自然言語で分析できるPandasAIライブラリの使い方
今回は、自然言語でデータ分析できるPandasAIライブラリの使い方を整理してみましたので、ご紹介します。
PandaAIとは?
PandasAIは、自然言語でデータに質問することを容易にするPythonプラットフォームです。これは、技術者以外のユーザーがより自然な方法でデータを操作できるようにし、ユーザーがデータを操作する際の時間と労力を節約するのに役立ちます。
基本的な使い方
事前準備
pip install pandasai japanize-matplotlib
pip install pandasai[plotly]
2024/9月時点では、pandasでファイルを読み込もうとすると以下のエラーが出てしまうので、numpyのバージョンをダウングレードする必要があります。
ValueError: numpy.dtype size changed, may indicate binary incompatibility. Expected 96 from C header, got 88 from PyObject
pip install numpy==1.26.4
pip install pyyaml
PandasAIの拡張機能
PandasAIライブラリの機能を拡張する追加パッケージが用意されています。
拡張機能は以下のコマンドでインストールできます:
pip install pandasai[extra-dependency-name]
extra-dependency-name を以下の表にある拡張機能名に置き換えることでインストールできます。
| 拡張機能名 | 概要 | 使用例 |
|---|---|---|
| google-ai | Google PaLMを言語モデルとして使用 | - 複雑なデータ分析タスクの自然言語による記述 - データセットに関する洞察を自然言語で生成 |
| google-sheet | Google Sheetsをデータソースとして利用 | - オンラインで共有されている調査データの分析 - リアルタイムで更新される売上データの処理 |
| excel | Excelファイルをデータソースとして使用 | - 財務レポートの自動分析 - 複数のExcelシートにまたがるデータの統合と分析 |
| modin | Modinデータフレームのサポート | - ビッグデータの高速処理 - 複数のCPUコアを活用した並列データ処理 |
| polars | Polarsデータフレームのサポート | - 時系列データの高速処理 - メモリ効率の良いデータ操作 |
| langchain | LangChain LLMsのサポート | - 複数の言語モデルを組み合わせたデータ分析 - LLMを活用した高度なデータ解釈 |
| numpy | NumPyのサポート | - 複雑な数学的操作を含むデータ分析 - 多次元配列の処理 |
| ggplot | ggplotによるプロッティング | - 統計的なデータビジュアライゼーション - プログラマティックなグラフ生成 |
| seaborn | seabornによるプロッティング | - 統計データの視覚化 - 複雑な多変量データセットの可視化 |
| plotly | plotlyによるプロッティング | - インタラクティブなデータ可視化 - ダッシュボード用の動的グラフ作成 |
| statsmodels | 統計モデリングのサポート | - 時系列分析 - 回帰分析や仮説検定 |
| scikit-learn | 機械学習のサポート | - 予測モデルの作成 - クラスタリングや次元削減 |
| streamlit | 対話型Webアプリケーションの作成 | - データ分析ダッシュボードの作成 - エンドユーザー向けの分析ツールの開発 |
| ibm-watsonx-ai | IBM watsonx.aiをモデルとして使用 | - エンタープライズレベルのAI機能の統合 - IBM独自の言語モデルを活用したデータ分析 |
サンプルデータの準備
今回は、以下のような架空の作業時間データを使います。
以下のデータをコピペしてsample_data.csvという名前で保存しておきましょう。
日付,ユーザー名,プロジェクト名,サブプロジェクト名,タスクID,作業時間(時間単位),作業区分,コメント
2023-10-01, 田中 太郎, システム開発プロジェクト, フロントエンド開発, SD-FE-001, 2.5, 設計, 初期設定
2023-10-01, 鈴木 花子, ウェブサイトリニューアル, デザイン, WR-D-001, 1.0, 修正, バグ修正
2023-10-02, 佐藤 次郎, システム開発プロジェクト, バックエンド開発, SD-BE-001, 3.0, 開発, 機能開発
2023-10-02, 高橋 美咲, モバイルアプリ開発, UI/UXデザイン, MA-UI-001, 4.0, レビュー, コードレビュー
2023-10-03, 伊藤 健一, ウェブサイトリニューアル, コンテンツ作成, WR-C-001, 2.0, テスト, テスト
2023-10-03, 田中 太郎, システム開発プロジェクト, フロントエンド開発, SD-FE-002, 1.5, ドキュメント, ドキュメント作成
2023-10-04, 鈴木 花子, モバイルアプリ開発, API開発, MA-API-001, 3.5, 会議, 会議
2023-10-04, 佐藤 次郎, ウェブサイトリニューアル, デザイン, WR-D-002, 2.5, リファクタリング, コードリファクタリング
2023-10-05, 高橋 美咲, システム開発プロジェクト, バックエンド開発, SD-BE-002, 4.0, 開発, 機能開発
2023-10-05, 伊藤 健一, モバイルアプリ開発, テスト, MA-T-001, 1.0, 修正, バグ修正
2023-10-06, 田中 太郎, ウェブサイトリニューアル, コンテンツ作成, WR-C-002, 3.0, テスト, テスト
2023-10-06, 鈴木 花子, システム開発プロジェクト, フロントエンド開発, SD-FE-003, 2.0, ドキュメント, ドキュメント作成
2023-10-07, 佐藤 次郎, モバイルアプリ開発, UI/UXデザイン, MA-UI-002, 4.5, 会議, 会議
2023-10-07, 高橋 美咲, ウェブサイトリニューアル, デザイン, WR-D-003, 1.5, リファクタリング, コードリファクタリング
2023-10-08, 伊藤 健一, システム開発プロジェクト, バックエンド開発, SD-BE-003, 3.5, 開発, 機能開発
2023-10-08, 田中 太郎, モバイルアプリ開発, API開発, MA-API-002, 2.0, 修正, バグ修正
2023-10-09, 鈴木 花子, ウェブサイトリニューアル, コンテンツ作成, WR-C-003, 4.0, テスト, テスト
2023-10-09, 佐藤 次郎, システム開発プロジェクト, フロントエンド開発, SD-FE-004, 1.0, ドキュメント, ドキュメント作成
2023-10-10, 高橋 美咲, モバイルアプリ開発, UI/UXデザイン, MA-UI-003, 3.0, 会議, 会議
2023-10-10, 伊藤 健一, ウェブサイトリニューアル, デザイン, WR-D-004, 2.5, リファクタリング, コードリファクタリング
2023-10-11, 田中 太郎, システム開発プロジェクト, バックエンド開発, SD-BE-004, 4.0, 開発, 機能開発
2023-10-11, 鈴木 花子, モバイルアプリ開発, API開発, MA-API-003, 1.5, 修正, バグ修正
2023-10-12, 佐藤 次郎, ウェブサイトリニューアル, コンテンツ作成, WR-C-004, 3.0, テスト, テスト
2023-10-12, 高橋 美咲, システム開発プロジェクト, フロントエンド開発, SD-FE-005, 2.0, ドキュメント, ドキュメント作成
2023-10-13, 伊藤 健一, モバイルアプリ開発, UI/UXデザイン, MA-UI-004, 4.5, 会議, 会議
2023-10-13, 田中 太郎, ウェブサイトリニューアル, デザイン, WR-D-005, 1.0, リファクタリング, コードリファクタリング
2023-10-14, 鈴木 花子, システム開発プロジェクト, バックエンド開発, SD-BE-005, 3.5, 開発, 機能開発
2023-10-14, 佐藤 次郎, モバイルアプリ開発, API開発, MA-API-004, 2.0, 修正, バグ修正
2023-10-15, 高橋 美咲, ウェブサイトリニューアル, コンテンツ作成, WR-C-005, 4.0, テスト, テスト
2023-10-15, 伊藤 健一, システム開発プロジェクト, フロントエンド開発, SD-FE-006, 1.5, ドキュメント, ドキュメント作成
2023-10-16, 田中 太郎, システム開発プロジェクト, フロントエンド開発, SD-FE-007, 2.5, 設計, 初期設定
2023-10-16, 鈴木 花子, ウェブサイトリニューアル, デザイン, WR-D-006, 1.0, 修正, バグ修正
