ロジスティック回帰を経由して2×2の分割表のオッズ比の検定を作る
モチベーション
なぜわざわざそんなことをするのか?
- 最近は機械学習の手法としてロジスティック回帰を学んだことはあるが分割表の独立性の検定は知らないみたいな人もそこそこいるだろうし, 既知のことから発展して色々できたほうが楽で良いと思ったから
- わざわざしなくてもいいようなことをしたいときもあるから
モデル:ロジスティック回帰
ジスティック回帰は説明変数
ここで,
である. また, 今回は特に2×2の分割表のみを考えたいため,
上の分布の
分割表のオッズ比の検定
上と同じ記号のもとで
であり,
であり,
であるから, 「
このオッズ比に対して帰無仮説
であるとして,
より,
とすることにより求める. 真の
すなわち, オッズ比の対数の点推定量を
を標準正規分布で近似して棄却域を求める.
ずいぶん粗い近似が出てくるように思うかもしれないが, その感覚はたぶん正しい. 統計学はサンプルサイズが大きいときに一致させたいという気持ちがあるのでテイラー展開(後ろのほうは
それが有限の現実的なサンプルサイズでうまくいくかというのは計算が難しく, シミュレーションに頼らざるを得ないことが多い.
ロジスティック回帰経由の分割表のオッズ比の検定
と置く.
であり,
であるから, 最尤推定量は変数変換に対して不変なので,
が得られる.
また
から
であるため, 二項分布の分散よりデルタ法では
と近似できる.
となる.
ちなみに
Stan Lipovetsky, Analytical closed-form solution for binary logit regression by categorical predictors. Journal of Applied Statistics, 2015.
でも同様の議論がなされている.
シミュレーション
カイ2乗分布とt分布を使った場合とでαエラーと検出力をシミュレーションしてみる.
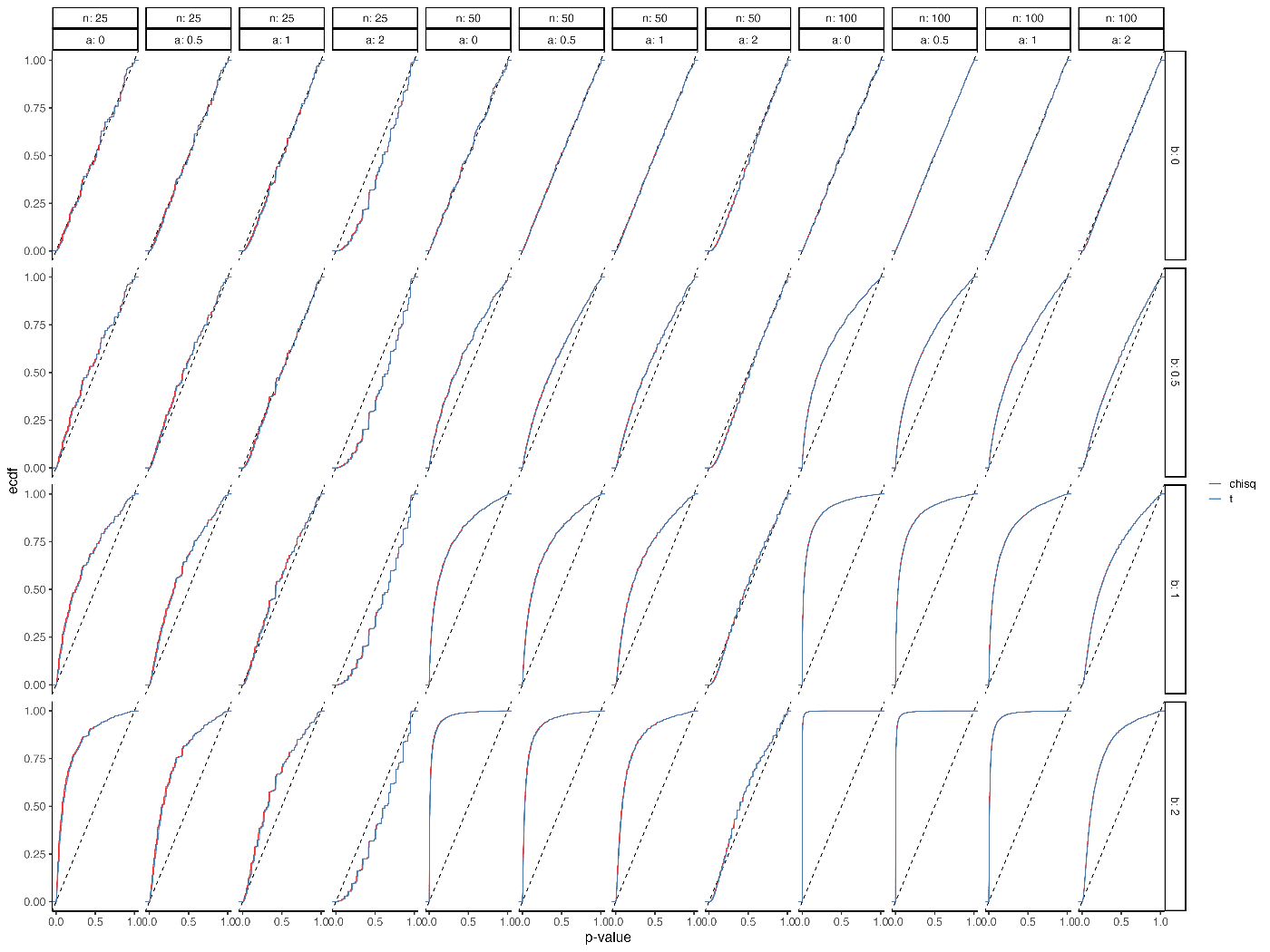
図の b=0 となっている行がαエラーで, どちらもほぼ名目上水準を達成していることがわかる.
違いはほとんどないが, 少しだけt統計量のほうが保守的である.
a (
R のコード
library(tidyr)
library(dplyr)
library(tibble)
library(ggplot2)
simOR <- function(i, n, a, b, beta0=0){
set.seed(i)
