Stan ユーザーのための層別解析入門の準備
はじめに
因果推論の手法として知られる層別解析を勉強する過程で,私自身がつまずいた前提みたいな部分について書いていく.前提みたいな部分というのは,そもそもこれなんの計算してるの? というようなことで,層別解析のやり方についての解説まで至らない.なのでタイトルは「層別解析入門」ではなく「層別解析入門の準備」とした.
結論を先取りすると,おおむね下の箇条書きのようなことを述べる.
- 介入後の結果変数は観察データのモデルの結果変数とは(パラメータを共有する)別の確率変数だと思うのがいい
- 観察データのモデルが決まっても,それだけでは介入後を表すモデルは一意に決まらない
- 因果グラフも加えて仮定するとそれが一意に決まる
確率的グラフィカルモデルを用いた解説のスタイルは主に下記の文献を参考にした.
- Finnian Lattimore & David Rohde - Causal inference with Bayes rule (arXiv)
- Finnian Lattimore & David Rohde - Replacing the do-calculus with Bayes rule (arXiv)
- 著者自身による上の2つ論文の解説記事:Finnian Lattimore - Causal Inference with Bayes Rule
使用したコードの全体は記事の末尾にまとめてある.
確率的グラフィカルモデルを作る
まず(疑似)乱数を使ったシミュレーションをやってみたい.次の表で表せるような同時分布からの乱数をR言語(または適当な統計ソフト)を使って得るにはどうすればいいだろうか.
| 確率 | |||
|---|---|---|---|
| 0 | 0 | 0 | 0.200 |
| 1 | 0 | 0 | 0.050 |
| 0 | 1 | 0 | 0.200 |
| 1 | 1 | 0 | 0.200 |
| 0 | 0 | 1 | 0.050 |
| 1 | 0 | 1 | 0.245 |
| 0 | 1 | 1 | 0.005 |
| 1 | 1 | 1 | 0.050 |
3つ組の確率変数
このモンテカルロ・シミュレーションでは(単変量の)2項分布に従う乱数を生成する rbinom 関数を使うことにしよう.
条件付き確率の定義から,同時分布は次のようにも書ける.
右辺は単変量の2項分布の積で表せた.2項分布のパラメータを下記のリストのようにおく.
p(y=1|z,x) = \xi_{z,x} p(x=1|z) = \psi_x p(z=1) = \gamma
これは rbinom 関数でサンプリングできることを意味する.R のコードはたとえば次のようになる.
rand_case1 = function(n, xi, psi, gamma){
## draw x given by z
z = rbinom(n, 1, gamma)
x = rbinom(n, 1, psi[z+1]) #R の配列のインデックスは 1 からはじまるため,1 足して z=0 のときを 1行目, z=1 のときを 2 行目にしている
y = rbinom(n, 1, xi[cbind(z+1,x+1)])
return(data.frame(Y=y, X=x, Z=z))
}
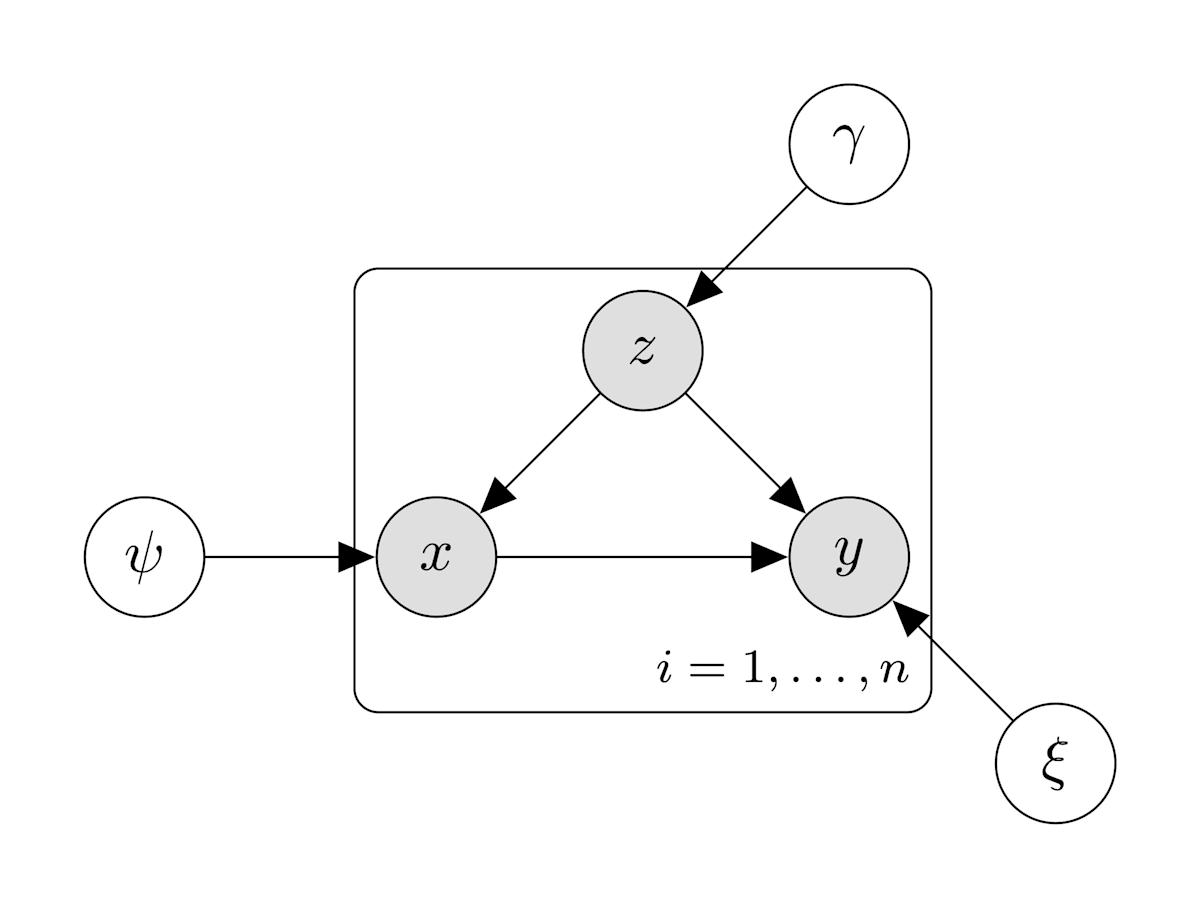
(1)の方針の確率的グラフィカルモデル
このように向きがあり,元のノードに戻るパスがないグラフを有向非巡回グラフ(Directed Acyclic Graph; DAG)と呼ぶ.
