MLIR がもたらす新たな中間表現の可能性
はじめに
半導体の微細化が鈍化し、ハードウェアによる高速化が困難になっている現状において、ソフトウェアによる計算の高速化が喫緊の課題となっています。この状況において、特定のドメインの問題を解くことに最適化された言語であるドメイン固有言語と、そのコンパイラであるドメイン固有コンパイラの活用が望まれています。
ドメイン固有コンパイラの構築の際には、開発を容易にするために、既存のコンパイラ基盤であるLLVMを活用することが考えられます。しかし、LLVM はドメイン固有コンパイラの構築にはあまり向きません。この理由は、LLVM の成功と表裏一体の関係にあります。
LLVM が成功した理由は、コンパイラの処理を適切に分割し、独立したモジュールとして機能させたことにあります。このモジュール化において中心的な役割を果たしているのが、LLVM で用いられる中間表現(Intermediate Representation; IR)であるLLVM IRです。LLVM は、高水準言語とハードウェアの両方に依存しない中間表現である LLVM IR を使用することで、コンパイラのフロントエンドとバックエンドの完全な分離に成功しました。また、LLVM IR を唯一の中間表現とすることで、フロントエンドとバックエンドの再実装の数を
しかし、これらの設計のトレードオフとして、柔軟性とオプション性が LLVM IR から失われました。その理由は、LLVM を用いたコンパイルフローでは、すべてのフローが LLVM IR を経由することにあります。その結果、LLVM IR の変更は、思わぬところに波及効果を引き起こす可能性があるため、容易ではありません。また、LLVM は LLVM IR 以外の中間表現を持たないため、ドメインに依存した解析や最適化を導入することも容易ではありません。
これらの課題を解決し、ドメイン固有コンパイラの構築を容易にするために、 MLIR (Multi-Level Intermediate Representation) は開発されました。MLIR とは、特定のドメインの処理にカスタマイズされた中間表現の定義と、複数の中間表現の協調動作を、1 つのインフラ上で実現させるための中間言語基盤です。MLIR は LLVM の一部として開発が進められており、コンパイラフローにおいて、抽象構文木の構築と LLVM IR の生成の間を橋渡しする役割を担っています。MLIR は中間表現のカスタマイズとモジュール化を促すことで、中間表現フローに柔軟性とオプション性を提供できると考えられています。
この文章の目的は、MLIR の基本的な構成要素を説明し、MLIR が解決する課題を説明することにあります。この文章の残りの部分は、以下のように構成されています。まず、既存の汎用コンパイラスタックとドメイン固有コンパイラスタックの現状を整理し、課題を述べます。次に、その課題を解決するための MLIR の中心的な概念である、中間表現と変換パスについて述べます。続いて、MLIR に利便性と再利用性をもたらしている、特徴的なパスの定義方法について述べます。これらの新たな概念によって、MLIR は上述した課題を解決しています。最後に、その後の展開として、MLIR において構築されつつある中間表現フローを俯瞰します。
この文章は、主に MLIR: A Compiler Infrastructure for the End of Moore's Law に基づいています。
既存のコンパイラスタックの課題
MLIR が開発されたきっかけは、多くの汎用コンパイラやドメイン固有コンパイラが開発されているにも関わらず、共通する開発基盤を共有していないことに気づいたことでした。ここでは、汎用コンパイラと深層学習コンパイラの 2 つを例に、既存のコンパイラスタックの現状と課題を整理します。
近年の汎用プログラミング言語の傾向として、プログラマの生産性を向上させるために、言語固有の解析や最適化を導入していることが挙げられます。例えば Swift では初期化されていない変数の使用を検出する仕組みが導入され、Rust では高度な所有権と生存区間の解析が導入されました。
これらの言語固有の解析を単純化し、解析の責任を明確化するために、これらのプログラミング言語の中間言語スタックでは、複数のレベルの中間表現が導入されました。例えば、Swift では Swift Intermediate Language (SIL)という中間表現が導入されました。また、Rust では High-level IR (HIR)と Mid-level IR (MIR)と呼ばれる 2 種類の中間表現が導入されています。
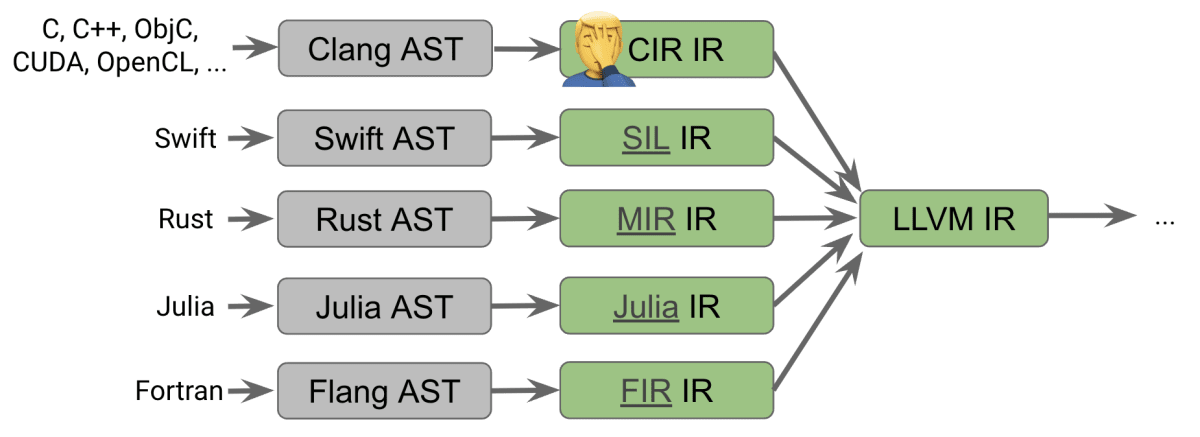