2023-10-17, 佐藤 次郎, システム開発プロジェクト, バックエンド開発, SD-BE-006, 3.0, 開発, 機能開発
2023-10-17, 高橋 美咲, モバイルアプリ開発, UI/UXデザイン, MA-UI-005, 4.0, レビュー, コードレビュー
2023-10-18, 伊藤 健一, ウェブサイトリニューアル, コンテンツ作成, WR-C-006, 2.0, テスト, テスト
2023-10-18, 田中 太郎, システム開発プロジェクト, フロントエンド開発, SD-FE-008, 1.5, ドキュメント, ドキュメント作成
2023-10-19, 鈴木 花子, モバイルアプリ開発, API開発, MA-API-005, 3.5, 会議, 会議
2023-10-19, 佐藤 次郎, ウェブサイトリニューアル, デザイン, WR-D-007, 2.5, リファクタリング, コードリファクタリング
2023-10-20, 高橋 美咲, システム開発プロジェクト, バックエンド開発, SD-BE-007, 4.0, 開発, 機能開発
2023-10-20, 伊藤 健一, モバイルアプリ開発, テスト, MA-T-002, 1.0, 修正, バグ修正
2023-10-21, 田中 太郎, ウェブサイトリニューアル, コンテンツ作成, WR-C-007, 3.0, テスト, テスト
2023-10-21, 鈴木 花子, システム開発プロジェクト, フロントエンド開発, SD-FE-009, 2.0, ドキュメント, ドキュメント作成
2023-10-22, 佐藤 次郎, モバイルアプリ開発, UI/UXデザイン, MA-UI-006, 4.5, 会議, 会議
2023-10-22, 高橋 美咲, ウェブサイトリニューアル, デザイン, WR-D-008, 1.5, リファクタリング, コードリファクタリング
2023-10-23, 伊藤 健一, システム開発プロジェクト, バックエンド開発, SD-BE-008, 3.5, 開発, 機能開発
2023-10-23, 田中 太郎, モバイルアプリ開発, API開発, MA-API-006, 2.0, 修正, バグ修正
2023-10-24, 鈴木 花子, ウェブサイトリニューアル, コンテンツ作成, WR-C-008, 4.0, テスト, テスト
2023-10-24, 佐藤 次郎, システム開発プロジェクト, フロントエンド開発, SD-FE-010, 1.0, ドキュメント, ドキュメント作成
2023-10-25, 高橋 美咲, モバイルアプリ開発, UI/UXデザイン, MA-UI-007, 3.0, 会議, 会議
2023-10-25, 伊藤 健一, ウェブサイトリニューアル, デザイン, WR-D-009, 2.5, リファクタリング, コードリファクタリング
2023-10-26, 田中 太郎, システム開発プロジェクト, バックエンド開発, SD-BE-009, 4.0, 開発, 機能開発
2023-10-26, 鈴木 花子, モバイルアプリ開発, API開発, MA-API-007, 1.5, 修正, バグ修正
2023-10-27, 佐藤 次郎, ウェブサイトリニューアル, コンテンツ作成, WR-C-009, 3.0, テスト, テスト
2023-10-27, 高橋 美咲, システム開発プロジェクト, フロントエンド開発, SD-FE-011, 2.0, ドキュメント, ドキュメント作成
2023-10-28, 伊藤 健一, モバイルアプリ開発, UI/UXデザイン, MA-UI-008, 4.5, 会議, 会議
2023-10-28, 田中 太郎, ウェブサイトリニューアル, デザイン, WR-D-010, 1.0, リファクタリング, コードリファクタリング
2023-10-29, 鈴木 花子, システム開発プロジェクト, バックエンド開発, SD-BE-010, 3.5, 開発, 機能開発
2023-10-29, 佐藤 次郎, モバイルアプリ開発, API開発, MA-API-008, 2.0, 修正, バグ修正
2023-10-30, 高橋 美咲, ウェブサイトリニューアル, コンテンツ作成, WR-C-010, 4.0, テスト, テスト
2023-10-30, 伊藤 健一, システム開発プロジェクト, フロントエンド開発, SD-FE-012, 1.5, ドキュメント, ドキュメント作成
2023-10-31, 田中 太郎, システム開発プロジェクト, フロントエンド開発, SD-FE-013, 2.5, 設計, 初期設定
2023-10-31, 鈴木 花子, ウェブサイトリニューアル, デザイン, WR-D-011, 1.0, 修正, バグ修正
まずは、上記ファイルを読み込んで表示してみます。
csvと同じフォルダにsample.pyを作成して以下のコードを記載します。
import pandas as pd
df = pd.read_csv('sample_data.csv', encoding='shift_jis')
print(df)
以下のコマンドで実行します。
python sample.py
実行結果
python sample.py
日付 ユーザー名 プロジェクト名 サブプロジェクト名 タスクID 作業時間(時間単位) 作業区分 コメント
0 2023-10-01 田中 太郎 システム開発プロジェクト フロントエンド開発 SD-FE-001 2.5 設計 初期設定
1 2023-10-01 鈴木 花子 ウェブサイトリニューアル デザイン WR-D-001 1.0 修正 バグ修正
2 2023-10-02 佐藤 次郎 システム開発プロジェクト バックエンド開発 SD-BE-001 3.0 開発 機能開発
3 2023-10-02 高橋 美咲 モバイルアプリ開発 UI/UXデザイン MA-UI-001 4.0 レビュー コードレビュー
4 2023-10-03 伊藤 健一 ウェブサイトリニューアル コンテンツ作成 WR-C-001 2.0 テスト テスト
.. ... ... ... ... ... ... ... ...
57 2023-10-29 佐藤 次郎 モバイルアプリ開発 API開発 MA-API-008 2.0 修正 バグ修正
58 2023-10-30 高橋 美咲 ウェブサイトリニューアル コンテンツ作成 WR-C-010 4.0 テスト テスト
59 2023-10-30 伊藤 健一 システム開発プロジェクト フロントエンド開発 SD-FE-012 1.5 ドキュメント ドキュメ ント作成
60 2023-10-31 田中 太郎 システム開発プロジェクト フロントエンド開発 SD-FE-013 2.5 設計 初期設定
61 2023-10-31 鈴木 花子 ウェブサイトリニューアル デザイン WR-D-011 1.0 修正 バグ修正
[62 rows x 8 columns]
データが読み込めたので、PandasAIの機能を利用してOpenAIのGPT-4o-miniモデルを使って自然言語で分析できるコードに修正します。
pandasaiのSmartDataframeクラスを使うことで、データフレームに対して自然言語で質問をすることができます。
sample.pyを以下のコードに修正しましょう。
from pandasai import SmartDataframe
from pandasai.llm import OpenAI
import sys
import pandas as pd
import japanize_matplotlib
def main(question):
df = pd.read_csv('sample_data.csv', encoding='shift_jis')
llm = OpenAI(
api_token="OpenAIのAPIキーをここに指定する",
model_name="gpt-4o-mini")
pandas_ai = SmartDataframe(df, config={"llm": llm})
response = pandas_ai.chat(question)
print(response)
if __name__ == "__main__":
if len(sys.argv) != 2:
print("Usage: python sample.py <質問内容>")
sys.exit(1)
question = sys.argv[1]
main(question)
以下のコマンドを実行してみましょう。
python sample.py 作業時間の合計時間が多い順 に「氏名:合計時間」という形式で一覧表示してください。
回答例
{'type': 'string', 'value': ' 高橋 美咲:37.0\n 佐藤 次郎:32.0\n 鈴木 花子:32.0\n 田中 太郎:30.5\n 伊藤 健一:30.0'}
高橋 美咲:37.0
佐藤 次郎:32.0
鈴木 花子:32.0
田中 太郎:30.5
伊藤 健一:30.0
csvデータを分析して、氏名ごとの作業工数の合計を計算し降順に表示してくれました。
実際のcsvデータを確認しましたが計算結果は一致していたので、確かに正確に計算してくれていました。
ただ、
「どういうロジックで計算してるのか?」
「実際にどんなコマンドを実行して分析しているのか?」がわからないとちょっともやっとしますよね?
