JavaScript エンジンの高速化
JavaScript をはじめとする動的言語の処理系における最適化について紹介します。主に 🔗Speculation in JavaScriptCore | WebKit を参考にしています。
はじめに
JavaScript, Ruby, Python をはじめとする動的言語は至るところで利用されています。近年では通常のアプリに見える Web アプリケーションも多く、VSCode, Slack や Notion といったアプリが Web アプリとして実装されています。
一方、動的言語は多くの場合、型を静的に決定することができないことから、その高速化にはネイティブコード生成するコンパイラとは異なる難しさがあります。例として以下の JavaScript のコードを考えます。
function foo(a, b) {
return a + b;
}
a や b の型がわからないため、a と b の加算で実行されるコードを特定することはできません。この加算は整数の加算かもしれませんし、浮動小数点の加算かもしれませんし、文字列の連結かもしれません。その結果、このプログラムを忠実にコンパイルするコンパイラは、次の図のように、分岐を多く含むコードを生成せざるを得ません。
分岐を多く含むコード。🔗Speculation in JavaScriptCore | WebKit より引用
このように、動的言語のプログラムから効率的なネイティブコードを静的に生成するのはほぼ不可能であり、動的言語特有の最適化が重要になります。
そこで、この文章では動的言語の処理系において広く用いられている最適化手法について紹介します。具体例として、動的言語の処理系の中でも洗練された設計をもつ、JavaScriptCoreと呼ばれる JavaScript エンジンを取り上げたいと思います。
JavaScript エンジンの紹介
本題に入る前に、JavaScript エンジンについて軽く紹介します。Web ブラウザ等のバックグラウンドで実行されている、JavaScript のコードを実行するプログラムのことを JavaScript エンジンと呼びます。主要な JavaScript エンジンには、JavaScriptCore, V8, SpiderMonkey 等があります。各 JavaScript エンジンの概要を、次の表に示します。
| JavaScriptエンジン | 開発元 | 使用されているWebブラウザ | |
|---|---|---|---|
 |
JavaScriptCore | Apple | Safari |
 |
V8 | Google Chrome, Microsoft Edge | |
 |
SpiderMonkey | Mozilla | Firefox |
これらの JavaScript エンジンのうち、以下では特に JavaScriptCore を扱います。
最適化の基本戦略
JavaScript をはじめとする動的言語は、主にインタープリタにおいて実行されます。しかし、インタープリタはコンパイルされたコードと比較して実行に時間を要するという欠点があります。そこで、インタープリタの最適化では、バイトコードの JIT コンパイルが最初に行われます。
しかし、コンパイルには当然時間がかかります。少しでも高速化されたコードを生成するには、より多くの時間をコンパイルにかけなければなりません。コンパイルによる速度向上とコンパイルのレイテンシはトレードオフの関係にあります。
そこで、多くの JavaScript エンジンは、インタープリタと多階層の JIT コンパイラの組み合わせで構成されています。次の図は、主要な JavaScript エンジンの設計を示しています。

主要な JavaScript エンジンの設計。🔗Building a baseline JIT for Lua automatically | Max Bernstein より引用
JavaScript のコードはまず、インタープリタで実行されます。インタープリタで実行されるコードのうち実行回数の多い部分が、最適化なしの JIT コンパイラによりコンパイルされ、コンパイルされたコードが実行されます。さらに実行回数の多い部分のみ、最適化を行う JIT コンパイラによりコンパイルされます。
特に、JavaScriptCore は、他の JavaScript エンジンより 1 階層多い JIT コンパイラで構成されており、より優れた設計をもちます。そこで、ここからは JavaScriptCore における最適化について紹介します。