さて,(1)のような分解は一通りに限らない.たとえば次のようにしてもいい.
ここではパラメータを下記のリストのようにおく.
p(y=1|z,x) = \xi_{z,x} p(z=1|x) = \phi_x p(x=1) = \delta
これに対応する R のコードはたとえば次のように書ける.
rand_case2 = function(n, xi, phi, delta){
## draw z given by x
x = rbinom(n, 1, delta)
z = rbinom(n, 1, phi[x+1])
y = rbinom(n, 1, xi[cbind(z+1,x+1)])
return(data.frame(Y=y,X=x,Z=z))
}
グラフィカルモデルは下の図のようになる.
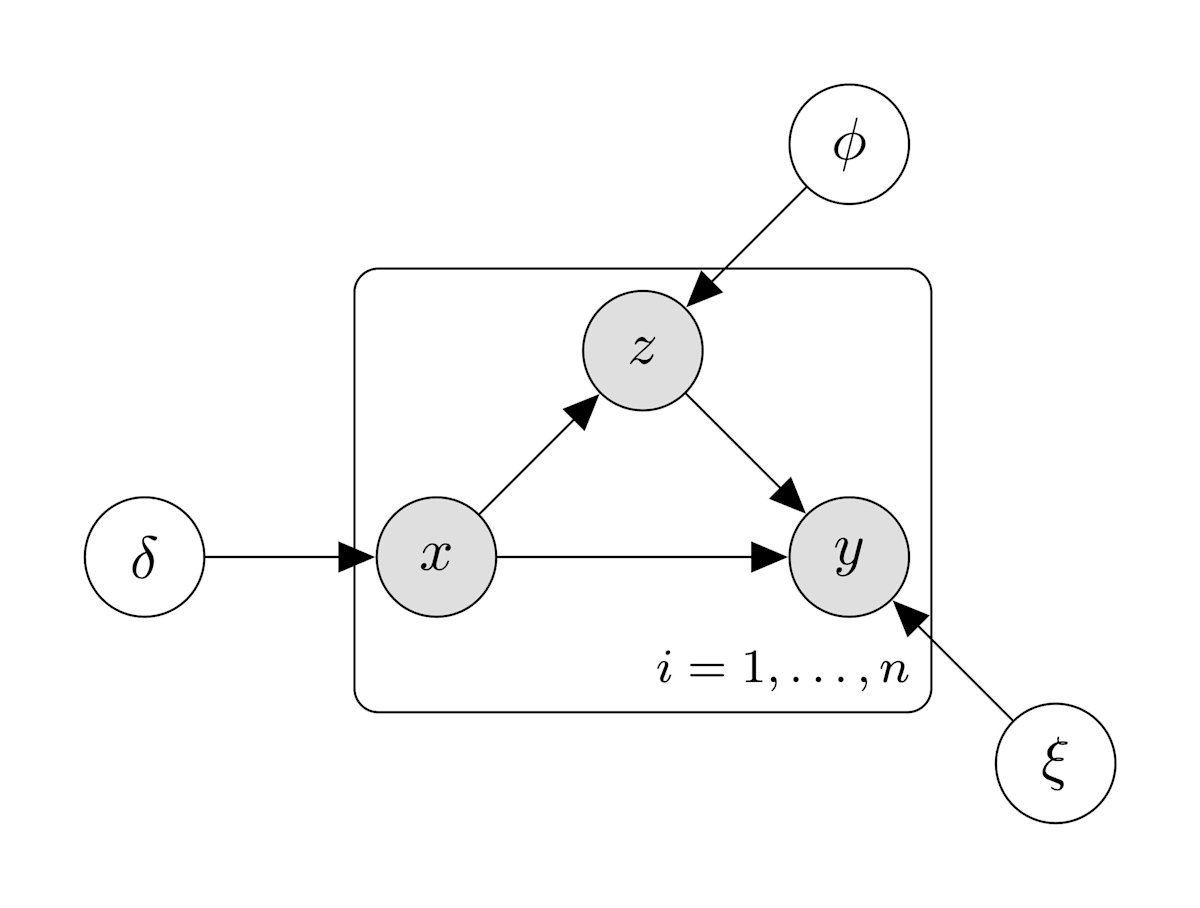
(2)の方針の確率的グラフィカルモデル
観測されない潜在変数(latent variable)は白丸,観測される変数をグレーの丸で表している.
