、読みやすくなっています。
専門用語の扱い:
次世代モデルは専門用語をより適切に扱っています。例えば、"instruction hierarchy"を「命令階層」と訳しており、これは技術的な文脈において適切です。
ニュアンスの伝達:
次世代モデルの翻訳は、原文のニュアンスをより正確に伝えています。例えば、"dramatically improve robustness"を「堅牢性が大幅に強化される」と訳しており、原文の強調を適切に反映しています。
文章構造:
次世代モデルの翻訳は、原文の段落構造をより忠実に再現しており、論理の流れが分かりやすくなっています。
総合評価:
次世代言語モデルの翻訳の方が明らかに優れています。より正確で、自然な日本語表現を用いており、原文の意図とニュアンスをより適切に伝えています。専門的な内容を扱う際の用語の選択も適切で、全体的な読みやすさも向上しています。クラシックモデルの翻訳と比較すると、次世代モデルは翻訳の質を大きく向上させていると言えます
さいごに
私自身、翻訳はChatGPT等のLLMを使うケースが多かったです。
今回のDeepLの発表を踏まえて、DeepLを活用してみようと思います。
この記事が、みなさまの日々の業務や生活がよりよくなる一助になれば幸いです。
またなにか気づいたことがありましたら投稿します!

アクセンチュア株式会社に所属する社員有志による運営です。アクセンチュアの社員による様々な発信をまとめています。なお、投稿内容は社員個人の見解であり、所属する組織を代表するものではありません。
Discussion