JavaScriptCore における最適化
JavaScriptCore は、最適化が弱い順に、
- インタープリタ (LLInt)
- Baseline JIT
- Lightweight Optimizing JIT (DFG)
- Heavyweight Optimizing JIT (FTL)
の 4 つの処理系で構成されています。
インタープリタ (LLInt)
JavaScript のプログラムが最初に実行されるインタープリタのことを、JavaScriptCore ではLLIntと呼びます。上述したように、インタープリタはバイトコードの間接分岐により実装されているため、非常に遅いという短所があります。しかし、多くのコードは 1 度しか実行されないため、コンパイルのレイテンシや必要メモリを考慮すると、プログラムの大部分はインタープリタによる実行で問題ありません。
実は、インタープリタにおいても、後述する Inline Caching といった最適化が可能です。しかし、JavaScriptCore ではインタープリタの実装を単純化するため、特に最適化は行いません。
Baseline JIT
JavaScriptCore において最初に起動する JIT コンパイラのことを、Baseline JITと呼びます。Baseline JIT は、ほとんど最適化を行わなず、後述する安価な最適化のみ実行する JIT コンパイラです。一見、この段階でももっと最適化を行えばよいのではと感じるかもしれません。しかし、Baseline JIT には上位のコンパイラが行う投機的な最適化が失敗した場合に、上位のコンパイラの代わりにプログラムを実行するという役割があります。そのため、Baseline JIT では投機的な最適化はあえて実施しません。
Baseline JIT によって実行される最適化は次の通りです。
JIT コンパイルによる間接分岐の除去
Baseline JIT はほとんど最適化を行わないと述べましたが、そのもうひとつの理由は、コンパイルすること自体が高速化となることにあります。Baseline JIT における最大の最適化は、JIT コンパイルにあると言っても過言ではありません。
その理由として、インタープリタ実行は間接分岐を多く含むため、コンパイルされたコードの実行と比較して極めて低速であるという欠点が挙げられます。インタープリタは多くの場合、次のコードで示すように、バイトコードに対する間接分岐を用いて実装されます。
// インタープリタの実装の擬似コード
while (pc < size(bytecode)) {
switch (bytecode[pc]) {
case Add: { ... }
case Sub: { ... }
case Load: { ... }
case Store: { ... }
case Jmp: { ... }
...
}
pc += 1;
}
1 つのバイトコードの実行毎に間接分岐が挟まるため、インタープリタの実行では、分岐予測といった CPU の各種予測が上手く動作しません。また、命令の局所性が低下しやすいため、命令キャッシュミスも無視できません。そこで、バイトコードの JIT コンパイルによる間接分岐の除去が、インタープリタにおける最初に行われる最適化となります。
Inline Caching
特定の命令で実行されるコードがプログラム実行中に変化することは少ないことを利用して、実行されるコードをキャッシュする最適化をInline Cacheingと呼びます。Inline Cacheing は命令のセマンティクス選択、間接関数呼び出し、オブジェクトのプロパティアクセス等、様々な箇所で利用されるため、動的言語において最も効果的な最適化の 1 つとなります。
次の図は Inline Cacheing の仕組みを表しています。最初にコードが実行されるときは、キャッシュが存在しないため、キャッシュミス時のロジック(図の ic_miss)が実行され、IC case #1 がキャッシュされます。次にコードが実行される場合は、IC case #1 がチェックされ、ヒットした場合はそのロジックを実行、ミスした場合は再び ic_miss が実行され、IC case #2 がキャッシュされることとなります。

