はじめに
ClaudeのPDF読み取り機能が強化されています。
PDF機能の内容
ドキュメントからPDF機能の内容を見ていきましょう。
できること
テキスト、画像、チャート、表など、PDF 内のあらゆる要素がインプットの対象になります。
具体的な使用例があげられています。
- 財務報告書の分析とチャート/表の理解
- 法律文書からの重要情報の抽出
- 文書の翻訳支援
- 文書情報の構造化フォーマットへの変換
仕組み
PDFファイルを含むリクエストを送信すると、以下の手順で処理されると書かれています。
これまでの生成AIアプリのPDF解析はテキスト抽出のみでしたが、ClaudeのPDF機能ではテキスト抽出に加えてページを画像変換したうえで画像分析も含まれる点、より精度高いPDF解析ができそうです。
- 文書内容の抽出:文書の各ページが画像に変換される
- 各ページからテキストが抽出され、ページ画像と共に提供される
- テキストと画像の分析:Claude はテキストと画像の両方を分析し、文書をより深く理解する
- 文書は分析のためにテキストと画像の組み合わせとして提供される
制約事項
ファイルが以下の要件があるようです。
- リクエストサイズ: 最大 32MB
- リクエストあたりの最大ページ数: 100ページ
これらの制限は、PDF と共に送信される他のコンテンツを含む、リクエストペイロード全体に適用されます。また、提供される PDF にはパスワードや暗号化が設定されていない必要があります。
他のClaude機能との組み合わせ
特に1つのPDFに対して様々な質問をする場合、プロンプトキャッシングが有効になりそうです。
- プロンプトキャッシュ: 繰り返し分析のパフォーマンス向上
- バッチ処理: 大量文書処理
使ってみる インプットファイル
観光庁の「訪日外客統計」の「2024年9月推計値(2024年10月16日発表)(PDF)」をインプットにしました!
使ってみる ClaudeのWeb画面(Visual PDFs)
設定方法
Claudeの画面の左メニューに「Feature Preview」があるのでクリックします。
「Visual PDFs」があるので、トグルをOnにします。

これで使えるようになります。
操作方法
ここまでできたら、あとはPDFを添付して質問するだけです。
下記のようにPDFの内容を分析して回答してくれます。
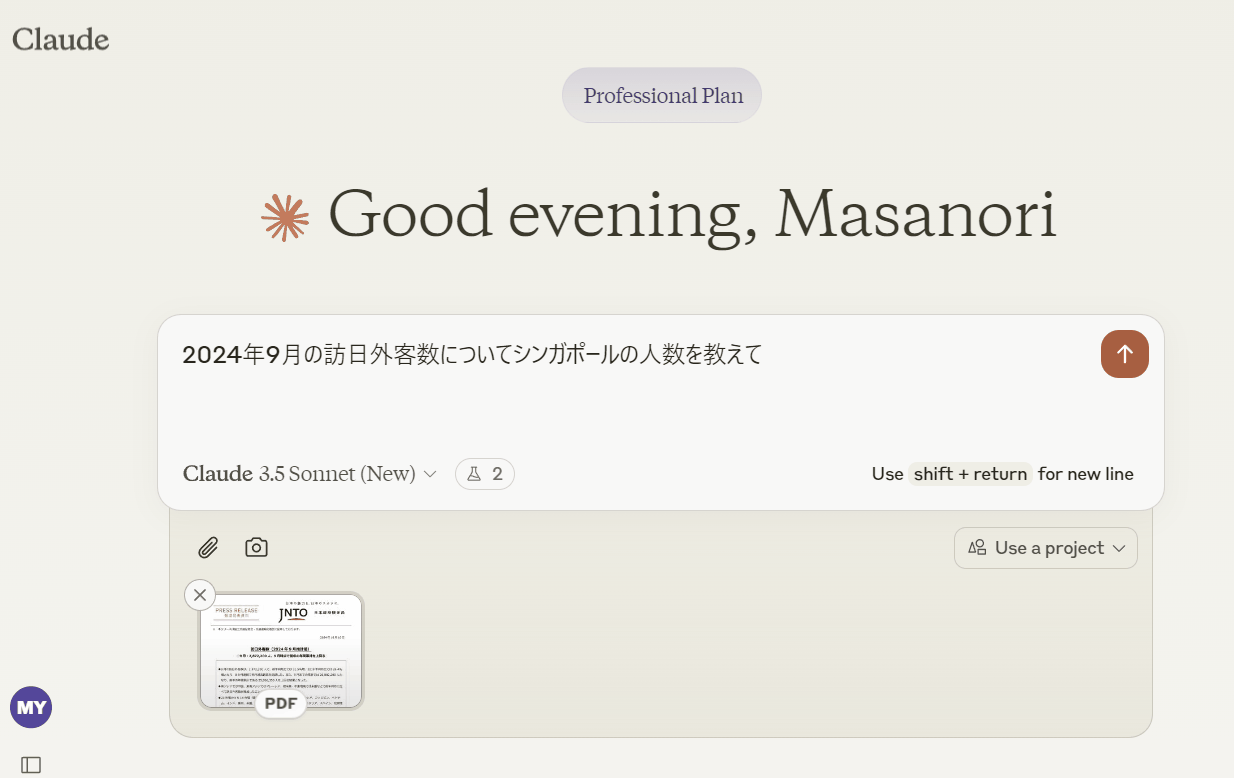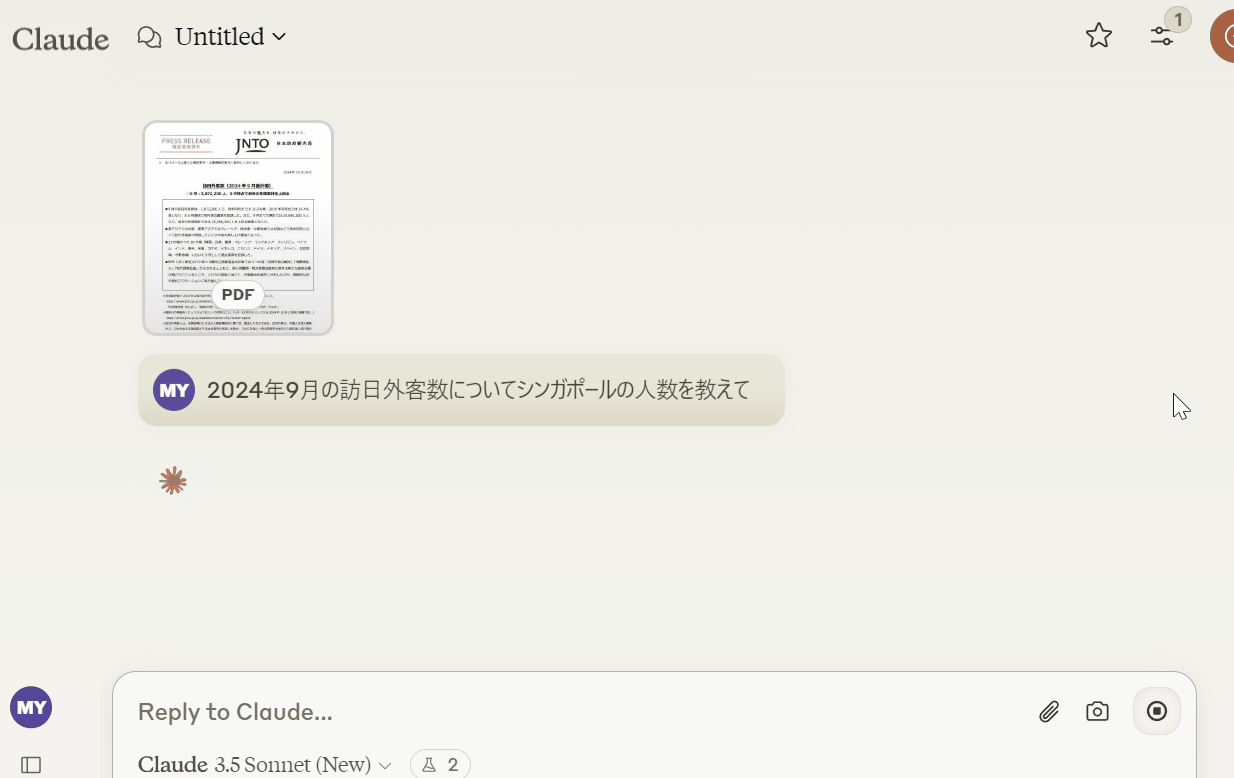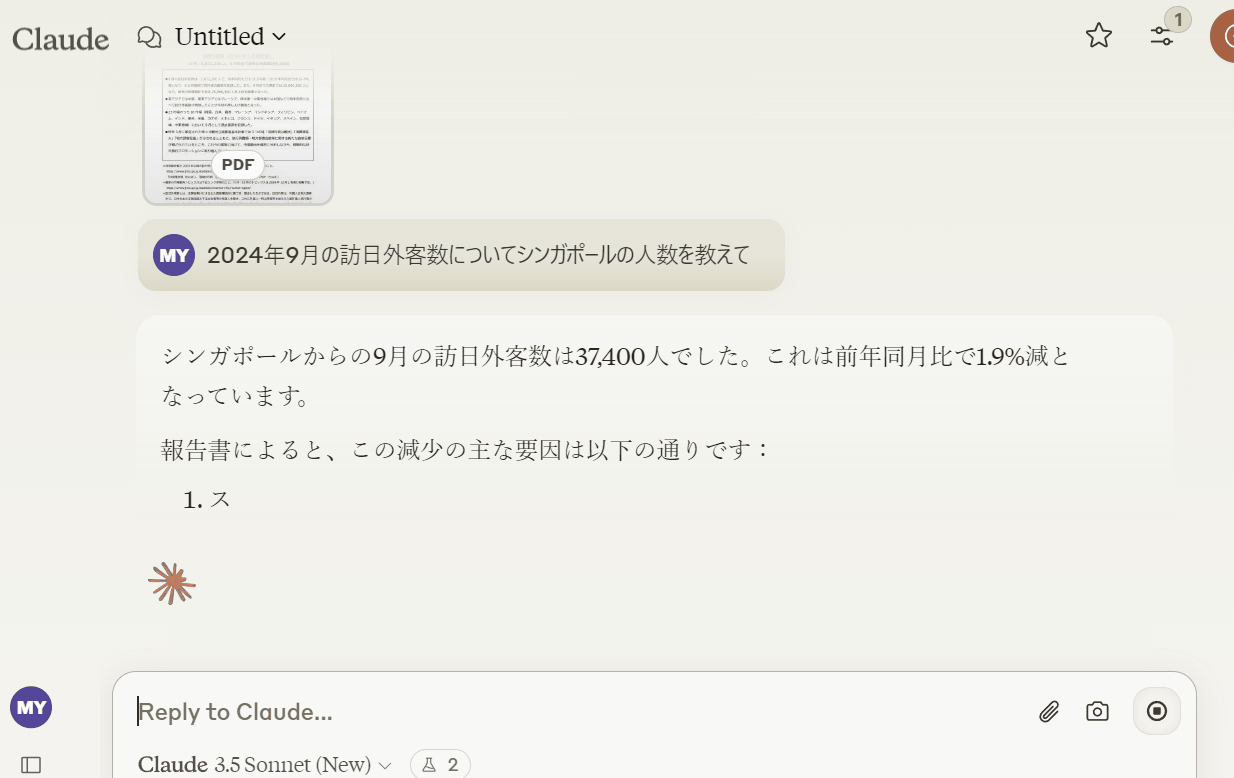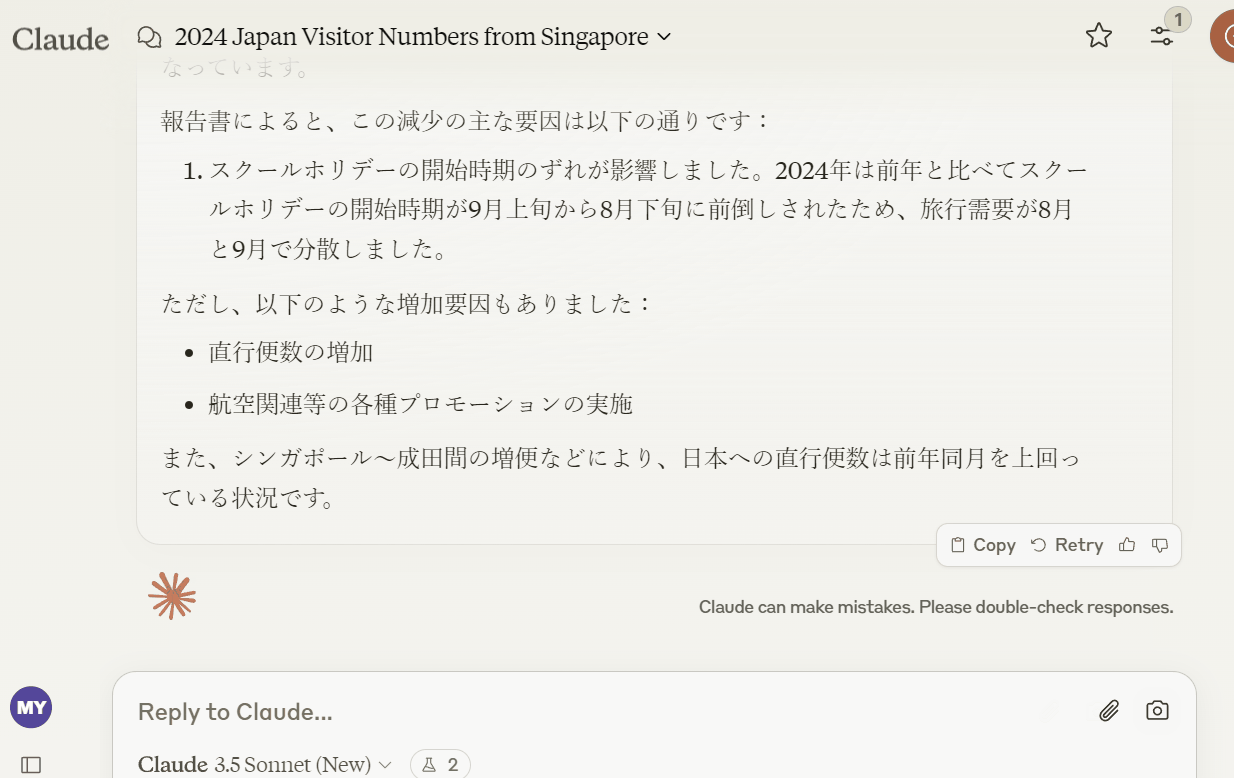