次は、どういうロジックで結果を出しているか、実際に分析する際に使ったPythonコードも一緒に回答してもらいましょう。
sample.pyを以下のコードに修正ます。
pandas_ai._agent.explain()を使うとどのように回答を導き出したのか説明を回答してくれます。
ただし、英語で説明文が返ってくるので、日本語に翻訳する関数(translate_to_japanese)を追加しています。
また、pandas_ai._agent.last_code_executed)を実行すると、分析する際に実行したPandasのPythonコードを返してくれます。
from pandasai import SmartDataframe
from pandasai.llm import OpenAI
import sys
import pandas as pd
import japanize_matplotlib
def translate_to_japanese(text, llm):
translation_prompt = f"Translate the following English text to Japanese:\n\n{text}"
response = llm.client.create(
model=llm.model,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": translation_prompt}
]
)
# responseオブジェクトから回答メッセージを取り出す
translation_response = response.choices[0].message.content.strip()
return translation_response
def main(question):
df = pd.read_csv('sample_data.csv', encoding='shift_jis')
llm = OpenAI(
api_token="xxxxxxxxxxxx",
model_name="gpt-4o-mini")
pandas_ai = SmartDataframe(df, config={"llm": llm})
response = pandas_ai.chat(question)
print(response)
explanation = pandas_ai._agent.explain()
print("英語の説明:\n", explanation)
# 英語の説明を日本語に翻訳
japanese_explanation = translate_to_japanese(explanation, llm)
print("日本語の説明:\n", japanese_explanation)