現代的なプログラミング言語のコンパイラスタック。現代的なプログラミング言語では、LLVM IR の前に、言語の高水準な情報を提供する中間表現である、高レベル中間表現が導入されている。ただし、Clang は高レベル中間表現を持たないため、複雑な情報の引き下げに頭を悩ませている 🤦♂️ 2020-02-26 - CGO 2020 Talk より引用。
しかし、言語固有の解析を導入するために、これらのプログラミング言語では既存の中間言語スタックを流用することができませんでした。そのため、共通する設計ポイントも多数存在するにも関わらず、個々の言語で中間言語スタックを開発しなければなりませんでした。そうして、個々の言語が自前の中間言語スタックを持った結果、開発で得られた知見が言語間で共有されずにいました。
また、深層学習コンパイラのコンパイラスタックでは、深層学習フレームワークとターゲットハードウェアの多様化に伴い、多くのコンパイラ、グラフ技術やランタイムが開発されました。しかし、ここでも共通する開発基盤や設計ポイントを共有できず、多数の再発明が行われました。また、変化の激しい分野では、中間表現スタックの開発に十分な資源を投資できるとは限りません。その結果、コンパイル速度が遅く、十分な診断情報を発行できないといった、コンパイラの品質の低下を招いていました。
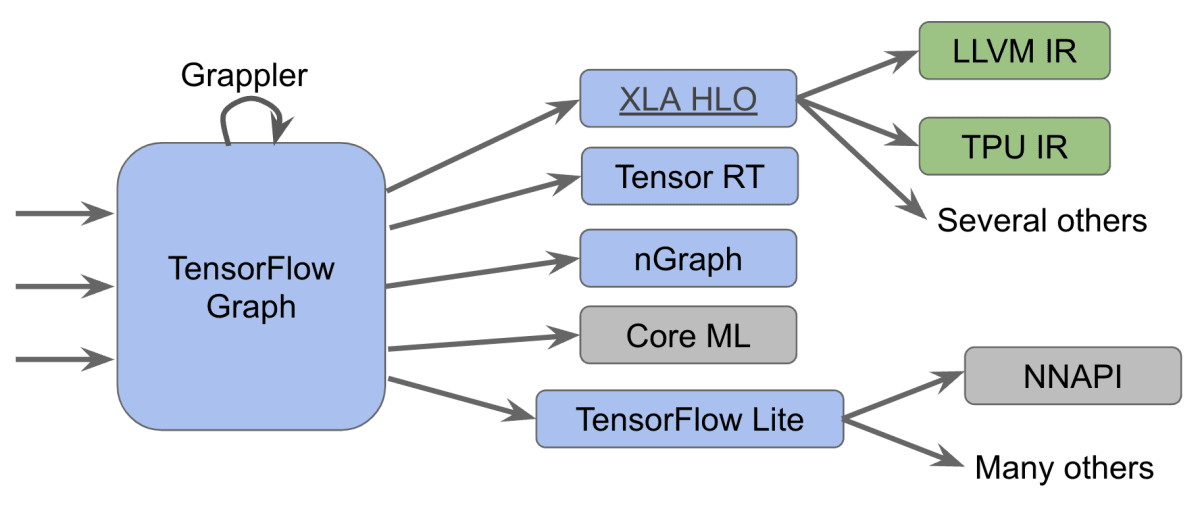
TensorFlow のコンパイラエコシステム。多くの異なるドメイン固有コンパイラシステムを有している。これらのシステムの数だけ、車輪の再発明が起こっている。2020-02-26 - CGO 2020 Talk より引用。
このように、生産性向上と特定のドメインの処理の効率化のために、コンパイラスタックに複数のレベルの中間表現が導入されるようになりました。しかし、既存の中間表現スタックは
- 共通基盤の再発明
- 中間表現の品質の低下
- 知見が共有されない
といった問題を引き起こしていました。
MLIR の中心的な概念
MLIR の本質は、完成された固定の中間表現を提供するのではなく、カスタム中間表現を定義するための仕組みと、そのカスタム中間表現を記述するためのメタ言語を提供することにあります。いわば、MLIR は中間表現を定義するための「入れ物」です。そのため、具体的な命令が定義された絶対的な中間表現が存在するわけではありません。
MLIR を用いて中間表現フローを構築したい場合、ユーザは、このカスタム中間表現(方言と呼ばれる)を定義して使用することができます。また、よく利用される汎用性の高い中間表現が LLVM プロジェクト内で開発されています。中間表現フローを構築したいユーザは、LLVM 内の中間表現を使用することもできます。
また、中間表現は単独では意味のある仕事はできません。解析パスや変換パスを定義することで、初めて中間表現に役割を持たせることができます。MLIR はパスを定義するための仕組みも備えています。
ここでは、以上のような、MLIR において中心的な役割を果たしている要素について紹介します。まず、MLIR のカスタマイズ性を示すために、カスタム中間表現を記述するためのメタ言語について説明します。続いて、中間表現とパスを定義する方法について説明します。
この文章では、中間表現の実装方法の詳細まで立ち入ることはできていません。詳細を知りたい方は、MLIR で Hello, Tensor という素晴らしい記事もありますので、参考にしてください。
MLIR のメタ言語
MLIR の特徴は、カスタマイズ可能な中間表現にありますが、そのカスタマイズに柔軟性を与えているのが、カスタム中間表現を記述するためのメタ言語になります。メタ言語は、LLVM IR の Instruction に対応する要素である、Operation によって構成されています。MLIR では、モジュールや関数を含めた、すべての構造が Operation によって表されています。
以下に Operation の例と構成要素を示します。MLIR のメタ言語において、Operation の使用は静的単一代入形式(SSA 形式)で記述されます。

Operation の例 1:llvm.icmp Op
①Operation 名:Operation を一意に識別するための名前。Operation の属する名前空間を表す方言名と、Operation の識別子であるニーモニックからなる。
②Argument:Operation の引数。MLIR は 2 種類の引数をサポートしている。1 つ目は、他の Operation によって実行時に生成される値をとる引数である、Operand である。2 つ目は、コンパイル時に確定する定数値をとる引数である、Attribute である。
③Result:Operation の戻り値。
④ 型:MLIR のメタ言語は静的型付け言語であるため、すべての値が型を持つ。型はカスタマイズ可能であり、ある方言に属する型として定義することができる。また、よく使用される型が Builtin 方言に定義されている。以下に Builtin 方言において定義されている型の一部を示す。参考:🔗 Builtin Dialect