上記以外にも表にしか記載されていない情報(例:2019年のシンガポールからの訪日外客数)も回答してくれました。

使ってみる API
開発、実行環境
開発と実行はGoogle Colabで行います。
また、Input、OutputするファイルはGoogle Driveを使用します。
実装
まずは、Anthropicのライブラリをインストールします。
!pip install anthropic
必要なライブラリをインポートします。
import anthropic
import base64
from google.colab import drive
from google.colab import auth
from googleapiclient.discovery import build
from googleapiclient.http import MediaIoBaseDownload, MediaFileUpload
from googleapiclient.http import MediaIoBaseUpload
import io
import os
AnthropicのAPIキーを設定します。
client = anthropic.Anthropic(
api_key="XXX",
)
Google DriveのファイルInput、Output周りの処理と関数定義をします。
# Google Driveをマウント
drive.mount('/content/drive')
# Google Driveの認証
auth.authenticate_user()
# Drive APIを初期化
drive_service = build('drive', 'v3')
def get_folder_id(folder_path):
"""指定されたパスのフォルダIDを取得する"""
folder_name = os.path.basename(folder_path)
results = drive_service.files().list(
q=f"mimeType='application/vnd.google-apps.folder' and name='{folder_name}'",
fields="files(id)"
).execute()
items = results.get('files', [])
if not items:
raise FileNotFoundError(f"Folder '{folder_name}' not found in Google Drive")
return items[0]['id']
def list_files_in_folder(folder_id):
"""フォルダ内のPDFファイル一覧を取得する"""
results = drive_service.files().list(
q=f"'{folder_id}' in parents and mimeType='application/pdf'",
fields="files(id, name)"
).execute()
return results.get('files', [])
def download_file(file_id):
"""
指定されたファイルIDのファイルをダウンロードする
"""
request = drive_service.files().get_media(fileId=file_id)
fh = io.BytesIO()
downloader = MediaIoBaseDownload(fh, request)
done = False
while done is False:
status, done = downloader.next_chunk()
return fh.getvalue()
def upload_file(file_name, file_content, mime_type, parent_folder_id):
"""ファイルを指定されたフォルダにアップロードする"""
file_metadata = {
'name': file_name,
'parents': [parent_folder_id]
}
if isinstance(file_content, str):
file_content = io.BytesIO(file_content.encode())
elif not isinstance(file_content, io.BytesIO):
raise ValueError("file_content must be either str or BytesIO object")
media = MediaIoBaseUpload(file_content, mimetype=mime_type, resumable=True)
file = drive_service.files().create(body=file_metadata, media_body=media, fields='id').execute()
return file.get('id')