print("実行されたコード:\n",pandas_ai._agent.last_code_executed)
if __name__ == "__main__":
if len(sys.argv) != 2:
print("Usage: python sample.py <質問内容>")
sys.exit(1)
question = sys.argv[1]
main(question)
再度以下のコマンドを実行してみましょう。
python sample.py 作業時間の合計時間が多い順 に「氏名:合計時間」という形式で一覧表示してください。
回答例
高橋 美咲:37.0
佐藤 次郎:32.0
鈴木 花子:32.0
田中 太郎:30.5
伊藤 健一:30.0
英語の説明:
To create a list that shows the total hours worked by each person in descending order, I followed a straightforward process:
1. **Gathering Data**: I started with a collection of information that included dates, names of users, project details, and the hours they worked on various tasks.
2. **Calculating Total Hours**: I then looked at the hours each person worked and added them up to find out how many hours each individual contributed in total.
3. **Sorting the Results**: Once I had the total hours for each person, I organized this information so that the person with the most hours appeared first, followed by others in decreasing order of their total hours.
4. **Formatting the Output**: Finally, I formatted the results into a clear and easy-to-read list, where each entry showed the person's name followed by the total hours they worked.
This approach allowed me to present the information in a way that is simple and understandable, making it easy to see who worked the most hours.
日本語の説明:
以下の手順で、各人が働いた合計時間を降順で示すリストを作成しました。
1. **データ収集**: 日付、ユーザーの名前、プロジェクトの詳細、およびさまざまなタスクで働いた時間を含む情報を集めました。
2. **合計時間の計算**: 次に、各人が働いた時間を確認し、それを合計して、各個人が全体でどれだけ働いたかを求めました。
3. **結果のソート**: 各人の合計時間がわかったら、この情報を整理して、最も多くの時間を働いた人が最初に表示され、その後は 合計時間が減少する順に他の人が続くようにしました。
4. **出力のフォーマット**: 最後に、結果をわかりやすく読みやすいリスト形式に整え、各エントリにはその人の名前と、その人が 働いた合計時間を示しました。
このアプローチにより、情報をシンプルで理解しやすい方法で提示でき、誰が最も多くの時間を働いたかが一目でわかるようになりました。
実行されたコード:
data = {'日付': ['2023-10-03', '2023-10-25', '2023-10-15'], 'ユーザー名': ['伊藤 健一', '佐藤 次郎', '鈴木 花子'], 'プ ロジェクト名': ['システム開発プロジェクト', 'ウェブサイトリニューアル', 'モバイルアプリ開発'], 'サブプロジェクト名': [' デザイン', 'フロントエンド開発', 'テスト'], 'タスクID': ['WR-C-008', 'WR-C-003', 'SD-BE-002'], '作業時間(時間単位)': [4.0, 3.5, 2.5], '作業区分': ['開発', '会議', '修正'], 'コメント': ['テスト', '機能開発', 'ドキュメント作成']}
combined_df = pd.concat(dfs)
total_hours = combined_df.groupby('ユーザー名')['作業時間(時間単位)'].sum().reset_index()
total_hours_sorted = total_hours.sort_values(by='作業時間(時間単位)', ascending=False)
result_list = [f"{row['ユーザー名']}:{row['作業時間(時間単位)']}" for index, row in total_hours_sorted.iterrows()]
result_string = '\n'.join(result_list)
result = {'type': 'string', 'value': result_string}
print(result)
