📶
WebGPUでバイトニックソート

WebGPUのCompute Shaderを使ってバイトニックソートを実装してみます。
以前にJavaScriptとWebGLでバイトニックソートを実装したことあるので、それを参考に作成しました。
結果は以下のようになります。
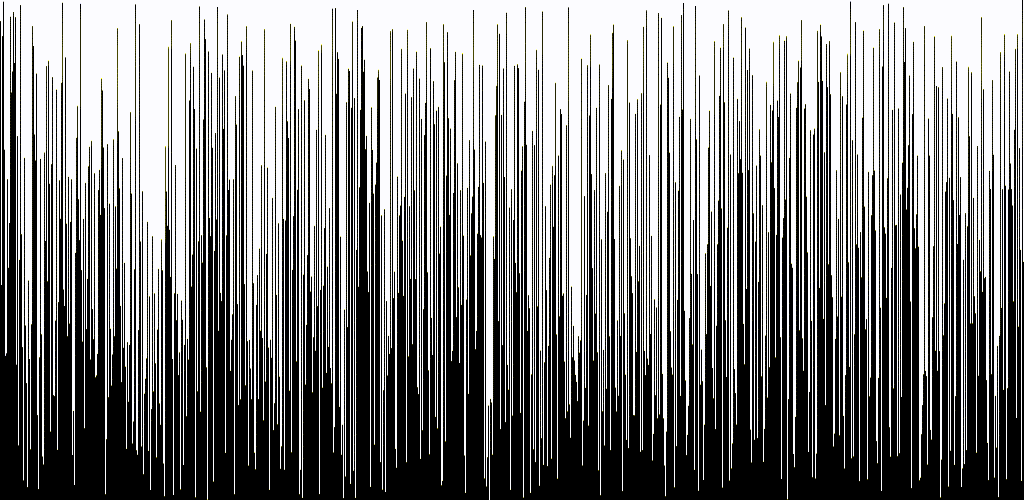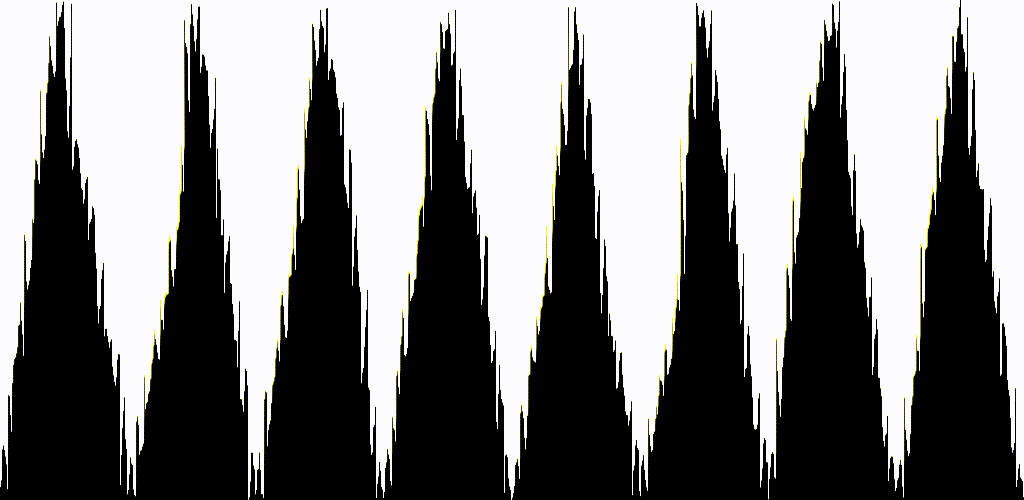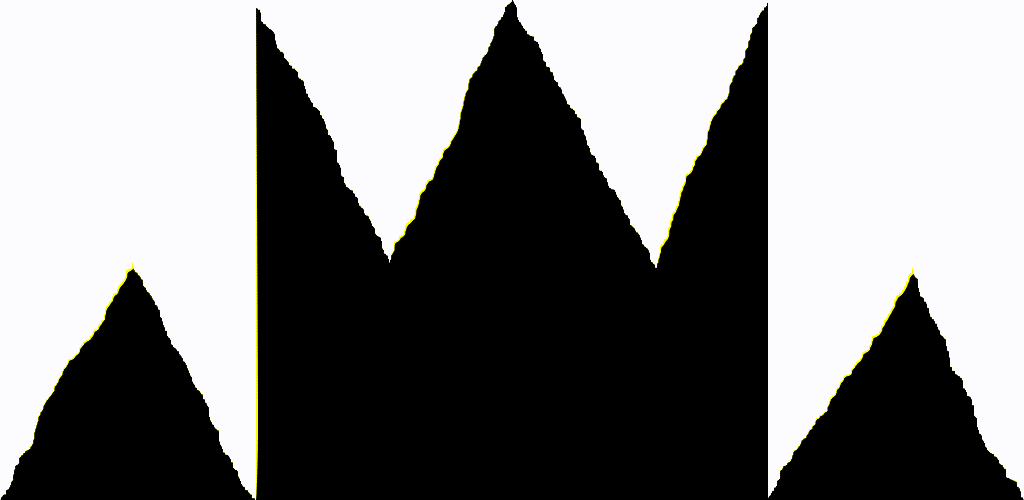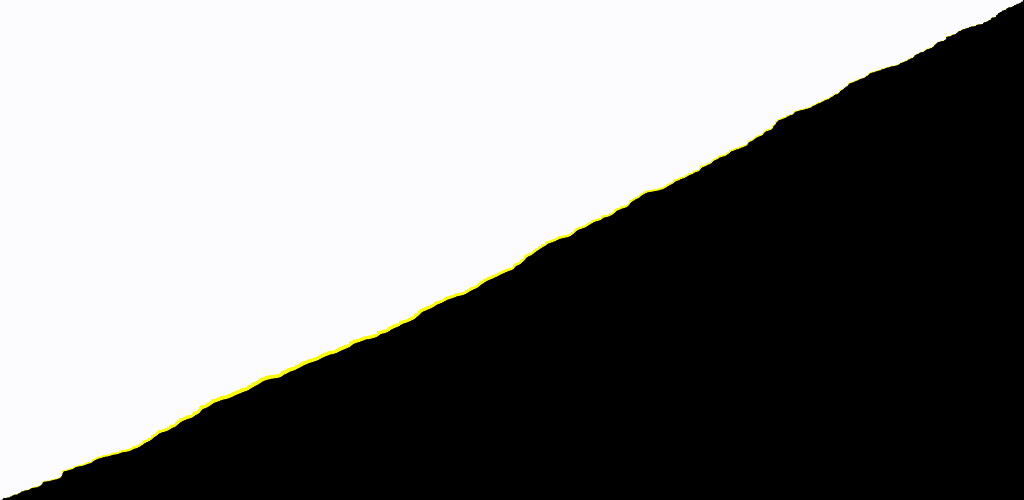
ソースコードはGitHubに置いてあります。
動くデモはこちらから確認できます。
バイトニックソートを行うbitonicsort関数は以下のようになります。
function getBaseLog(x: number, y: number) {
return Math.log(y) / Math.log(x);
}
async function bitonicsort(device: GPUDevice, array: Float32Array) {
// ソートする配列の長さが2の累乗である必要があるため、十分な大きさの配列を作成してダミーのデータで埋める
const base = Math.ceil(getBaseLog(2, array.length))
const paddedArrayLength = 2 ** base
const paddedArray = new Float32Array(Array.from({ length: paddedArrayLength }, (_, i) => i < array.length ? array[i] : 1))
let readBuffer = device.createBuffer({
size: paddedArray.byteLength,
usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_DST | GPUBufferUsage.COPY_SRC
})
device.queue.writeBuffer(readBuffer, 0, paddedArray.buffer)
let writeBuffer = device.createBuffer({
size: paddedArray.byteLength,
usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_SRC
})
const shaderModule = device.createShaderModule({
code: shaderCode
})
const computePipeline = device.createComputePipeline({
layout: 'auto',
compute: {
module: shaderModule,
entryPoint: 'kernel'
}
})
