[論文紹介] AdaLoRA
ICLR22のLoRA[1]の後続研究であるAdaLoRA[2](ICLR23にposterで採択)の解説です.
書誌情報です.
Q. Zhang, M. Chen, A. Bukharin, P. He, Y. Cheng, W. Chen, and T. Zhao, "Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning," in ICLR, 2023.
輪講スライドも公開してるので,良ければそちらも参照していただければ.
関連リンク
- ガチプロによる査読であるところのOpen Review
- Paper
- PEFT v0.3.0における実装箇所
SUMMARY
LoRAの派生手法であるAdaLoRAを提案
- 増分行列
\Delta \Delta = P \Lambda Q - LoRAでは固定だったランク
r \Lambda - LoRAなどのベースライン手法を上回るパフォーマンス
- 定性的結果で研究の動機を回収
前提:LoRA
深層学習モデルのfine-tuningにおいて,全てのパラメータを更新する代わりにパラメータの増分のみを最適化することを考えます.
例えばあるLLMが持つある線形層のパラメータ行列
(増分行列:fine-tuningによるパラメータの変化量.c.f., "accumulated gradient update during adaptation")
その際,LoRAではこの増分行列
すると学習可能パラメータの数は

LoRA: eye-catch figure + note
LoRAの嬉しい所をざっくり3つ挙げます.
- 元のモデルにアダプタネットワークとして
\Delta = BA - また,増分行列
\Delta - さらに,複数のタスクに向けて個別にfine-tuningしたモデルを用意したいとき,モデル全体をfine-tuningする場合は事前学習済みモデルと同様の大きさのモデルを複数保管する必要がありましたが,LoRAであればタスクごとに求めた増分行列のみを保持すればよいので,より少ないパラメータを保持しておけば良く,省スペースです.
このLoRAについてはもうだいぶ知っている人が多いと思います.ICLR22の元論文はLLMのパラメータ全てを更新するのはexpensiveなのでもっと効率的にモデルを調整したいというモチベーションからLoRAを提案していますが,条件付き画像生成モデルであるStable DiffusionやControlNetのfine-tuningにおいてもLoRAが利用されるようになっています.
良い資料もあるので,興味がある方は参照してください.
モチベーション:LoRAの問題点
LoRAは各増分行列
以下はある層,あるモジュールのみにLoRAを適用した際のMNLI-mのパフォーマンスの差を示す図です(縦軸注意です).

(a) Apply LoRA to selected weight matrix

(b) Apply LoRA to selected layers
まぁ数回実験したらひっくり返りそうな程度の差ですが,例えば図(b)の1-3層に適用した場合と10-12層に適用した場合を見るとこれはたしかに差はありそうです.
提案:AdaLoRA
AdaLoRAはLoRAでは固定だったランク
(i) 特異値分解に基づく適応
増分行列の分解
さて,LoRAは深層学習モデルのあるパラメータ行列
これに対してAdaLoRAは次のように増分行列
ここで
この式で一番見て欲しいところは勿論末尾の
ただ,これだけでは
この正則化項を係数
(特異値を
また,
特異値ごとに分解した定式化
後の議論のために,
さらに,ネットワーク内の全てのパラメータ行列の内,AdaLoRAを適用するパラメータ行列が
(ii) 重要度によるランクの割り当て
特異値 \lambda_{k,i}
半分終わりました!ここからはランク
ランクを適応的に変化させるために,まずは各triplet
次はこの重要度
結論から言うと次の式で更新を行います.
ここで
つまり,重要度の高い順に
Triplet \mathcal{G}_{k,i} S_{k,i}
第2,3項ではパラメータサイズに左右されないように,
ここで
ここで
簡単におきもちだけ説明します.
バジェット b^{(t)}
最後です.学習を円滑に進めるため,バジェット
具体的には
雰囲気が分かりやすいかもしれないので,一例を図にしましたどうぞ

実験結果
定量的結果
2つだけ紹介します.
以下の表はDeBERTaV3-baseに対してAdaLoRAやベースライン手法を使って学習を行った際のGLUE development setにおける結果です.
この結果はseedを変えて行った5回の実験の平均値であり,p < 0.05と報告されています.

