いま話題のReplit Agentを実際に触ってみました。
どんな感じのサービスなのか、どんな感じでアプリ開発ができるのかをざっくりですが紹介します。
参考になれば幸いです。
1.Replit Agentに生成してもらったアプリ
今回はTOEIC単語学習の進捗管理アプリを作成してみました。
よくある書籍などの単語帳だと以下のような課題があるので、これらを解決するアプリを作成みようと思いました。
- 覚えた単語とそうでない単語を効率よく整理できない。→ 視覚的に簡単にステータスを管理したい
- 書籍(本)と音声データ(アプリ)で分かれている → 一括で管理したい
- 今どれだけの単語を覚えてるか全体像が見えない → 視覚的に進捗率を数字として可視化したい
さっそくですが、Replit Agentに自然言語の指示出しだけで作ってもらったアプリのデモ動画をご覧ください。
2.アプリの要件定義書の作成
Xを見てるといきなりReplit Agentに指示出しするのではなく、要件定義書等を事前に生成AIに作らせてから指示出しするとよいという情報がトレンドになっていたので、まずはClaudeで作成したいアプリの要件定義書を作ってもらいました。
プロンプト例
TOEICで700点を目指すための、英単語、リスニング学習アプリを作成したいです。
このアプリの要件定義書を作成してください。
#英単語
700点に必要な英単語を以下のような形で管理する。
##各単語のステータス管理
以下の4つのステータスを各単語に対して割り当てられるようにする。
「学習中、インプット済み、熟知している、話せる」
上記の4つのステータスごとに列を用意して、単語のデータをマウス操作で簡単に列移動してステータスを管理できるようにする。
##各単語に紐づくデータ
* 意味
* 語源
* 発音
* コロケーション
* 例文
* 類似表現
何度か微修正して出来上がった要件定義書が以下です。
# TOEIC英単語学習アプリケーション 詳細設計書
## 1. データベース設計
### 1.1 テーブル一覧
1. words_word(単語マスタ)
2. words_studyhistory(学習履歴)