| 型 | 説明 |
|---|---|
| 整数型 |
i32 など。符号なし整数(ui)もある。bit 数(32 など)は任意の値を取れる。 |
| 浮動小数点型 |
f32, f64, bf16 など。 |
| 複素数型 |
complex<f32>など。 |
| タプル |
tuple<i32, f32>など。 |
| ベクトル |
vector<42xf32>など。 |
| テンソル |
tensor<6x7xf32>など。次元数未知のテンソル(tensor<6x?xf32>など)やランク未知のテンソル(tensor<*xf32>など)もある。 |
⑤ ソース位置情報:操作や値が元のプログラムにおいて記述されてい場所を表す情報。MLIR はデバッグとエラー報告を支援するために、常にソース位置情報を保持・追跡している。

Operation の例 2:toy.func Op を用いた関数定義
⑥Region:Operation の構成要素の 1 つ。Operation は Region を複数持つことも、持たないこともできる。Region は後述する Block を複数持つことができる。Region を使用することで、高水準な制御構造(for, while, if など)を表す Operation を定義することができる。
⑦Block:Region に含まれる要素。Block は Operation を複数持つことができる。Block の末尾の Operation は、Terminator と呼ばれる特別な Operation でなければならない。また、MLIR の Block は引数を持つため、MLIR に Phi 命令は存在しない。このアイデアは Swift Intermidiate Language からの借用である。
Block はコントロールフローグラフに基づく低レベルな制御構造を表すことができる。また、Block が持つ Operation がさらに Region を持つことで、ネストした構造を表すことができる。

ネストした構造の例。Operation は Region を持ち、Region は Block を持ち、Block は Operation を持つ。Block 内の Operation がさらに Region を持つことで、ネストした構造を表現することができる。左図は MLIR: A Compiler Infrastructure for the End of Moore's Law より引用。右図は 2020-02-26 - CGO 2020 Talk をもとに作成。
中間言語の定義
参考:🔗 Operation Definition Specification (ODS)
中間言語の定義を簡略化するために、MLIR では、Operation を宣言的に定義する方法をサポートしています。この仕組みを、Operation Definition Specification (ODS)といいます。
ODS は、LLVM においてコンパイラに共通するデータ構造を簡単に記述するためのメタプログラミング言語である、TableGen を用いて実現されています。ここでは、TableGen を用いたカスタム方言の定義方法を紹介します。
カスタム方言の定義は、カスタム Dialect クラスの定義とカスタム Operation クラスの定義の 2 段階からなります。
カスタム Dialect クラスの定義
カスタム Dialect クラスを定義するために、Dialect クラスのサブクラスを定義します。Dialect クラスとは、カスタム Dialect クラスを定義するためのスーパークラスです。Dialect クラスにおいて指定可能なフィールドのうち、一般的なものを以下に示します。
| フィールド名 | 説明 |
|---|---|
summary, description
|
方言のドキュメントを自動的に生成するために用いられる文章。summary には単純な 1 行の概要を書き、description には詳細な説明を書く。 |
name |
MLIR のメタ言語において Operation 名や型名に前置する名前空間。 |
cppNamespace |
C++のプログラムにおいて、カスタム Operation クラス等の定義が所属する名前空間。 |
カスタム Dialect クラスの定義例:
include "mlir/IR/OpBase.td"
def Your_Dialect : Dialect {
let summary = "Your dialect";
let description = [{
This is the dialect you are looking for.