試しに乱数を10000個サンプルして平均を取る.
PY_x = group_by(df_prob, x) %>%
summarise(p = sum(y*p)/sum(p))
PY_xz = group_by(df_prob, x, z) %>%
summarise(p = sum(y*p)/sum(p))
PX_z = group_by(df_prob, z) %>%
summarise(p = sum(x*p)/sum(p))
PZ_x = group_by(df_prob, x) %>%
summarise(p = sum(z*p)/sum(p))
PX = summarise(df_prob, p = sum(x*p)/sum(p))
PZ = summarise(df_prob, p = sum(z*p)/sum(p))
Xi = matrix(PY_xz$p, 2, 2)
rownames(Xi) = paste0("z", 0:1)
colnames(Xi) = paste0("x", 0:1)
dat1 = rand_case1(n = 10000, xi = Xi, psi = PX_z$p, gamma = PZ$p)
tab1 = group_by(dat1,Y,X,Z) %>%
tally() %>%
ungroup() %>%
mutate(p=n/sum(n)) %>%
arrange(Z,X,Y)
dat2 = rand_case2(n = 10000, xi = Xi, phi = PZ_x$p, delta = PX$p)
tab2 = group_by(dat2,Y,X,Z) %>%
tally() %>%
ungroup() %>%
mutate(p=n/sum(n)) %>%
arrange(Z,X,Y)
kable(cbind(df_prob, "rand_case1" = tab1$p, "rand_case2"=tab2$p),
digits=3)
結果は下の表のようになった.
| y | x | z | p | rand_case1 | rand_case2 |
|---|---|---|---|---|---|
| 0 | 0 | 0 | 0.200 | 0.206 | 0.205 |
| 1 | 0 | 0 | 0.050 | 0.049 | 0.046 |
| 0 | 1 | 0 | 0.200 | 0.200 | 0.198 |
| 1 | 1 | 0 | 0.200 | 0.195 | 0.195 |
| 0 | 0 | 1 | 0.050 | 0.048 | 0.052 |
| 1 | 0 | 1 | 0.245 | 0.249 | 0.247 |
| 0 | 1 | 1 | 0.005 | 0.005 | 0.004 |
| 1 | 1 | 1 | 0.050 | 0.049 | 0.052 |
"p" の列がこのシミュレーションで最初に設定した真値である.rand_case1 と rand_case2,どちらの書き方でも同じ分布が得られていそうなことがわかる.
そして,このような形でモデルが書けたら,事後分布に従う乱数をサンプルするための Stan のコードも書くことができる.
パラメータもふくめて(1)の方針の確率的グラフィカルモデルが表す同時分布をもう少しちゃんと書くと次のようになる.
パラメータ(潜在変数)の事後分布は
(1) の場合:
//case1.stan
data{
int N;
array[N] int<lower=0,upper=1> Y;
array[N] int<lower=0,upper=1> Z;
array[N] int<lower=0,upper=1> X;
real<lower=0> alpha;
}
parameters{
matrix<lower=0, upper=1>[2,2] Xi;
vector<lower=0, upper=1>[2] psi;
real<lower=0, upper=1> gamma;
}
model{
for(i in 1:N){
Z[i] ~ bernoulli(gamma);
X[i] ~ bernoulli(psi[Z[i]+1]);
Y[i] ~ bernoulli(Xi[Z[i]+1, X[i]+1]);
}
to_vector(Xi) ~ beta(alpha, alpha);
gamma ~ beta(alpha, alpha);
psi ~ beta(alpha, alpha);
}
この Stan のコードの ~ の現れる行はすべて,(1') の右辺の対数を lp__ という変数に足し込む操作を意味する.
alpha は事前分布のパラメータとして導入したが今回はあまり活躍せず,ずっと 1 (一様分布)にしている.
(2) の場合:
#case2.stan
data{
int N;
array[N] int<lower=0,upper=1> Y;
array[N] int<lower=0,upper=1> Z;
array[N] int<lower=0,upper=1> X;
real<lower=0> alpha;
}
parameters{
matrix<lower=0, upper=1>[2,2] Xi;
vector<lower=0, upper=1>[2] phi;
real<lower=0, upper=1> delta;
}
model{
for(i in 1:N){
Z[i] ~ bernoulli(phi[X[i]+1]);
X[i] ~ bernoulli(delta);
Y[i] ~ bernoulli(Xi[Z[i]+1, X[i]+1]);
}
to_vector(Xi) ~ beta(alpha, alpha);
delta ~ beta(alpha, alpha);
phi ~ beta(alpha, alpha);
}
(1) と (2) は同じ同時分布を表している.変数変換によって
条件付き確率の定義から
この関係から
また,
この関係を用いて
および,
である. generated quantities ブロックを次のように書けばよい.