### 1.2 テーブル定義詳細
#### 1.2.1 単語マスタ(words_word)
| 項目名 | 物理名 | データ型 | NULL | キー | 説明 |
|-------|--------|----------|------|------|------|
| ID | id | SERIAL | NO | PK | 単語ID |
| 単語 | word | VARCHAR(100) | NO | | 英単語 |
| 意味 | meaning | TEXT | NO | | 日本語訳 |
| 発音記号 | pronunciation | VARCHAR(100) | NO | | 発音記号 |
| 語源 | etymology | TEXT | NO | | 語源説明 |
| 音声ファイル | audio_file | VARCHAR(200) | YES | | 発音音声のパス |
| コロケーション | collocations | JSONB | NO | | 関連語句リスト |
| 類似表現 | similar_expressions | JSONB | NO | | 類義語リスト |
| 例文 | example_sentences | JSONB | YES | | 用例リスト |
| メモ | notes | TEXT | YES | | 補足情報 |
| カテゴリ | category | VARCHAR(20) | NO | | 使用頻度区分 |
| ステータス | status | VARCHAR(20) | NO | | 学習状態 |
| 品詞 | part_of_speech | VARCHAR(20) | NO | | 品詞情報 |
| 作成日時 | created_at | TIMESTAMP | NO | | レコード作成日時 |
| 更新日時 | updated_at | TIMESTAMP | NO | | レコード更新日時 |
| 最終学習日時 | last_studied | TIMESTAMP | YES | | 最終学習日時 |
| 学習回数 | study_count | INTEGER | NO | | 累計学習回数 |