}];
let name = "your";
let cppNamespace = "::your";
}
カスタム Operation クラスの定義
カスタム Operation クラスを定義する準備として、Op クラスのサブクラスを定義します。Op クラスとは、カスタム Operation クラスを定義するためのスーパークラスです。Op クラスの定義を以下に示します。
Op クラスのサブクラスを定義する際は、dialect に、上で定義したカスタム Dialect クラスを代入します。mnemonic と traits は、カスタム Operation クラスの定義の際に使用するため、ここではプレースホルダのままで構いません。
Op クラスのサブクラスの定義例:
class Your_Op<string mnemonic, list<OpTrait> traits = []>
: Op<Your_Dialect, mnemonic, traits>;
続いてカスタム Operation クラスを定義するために、先ほど定義した Op クラスのサブクラスをさらに継承したクラスを定義します。この際、先ほどプレースホルダにした ①Mnemonic, ②Traits と、③Operation クラスのフィールドを指定する必要があります。これらの要素の概要を以下に示します。
①Mnemonic:方言に所属する Operation の識別子。
②Traits:Operation の抽象的な性質を表すクラス。カスタム Operation クラスを定義する際に Traits を指定することで、Operation がある性質を満たすことを表明できる。指定した Traits は解析や最適化に利用することができる。例えば、以下のような Traits がある。参考:🔗 Traits
| Traits | 説明 |
|---|---|
Commutative |
Operation が可換である(X op Y == Y op X である)ことを表す Traits。 |
Idempotent |
Operation が冪等である(op(op(X)) == op(X)であるか、X op X == X である)ことを表す Traits。 |
ConstantLike |
Operation が副作用を持たず、オペランドを持たないことを表す Traits。 |
NoMemoryEffect |
Operation がメモリに影響を与えないことを表す Traits。 |
Pure |
Operation が副作用を持たず、常に投機的に実行可能であることを表す Traits。 |
③Operation クラスのフィールド:Operation クラスのフィールドのうち、一般的なものを以下に示す。
| フィールド名 | 説明 |
|---|---|
summary, description
|
Operation のドキュメントを自動的に生成するために用いられる文章。 |
arguments |
Operation の引数。実行時に生成される値の引数である Operand と、コンパイル時に確定する値の引数である Attribute の両方を指定できる。 |
results |
Operation の結果。 |
region |
Operation が持つ Region (Operation が入れ子になる Block の集合)。制御フローやデータフローの表現に使用される。 |
successors |
Operation が制御フローのターゲットとして持つことができる後続の Block。通常、制御フロー Operation に使用される。 |
builders |
Operation のコンストラクタである builder を定義する。builder は、C++や TableGen のコードで使用される。 |
hasVerifier |
Operation が正しく構築されていることを確認するために、カスタム検証ルーチンを持つことを表明するフィールド。このようなカスタムルーチンを持つことを表明するフィールドは、他にも、hasFolder, hasCanonicalizer, hasCanonicalizeMethod がある。 |
assemblyFormat |
Operation のアセンブリ表現の形式。これにより、MLIR のテキスト形式で Operation を読み書きする際のカスタム書式を決めることができる。 |
カスタム Operation クラスの定義例:
def Your_SimpleOp : Your_Op<"simple", []> {
// Operationのフィールドを定義
let arguments = (ins Type:$input);
let results = (outs Type:$output);
}
例:TensorFlow の TF 方言
カスタム中間表現を定義する例として、TensorFlow プロジェクトにおいて用いられている TF 方言を紹介します。MLIR は、TensorFlow プロジェクト内で開発され、LLVM に寄贈されたという経緯があります。そのため、MLIR では、TensorFlow モデルのコード生成を行う中間表現フローが早期から構築されています。
TF 方言は TensorFlow のすべての Operation を表すための方言です。約 700 個の Operation によって構成されています。
▼ カスタム Dialect クラスの定義
▼Op クラスのサブクラスの定義
▼tf.Const Op の定義
▼tf.While Op の定義