const uniformArray = new Uint32Array(2)
const uniformBuffer = device.createBuffer({
size: uniformArray.byteLength,
usage: GPUBufferUsage.UNIFORM | GPUBufferUsage.COPY_DST
})
// ソートを実行する
for (let i = 0; i < base; i++) {
for (let j = 0; j <= i; j++) {
uniformArray.set([i, j])
device.queue.writeBuffer(uniformBuffer, 0, uniformArray)
const commandEncoder = device.createCommandEncoder()
const passEncoder = commandEncoder.beginComputePass()
passEncoder.setPipeline(computePipeline)
const bindGroup = device.createBindGroup({
layout: computePipeline.getBindGroupLayout(0),
entries: [
{ binding: 0, resource: { buffer: readBuffer } },
{ binding: 1, resource: { buffer: writeBuffer } },
{ binding: 2, resource: { buffer: uniformBuffer } }
]
})
passEncoder.setBindGroup(0, bindGroup)
passEncoder.dispatchWorkgroups(Math.ceil(paddedArray.length / workgroupSize))
passEncoder.end()
device.queue.submit([commandEncoder.finish()])
// バッファーをスワップする
;[readBuffer, writeBuffer] = [writeBuffer, readBuffer]
}
}
// ソート済みのバッファーから値を取り出す
const resultBuffer = device.createBuffer({
size: array.byteLength,
usage: GPUBufferUsage.COPY_DST | GPUBufferUsage.MAP_READ
})
const commandEncoder = device.createCommandEncoder()
commandEncoder.copyBufferToBuffer(readBuffer, 0, resultBuffer, 0, array.byteLength)
device.queue.submit([commandEncoder.finish()])
