はじめに
2024年9月25日、オープンソースのマルチモーダルAI「Molmo」 が発表されました。
OpenAIのGPT-4oやGoogleのGemini 1.5 Proなどの最先端のAIに匹敵する性能を持ちながら、モデルのサイズは非常に小さいと話題になっていたので紹介します。
概要
Molmoは、Allen Institute for Artificial Intelligence(Ai2)によって開発されたオープンソースのマルチモーダルAIモデルです。
このモデルは、テキストと画像の両方を処理する能力を持ち、特に高いパフォーマンスを発揮します。
Molmoは、プロプライエタリなシステムと競争できる性能を示しており、GPT-4oやClaude 3.5 Sonnetなどの商業モデルと比較しても優れた結果を出しています。
molmoの特徴
マルチモーダルインタラクション
Molmoは、画像とテキストの両方を同時に処理する能力を持ち、ユーザーが写真を撮影すると、その内容を迅速に分析し、オブジェクトの識別やカウント、メニューからの食事選択などの具体的な洞察を提供します。
効率的なトレーニングプロセス
Molmoは、PixMoデータセットを用いて高品質なデータを使用してトレーニングされています。
このアプローチにより、トレーニングデータの量を大幅に削減しつつ、高いパフォーマンスを実現しています。
技術的アーキテクチャ
Molmoは、ビジョンエンコーダーとトランスフォーマー型言語モデルから構成されており、これらが多層パーセプトロン(MLP)で接続されています。
ビジョンエンコーダーにはOpenAIのViT-L/14 CLIPモデルが使用されています。
ベンチマーク性能
Molmo-72Bモデルは、DocVQAで96.3、TextVQAで85.5というスコアを記録し、多くのプロプライエタリモデルを上回る結果を示しています。
オープンソース
Molmoは完全にオープンソースであり、その使用に制限がないため、開発者や研究者は自由にカスタマイズや改良が可能です。
期待される分野
Molmoはその高性能とオープンソースという特性から、多くの分野での応用が期待されています。
- 自動キャプション生成
- 視覚障害者支援
- 医療画像診断支援 など
これにより、AI技術がより広範囲に普及し、多様な社会課題の解決に寄与することが期待されています。
機能と応用事例
Ai2はマルチモーダルAIの機能と応用事例についての紹介動画をYoutubeで公開しています。
以下で簡単に紹介するので、気になった方は実際の動画を視聴してみてください。
※動画は英語です。
❓ Molmo AMA: Your Questions Answered!
この動画では、様々な画像を用いてMolmoとの質疑応答形式で、その機能と応用範囲を紹介しています。
-
パイクプレイスマーケットの画像認識
画像内の物体認識、時間認識、天気認識、価格認識などの基本的なタスクをMolmoがどのように処理するかを示しています。
特定の情報のみを用いた回答、JSON形式での出力など、より詳細な指示への対応についても触れています。 -
ミニクーパーの広告画像の理解
画像内のユーモラスな要素をMolmoがどのように理解し、説明できるかを検証しています。
回答の長さや表現方法を指定するプロンプトについても紹介しています。 -
横断歩道の標識の解釈と応用