ちゃんと理由と実行したコードも表示できるといいですね。
次は、棒グラフを作成してもらいましょう。
コードはそのままで、以下の通り質問内容を変更してみます。
python sample.py 氏名ごとに作業時間の合計時 間がわかる棒グラフを作成してください。氏名ごとに色を変えてください。また各棒グラフに合計時間を表示してください。
すると・・・以下の棒グラフが自動生成され画面に表示されました。
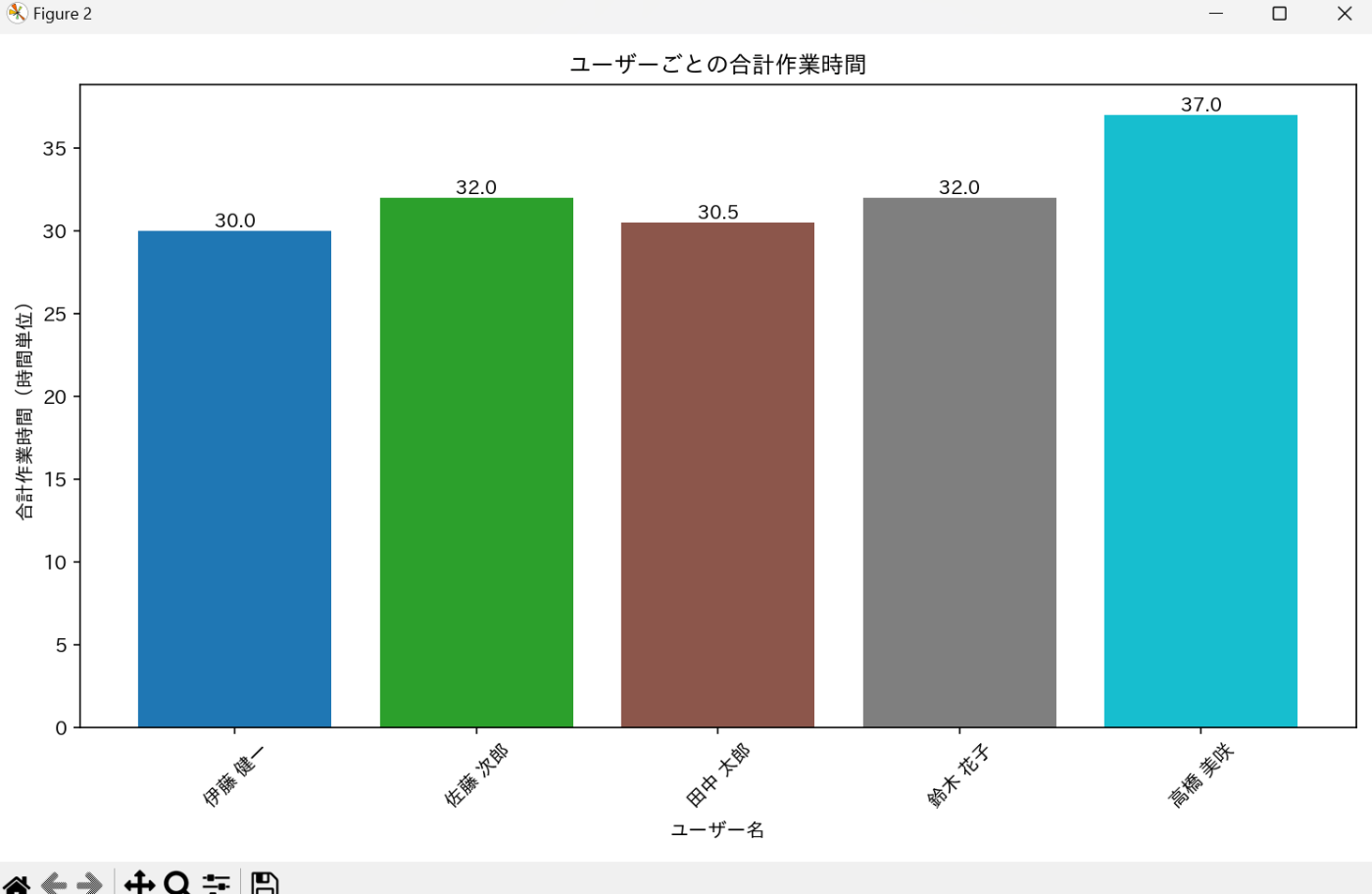
matplotlibだけで描画してるようなのでデザインがちょっと簡素なので、plotlyを使うように明確に指示出しを修正してみます。
python sample.py 氏名ごとに作業時間の合計時間がわかる棒グラフをplotlyで作成してください。氏名ごとに色を変えてください。また各棒グラフに合計時間を表示してください
plotlyの利用を明示すると、ブラウザが開いて以下のような図が表示されました。
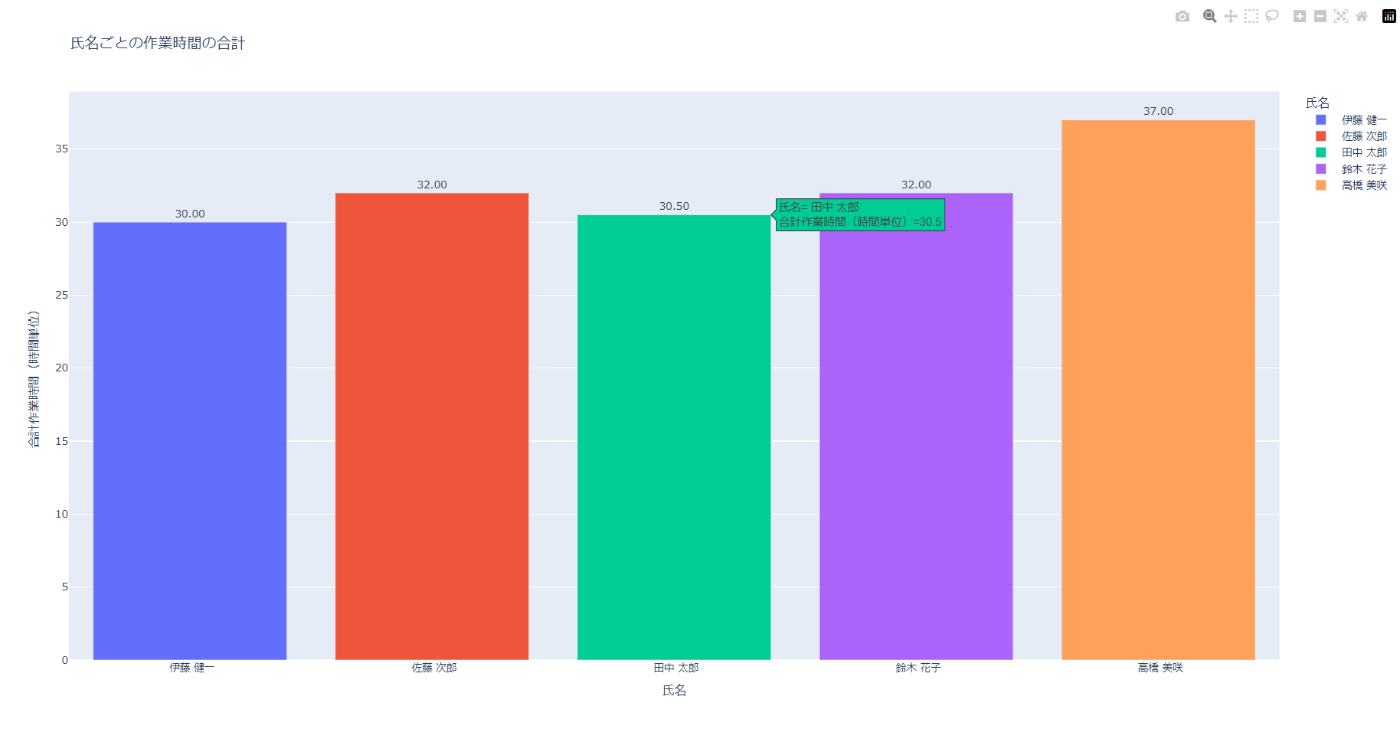
もう少し複雑な別のグラフも作成してみます。
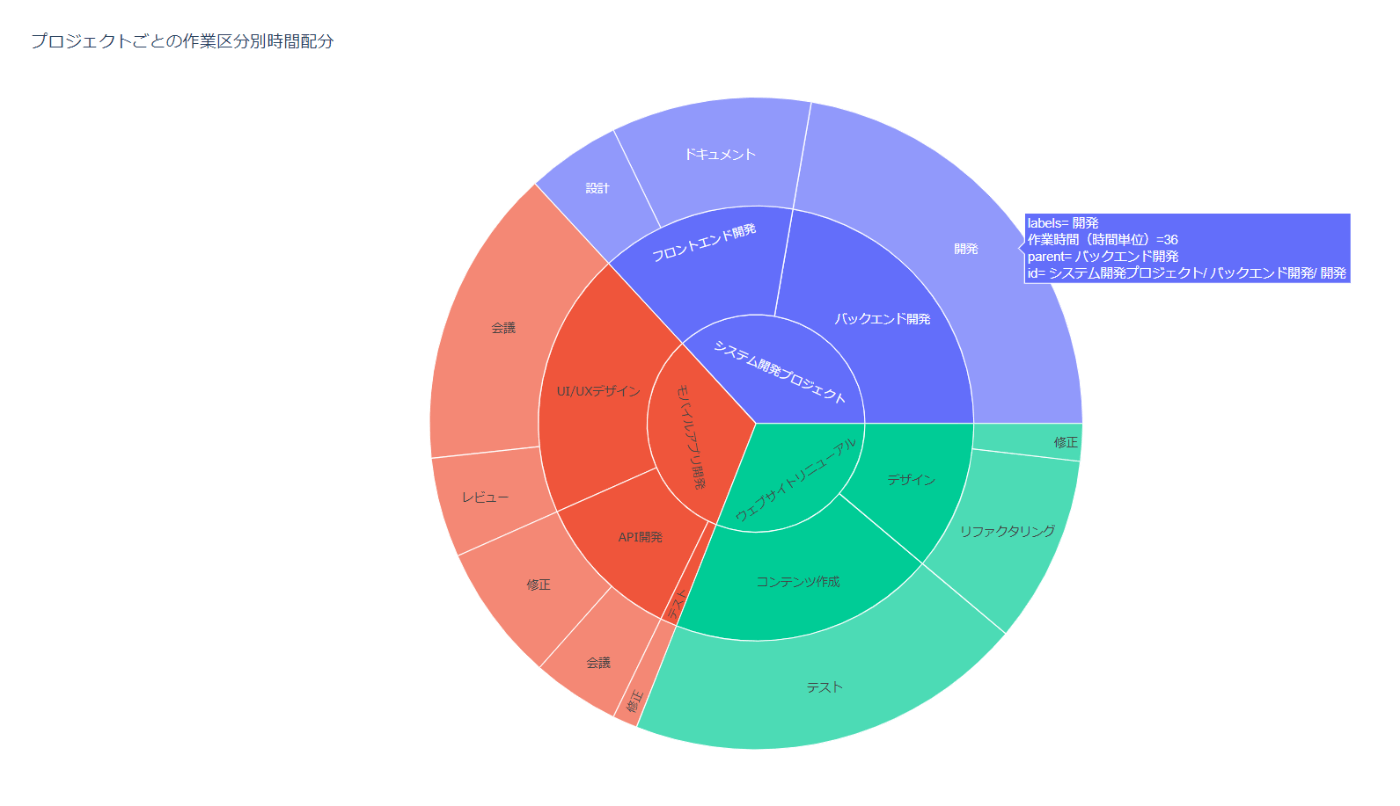
python sample.py 作業区分ごと に時間を集計し、各プロジェクトでの時間配分を比較できるグラフをplotlyのSunburstChartを利用して作成してくだ さい。
以下のようなPlotlyのインタラクティブなサンバーストグラフが自動生成されました。
PandasAIを搭載したWEBアプリ
毎回コマンド実行するのもめんどうなので、簡単にWEB画面にCSV,ExcelファイルをUPLOADして、指示出しできるDjangoアプリを試作してみました。
以下のリポジトリをCloneすればローカルPC上で簡単に動かせるので、興味がある方はぜひ触ってみてください。
※OpenAIもしくはAzureOpenAIのAPIキーが必要です。
以下は、上記リポジトリのREADMEに書いてある内容をそのまま転記しています。
pandasai-django-app
pandas-ai を組み込んだ Django アプリケーションです。
CSV,ExcelファイルをWEB画面にアップロード後に自然言語でデータ分析ができるアプリです。
アプトプットは、分析結果の文章、表形式、図の3種類を指定できます。
注意点
指示出しの仕方によっては、ハルシネーションを起こすのでアウトプットが正しいかは別途確認しましょう。
動作確認環境
- Python: 3.11.5
- Django: 5.1.1
起動手順
-
仮想環境の作成と有効化
python -m venv <仮想環境名> <仮想環境名>\scripts\activate -
依存関係のインストール