#case1.stan
generated quantities{
real<lower=0, upper=1> delta;
vector<lower=0, upper=1>[2] phi;
delta = psi[1]*(1-gamma) + psi[2]*gamma;
phi[1] = (1-psi[2])*gamma/(1-delta);
phi[2] = psi[2]*gamma/delta;
}
同様に
これより
また
この関係を用いて
および,
である.
#case2.stan
generated quantities{
real<lower=0, upper=1> gamma;
vector<lower=0, upper=1>[2] psi;
gamma = phi[1]*(1-delta) + phi[2]*delta;
psi[1] = (1-phi[2])*delta/(1-gamma);
psi[2] = phi[2]*delta/gamma;
}
サンプルサイズを
次の図からMCMCの系列が定常分布に収束した様子がうかがえる.
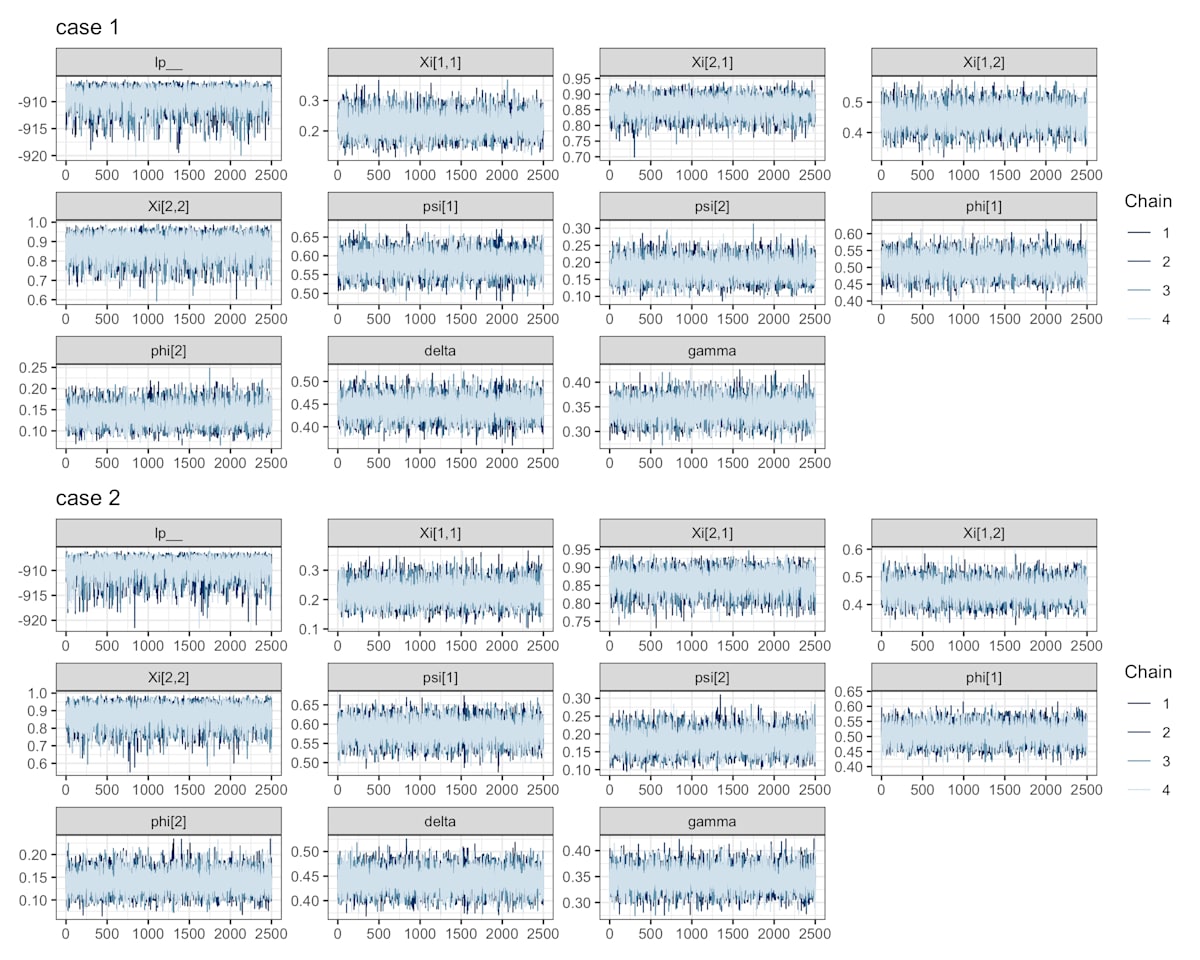
トレースプロット
各パラメータの事後分布の経験分布関数をプロットする.