標識の認識だけでなく、関連する音楽アルバム(アビイ・ロード)の知識を用いた応答が可能であることを示しています。
画像をテーマにした詩の作成など、創造的なタスクへの対応についても触れています。
🔢 Molmo and Counting: AI that Adds it Up
この動画は、Molmoの画像内のオブジェクトカウント機能に焦点を当てています。
-
オフィス風景の画像におけるカウント
椅子やモニターなど、オブジェクトの種類を指定したカウントが可能であることを示しています。
色などの属性を指定したカウントや、画像の一部領域に限定したカウントについても検証しています。 -
人間の行動認識とカウント
立っている人数、ポケットに手を入れている人数など、人間の姿勢や動作に基づいたカウントの精度について検証しています。 -
窓ガラスや花瓶など、多数のオブジェクトのカウント
窓ガラスの枚数など、多数のオブジェクトのカウント精度と、その限界について検証しています。
花瓶の画像を用いて、Molmoが複雑な形状のオブジェクトを正確にカウントできることを示しています。
色などの属性を指定したカウントについても検証しています。
🚀 Molmo Robotic Demo: AI in Action
この動画では、ロボットに搭載されたMolmoが、現実世界の環境を理解し、タスクを実行する様子を紹介しています。
-
キッチン環境の認識とオブジェクト操作
キッチンカウンター上のオブジェクトを認識し、その種類と位置を特定する様子を示しています。
特定のオブジェクト(例:白いボトル)を指示に従って操作する様子を紹介しています。
「汚れた食器を置くべき場所」といった、文脈を理解したタスク実行が可能であることを示しています。 -
お茶を入れるためのオブジェクト認識
ティーバッグやコーヒーメーカーなど、特定のタスクに必要なオブジェクトを認識し、その位置を特定する様子を示しています。
🤖 Molmo on Robotics Data: Powering Machines with AI
この動画では、ロボット工学のデータセットを用いて、Molmoがロボットの動作計画やタスク生成にどのように役立つかを探っています。
-
ロボットアームの動作理解と説明
ロボットアームが椅子を持ち上げる様子の画像から、Molmoがその動作を理解し説明できることを示しています。
鍋を持ち上げるために必要な把持位置を、Molmoが正確に特定できることを示しています。 -
オブジェクトの配置変更タスク
複数の画像を用いて、オブジェクトの配置変更手順をMolmoが生成できるかを検証しています。
複雑なタスクや、学習データセットにない状況では、正確な手順生成が難しい場合があることを示しています。 -
カップの積み重ねタスク
カップの積み重ねタスクの手順を、Molmoがロボットの動作に落とし込んで生成できることを示しています。
透明なカップの認識、画像内のカップの個数カウントについても検証しています。 -
キッチン環境におけるタスク生成
キッチン環境の画像から、Molmoがロボットのタスクを複数提案できることを示しています。
食器の準備、清掃、整理整頓など、具体的なタスク例を紹介しています。 -
キャビネットの開閉タスク
キャビネットの開閉に必要な把持位置を、Molmoが正確に特定できることを示しています。