await resultBuffer.mapAsync(GPUMapMode.READ, 0, array.byteLength)
const resultArray = new Float32Array(resultBuffer.getMappedRange()).slice()
resultBuffer.unmap()
return resultArray
}
使用するWGSLコードは以下のようになります。前述したWebGLのGLSLコードとほぼ同じです。
struct Params {
blockStep: u32,
subBlockStep: u32
}
@group(0) @binding(0) var<storage, read> input: array<f32>;
@group(0) @binding(1) var<storage, read_write> output: array<f32>;
@group(0) @binding(2) var<uniform> params: Params;
@compute @workgroup_size(64, 1, 1)
fn kernel(@builtin(global_invocation_id) gid: vec3<u32>) {
let index = gid.x;
let blockStep = params.blockStep;
let subBlockStep = params.subBlockStep;
let d = 1u << (blockStep - subBlockStep);
var asc = ((index >> blockStep) & 2) == 0;
var targetIndex = 0u;
if (index & d) == 0 {
targetIndex = index | d;
} else {
targetIndex = index & ~d;
asc = !asc;
}
let v0 = input[index];
let v1 = input[targetIndex];
output[index] = select(v0, v1, (v0 > v1) == asc);
}
こんな感じで実行します。
const device = await adapter.requestDevice()
const array = new Float32Array(Array.from({ length: 1024 }, () => Math.random()))
const sortedArray = await bitonicsort(device, array)
TypedArrayのsortメソッドと速度を比べてみましたが、以下のようにバイトニックソートのほうが激遅の結果となりました。
Bitonic sort: 20.0ms,
TypedArray#sort: 0.09999990463256836ms
簡単に調べてみた感じだと、bitonicsortメソッドのforループの後のソート結果をバッファーから取り出すところに特に時間がかかっているようでした。
Discussion