▼tf.Add Op の定義
▼tf.LeakyRelu Op の定義
変換パスの定義
参考:🔗 Pattern Rewriting : Generic DAG-to-DAG Rewriting
MLIR は、複数の中間表現を設定し、段階的にハードウェアに近い中間表現へと引き下げることを意図して設計されています。その中で、変換パスは、極めて重要な役割を果たしています。同時に、プログラムの意味を変えずに表現を変えるモジュールである変換パスの実装は、非常に複雑で難しくなることが予想されます。
MLIR は、大きく分けて 2 種類のパスの実装方法を提供しています。1 つ目は、C++を用いたパスの実装方法です。この方法は、実装が複雑になるものの、表現力が高く、幅広い変換パスを実装することができます。2 つ目は、TableGen を用いた宣言的なパスの実装方法です。この方法は、定義可能なパスの種類が限られるものの、変換パスを非常にシンプルに構成することができます。
ここでは、C++を用いてカスタムパスを定義する方法を紹介します。
カスタムパスを定義するには、RewritePatternクラスの派生クラスを定義する必要があります。ここで、RewritePatternクラスとは、一般的な書き換え規則を持つカスタムパスを定義するための基底クラスのことです。派生したカスタムパスクラスでは、以下のメソッドを override する必要があります。
-
matchメソッドとrewriteメソッドを override する - もしくは、
matchAndRewriteメソッドを override する
▼ 例:LinalgRewritePattern。このパスは、Linalg 方言に属する Operation を、SCF 方言を用いた制御文に書き換えます。
また、MLIR には、特定の性質を持つ書き換え規則を記述するための、ユーティリティクラスも用意されています。これらのクラスは、RewritePatternクラスの派生クラスです。これらのクラスをさらに継承することで、カスタムパスを定義することができます。そのようなユーティリティクラスには、以下のようなクラスがあります。
①OpRewritePatternクラス:特定の Operation の書き換え規則を定義するためのクラス。
▼ 例:FuseElementwiseOps。このパスは、elementwise mapping (テンソルの各要素に独立して関数を適用する写像)であるlinalg.generic Op を融合します。
②OpInterfaceRewritePatternクラス:特定のグループに属する Operation の書き換え規則を定義するためのクラス。
▼ 例:LinalgOpToLibraryCallRewrite。このパスは、Linalg 方言に属する Operation を、高度に最適化された外部ライブラリのカーネルに置き換えます。
③OpTraitRewritePatternクラス:特定の Trait を満たす Operation の書き換え規則を定義するためのクラス。
▼ 例:ReorderElementwiseOpsOnTranspose。このパスは、Elementwise Trait を満たす Operation の実行順序を、可能な限りvector.transpose Op の前に移動します。これにより、類似する Operation の実行順序を近づけることで、さらなる最適化を促進します。
④ConversionPatternクラス:方言間の書き換え規則を定義するための特別なクラス。
例:TensorFlow の TF 方言の変換
カスタムパスを定義する例として、TF 方言を HLO 方言に変換するパスを紹介します。HLO 方言とは、TensorFlow の中間表現フローにおいて、TF 方言の次に経由する方言です。HLO 方言は、TF 方言で記述された計算グラフを、限られた数の Operation で表すことを目的としています。HLO 方言は、約 120 個(TF 方言の約 6 分の 1)の Operation で構成されています。そのため、TF 方言の Operation には、直接対応する Operation が HLO 方言にある場合と、ない場合があります。
例えば、Add Op は TF 方言と HLO 方言の両方に存在します。そのため、TF 方言のAdd Op は HLO 方言のAdd Op に直接変換されます。
一方、LeakyRelu Op (x を x > 0 ? x : x * alpha に写す Operation)は TF 方言には存在しますが、HLO 方言には存在しません。そのため、TF 方言のLeakyRelu Op は HLO 方言の Operation を組み合わせて表されます。
以下のTf2XlaRewritePatternは、これらのパスをまとめ、TF 方言を HLO 方言に書き換えるパスです。Tf2XlaRewritePatternはConversionPatternを継承して定義されています。
MLIR の特徴
宣言的なパスの定義
参考:🔗 Table-driven Declarative Rewrite Rule (DRR)
カスタム変換パスの定義を簡略化するために、MLIR では、変換パスを宣言的に定義する方法をサポートしています。この仕組みを、Declarative Rewrite Rule (DRR)といいます。DRR もまた、TableGen を用いて実現されています。