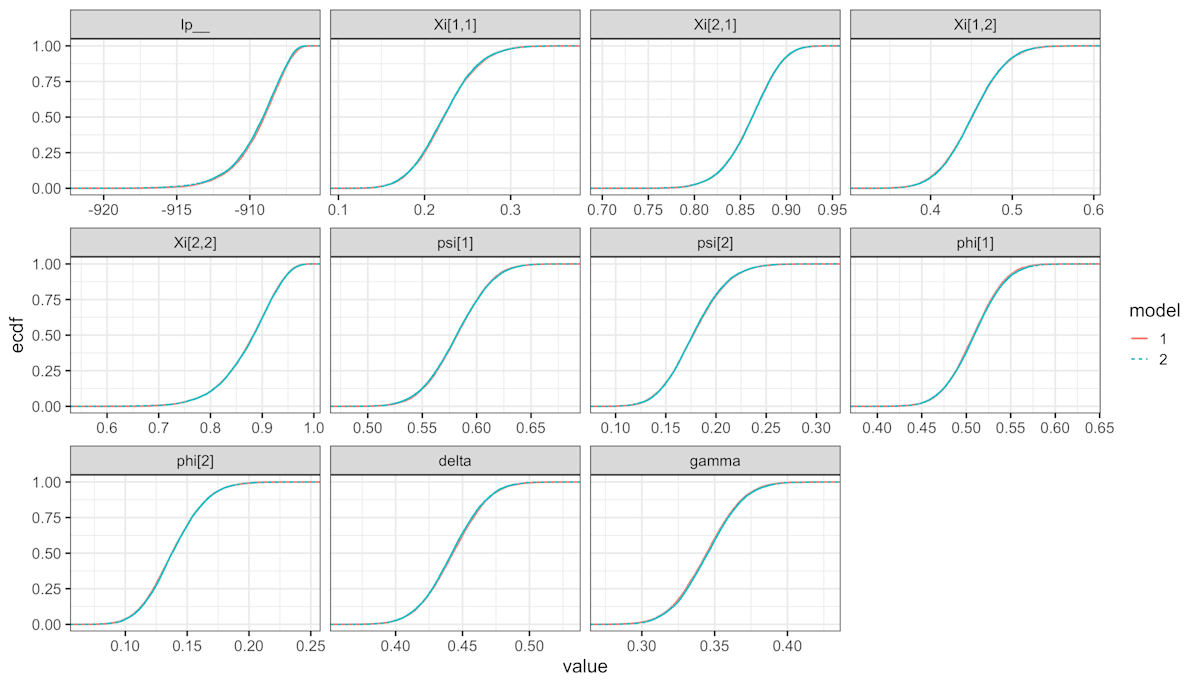
パラメータの事後分布
case1.stan と case2.stan を それぞれ model 1, 2 として色分けしたが重なっていてほとんど違いが見えない.つまり,ほぼ同じ事後分布が得られているとわかる.繰り返しになるが lp__ は同時確率の対数の総和である.
各パラメータの平均と標準誤差(この場合は事後分布の標準偏差のこと)は下の表の通り.
| variable | model1.mean | model1.sd | model2.mean | model2.sd | true |
|---|---|---|---|---|---|
| Xi[1,1] | 0.22 | 0.04 | 0.22 | 0.04 | 0.20 |
| Xi[2,1] | 0.86 | 0.03 | 0.86 | 0.03 | 0.83 |
| Xi[1,2] | 0.45 | 0.04 | 0.45 | 0.04 | 0.50 |
| Xi[2,2] | 0.88 | 0.06 | 0.88 | 0.06 | 0.91 |
| psi[1] | 0.58 | 0.03 | 0.58 | 0.03 | 0.62 |
| psi[2] | 0.18 | 0.03 | 0.18 | 0.03 | 0.16 |
| phi[1] | 0.51 | 0.03 | 0.51 | 0.03 | 0.54 |
| phi[2] | 0.14 | 0.02 | 0.14 | 0.02 | 0.12 |
| delta | 0.44 | 0.02 | 0.44 | 0.02 | 0.35 |
| gamma | 0.34 | 0.02 | 0.35 | 0.02 | 0.46 |
因果的グラフィカルモデルを作る
ここまでで同時分布は推定できた.仮にこのような分析を行い「この変数
一方でこれまでの考察で同時分布が定まっても
つまり (1) の方針でサンプリングする場合, (2) の方針でサンプリングする場合で
(1) の方針でのサンプリングを
#case1
generated quantities{
int Zast = bernoulli_rng(gamma)+1;
int Yast0 = bernoulli_rng(Xi[Zast,1]);
int Yast1 = bernoulli_rng(Xi[Zast,2]);
}
この Stan のコードは下の図のようなグラフィカルモデルを考えることに相当する.