ロボットの動作手順を、詳細な説明とともに生成できることを示しています。 -
ソファと枕の認識とカウント
ソファや枕など、家庭環境におけるオブジェクト認識とカウントの精度について検証しています。 -
水道の蛇口の操作
水道の蛇口を操作するために必要な把持位置を、Molmoが正確に特定できることを示しています。 -
ドアハンドルの認識と操作
ドアハンドルの把持位置を特定し、ドアを開けるためのロボットの動作手順を生成する様子を示しています。
🤝 Molmo meets SAM
この動画では、MolmoとセグメンテーションモデルであるSAM (Segment Anything Model) を組み合わせることで、画像理解と操作がどのように拡張されるかを探っています。
-
人物画の認識とセグメンテーション
人物画内のオブジェクト(例:リンゴ、手、ネクタイ)を指示に従って認識し、SAMを用いてセグメンテーションする様子を示しています。
詳細な指示(例:左のボタン)や、画像内に存在しないオブジェクト(例:ボタン)への対応についても検証しています。
背景オブジェクト(例:海、雲、レンガ)の認識とセグメンテーションについても検証しています。 -
猫の画像の認識とセグメンテーション
猫の画像を用いて、MolmoとSAMが複雑な形状のオブジェクトや、一部が隠れているオブジェクトをどのように処理するかを検証しています。
画像内に存在しないオブジェクト(例:犬、キャリーバッグ、テーブル)を指定した場合の応答についても検証しています。
床の素材(例:タイル、ラグ)を指定した場合の応答や、存在しない色のラグを指定した場合の応答についても検証しています。 -
人間の体の部位の認識とセグメンテーション
鼻、耳、親指など、人間の体の部位を認識し、セグメンテーションする様子を示しています。
左右を指定した場合の認識精度や、画像内に存在しない体の部位(例:左耳)を指定した場合の応答についても検証しています。
🥽 Molmo Vision Pro Demo - Augmenting how we see with AI
この動画では、Apple Vision Proと組み合わせることで、Molmoがどのように現実世界の体験を拡張できるかを具体例を通して示しています。
-
コーヒーメーカーの操作
コーヒーメーカーの機能説明、操作方法の説明、飲み物の種類やオプションの説明などを、Molmoが画像認識に基づいて行う様子を示しています。
特定のオプション(例:エスプレッソ、ダブルショット)を指示に従って選択する様子や、操作できない理由を説明する様子を紹介しています。 -
ランチメニューの要約
ランチメニューの画像から、重要な情報を抽出し、簡潔に要約する様子を示しています。 -
会議室内の椅子のカウント
会議室内の椅子の数を、Molmoが高速かつ正確にカウントする様子を示しています。
Molmoが、現実世界の状況把握と意思決定を支援するツールとなり得ることを示唆しています。
使ってみた
デモページでMolmoを触ってみました。
ネットから拾ってきたフリー画像を使ってレモンの個数を数えてもらいました。
日本語に弱いらしいとのこと。英語で質問してみます。
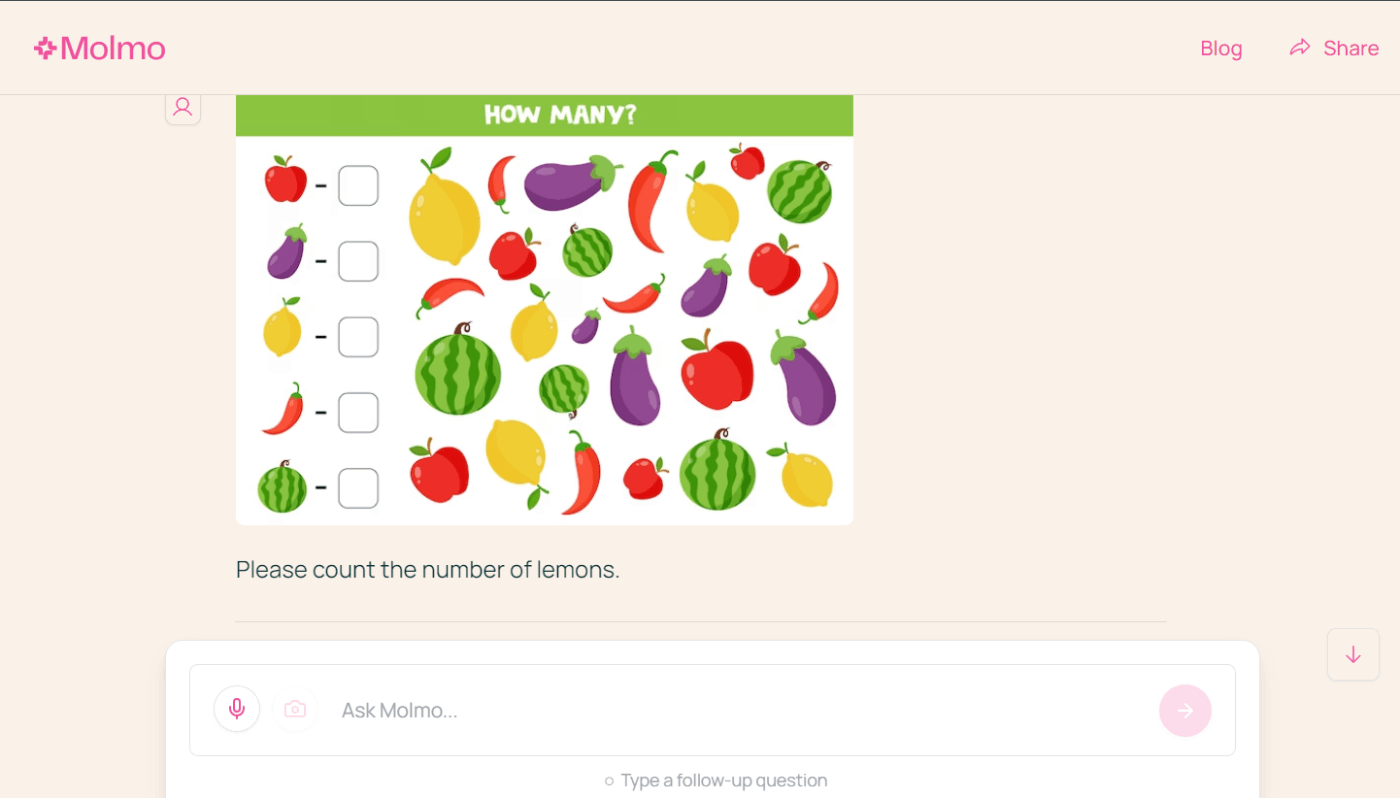
結果は...


しっかり数えられていますね。
違う画像でアボカドの数も数えてもらいました。

結果は...