DRR は、「Operation の単なる書き換え」で表されるような変換パスを、簡単に定義することに特化した仕組みです。そのため、表現できる変換パスは限られるものの、Operation の書き換え規則の定義を、変換元の指定と変換先の指定の 2 点で完結させることができる優れものです。DRR では、Pattern クラスまたは Pat クラスを用いてカスタム変換パスを定義します。Pattern クラスと Pat クラスの定義を以下に示します。
Pattern クラスは、一般的な書き換え規則を定義するために使用されるクラスです。Pattern クラスのサブクラスを定義することで、カスタム変換パスを定義することができます。Pattern クラスは、source と results を引数に持ちます(preds と benefitAdded の説明は省略)。source で変換元を表す Operation を指定でき、results で変換先を表す Operation を指定できます。
Pat クラスは、Pattern クラスを用いた書き換え規則をより簡潔にするための、Pattern クラスのサブクラスです。書き換え規則の変換先が 1 つに定まる場合は、Pattern クラスの代わりに Pat クラスを用いることで、書き換え規則をより簡潔に表すことができます。
例:TensorFlow の TF 方言における最適化と lowering
ここでは TF 方言を例に、Pat クラスを用いて宣言的に書き換え規則を定義する方法を示します。
▼RedundantReshape:連続する 2 つのtf.Reshape Op を 1 つの Reshape にまとめる最適化。
▼LowerSizeOp:tf.Size Op を他の Operation で表す変換。
▼FuseMulAndConv2D:tf.Conv2D Op の次に来るtf.Mul Op を融合する最適化。
一般化されたパスの定義
コンパイラで広く行われている最適化の中には、様々な抽象化レベルで広く適用可能な最適化もあります。そのような最適化を、カスタム方言を定義するたびに実装しなければならないのは、極めて煩雑です。そこで、パスの再利用を可能とし、再実装を回避するために、 MLIR では、一般化された、再利用可能なパスを定義する方法を、3 種類提供しています。
Operation の性質を利用したパスの定義
コンパイラで広く行われている最適化の例として、共通部分式削除(Common Subexpression Elimination; CSE)や、不要式削除(Dead Code Elimination; DCE)が挙げられます。これらの最適化パスは、「Operation が副作用を持たない」あるいは「Operation が可換である」といった、ごく単純な Operation の性質にのみ基づいています。そのため、これらの最適化パスは、Operation の詳細に依らず、幅広い場面で適用することができます。
このような Operation の性質にのみ基づく最適化パスの再実装を避けるために、MLIR は Trait という仕組みを導入しています。Trait とは、Operation が満たす抽象的な性質を表すクラスです。Operation を定義する際に、Traits を指定することで、Operation がある性質を満たすことを表明できます(中間言語の定義、も参照)。
MLIR で定義されている Trait の 1 つに、Operation が可換であることを表す Trait である、Commutativeがあります。arith.addi Op など、多くの Operation がCommutative Trait を満たします。
MLIR では、Operation が可換であることを利用した最適化が、Commutative Trait に基づいて行われています。例えば、定数畳み込みを行うメソッドであるtryToFoldメソッド内では、定数を Operand の末尾に移動する変換が行われています。この変換によって、計算式内で定数の位置を近づけ、さらなる最適化を促進します。
Operation hook を利用したパスの定義
参考:🔗 Operation Canonicalization
コンパイラで広く行われている最適化の中には、Operation の詳細に依存した最適化もあります。そのような最適化として、定数畳み込み(Constant Folding)と、式の標準化(Canonicalization)の 2 つが挙げられます。
定数畳み込みとは、コンパイル時に確定している 2 つの定数値の計算式をコンパイル時に計算し、計算式を計算結果で置き換える最適化です。例えば、addi(addi(x0, c0), c1)をaddi(x0, c0 + c1)に置き換えます。ここで、c0とc1を畳み込む方法(ここではc0 + c1に畳み込む)は、Operation の種類(ここではaddi)に強く依存しています。例えば、Operation がmuliであった場合は、畳み込んだ結果はc0 * c1であるべきでしょう。
また、式の標準化とは、計算式を特定の規則に基づいて書き換える最適化のことです。式の標準化を行うことで、動的な値を含む計算式を畳み込み、計算回数を減らすことができる場合があります。ここでも、畳み込みを行う方法は Operation の種類に強く依存しています。そのような畳み込み規則として、addi(x, 0) == x, muli(x, 0) == 0, subi(x, x) == 0, maxsi(x, x) == xなどが考えられます。