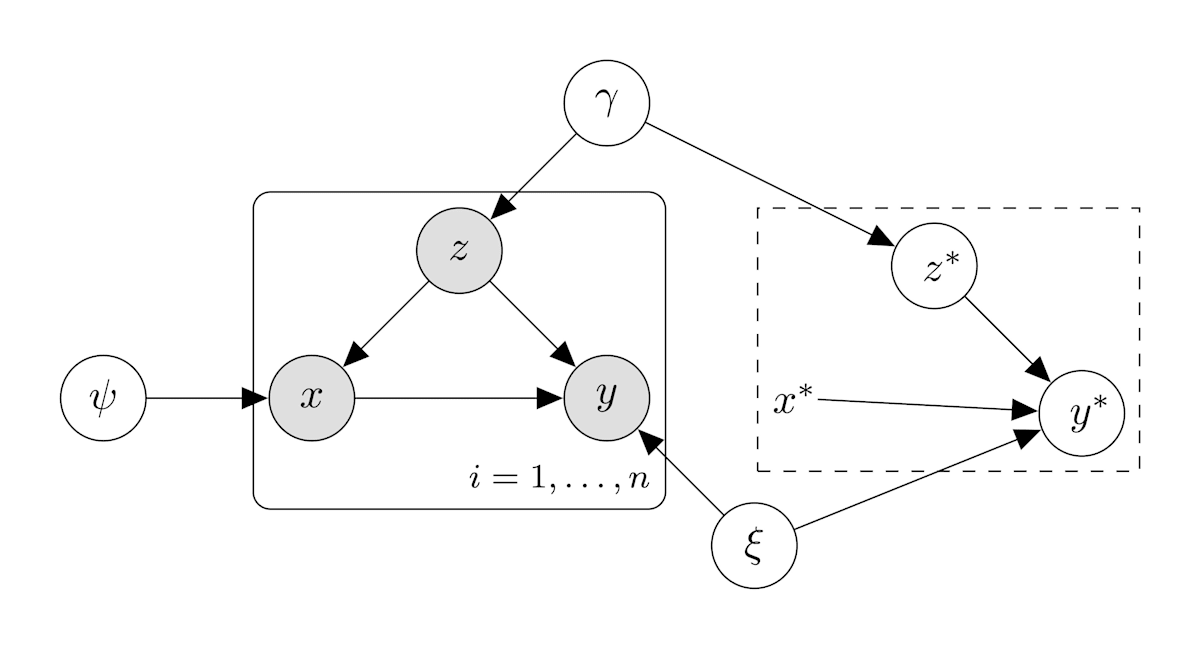
(1)の方針の確率的グラフィカルモデル2
(2) の方針でサンプリングする場合は,次のようになる.
#case2
generated quantities{
int Yast0;
int Yast1;
int Zast0;
int Zast1;
Zast0 = bernoulli_rng(phi[1])+1;
Zast1 = bernoulli_rng(phi[2])+1;
Yast0 = bernoulli_rng(Xi[Zast0,1]);
Yast1 = bernoulli_rng(Xi[Zast1,2]);
}
この Stan のコードは下の図のようなグラフィカルモデルを考えることに相当する.
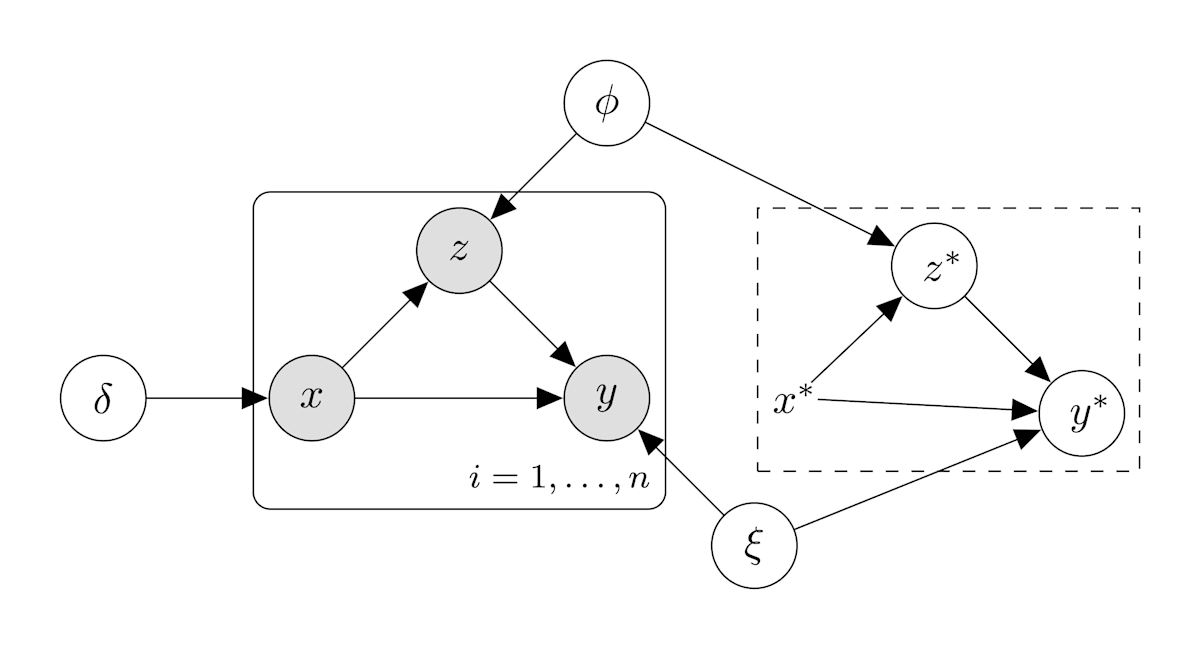
(2)の方針の確率的グラフィカルモデル2
「Xに効果があることがわかりました」という報告が「ただしここでいう効果はXを実際にやったときの効果ではありません」という意味だとすると,分析結果の使いみちに困る感じになる.