Results with DeBERTaV3-base on GLUE development set.
大体AdaLoRAが勝っていそうです.
もう一つは学習可能パラメータ数を変化させてLoRAとAdaLoRAのパフォーマンスを比較するものです↓(例によって縦軸注意です).

left: MNLI, middle: SQuADv2.0, right: XSum
一貫してAdaLoRAの方が良いパフォーマンスです.
定性的結果
モチベーションの回収を行っているので個人的おもしろポイントです.
以下の図はDeBERTaV3-baseをAdaLoRAによってMNLIでfine-tuningした結果,モジュール,層ごとのランク
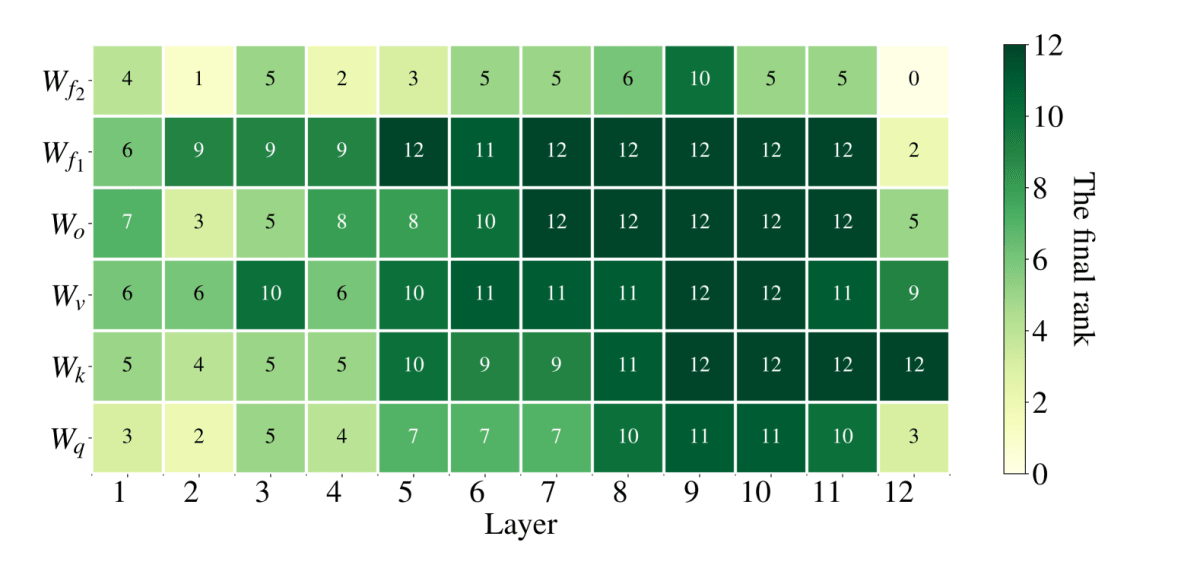
Rank of each incremental matrix when fine-tuning DeBERTaV3-base on MNLI with AdaLoRA
この図を見る限り,大まかに深い層に割り当てられるランクが偏っており,また線形層のパラメータ
ここでモチベーションに戻りますが,
fine-tuningを行う際に,層やモジュールによってパラメータの重要度が異なる
と主張し,実際に特定の層,モジュールのみにLoRAを適用した際のMNLI-mのパフォーマンスの差を示す図
(a) Apply LoRA to selected weight matrix
(b) Apply LoRA to selected layers
を見るとより深い層をtuningした方がパフォーマンスが良く,同様に線形層のパラメータをtuningした方がパフォーマンスが良いことが分かります.
→完全にとは言いませんが,最初の検証実験の結果にある程度沿った定性的結果が得られています.
SUMMARY
LoRAの派生手法であるAdaLoRAを提案
- 増分行列
\Delta \Delta = P \Lambda Q - LoRAでは固定だったランク
r \Lambda - LoRAなどのベースライン手法を上回るパフォーマンス
- 定性的結果で研究の動機を回収
p.s. 既にHuggingFace PEFTに実装されていて動かせるので試してみてはいかがでしょう.例えばAlpaca-LoRAはPEFTを使っていますから,configを軽く書き換えるだけで試せます.
-
E. J. Hu, yelong shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, and W. Chen, "LoRA: Low-Rank Adaptation of Large Language Models," in ICLR, 2022 ↩︎
-
Q. Zhang, M. Chen, A. Bukharin, P. He, Y. Cheng, W. Chen, and T. Zhao, "Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning," in ICLR, 2023. ↩︎
-
Q. Zhang, S. Zuo, C. Liang, A. Bukharin, P. He, W. Chen, and T. Zhao, "Platon: Pruning large transformer models with upper confidence bound of weight importance," in ICML, 2022, pp. 26809–26823. ↩︎
Discussion