Inline Cacheing の仕組み。🔗Building a baseline JIT for Lua automatically | Haoran Xu より引用
Hidden Class
構築方法が同じオブジェクトは同じプロパティを持つことが多いことを利用して、オブジェクトのレイアウトをキャッシュし、プロパティアクセスを高速化する手法のことをHidden Classと呼びます。ここでオブジェクトのレイアウトとは、オブジェクトの各プロパティの先頭アドレスからのオフセットのことを指しており、Hidden Class や Shape と呼ばれています。
次の図は Hidden Class の仕組みを表しています。for ループが回るたびに "x" と "y" をプロパティにもつオブジェクトが作成されています。これらのオブジェクトは同じ Hidden Class を持つため、プロパティアクセスがキャッシュされ高速化されます。

Hidden Class の仕組み。🔗[PDF] JavaScript エンジンの実装技術 - 鵜川始陽 より引用
Inline Caching と Hidden Class には、実行時のオーバーヘッドがほとんどありません。そのため、これらの最適化だけはほとんど最適化を行わない JIT である Baseline JIT においても実行されています。
Lightweight Optimizing JIT (DFG)
JavaScriptCore において 2 番目に起動する JIT コンパイラをDFGと呼びます。DFG は Data Flow Graph の略であり、安価な最適化のみ実行することで、高速に動作する JIT コンパイラです。そのため、DFG は軽量 JIT コンパイラ (Lightweight Optimizing JIT) ということもできます。
DFG の Baseline JIT との大きな違いは、投機的実行を用いた最適化を採用していることにあります。例えば DFG は、ある変数の型を仮定する・ある変数が定数であることを仮定するといった仮定を置くことで、大胆な最適化を行っています。
なお、DFG は命令選択・レジスタ割り当て・共通部分式削除といった低レベル最適化も実行します。しかし、高速に動作するために、基本ブロック単位でしかこれらの最適化を実行しません。そのため DFG は、最適化を制限的に実行することで高速に動作する JIT コンパイラだと言えます。
DFG では主に以下の最適化が行われます。
Type Speculation
特定の命令のオペランドの型がプログラム実行中に変化することは少ないことを利用して、使用された型をキャッシュする最適化をType Speculationといいます。Type Speculation を用いると各命令で実行されるコードを仮定できるため、典型的な実行パスを高速化できます。これだけでも強力ですが、後述する OSR-Exit と組み合わせることで、より多くの型チェックを除去できます。
Watchpoint
ある実行時チェックが真であると仮定してコードを実行する最適化をWatchpointと呼びます。実行時チェックの例として、「あるオブジェクトが不変である」などが挙げられます。例えば JavaScript では、Math.sqrt の Math や sqrt に代入したり削除したりすることが許されています。しかし、通常のプログラムではこれらの値は実行中に変化しないと仮定して問題ないはずです。これにより、多くのコンパイラ最適化が適用できるようになります。

Watchpoint を含むコードの流れ
OSR-Exit
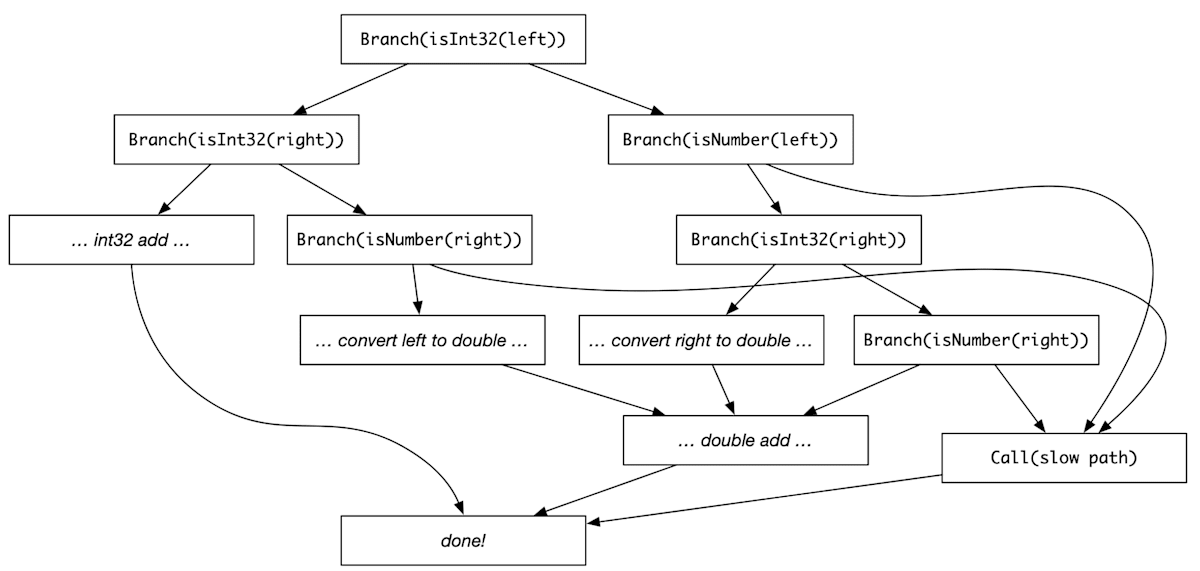
実行時チェックに失敗しベースライン JIT で実行する場合に、都度最適化コードに戻らず、最適化コードに戻るタイミングを遅らせる最適化をOSR-Exitと呼びます。OSR-Exit により、失敗したチェックからの復帰を遅延させることで、最適化パスにおいて実行時チェックを除去する機会が増えるという利点があります。
次の図は、OSR-Exit を行わないプログラムの流れ(左。Diamond Speculation と呼ぶ)と、OSR-Exit を行うプログラムの流れ(右)を示しています。OSR-Exit を行わないプログラムでは、スローパスが実行された場合、2 回目の x が int とは限りません。そのため 2 回目の型チェック (Branch(isInt32(x))) を取り除くことはできません。