しかし,「
「
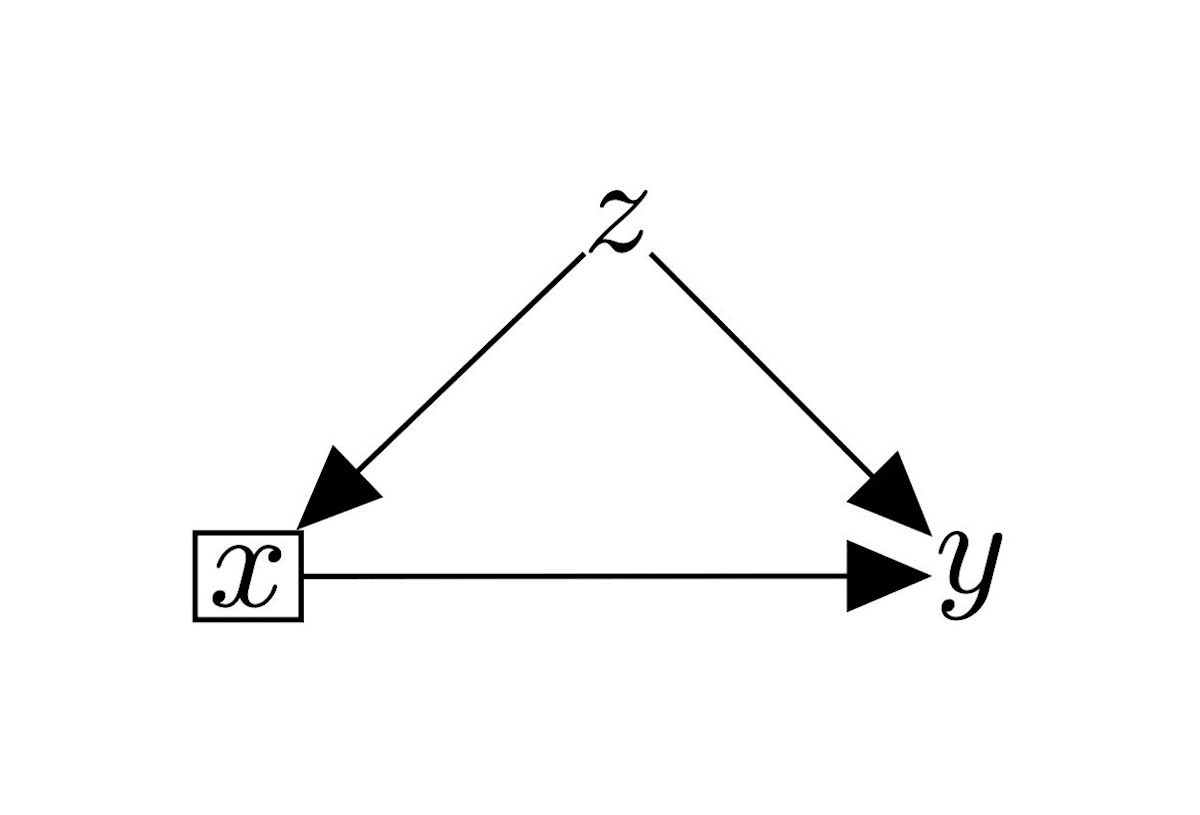
この図では
次のように因果グラフが与えられれば,
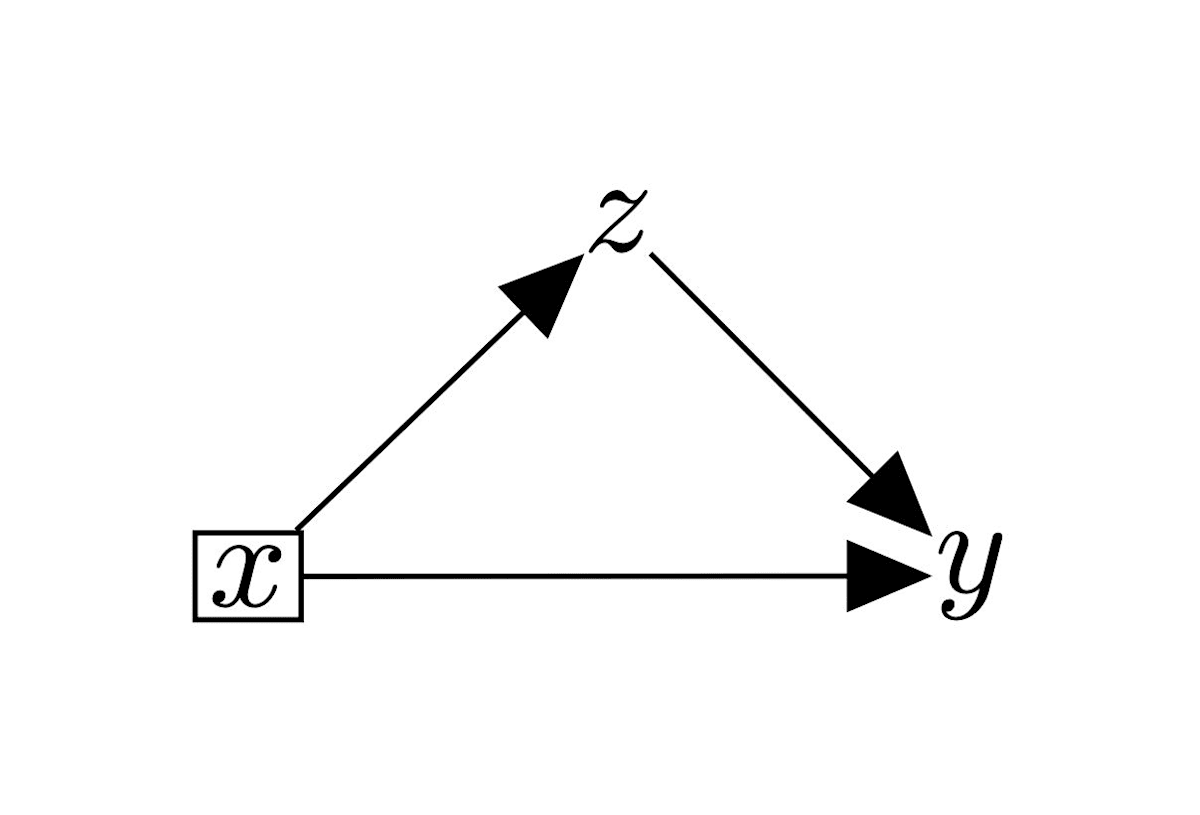
逆に言うと,このように介入後のモデルを考えるために必要な仮定を「因果」と呼んでいることになるだろう.