#### 1.2.2 学習履歴(words_studyhistory)
| 項目名 | 物理名 | データ型 | NULL | キー | 説明 |
|-------|--------|----------|------|------|------|
| ID | id | SERIAL | NO | PK | 履歴ID |
| 単語ID | word_id | INTEGER | NO | FK | 単語マスタの外部キー |
| 前回ステータス | previous_status | VARCHAR(20) | NO | | 変更前のステータス |
| 新ステータス | new_status | VARCHAR(20) | NO | | 変更後のステータス |
| 学習日時 | studied_at | TIMESTAMP | NO | | ステータス変更日時 |
## 2. 画面遷移設計
### 2.1 画面一覧
1. ダッシュボード画面
2. 単語管理(カンバンボード)画面
3. 単語登録・編集画面
4. フラッシュカード学習画面
5. テスト画面
6. 統計画面
### 2.2 画面遷移フロー
[ログイン] → [ダッシュボード]
├→ [単語管理] ←→ [単語登録・編集]
├→ [フラッシュカード学習]
├→ [テスト]
└→ [統計]
## 3. 機能設計
### 3.1 画面別機能一覧
#### 3.1.1 ダッシュボード
- 学習進捗サマリー表示
- カテゴリー別単語数グラフ
- ステータス別単語数グラフ
- 本日の学習推奨単語リスト
- 最近の学習履歴
#### 3.1.2 単語管理(カンバンボード)
- ステータス別単語一覧表示
- ドラッグ&ドロップによるステータス変更
- 単語検索・フィルタリング
- 単語詳細表示
- 単語の追加・編集・削除
#### 3.1.3 単語登録・編集
- 単語情報入力フォーム
- 音声ファイルアップロード
- バリデーションチェック
- 一括登録機能
#### 3.1.4 フラッシュカード学習
- ランダム出題
- カテゴリー別学習
- 正誤判定
- 学習履歴記録
- 復習アルゴリズムによる出題順序制御
### 3.2 共通機能
- ユーザー認証
- エラーハンドリング