一方、OSR-Exit を行うプログラムでは、1 回目の実行時チェックが終了した場合に実行パスが合流しないため、2 回目のチェックを省略できます。これにより、ファストパスの型チェックが 1 つ少なくなることがわかります。
var tmp1 = x + 42;
... // things
var tmp2 = x + 100;

OSR-Exit を行わないプログラムの流れ(左)と、行うプログラムの流れ(右)。🔗Speculation in JavaScriptCore | WebKit より引用
Heavyweight Optimizing JIT (FTL)
JavaScriptCore において最後に起動する JIT コンパイラをFTLと呼びます。FTL は Faster Than Light の略であり、ホットコードにおいてピーク性能を出すために、最もアグレッシブな最適化を実行する JIT コンパイラです。そのため、FTL は高性能 JIT コンパイラ (Heavyweight Optimizing JIT) ということもできます。
FTL は、命令選択・レジスタ割り当て・定数畳み込み・共通部分式削除・デッドコード削除といった、低レベルの最適化を担当します。この中で、命令選択とレジスタ割り当てが最も重要な最適化となります。また、DFG とは異なり、これらの最適化をグローバルなレベルで実行します。
低レベルの最適化を上手く行うために、FTL では DFG IR, DFG SSA IR, B3 IR, Assembly IR の 4 種類の IR(中間表現)が使用され、ネイティブコードまで段階的に lowering されます。FTL で実行される最適化や各 IR の役割については、🔗Introducing the B3 JIT Compiler | WebKit において詳しく説明されています。

DFG と FTL のコンパイラパイプライン。🔗Speculation in JavaScriptCore | WebKit より引用
FTL は 4 つもの IR を使用するため、コンパイル時間がとても長いという短所をもちます。しかしこの短所は、DFG は高速にコンパイルし、FTL は高性能なコードを生成するという役割分担を行うことで対処されています。
性能評価
それでは、ここまで説明してきた最適化手法が実際どの程度の効果を発揮するのかを見ていきたいと思います。性能評価の結果を示す前に、よく使用される JavaScript エンジンの評価指標である、JavaScript ベンチマークについて軽く紹介します。
代表的な JavaScript ベンチマークに、JetStream, Octane, Kraken があります。それぞれ Apple, Google, Mozilla によって開発された JavaScript ベンチマークです。現在、Octane, Kraken は開発が停止されており、JetStream が主流のベンチマークとなっています。2016 年の情報も元に各ベンチマークの特徴を述べると、JetStream は多くの現実的なワークロードをカバーするテストを含むため、JavaScript エンジンの総合的な性能を評価できます。Octane は JetStream に似ていますが、異なる観点から性能を評価するベンチマークです。Kraken は JetStream とは異なり、比較的短時間で実行されるコードの性能を評価するという特徴があります。
各ベンチマークが異なった観点から性能を評価するため、あらゆる現実のワークロードで平均的に高い性能を発揮するには、幅広いベンチマークで良い結果を出すことが重要だと言われています。
| JavaScriptベンチマーク | 開発元 | 補足 |
|---|---|---|
| JetStream | Apple | 主流 |
| Octane | 2017年に更新停止 | |
| Kraken | Mozilla |
次の図は 🔗Speculation in JavaScriptCore | WebKit に掲載されている、JavaScriptCore の非公式なベンチマーク結果です。

JavaScriptCore の非公式なベンチマーク結果。🔗Speculation in JavaScriptCore | WebKit より引用