このような Operation の詳細に基づいた最適化を行うために、MLIR では、Operation 固有の最適化をカスタマイズすることができる hook が設けられています。現時点では、① 定数畳み込みの hook と ② 式の標準化の hook が設けられています。
①定数畳み込みの hook:定数式を畳み込む方法を指定できる hook。Operation を定義する際に、hasFolderフィールドを 1 にすることで有効化できる。さらに、C++で Operation のfolderメソッドを override することで、定数式を畳み込む方法を指定できる。例えば、arith.addi Op のfoldメソッドは以下のように定義されている。
② 式の標準化の hook:式を標準化する方法を指定できる hook。Operation を定義する際に、hasCanonicalizerフィールドを 1 にするか、hasCanonicalizeMethodフィールドを 1 にすることで有効化できる。hasCanonicalizerフィールドを 1 にした場合は、C++でgetCanonicalizationPatternsメソッドを override する。hasCanonicalizeMethodフィールドを 1 にした場合は、C++でcanonicalizeメソッドを override する。例えば、arith.addi Op のgetCanonicalizationPatternsメソッドは以下のように定義されている。
このとき、書き換えパターンクラスは、宣言的書き換え規則(DRR; 宣言的なパスの定義、も参照)を用いて以下のように定義されている。
Interface を利用したパスの定義
参考:🔗 Interfaces
コンパイラで広く行われている最適化の中には、ごく一部の Operation のみ詳細に依存した変換を行いますが、その他の Operation ではデフォルトの変換で済むようなものも存在します。そのような最適化の一例として、関数のインライン化(Function Inlining)が挙げられます。
関数のインライン化とは、関数呼び出しを関数本体で置き換えることで、関数呼び出しのオーバーヘッドを削減する最適化のことです。関数のインライン化が可能か否かを判断するには、その関数に属するすべての Operation について、以下の情報が得られる必要があります。
- Operation が与えられた Region にインライン化可能か否か
- インライン化後に、Block の途中で終わってしまった Terminator Operation をどう扱うか
一方、これらの情報は、方言ごとにある程度決まっています。1 つの方言内で特別な処理が必要な Operation はほんの一部であり、その他の Operation はデフォルトの操作で事足ります。このとき、すべての Operation に最適化をカスタマイズするための hook を用意するのは、複雑で面倒です。
このような場面で定義を簡略化するために、Interface は導入されました。Interface とは、特定のグループ単位で Operation の最適化処理をカスタマイズためのクラスです。例えば、DialectInlinerInterfaceクラスを用いることで、方言単位でインライン化のための最適化処理をカスタマイズすることができます。
DialectInlinerInterfaceクラスを用いて方言をインライン化に対応させるには、このクラスを継承した派生クラスを定義し、isLegalToInlineメソッドとhandleTerminatorメソッドを override する必要があります。例えば、Func 方言では、DialectInlinerInterfaceクラスの派生クラスが、以下のように定義されています。
MLIR が解決する課題
中間表現と中間表現基盤の開発コスト削減
MLIR は、以下に代表される開発基盤を提供することで、中間表現と中間表現基盤の開発コストの減少に貢献しています。
- ODS, DRR をはじめとする、中間表現とパスの宣言的な記述方法
- builder, verifier, parser, printer といった、中間表現の構築・解析・変換・デバッグに必要な基本的な開発基盤
- Canonicalizer, ConstantFolding, CSE, Inliner, InstCombiner といった、一般化された、再利用可能な最適化パス
中間表現の品質の向上
MLIR は、以下のような機能を提供することで、中間表現の品質の向上に取り組んでいます。
- 定型化されたドキュメント記述方法:定型化された Operation や Pass のドキュメント記述方法を提供することで、開発者が容易に中間表現のドキュメントにアクセスできるようにします。
- ソース位置情報の保持・追跡:ソース位置情報を保持する機能を備えることで、中間表現のデバッグとエラーの報告を支援します。
- マルチスレッドコンパイル:マルチスレッドコンパイルをサポートすることで、複数のコンパイルタスクを並列して実行し、コンパイル時間の短縮に貢献しています。
中間表現とパスのカスタマイズとモジュール化
MLIR を中間言語基盤に用いることで、拡張性と再利用性に優れた中間表現を利用できるようになります。これにより、中間表現フローに柔軟性とオプション性を与えることができます。
はじめに、で紹介したように、MLIR が開発された経緯には、LLVM の課題がありました。LLVM は、中間表現の変更が容易ではないため、中間表現をコンパイラの解析や変換と共に進化させることが難しいという問題を抱えていました。しかし、MLIR を導入することで、柔軟な中間表現フローを構築できるようになり、中間表現の開発・選択・淘汰が容易となります。その結果、コンパイラ開発における知見の共有を促し、将来的には 1 つのドメインの処理が 1 つの中間表現フローに集約されることが示唆されます。