- ログ出力
- バックアップ
- キャッシュ制御
## 7. 開発環境・ツール
### 7.1 開発環境
- Django 5.0以上
- Python 3.11以上
- PostgreSQL 15以上
- Nginx
- gunicorn
## 8. 学習データセット設計
### 8.1 データセット概要
#### 8.1.1 データ規模
- 総単語数:約3,000語
- カテゴリ別内訳:
- よく使う単語(Frequent):1,000語
- 時々使う単語(Regular):1,000語
- 稀に使う単語(Occasional):600語
- あまり使わない単語(Rare):400語
#### 8.1.2 データ収集方法
1. TOEIC頻出単語リスト
2. ビジネス英語コーパス
3. ETS公式問題集の語彙分析
4. ビジネスニュース用語
5. オフィス・職場関連用語
### 8.2 単語データ詳細設計
#### 8.2.1 品詞別分類
- 名詞:40%
- ビジネス用語
- 一般名詞
- 抽象概念
- 動詞:25%
- 基本動詞
- ビジネス関連動詞
- イディオム構成動詞
- 形容詞:20%
- 描写形容詞
- 評価形容詞
- ビジネス評価用語
- 副詞:10%
- 頻度副詞
- 様態副詞
- 程度副詞
- その他:5%
- 前置詞
- 接続詞
- 慣用句
#### 8.2.2 トピック別分類
1. ビジネス基本(30%)
- オフィス環境
- ビジネスプロセス
- 社内コミュニケーション
2. 業界・専門(25%)
- 金融・経済
- IT・テクノロジー
- マーケティング
- 人事・管理
3. ビジネスコミュニケーション(25%)
- メール・文書
- 会議・プレゼン
- 電話・商談
- 社交・マナー
4. 一般ビジネス(20%)
- 時事用語
- 文化・習慣
- 一般教養
### 8.3 学習リソース設計
#### 8.3.1 音声データ
- 形式:MP3
- 品質:44.1kHz, 128kbps
- 収録内容:
- アメリカ英語発音
- イギリス英語発音
- ナチュラルスピード
- スロースピード
#### 8.3.2 例文データベース
1. TOEIC形式例文(各単語3例)