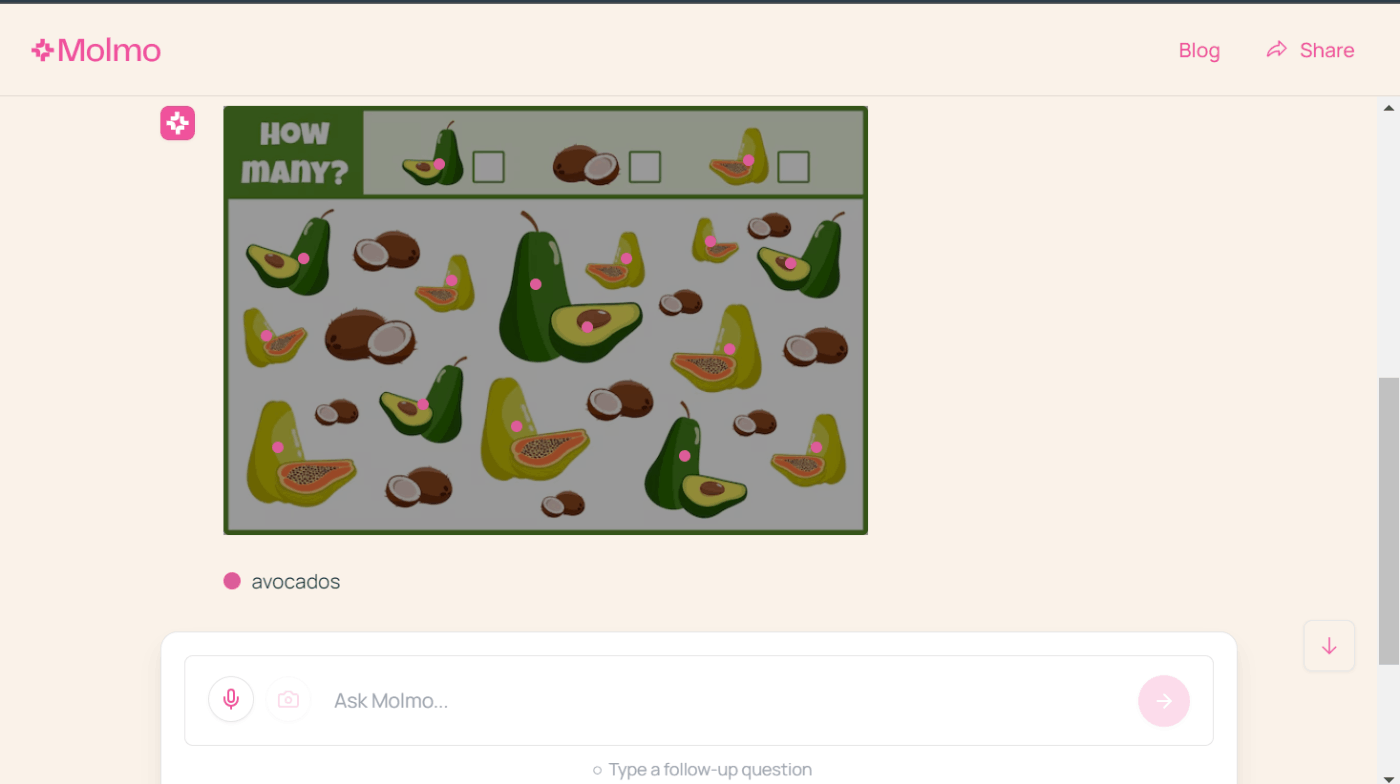

パパイヤも一緒にカウントされました。
ただ、アボカドとパパイヤは漏れなくカウントできているので、見分けることができるようになったらしっかりと数えてくれそうです。
よく見たら中央のアボカド2つカウントしてますね。
1個半で一つの画像だから少し難しかったかな🤔
おわりに
今回紹介したカウント検証だけでなく、いろいろ触って機能を体験してみましたが、正直なところ、性能として特別衝撃は感じませんでした。
実際GPT-4oとGemini 1.5 Proと同等の性能が出た結果があるだけで、ユニークな機能や凄さをあまり感じられなかったからです。
試した例が悪かったのか、プロンプトが悪かったのか、、、使い方間違ってるのだろうか。。
ウォーリーとか探せちゃうかなとか思ったんですけどね。
期待し過ぎでした。
すごいという噂を鵜呑みにして、情報に踊らされた良い例です。
まあでも公開情報だけ見たら充分将来性ありますね。
今後2か月でアップデートのリリース計画が公開されているので、情報を追っていきたいと思います。
今後に期待です!🥑

アクセンチュア株式会社に所属する社員有志による運営です。アクセンチュアの社員による様々な発信をまとめています。なお、投稿内容は社員個人の見解であり、所属する組織を代表するものではありません。
Discussion