pip install -r requirements.txt -
プロジェクトディレクトリに移動
cd pandasai-django-app\source -
データベースのセットアップ
python manage.py makemigrations pandasai_app python manage.py migrate -
管理者ユーザーの作成
python manage.py createsuperuser -
サーバーの起動
python manage.py runserver -
ブラウザで
http://127.0.0.1:8000/にアクセスして動作確認
初期データの登録(LLMモデル)
以下のコマンドを実行して LLM モデルの初期データを登録します:
python manage.py init_model_data
成功時のメッセージ:
Model data initialized successfully with gpt-4o-mini preset for all providers.
Successfully initialized AI model data
LLMモデルの設定
- OpenAI と AzureOpenAI の 2 つのプロバイダーが利用可能
- デフォルトでは OpenAI が Active 状態
- 一度に 1 つのプロバイダーのみを Active に設定可能
- 初期設定:
- モデル:gpt-4o-mini
- API キー:「default_key_please_change」(実際の API キーに変更が必要)
- 利用可能なモデル名は「AI model names」に登録されたものがリスト表示されます
- モデル名は必要に応じて admin 画面から追加可能です
アプリの利用方法
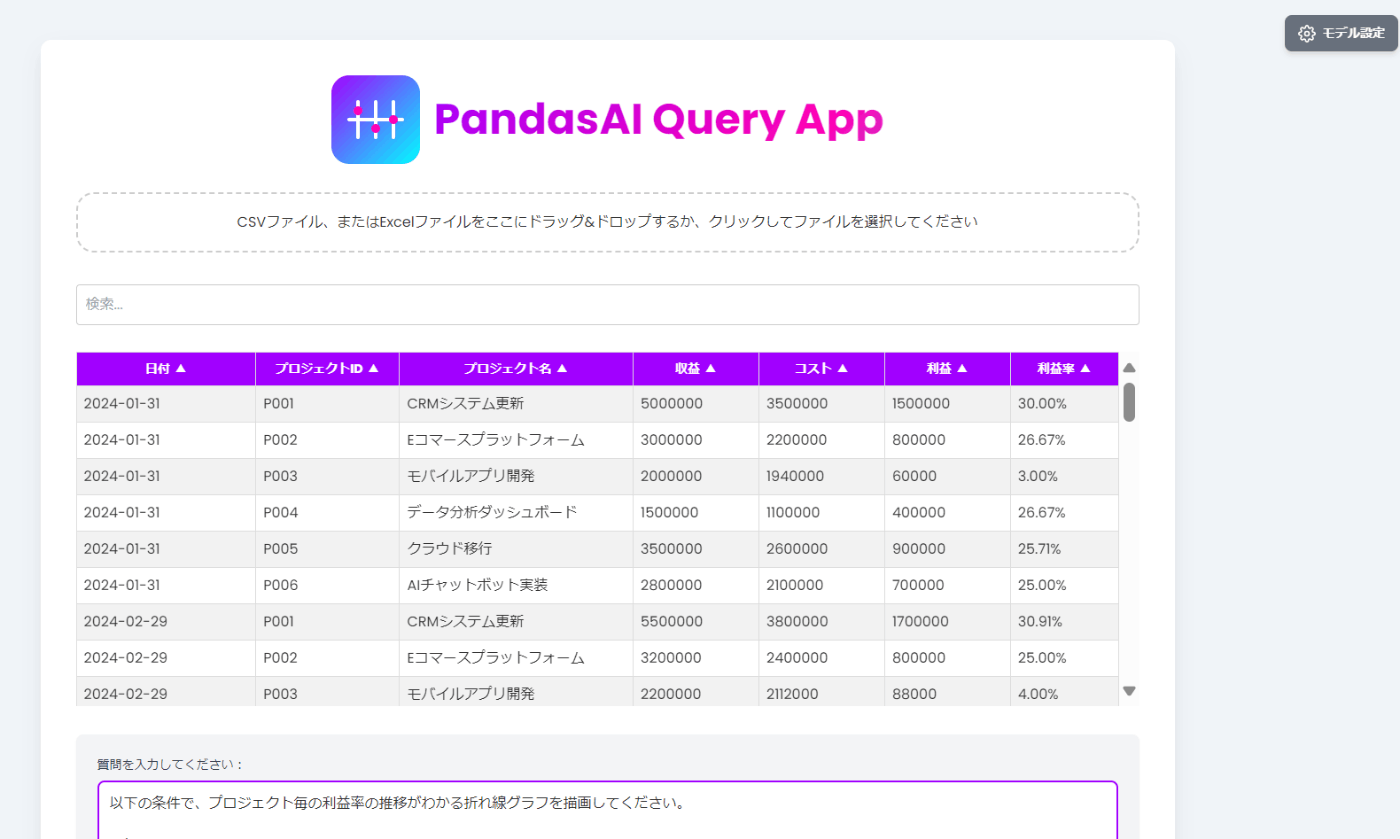
http://127.0.0.1:8000/ にアクセスすると以下のような画面が表示されます。
1. モデルの設定
画面右上の「モデル設定」を押すと以下の画面が表示されるので、利用するプロバイダの「セットアップ」ボタンをクリックします。


モデル名、API キーを入力してアクティブ UI を有効にした状態で保存します。
AzureOpenAI の場合は、API Version と Endpoint も登録します。
有効にできるモデルは 1 つだけです。
2. 質問の投げ方
-
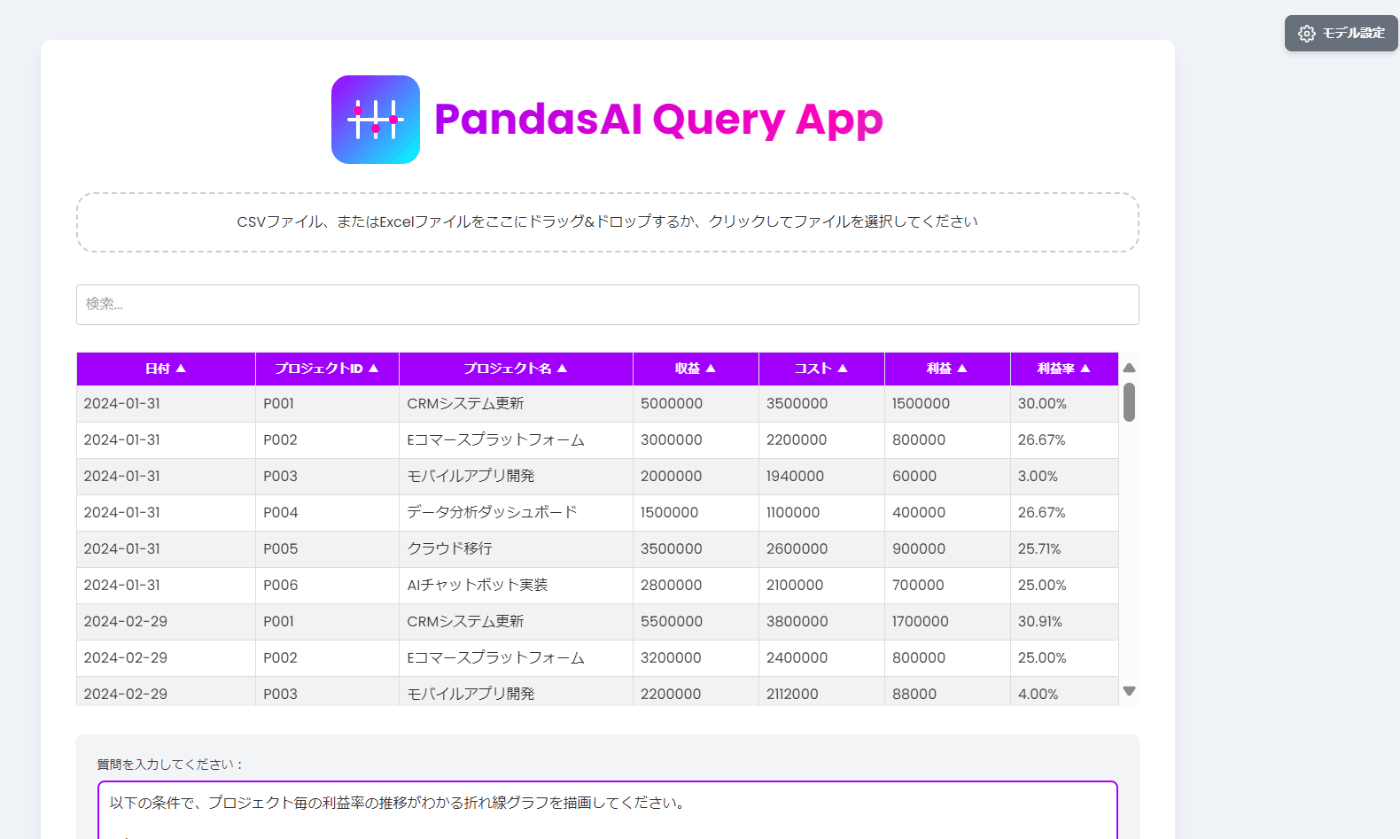
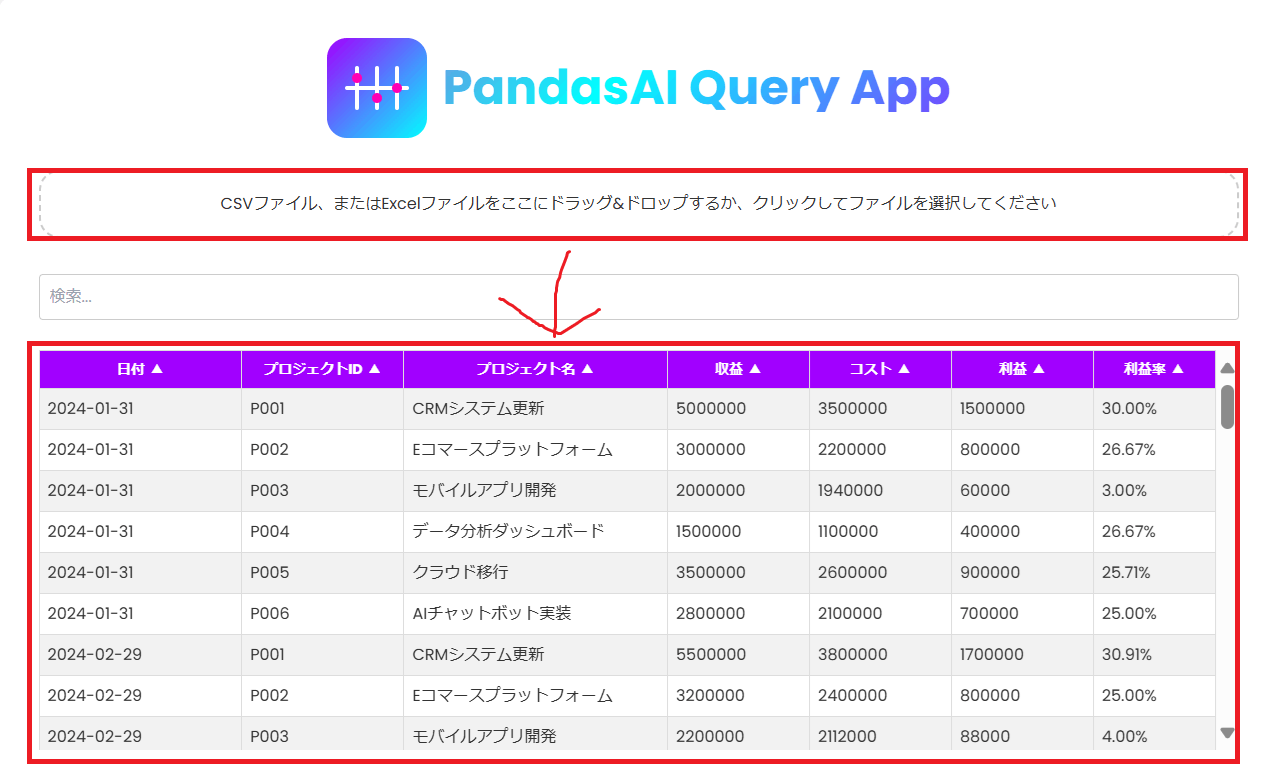
画面上部の「CSV ファイル、または Excel ファイルをここにドラッグ&ドロップするか、クリックしてファイルを選択してください」の欄に csv、もしくは Excel ファイルをアップロードします。