- Part 5形式
- Part 6形式
- Part 7形式
2. ビジネスシーン例文(各単語2例)
- メール文例
- 会話文例
- 文書文例
#### 8.3.3 コロケーションデータ
- 一般的組み合わせ(3-5例)
- ビジネス特有の組み合わせ(2-3例)
- TOEIC頻出組み合わせ(2-3例)
3.Replit Agentにアプリ作成依頼を投げる
先ほどの要件定義書をそのままコピペしてReplit Agentにアプリ作成を依頼します。
投げたプロンプトは以下の通り。
以下の要件を満たすアプリを作成して
{ここに要件定義書の情報を張り付ける}

start buildingボタンを押すとアプリ生成が始まります・・・。
しばらくすると以下の用が画面が表示されて、アプリに実装したい機能のリストが提案されるので、組み込みたい機能にチェックを入れて続行します。

すると、早速データベースの生成が始まりました。。。

次はFlaskを使ってアプリの構築が続きます。。。
画面周りの生成も続きます。。。
足りないパッケージがあれば自動でインストールが続きます。。。
以下のようなメッセージが随時表示されて、何やら専用のエージェントたちがそれぞれの役割を処理しているようです。。。



しばらくするとアプリの作成が終わり、以下のようなログオン画面が表示されました。

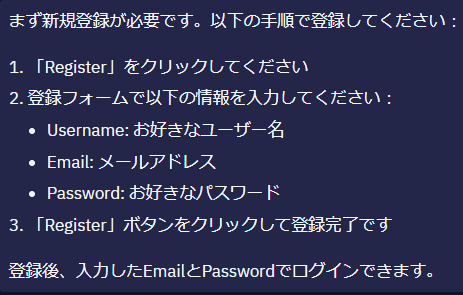
ユーザ名とパスワードがわからないので「ユーザ名とパスワードを教えて」と聞くと手順を教えてくれました。
ユーザ登録してログオンすると、以下のような画面が表示されました。
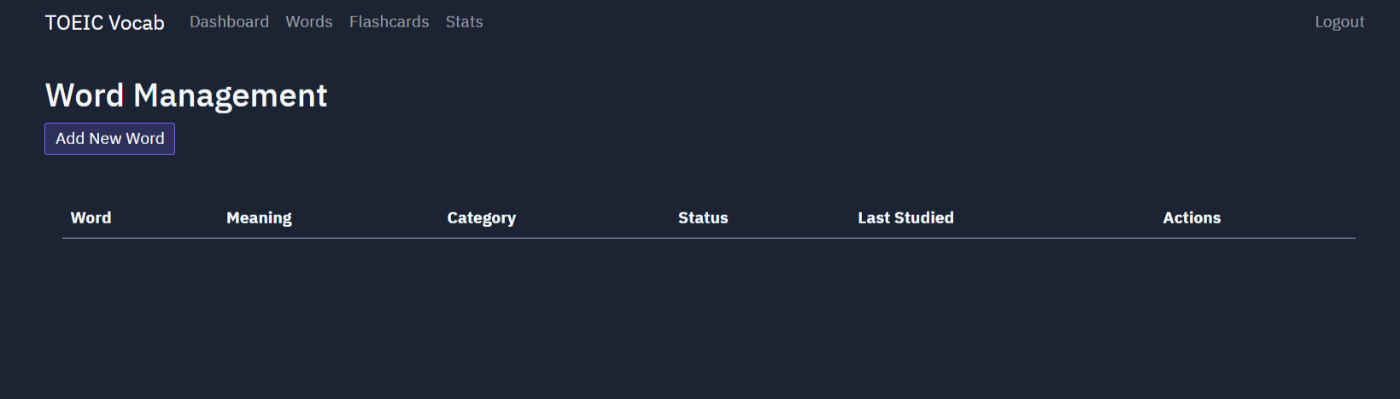
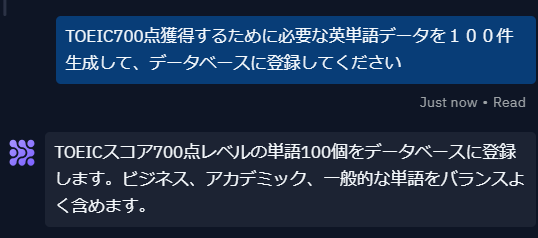
データが何もないようなので、「TOEIC700点獲得するために必要な英単語データを100件生成して、データベースに登録してください」と指示出ししてみると生成AIが単語データを生成した上でデータベースに自動でデータを登録してくれました。
後は、アプリを自分が望む形になるように修正依頼を出していきます。