また、LLVM は、LLVM IR 以外の中間表現を持たないため、汎用コンパイラとは異なるニーズを持つドメイン固有コンパイラとの共存が難しいという問題を抱えていました。しかし、MLIR を導入することで、オプション性のある中間表現フローの形成が容易となります。このことは、複数のドメインの多様な中間表現フローが 1 つの基盤の上に共存しつつ、共通する処理を共有することのできるコンパイラスタックの構築を可能とするでしょう。
MLIR の展開
MLIR が誕生したことで、任意の抽象化レベルを表すことのできる中間表現を、1 つの基盤の上に定義することができるようになりました。この新たな可能性がもたらされたことで、現在、解析や変換のためにどのような中間表現を定義し、どのような中間表現フローを形成するべきか、議論されています。ここでは、MLIR において構築されている中間表現フローについて紹介します。
MLIR の現時点における中間表現フローは以下の図のように表されます。
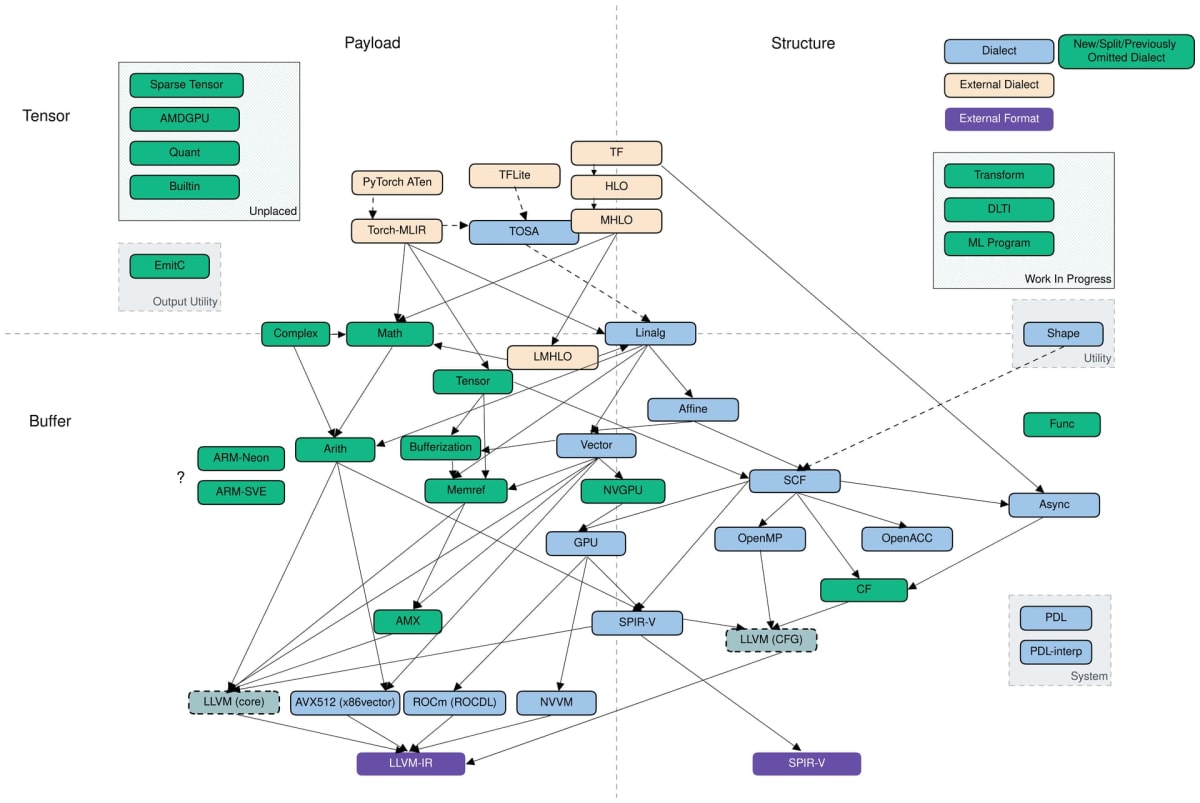
MLIR の 2022.08.22 時点での中間表現フロー。[RFC] Updated MLIR Dialect Overview Diagram より引用。
四角は定義されている方言を表しており、矢印は始点の方言から終点の方言への変換パスが存在することを表しています。これらの方言は 2 つの軸を持つ平面上に配置されています。
縦軸はテンソル ↔ バッファ軸であり、データ抽象化の度合いを表しています。ここで、テンソル(上)はメモリに関連しない定数値を指しており、副作用を持たない Operation とともに使用されます。また、バッファ(下)はメモリに関連する変更可能な値を指しており、メモリへの書き込みなどの副作用を持つ Operation とともに使用されます。
横軸は Payload↔Structure 軸であり、Operation が表す計算の性質を表しています。ここで、Payload(左)は実行されるべき計算を指しており、math.sqrt (平方根を計算する)のように、どの計算が実行されるかを表しています。また、Structure(右)は実行されるべき方法を指しており、scf.while (ある条件が満たされるまで繰り返す)のように、どのように計算が実行されるかを表しています。
縦軸では下流(バッファ側)に行くほどハードウェアに近い階層を表しています。最下流には LLVM IR と SPIR-V が位置しており、これらの中間表現まで lowering することで、ランタイム実行やコード生成を行うことができます。MLIR を利用して中間表現フローを形成するには、プロジェクト固有の操作を表すためのカスタム方言を定義し、既存の中間レベルまたは低レベル方言(複数となりうる)を選択し、それらの方言への変換パスを実装することになります。
続いて、中間表現フローの一例として、TensorFlow の中間表現フローを紹介します。
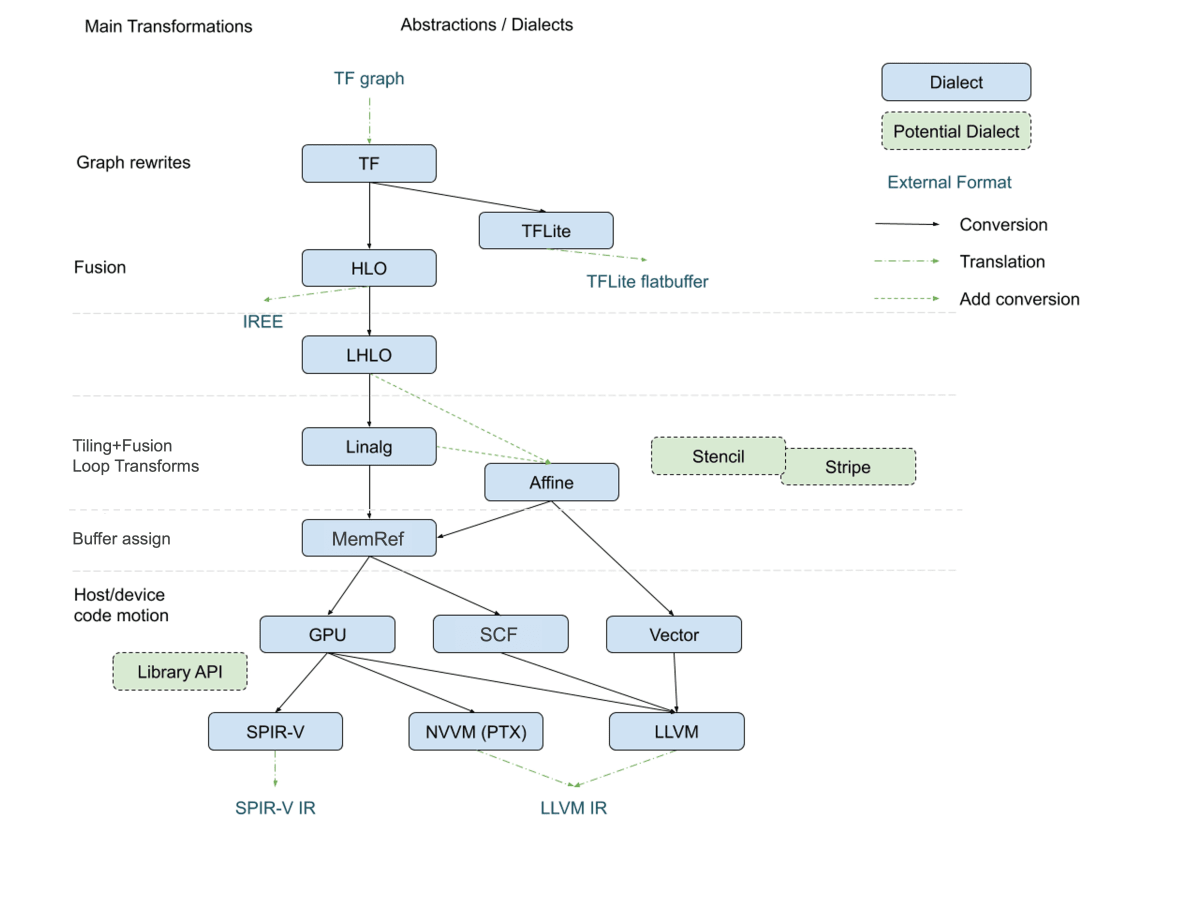
TensorFlow の中間表現フロー。オリジナルの資料の公開時は 2019.12.05 であり、情報が古いため、現状に合わせて修正を加えている。また、OpenXLA は考慮できていない。Structured Ops in MLIR Compiling Loops, Libraries and DSLs より引用、一部改変。
TensorFlow の中間表現フローは TF 方言に始まり、LLVM IR や SPIR-V をターゲットとします。その過程では、演算子融合・ループ変換・ベクトル化などの最適化や、メモリ割り当てが行われます。これらの変換に担当する方言がちょうど 1 つ存在することで、段階的な lowering と変換の責任の明確化を実現しています。
TensorFlow の中間表現フローを構成する方言のうち、LLVM プロジェクト内に含まれる方言の概要は以下のとおりです。参考:🔗 Dialects
| 方言 | 概要 |
|---|---|
| Linalg 方言 | 完全なループネストと affine 要素アクセスに基づく最適化を行う方言。 |
| Affine 方言 | 多面体モデルに基づく最適化を行う方言。 |
| MemRef 方言 | メモリ管理や具体的なデータアクセスに関連する操作を表す方言。 |
| SCF 方言 | 制御フローグラフよりも高水準な制御フロー(for, while, if など)を表す方言。 |
| Vector 方言 | SIMD 命令やデータ並列処理に関連するベクトル操作を表す方言。 |
ただし、これらの中間表現フローはあくまで現時点のものです。中間表現フローは、今後もコンパイラの解析や変換と共に進化し、方言の誕生や分裂を繰り返すでしょう。
おわりに
本記事は正確を期していますが、筆者の不勉強のために誤りが含まれる可能性があります。お気づきの点がございましたら、コメント頂けますと幸いです。
Discussion
とても分かりやすかったです(多分分かってないけど)。
素晴らしい記事を共有して頂き、ありがとうございます。
MLIRって"Machine Learning IR"だと勝手に思っていましたが、"Multi-Level IR"だったんですね。
大変有益なブログを有難うございました。