x <- rbinom(n, 1, 0.5)
y <- rbinom(n, 1, plogis(a+b*x))
x <- factor(x, levels = 0:1)
y <- factor(y, levels = 0:1)
tab <- table(x, y)
beta <- log(tab[2,2])-log(tab[2,1]) - (log(tab[1,2])-log(tab[1,1]))
se <- sqrt(sum(1/tab))
return((beta-beta0)/se)
}
cond <- as.matrix(expand.grid(n=c(25,50,100),
a=c(0,0.5,1,2),
b=c(0,0.5,1,2)))
conddf <- as.data.frame(cond) %>%
rowid_to_column()
res <- apply(cond, 1, function(par)sapply(1:10000, simOR, n=par[1], a=par[2], b=par[3]))
resdf <- pivot_longer(as.data.frame(res), 1:48, names_to = "rowid") %>%
mutate(rowid = as.integer(gsub("V","",rowid))) %>%
left_join(conddf, by="rowid")
ggplot(resdf)+
geom_abline(slope=1, intercept = 0, linetype=2)+
stat_ecdf(aes(x=pchisq(value^2, df=1, lower.tail=FALSE), colour="chisq"), alpha=0.9)+
stat_ecdf(aes(x=2*pt(abs(value), df=n-2, lower.tail=FALSE), colour="t"), alpha=0.9)+
scale_colour_brewer(palette = "Set1")+
facet_grid(b~n+a, labeller = label_both)+
labs(x="p-value", colour="")+
scale_x_continuous(breaks = seq(0,1,length.out=3))+
theme_classic(16)
ggsave("p_or1.png", width = 20, height = 15)
Discussion