上のような介入を行った場合まで含めた確率的グラフィカルモデルは因果グラフから機械的に得られる.すなわち
因果グラフが
ここでは
因果グラフが
である.
潜在結果変数についての期待値
真の分布の下での平均処置効果は R では次のように書ける.
因果グラフが
ATE_case1 = function(xi, psi, gamma){
y0 = (1-gamma)*xi[1,1]+gamma*xi[2,1]
y1 = (1-gamma)*xi[1,2]+gamma*xi[2,2]
return(mean(y1-y0))
}
因果グラフが
ATE_case2 = function(xi, phi, delta){
y0 = phi[1]*xi[2,1] + (1-phi[1])*xi[1,1]
y1 = phi[2]*xi[2,2] + (1-phi[2])*xi[1,2]
return(mean(y1-y0))
}
平均処置効果の真値はそれぞれ次のようになる.
> print(round(ATE_case1(xi = Xi, psi=PX_z$p, gamma=PZ$p),3)) #D1
[1] 0.223
> print(round(ATE_case2(xi = Xi, phi=PZ_x$p, delta=PX$p),3)) #D2
[1] 0.008
Stan のコードで int D = Yast1-Yast0; のようにして,平均すれば平均処置効果の推定値が得られる.やってみた結果を下の表にまとめる.
| variable | mean | sd |
|---|---|---|
| D1 (case1.stan) | 0.16 | 0.60 |
| D2 (case1.stan) | -0.03 | 0.71 |
| D1 (case2.stan) | 0.15 | 0.61 |
| D2 (case2.stan) | -0.04 | 0.71 |
因果グラフが case1.stan と case2.stan はどちらも近い分布が得られるが,因果グラフの違いは大きく結果に影響することがわかる.
さて,実はこの設定ではMCMCを用いる必要はなく,事後分布はベータ分布であり閉じた形で求まる.もちろん最尤法を用いてもいい.というか,通例は最尤法を用いた場合の具体的な計算の手順が層別解析のやり方として紹介されている.因果推論に関する本をお持ちの方は,目次を探して「層別」や「標準化」の章があればそれを参照してほしい.例えば,
- 佐藤俊哉・松山裕,交絡という不思議な現象と交絡を取りのぞく解析—標準化と周辺構造モデル—,計量生物学 / 32 巻 (2011) ;リンク先に本文PDFあり
- 佐藤俊哉『宇宙怪人しまりす統計よりも重要なことを学ぶ』(朝倉書店)の第4話
- 林岳彦『はじめての統計的因果推論』(岩波書店) の4.1節「層別化と標準化で揃える」
などに解説がある.
ちなみに,『宇宙怪人しまりす統計よりも重要なことを学ぶ』では「層別解析」だとサブグループ解析などと混同しやすいことから,「層化統合解析」という用語を提案している.たしかにそのとおりだと思うので今後は「層化統合解析」の方を採用するかもしれない.今回はこの文章だけで完結するような書き方ではない (あまり self-contained でない)ので他の文献を参照しやすいよう,よく使われる「層別解析」を使用した.
感想など
統計的因果推論の必要性について
最初,因果グラフを与えた上でないと因果推論ができないのは物足りなく感じたことがある.
しかし,上の例のような因果効果の符号が逆とか,大きさが小さすぎとかの場面を想像すると,質的に因果関係がわかったとしても,量的な因果関係を知ることが重要と思えた.
一方で,大抵の場合は因果グラフも未知であり「モデル」である.因果的グラフィカルモデルを考えるときは,データの数字の部分だけでなくデータ取り方も重要になるだろうから,疫学の分野でよく言われる「コホート研究」や「ケースコントロール研究」などの観察研究の分類も,この観点から整理できるかもしれない.
因果的グラフィカルモデルについて意見がわかれるようなときも,仮定を明示したほうが「この部分がちょっと違った場合は……」のような議論がクリアになるだろう.
ついでに,「ちょっと違った」場合どの程度分析結果が変わりうるか,影響を量的に調べる感度分析というのも必要性があるだろう.
もう少し細かい話
数理統計の教科書では推定量のバイアス(bias)はパラメータ
また,上で標準誤差を見たような場面でP値を見ることも因果推論の目的とはまったく対立しないだろう.
使用したコードなど
Stan のコードの全体は,case1.stan がこちら:
case2.stan がこちら:
R のコードの全体はこちら:
グラフィカルモデルの図は TikZ で書いていて
のディレクトリにある.
Discussion