Baseline JIT はインタープリタの 2 倍以上、DFG は Baseline JIT のさらに 2 倍以上、FTL は DFG の約 1.1 倍の性能をもつことがわかります。
Baseline JIT や DFG と比較して、FTL による性能向上が僅かであるように感じられるかもしれません。これは僅かであっても、FTL は最高のピークスループットを達成することが目的であるためと理解することができます。
おわりに:その他の動的言語
ここまで JavaScriptCore を例に、動的言語の最適化手法について説明してきました。高性能なコードの生成と、高速なコンパイルの両方を達成するために、動的言語では複数の JIT コンパイラを採用し、段階的に最適化レベルを上げるという極めて洗練された手法が用いられていました。また、Baseline JIT では主に Inline Caching を行うのに対し、DFG では投機的な最適化・FTL では低レベル最適化と、異なる種類の最適化を組み合わせていることもわかりました。このように、動的言語の最適化には多層的かつ段階的なアプローチが重要であり、各層で異なる最適化手法を組み合わせることで、実行速度と効率性の両立が図られていると言えると思います。
最後にその他の動的言語の処理系について軽く紹介して、この文章を締めたいと思います。
Ruby
MJIT: Ruby を高速化するために開発された JIT コンパイラ。Ruby の VM がスタックベースの命令を実行するのに対し、MJIT ではレジスタベースの命令を採用することで高速化を図っています。高速なコンパイルを実現するために軽量 JIT コンパイラが採用されています。Ruby 3.3 で RJIT が導入されたことに伴い廃止。
参考文献
- 🔗Ruby 2.6 に JIT コンパイラをマージしました - k0kubun's blog
- 🔗MIR: A lightweight JIT compiler project | Red Hat Developer
- 🔗Code specialization for the MIR lightweight JIT compiler | Red Hat Developer
Lua
Deegen: 最新の JIT コンパイル手法を用いて開発されているの Lua インタープリタ & JIT コンパイラ。言語内 DSL を用いて記述された言語のセマンティクスからインタープリタと JIT コンパイラを自動生成するという、野心的な目標を掲げています。コード生成では、Python の項で後述する Copy-and-Patch コンパイルと呼ばれる手法が用いられています。

🔗Building a baseline JIT for Lua automatically | Haoran Xu より引用
参考文献
- 🔗Building the fastest Lua interpreter.. automatically! | Haoran Xu
- 🔗Building a baseline JIT for Lua automatically | Haoran Xu
- 🔗Copy-and-patch compilation: a fast compilation algorithm for high-level languages and bytecode | Proceedings of the ACM on Programming Languages
Python
Experimental JIT Compiler: CPython において試験的に実装されている JIT コンパイラ。前述した Lua 処理系である Deegen 等を参考に、Copy-and-Patch コンパイルと呼ばれる最新の JIT コンパイル手法を用いて実装されています。
Copy-and-Patch コンパイルとは、既存のコード片(コードスニペット)を再利用し、それを適切に修正(パッチ)することで新しいコードを生成する、主に JIT コンパイラ向けの新しい手法です。
次の図は、Copy-and-Patch コンパイルを用いて修正可能なコードを生成する方法を説明するために、インタープリタの実装からコード生成する関数を実装する過程を表しています。修正可能なコードを生成するために、Copy-and-Patch コンパイルでは extern 宣言を用いてバイナリの中にプレースホルダを埋め込みます。埋め込まれたプレースホルダは、リロケーション情報を利用することで JIT コンパイル時に適切なアドレスに置き換えることができます。このように修正可能なコード片を事前に生成することで、高性能なコードを高速に生成できることが Copy-and-Patch コンパイルの利点となっています。