エラーが出てWEB画面が表示されなくなったら修正指示を出すだけ勝手に直してくれます。
実際にデモ動画のアプリを作成するまでに指示出しした内容を以下にまとめましたので、どんな感じの指示出しをしたか雰囲気が伝わればよいかなと思います。







ちょっと驚いたのが、上図の最後の質問で音声データをつけてと指示だししたら、実際に各例文のところに再生アイコンが追加され、ボタンをクリックすると英文の発音音声が流れる機能が自動で追加されました・・・。

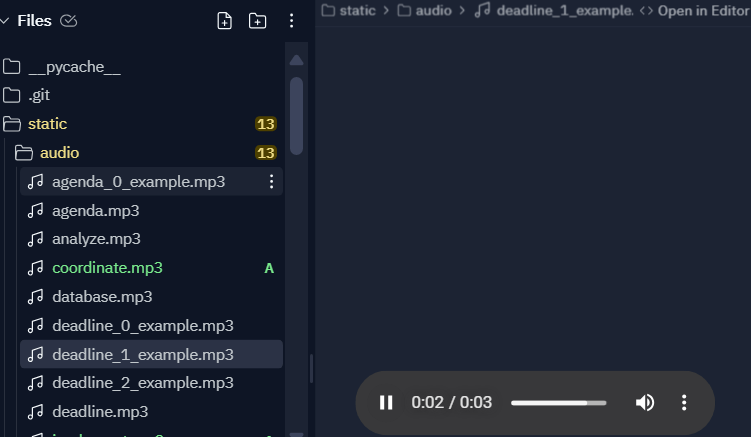
どうやって自動で実装されたかよくわかりませんが、生成されたプログラム内のディレクトリ(static/audio)配下を見ると、下図の通り、単語ごとに音声データが自動で生成されていました‥。凄すぎる・・・。
ちなみに、Replitの開発画面の左下には下図のようなTool群が表示されています。
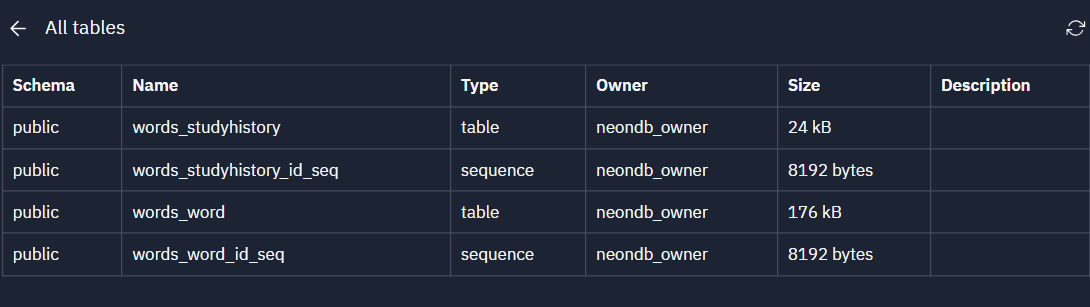
例えば、PostgreSQLをクリックすると、実際にデータベースに登録されているテーブル一覧やテーブル内のデータもマウス操作だけで簡単に確認することができます。
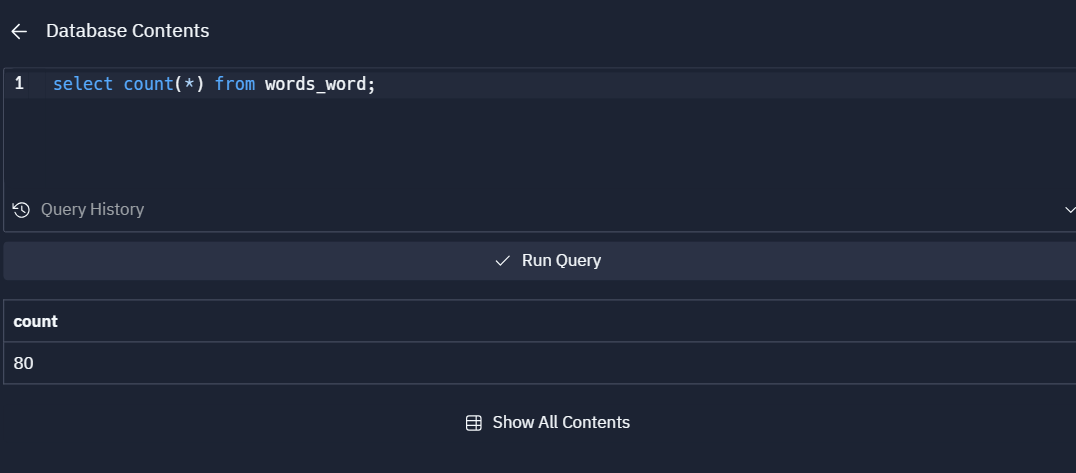
登録されているテーブル一覧
テーブルに登録されているデータ一覧

SQLクエリーを実行できる画面もあるので、自分でSQLを明示的に実行することもできます。
4.デプロイ(アプリの公開)
デプロイは画面右上の「Deploy」ボンタンから行います。
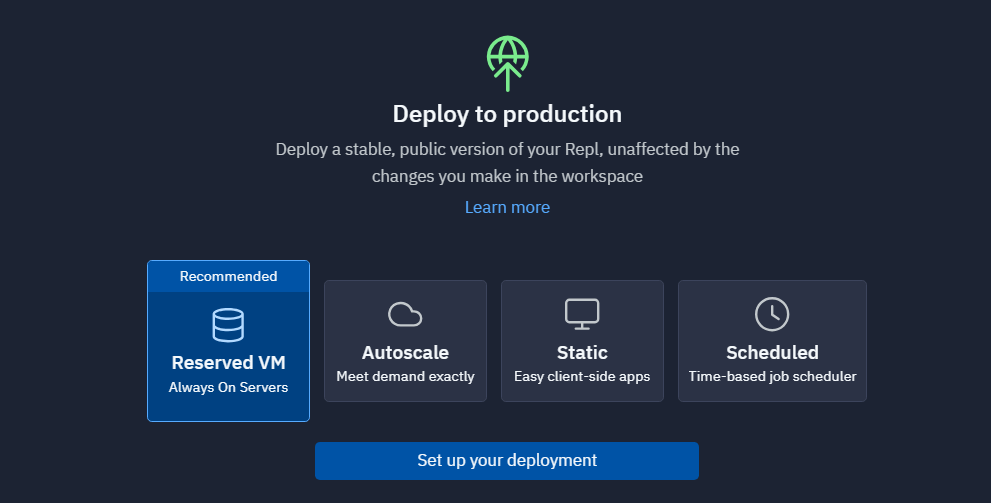
4つのデプロイオプションがありますが今回はとりあえず推奨のReserver VMでデプロイしてみました。
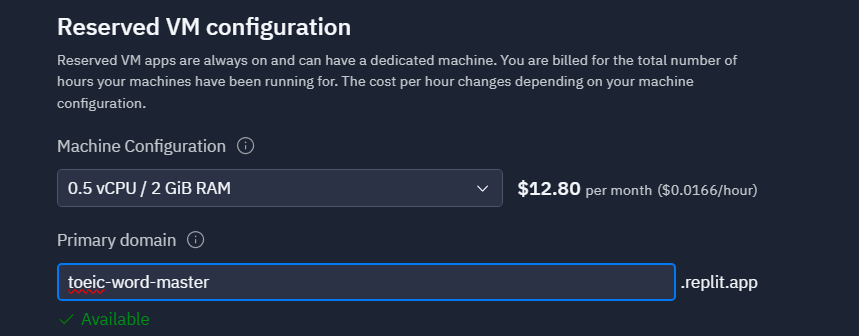
VMのスペックとドメイン名、APPタイプあたりを指定したら「Deploy」ボタンを押すだけで完了です。
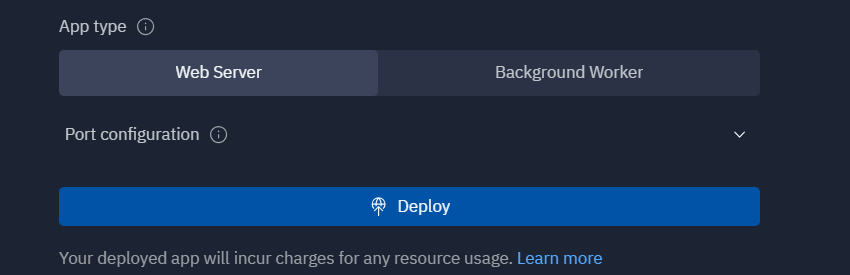
デプロイが完了(10分くらいで終わりました)すると以下のような画面が表示されました。
