Open2
Triton: an intermediate language and compiler for tiled neural network computations
Triton
🔗 Triton: an intermediate language and compiler for tiled neural network computations
Triton:効率的なカーネル生成を目的とする、タイルを中心とした中間表現とコンパイラ
(1)テンソルプログラムをパラメトリックなタイル変数に対する演算で表現するためのCベースの言語とLLVMベースの中間表現
(2)これらのプログラ ムを効率的なGPUコードにコンパイルするための新しいタイルレベルの最適化パスのセット
変更点
コンパイラパイプラインにタイルレベル演算と最適化を追加
利点
(1) XLA・Glowよりも柔軟
(2) TC・Dieselがサポートしない、non-affine indexingをサポート
(3) Halide・TVMでは手動で指定する必要のあるスケジューリングを、自動で推論
欠点
プログラミングの手間が増える
↓ C = A * B^T の実装、TF/Plaid ML/TC/TVMの場合
C = tf.matmul(A, tf.transpose(B)) // TF
C[i, j: I, J] = +(A[i, k] * B[j, k]); // PlaidML
C(i, j) +=! A(i, k) * B(j, k) // TC
tvm.sum(A[i, k] * B[j, k], axis=k) // TVM
↓ Triton-Cの場合
タイル型とタイル操作を用いてタイル化を明示的に指定する。タイルサイズは自動で調整される

※ @check_cはcheck_c[i,j]がtrueのとき評価される式(predicate expression)
構成要素
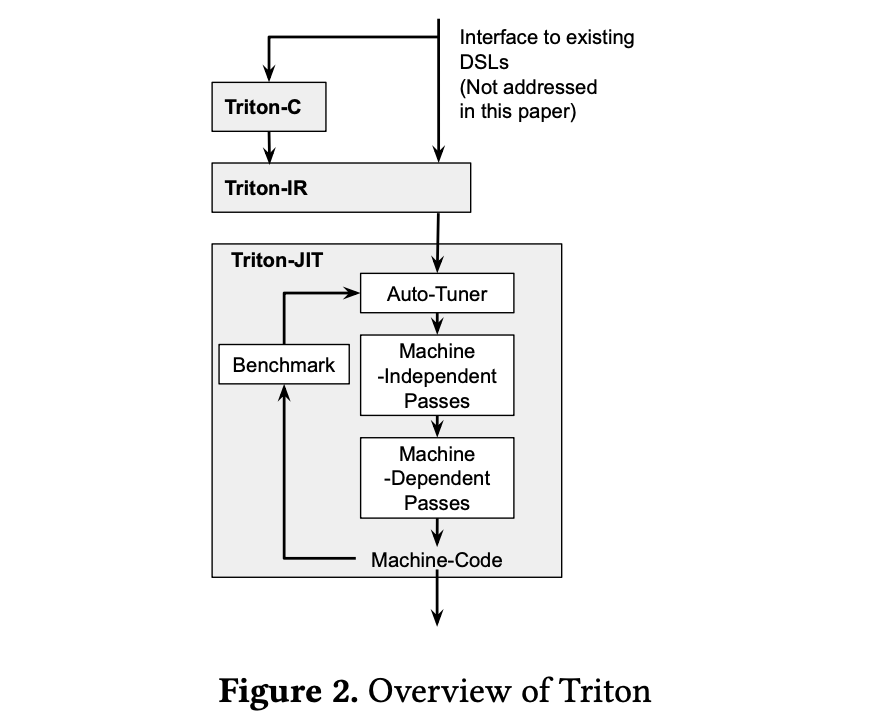
Triton-C:プログラマ向けのインターフェース
- CUDA-Cベースの構文に、タイル型とタイル操作を追加
- 暗黙のブロードキャスト
Triton-IR:解析・変換に適した中間表現
- LLVM-IRベース
- タイル型
i32<8, 8> - リシェイプ命令
reshape i32<8, 8> %0とブロードキャスト命令broadcast i32<8, 8> %0 - タイルレベルの制御フロー
-
Predicated SSA form (cmpp命令)とpsi-function (psi命令)
; pt[i,j], pf[i,j] = (true, false) if x[i,j] < 5 ; pt[i,j], pf[i,j] = (false, true) if x[i,j] >= 5 %pt, %pf = icmpp slt %x, 5 ; y1[i,j] = x[i,j] + 1 if pt[i,j] @%pt %y1 = add %x, 1 ; y2[i,j] = x[i,j] - 1 if pf[i,j] @%pf %y2 = sub %x, 1 ; y[i,j] = y1[i,j] if pt[i,j] ; y[i,j] = y2[i,j] if pf[i,j] %y = psi i32<8, 8> [%pt, %y1], [%pf, %y2] ; ...