実際にCloudeを呼び出す関数を定義します。
モデルは、「claude-3-5-sonnet-20241022」を指定しましょう。
関数「client.beta.messages.create」を使っている点気を付けましょう。PDF機能はまだベータ版でこの関数を使う必要がありそうです。
パラメータ「betas=["pdfs-2024-09-25", "prompt-caching-2024-07-31"]」を設定します。PDF機能とキャッシュ機能が有効になります。
def analyze_pdf_with_claude(pdf_data, file_name):
pdf_base64 = base64.b64encode(pdf_data).decode('utf-8')
prompt = f"""2019年9月の訪日外客数についてシンガポールの人数を教えて"""
message = client.beta.messages.create(
model="claude-3-5-sonnet-20241022",
betas=["pdfs-2024-09-25", "prompt-caching-2024-07-31"],
max_tokens=4096,
messages=[
{
"role": "user",
"content": [
{
"type": "document",
"source": {
"type": "base64",
"media_type": "application/pdf",
"data": pdf_base64,
},
},
{
"type": "text",
"text": prompt
}
],
}
],
)
return message.content[0].text
最後にメイン処理を実装します。
# メイン処理
input_folder_path = '/content/drive/MyDrive/claude_pdf_demo/input'
output_folder_path = '/content/drive/MyDrive/claude_pdf_demo/output'
# 入力フォルダと出力フォルダのIDを取得
input_folder_id = get_folder_id(input_folder_path)
output_folder_id = get_folder_id(output_folder_path)
# フォルダ内のファイル一覧を取得
files = list_files_in_folder(input_folder_id)
for file in files:
print(f"Processing file: {file['name']}")
# ファイルをダウンロード
pdf_data = download_file(file['id'])
# Claudeで画像を解析
analysis_result = analyze_pdf_with_claude(pdf_data, file['name'])
# 結果をGoogle Driveに保存
output_file_name = f"analysis_{file['name']}.txt"
# upload_file(output_file_name, analysis_result, 'text/plain')
uploaded_file_id = upload_file(output_file_name, analysis_result, 'text/plain', output_folder_id)
print(f"Analysis result for {file['name']} has been saved as '{output_file_name}' in your Google Drive.")
print("All files have been processed.")
実行結果は下記となります。ClaudeのWebからより端的な回答になっていますね。
おそらく、ClaudeのWebではこまかくSystemプロンプトが設定されているのではと推測しています。
ドキュメントの中から、2019年9月のシンガポールからの訪日外客数を確認すると、29,147人でした。これは参考資料の表から読み取れる数値です。
さいごに
いかがでしたか。Claudeを活用してPDFを精度高くテキストにアウトプットする方法がご理解いただけたら幸いです。この記事の件名に「パワポ」という単語がありますが、PowerPointファイルもPDFに変換ができるため、PowerPointのドキュメントもPDFへ変換したうえで精度高くテキストにアウトプットできます。
多くの企業で業務情報をRAGに取り込んで生成AIを活用していると思いますが、グラフや図についてはなかなかテキスト化が難しかったのではと推察しています。このような課題についてもClaudeを活用すれば、精度高くテキスト化してRAGに取り込むことができるのではと考えています。

アクセンチュア株式会社に所属する社員有志による運営です。アクセンチュアの社員による様々な発信をまとめています。なお、投稿内容は社員個人の見解であり、所属する組織を代表するものではありません。
Discussion