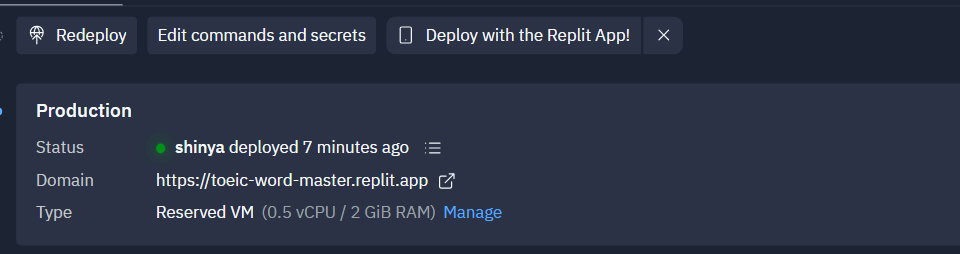
記載されているURLにアクセスするとアプリが使えるようになっていました。
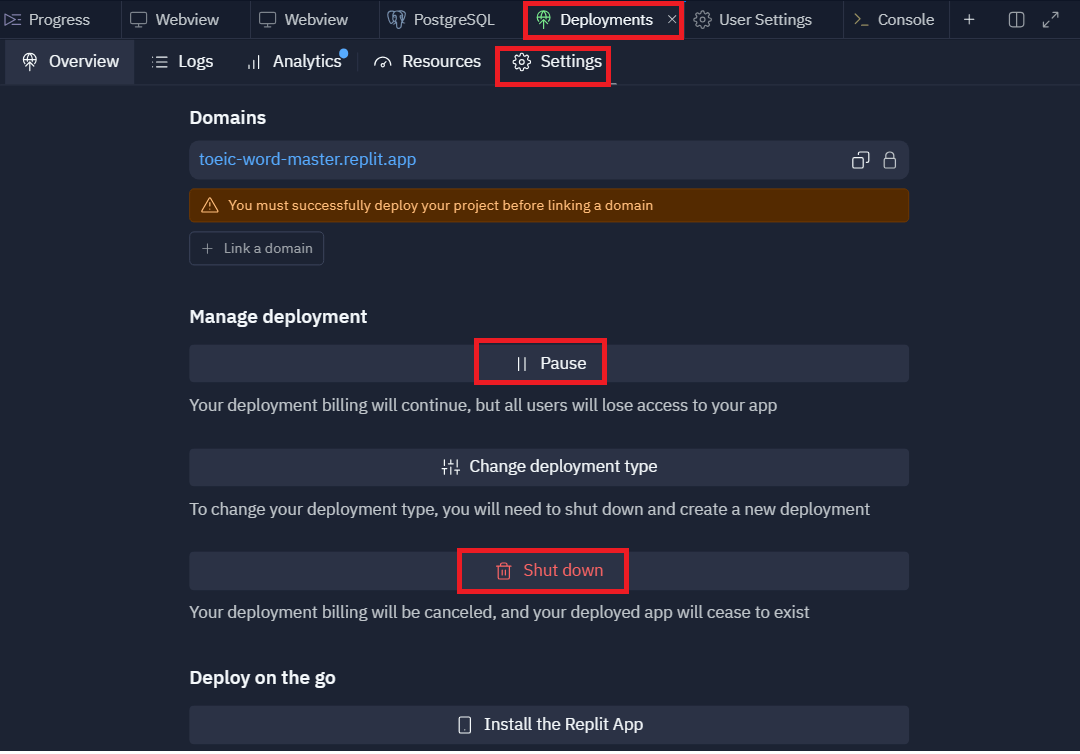
一旦デプロイしたWEBアプリは、Deployments→Settingsからユーザアクセスを停止(PAUSE)したり、アプリ自体を削除(Shut down)が簡単にできるようになっています。
Replitのデプロイメントタイプ比較
| 特徴 | Autoscale | Reserved VM | Static | Scheduled |
|---|---|---|---|---|
| 主な用途 | ウェブサイト、Webアプリ、API、マイクロサービス | 長時間実行/計算集約型アプリ | 静的コンテンツ配信 | 定期実行タスク |
| スケーリング | 水平スケーリング可能 | 単一VMで固定 | なし | なし |
| 稼働率保証 | 99.95% | 99.9% | - | - |
| リソース | トラフィックに応じて変動 | 柔軟なマシンサイズ | - | 1vCPU/2GiB RAM |
| 料金体系 | トラフィックに応じた従量課金 | 固定料金 | コスト効率的 | Core会員は$10/月クレジット付与 |
| 実行時間制限 | リクエストベース | なし | - | 11時間 |
| 適している ワークロード |
• HTTPサーバー • HTTP/2 • WebSocket • gRPC |
• バックグラウンド処理 • 長時間接続(ボット) • 再起動に弱いアプリ |
• ポートフォリオ • 個人サイト • ランディングページ |
• バッチ処理 • 定期メンテナンス • 自動化タスク |
| 非推奨の ワークロード |
• バックグラウンド処理 • 並列インスタンス非対応 • 並列リクエスト非対応 • 再起動に弱いアプリ |
- | - | - |
永続ストレージについて
- すべてのデプロイメントタイプで、ファイルシステムへの保存データは再デプロイ後に消失
- 利用可能な永続ストレージオプション:
- オブジェクトストレージ
- PostgreSQL
- ReplDB (KV)
Reserved VMは時間単位で課金され、料金は1時間あたり0.00833ドルからと記載あがります。
※156円換算で、だいたい月額1000円~
5.その他
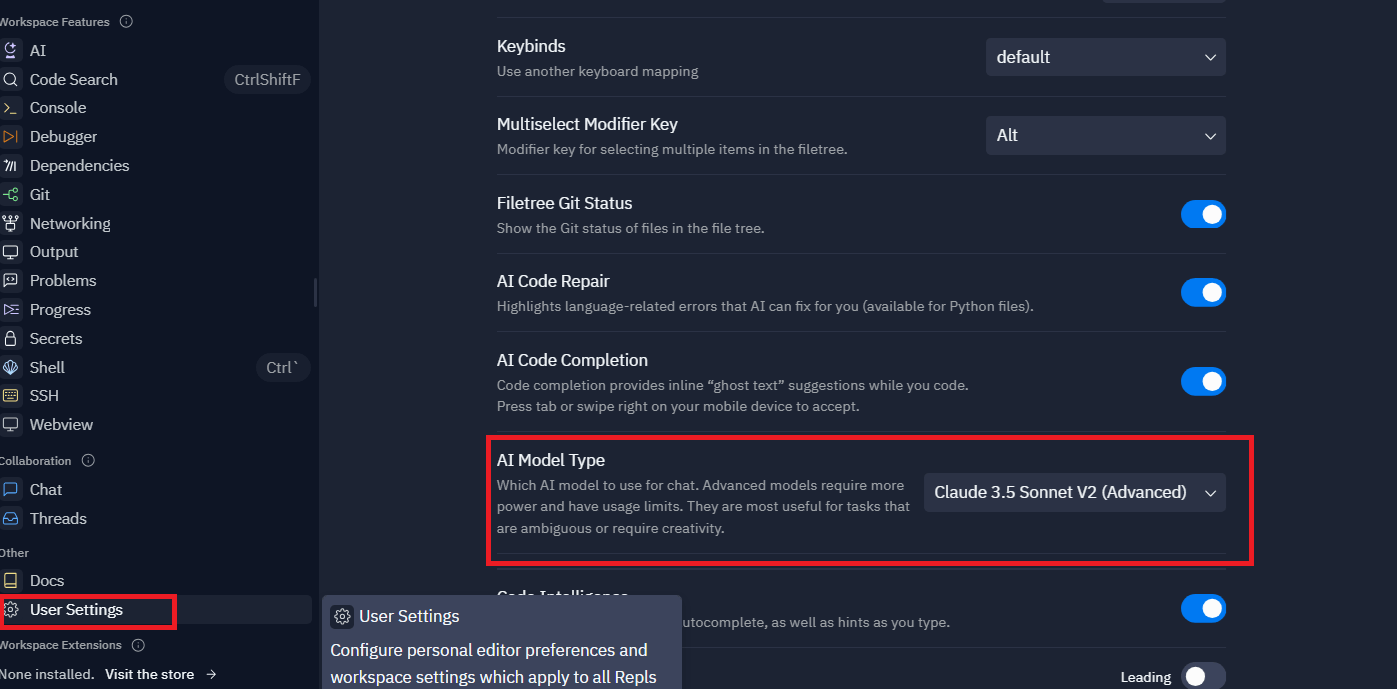
Replitの開発画面の左下の方を見ると、Toolsというメニューがありその中にいろいろな機能があります。
利用するAIモデルの変更
User settingsから切り替えられます。
コード内の横断検索
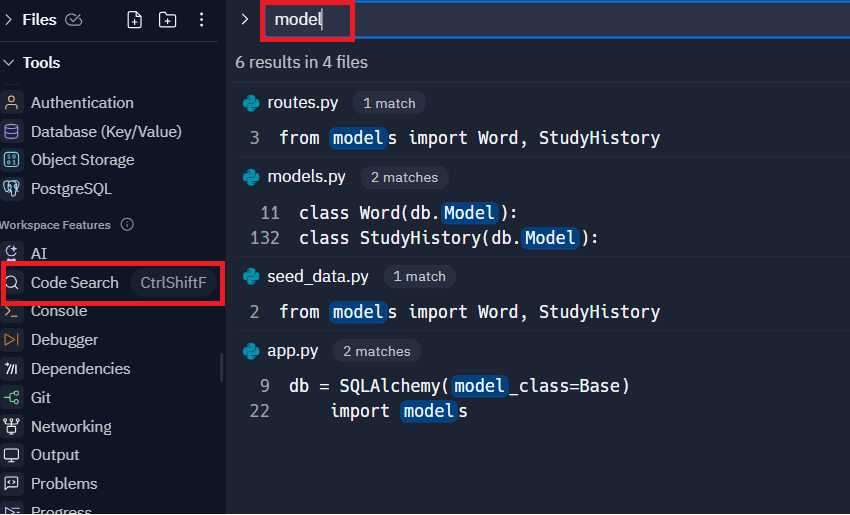
Workspace Features -> Code Searchから使えるコード内検索機能が何気に便利です。
検索フォームに文字列を入れると、開発された全体プロジェクト内に存在するファイルに対して横断検索してくれるようです。
開発されたコードに対してQ&Aを投げれる
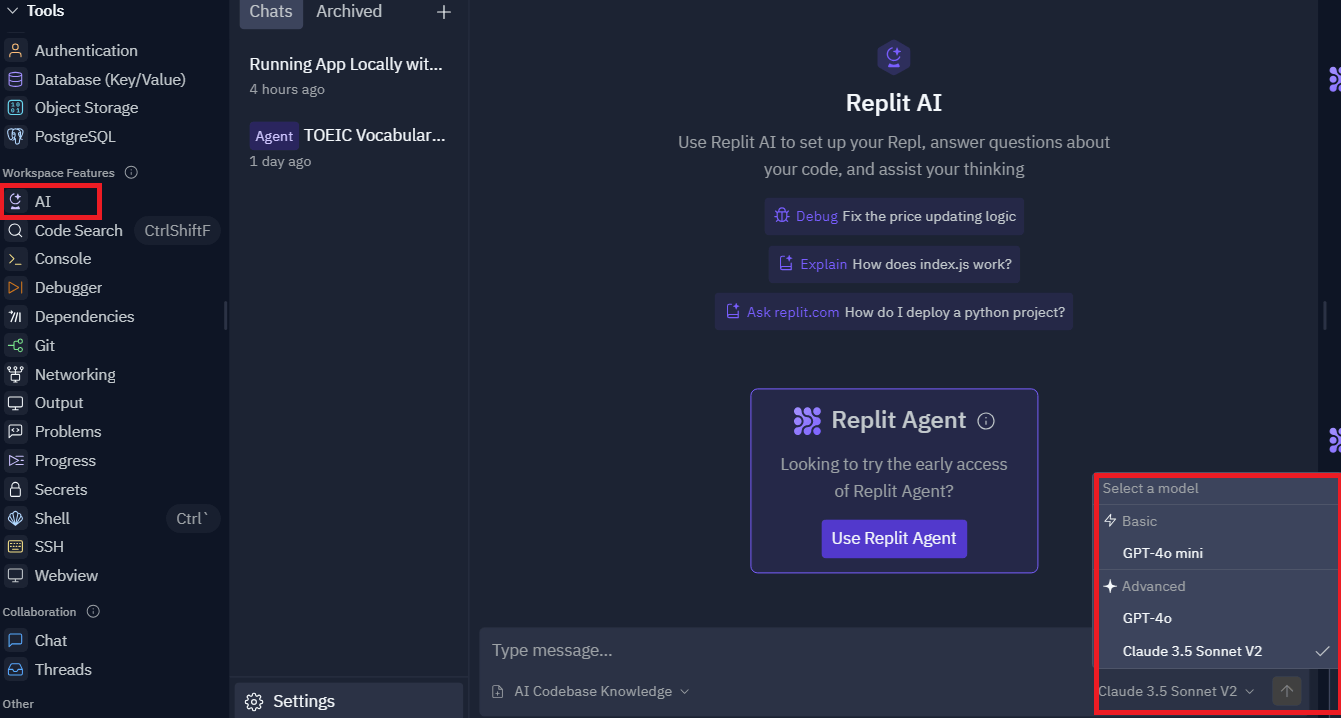
Workspace Features -> AIからモデルを指定してチャットで生成されたコードに対していろいろ質問できるようです。
その他、気になった点は、開発環境として以下を指定しましたが実際はFlaskが採用されました。
### 7.1 開発環境
- Django 5.0以上
- Python 3.11以上
- PostgreSQL 15以上
- Nginx
- gunicorn
Replit Agentがサポートしている技術スタックの組み合わせじゃないと指示した通の組み合わせでは開発してくれず、一番近しい技術スタックの組み合わせで開発されるようですね。

アクセンチュア株式会社に所属する社員有志による運営です。アクセンチュアの社員による様々な発信をまとめています。なお、投稿内容は社員個人の見解であり、所属する組織を代表するものではありません。
Discussion
*.replit.app のドメインをIP引いたら 34.117.33.233 で、これ、Google Cloud 所有とのことだから、Replit 自体はGCP上で稼働、なんですかねー