-
Triton-JIT:最適化されたコード生成
マシン非依存
- メモリプリフェッチ
- Peephole optimization
マシン依存
-
階層的なタイリング
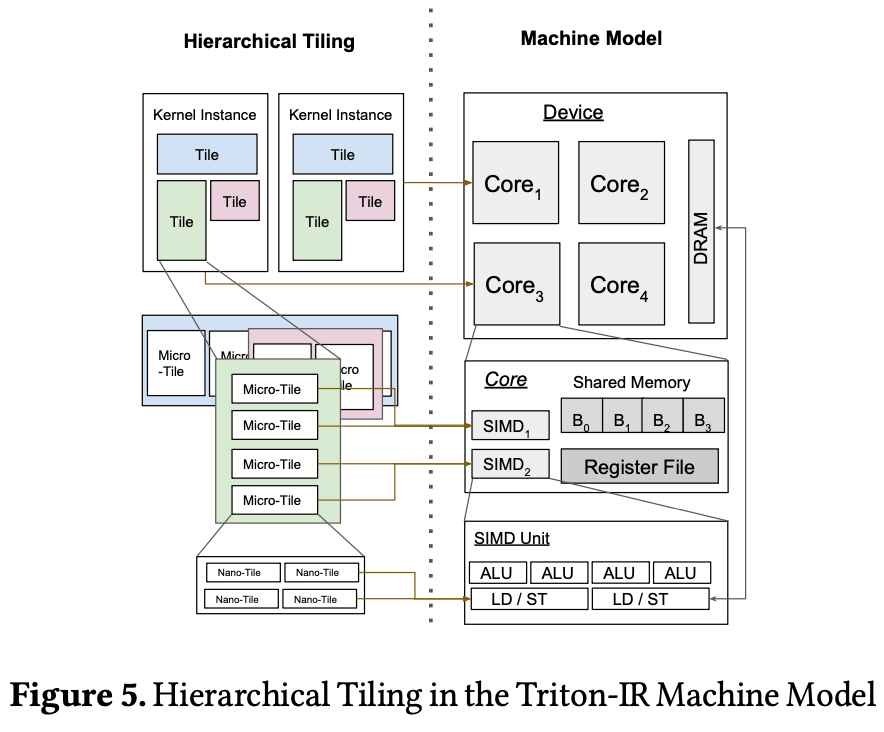
-
メモリ合併
-
共有メモリ割り当て・共有メモリ同期
-
タイルサイズの自動チューニング
使用例
- PyTorch 2.0のTorchInductor
Triton 2.0: Triton-MLIR
Triton-MLIR IR Flow
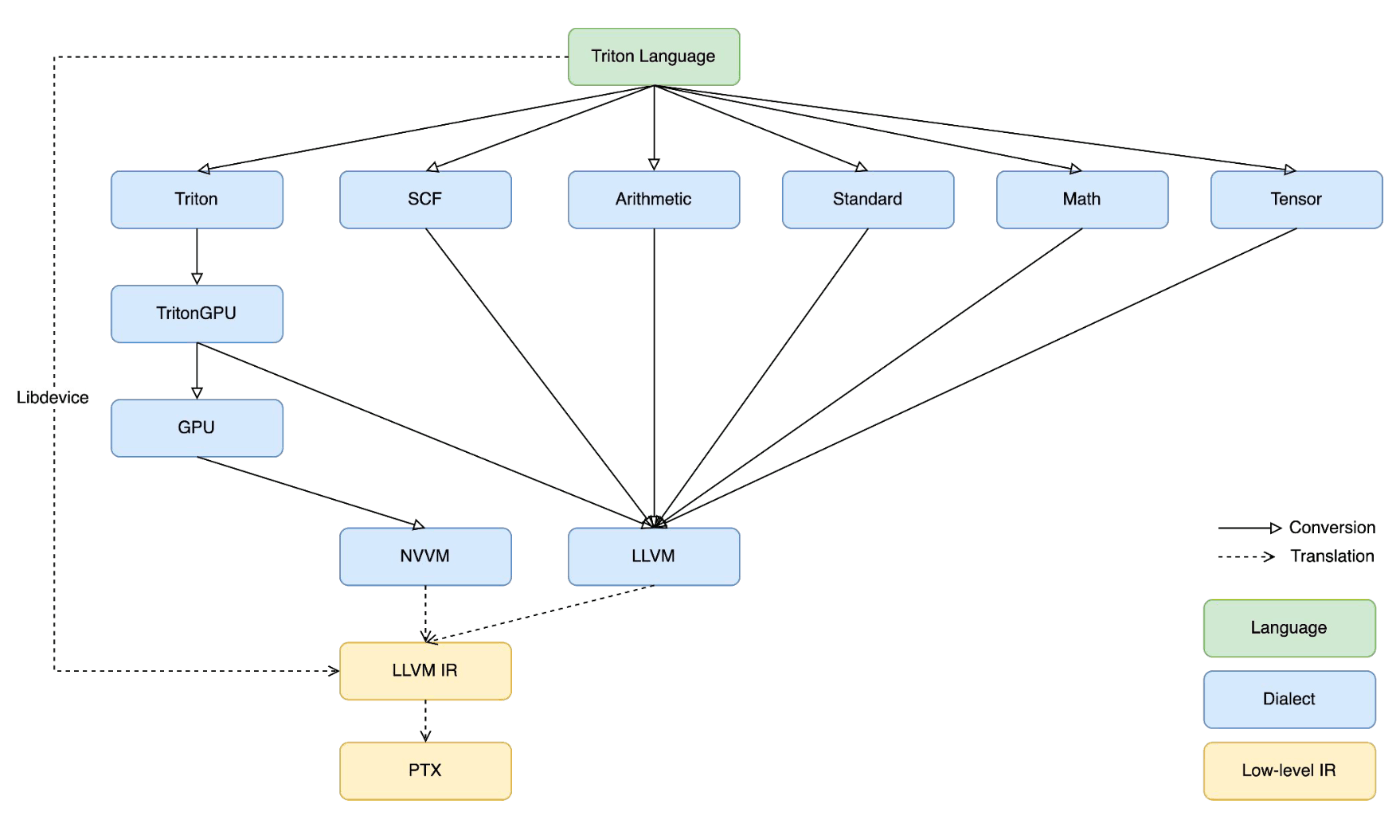
Triton Dialect
TritonGPU Dialect
TritonToTritonGPU
TritonGPU Transforms
TritonGPUToLLVM