インタープリタの実装からスタートして、Copy-and-Patch コンパイルにおける LOAD_FAST 命令を生成する関数を導く過程(あくまで説明のための概念図)。🔗Talks - Brandt Bucher: Building a JIT compiler for CPython - YouTube を元に作成
参考文献
- 🔗Talks - Brandt Bucher: Building a JIT compiler for CPython - YouTube
- 🔗PEP 744 – JIT Compilation | peps.python.org
- 🔗JIT Compilation · Issue #113464 · python/cpython
参考文献
- 🔗Speculation in JavaScriptCore | WebKit
- 🔗Introducing the B3 JIT Compiler | WebKit
- 🔗Building the fastest Lua interpreter.. automatically! | Haoran Xu
- 🔗Building a baseline JIT for Lua automatically | Haoran Xu
Inline Caching
Hidden Class
- 🔗An efficient implementation of SELF a dynamically-typed object-oriented language based on prototypes | ACM SIGPLAN Notices
- 🔗[PDF] JavaScript エンジンの実装技術 - 鵜川始陽
Watchpoint
Discussion
大変有益な記事を投稿いただきありがとうございます。
V8ではChrome117からSparkplugとTurboFanの間にMaglevという新しいJITコンパイラが導入されたことにより、JavaScriptCoreと同じく全4階層の構成になっています。
よくまとめて頂いて勉強になりました。ありがとうございます。
RubyのJITに関してですが、2021年にYJITがマージされました。2023年に新しくRJITがマージされ、MJITが削除されてYJITが事実上のメインJITエンジンとなっています。
Ruby 3.1正式リリース。Shopify開発のJITコンパイラ「YJIT」をメインラインにマージ
YJIT: Building a New JIT Compiler for CRuby
YJIT: a basic block versioning JIT compiler for CRuby
RJITはRubyでJITコンパイラを書くという野心的なプロジェクトですが、現在はExperimentalな位置付けです。
RJIT: RubyでRubyのJITコンパイラを書いた
MJITに関してですが、原型となったMJIT(区別のためVlad's MJITと呼びます)がレジスタマシンVMを採用していたのはその通りなのですが、RubyにマージされたMJITは互換性維持の観点から当初よりRubyの標準VM(スタックマシン)を使用するようになっています。
Ruby 2.6にJITコンパイラをマージしました
なお、参考文献にあるMIRは(作者はVlad's MJITと同じ方ですが)MJITとは別のプロジェクトです。文中の「高速なコンパイルを実現するために軽量 JIT コンパイラ」はMIRの特徴です。
(WebKit blogの表記をひと通り確認しましたが)DFGはあくまでdata flow graphのことであって、DFG JITコンパイラのことをDFGと呼んではいない(そう呼び出すと余計な混乱が生じる)と思います。IRのJITコンパイラのことをIRとは呼ばないのと同じです。FTL JITコンパイラについても同様のことがいえそうです。
(1本の記事だけの問題としては些細なことなのですが、この記事は資料価値が高くて今後たびたび参照されそうな気がするので、あまりこの表記が広がらないうちに是正されたほうが良いと思いコメントしました。)
コメントありがとうございます。修正に反映させていただきます。