-
アップロードすると以下の様に自動的にファイルの内容を読み取りテーブル形式で表示します。
※綺麗なテーブル形式のデータ以外は正しく読み取れないので注意。
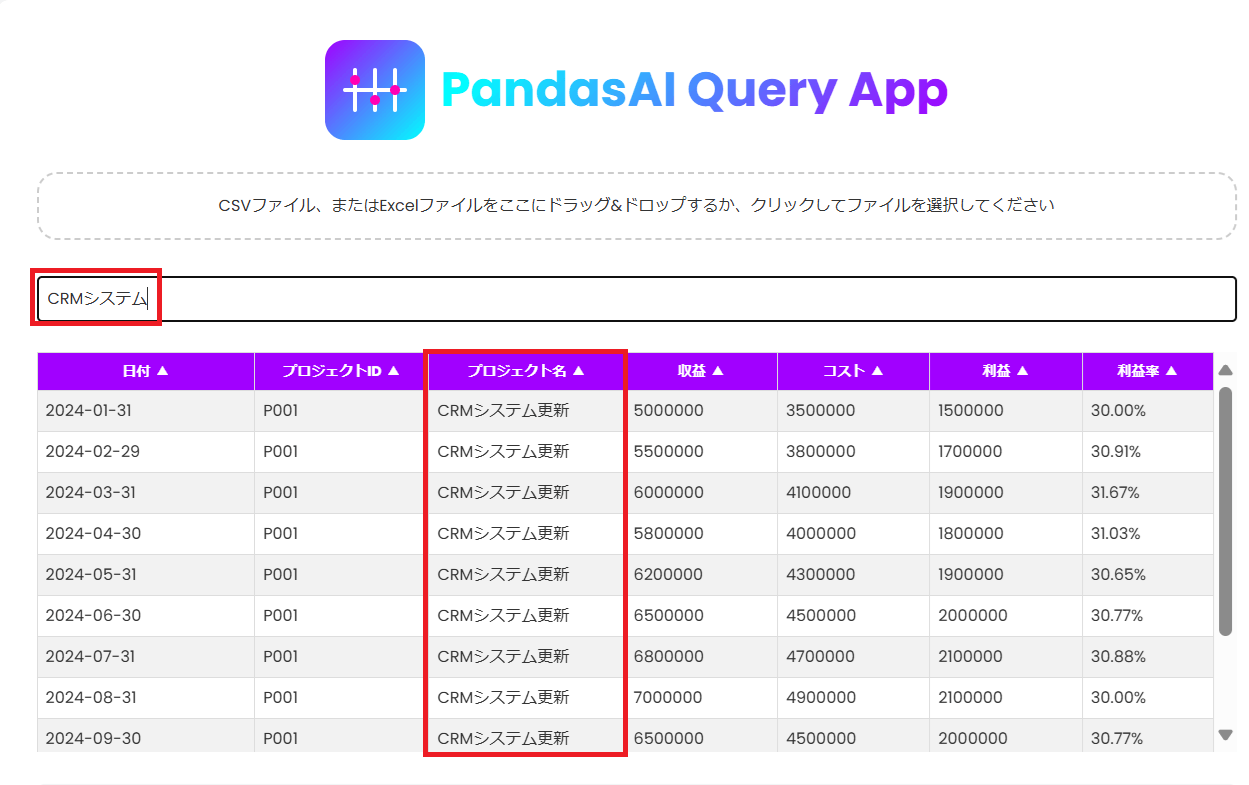
- 「検索」ボックスに文字列を入れると文字列検索ができます。
- 各列をクリックすると、「昇順、降順」にソートすることができます。
-
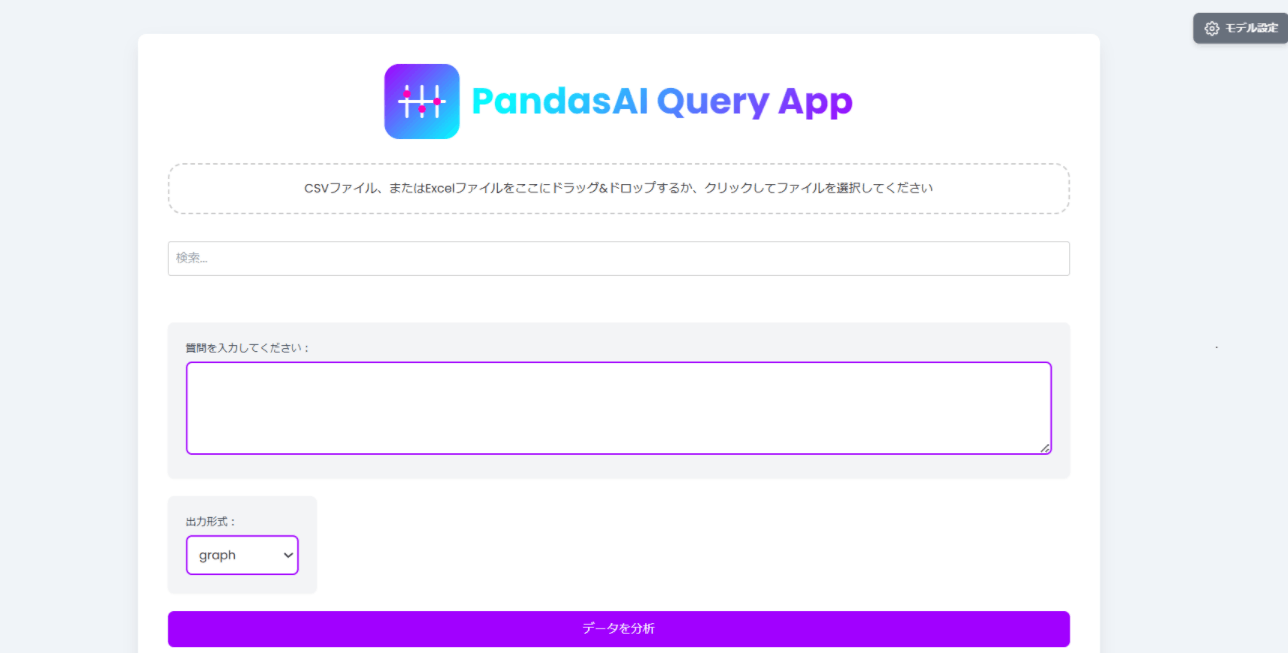
「質問を入力してください:」の欄にアップロードしたファイルに対する指示文を入力します。
-
「出力形式」から以下のいずれかを選択してください。
- graph: グラフを表示してほしい場合
- dataframe: 表形式の結果を返してほしい場合
- string: 文字列(文章)の回答が欲しい場合
サンプルデータを使用した例
サンプルデータの「プロジェクト収支データ.csv」をアップロードした状態で出力形式を「graph, dataframe, strings」を指定して実行した場合の実行例です。
【注意】
✅指示出し内容が曖昧だったり、指定した出力形式と指示内容に矛盾がある場合は正しいアウトプットが出力されない、もしくは誤った結果が表示されるケースがあるのため、出力内容の正しさは別途確認しましょう。
✅上手く出力されないケースがあるので、何度か実行するとうまくいくと思います。
graph の例
以下の条件で、プロジェクト毎の利益率の推移がわかる折れ線グラフを描画してください。
#条件
プロジェクト毎に違う色で利益率の折れ線グラフを描画する
値のラベルを表示する。
凡例はグラフの外側に表示する。
縦、横に Grid 線を表示する。
横幅をできるだけ長くして見やすいレイアウトにしてください。
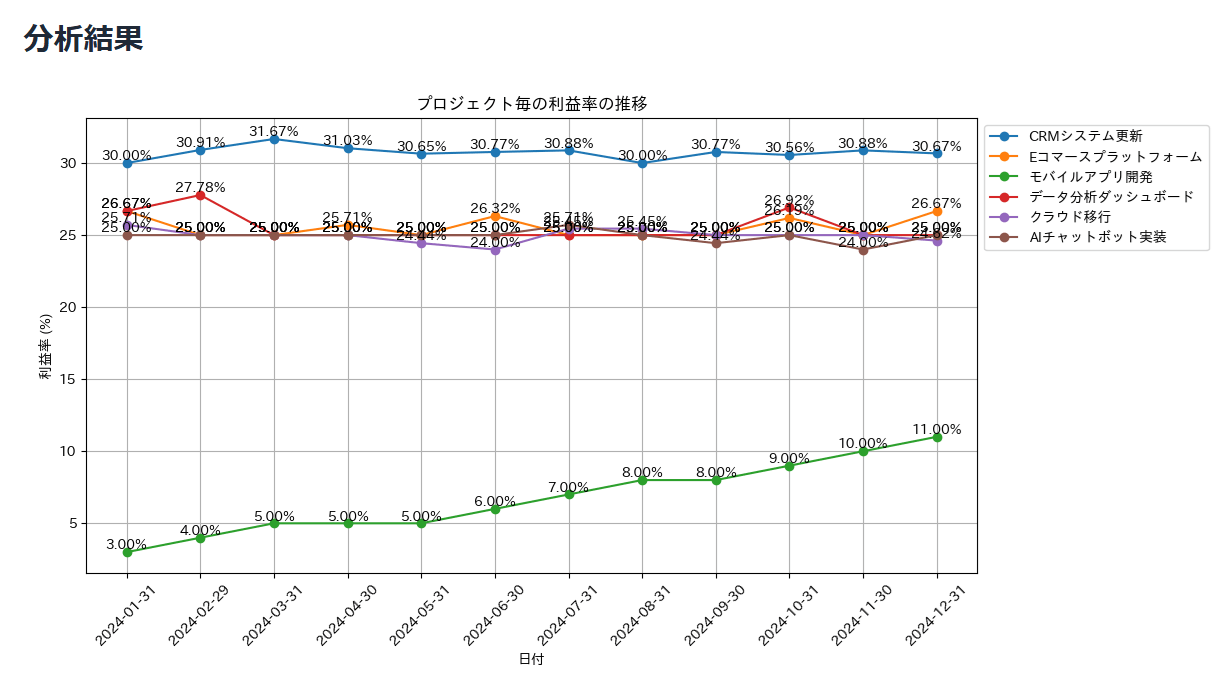
以下の様にPandasaiが標準で返す説明情報と、実行された分析コード、また分析コードを生成AIに解説してもらった結果(独自に追加した機能)の情報を確認することができます。


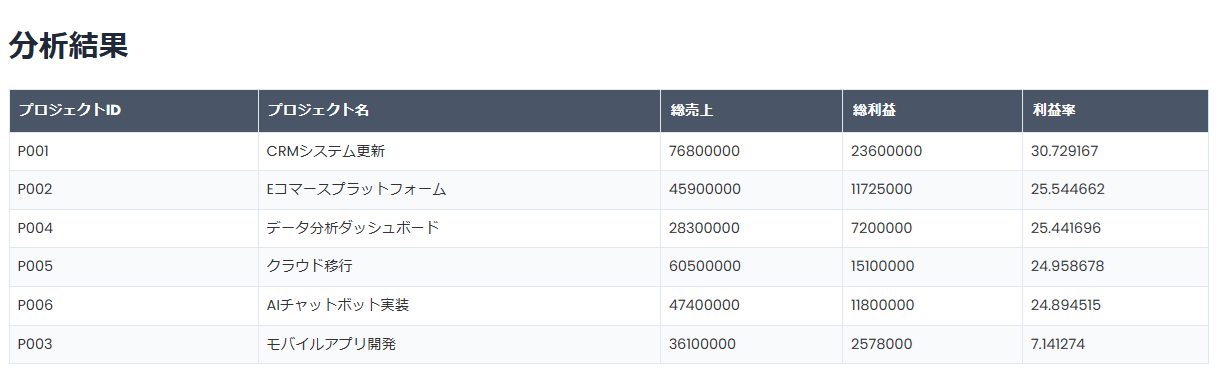
dataframe の例
プロジェクト毎の全データの総収益、総コスト、総利益、利益率をまとめてください。
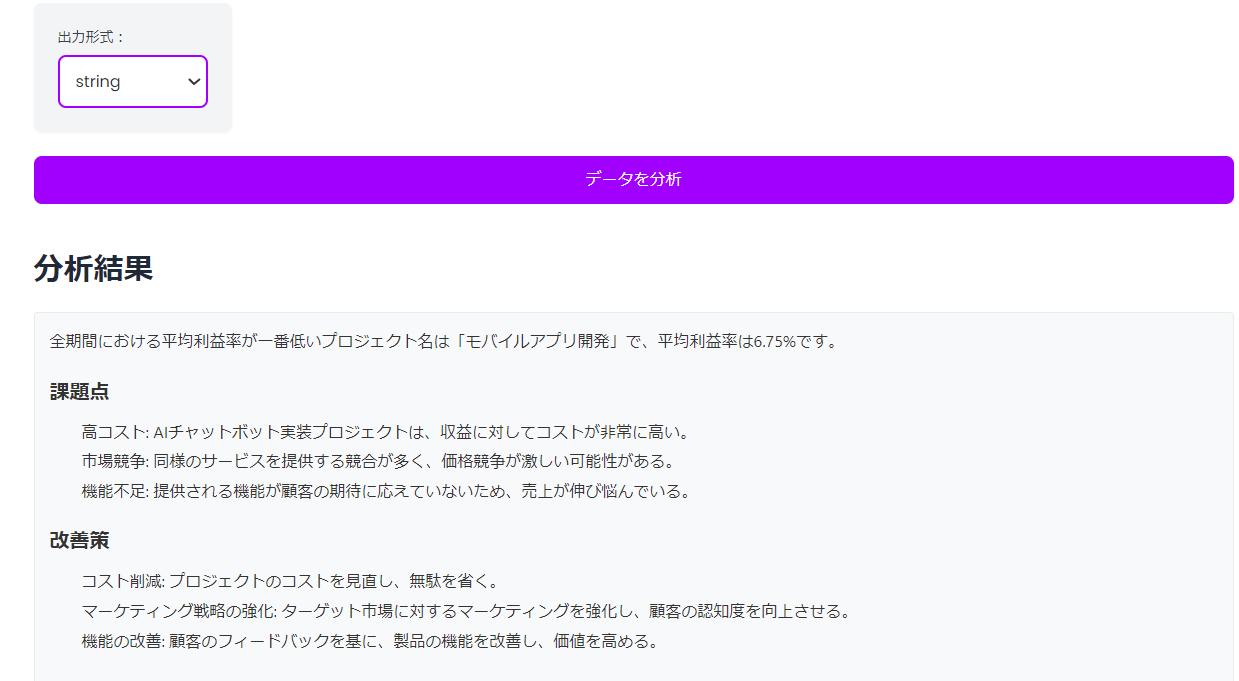
string の例
全期間における利益率が一番低いプロジェクト名を抽出し、与えられたデータから推測できる課題点と具体的な改善策を回答してください。

アクセンチュア株式会社に所属する社員有志による運営です。アクセンチュアの社員による様々な発信をまとめています。なお、投稿内容は社員個人の見解であり、所属する組織を代表するものではありません。
Discussion