🤖
BitNet-b1.58-2B-4T 動いた on Mac
BitNet-b1.58-2B-4T 動作手順
microsoft/BitNet の手順を行ったが、cmake が返って来なかったので、Claude に聞きながら動くまでやってみた。
# リポジトリから取得
git clone --recursive https://github.com/microsoft/BitNet.git
cd BitNet
# 環境作成
conda create -n bitnet-cpp python=3.9
conda activate bitnet-cpp
# パッケージインストール
pip install -r requirements.txt
# モデルダウンロード
huggingface-cli download microsoft/BitNet-b1.58-2B-4T-gguf --local-dir models/BitNet-b1.58-2B-4T
# "DBITNET_ARM_TL1" を "ON" から "OFF" に変更する
# (これを行わないと次のコマンドが返ってこない)
vim setup_env.py
# セットアップ
python setup_env.py -md models/BitNet-b1.58-2B-4T -q i2_s
# prompt
python run_inference.py -m models/BitNet-b1.58-2B-4T/ggml-model-i2_s.gguf -p "You are a helpful assistant" -cnv
公式手順のままだと arm64 アーキテクチャでは TL1 カーネルが使用され、x86_64 では TL2 カーネルが使用されるようだけど、TL1 カーネル が ON だとセットアップが終わらない。
環境
- Mac Book Pro M1 Max (Memory: 64GB)
- macOS 15.3.1
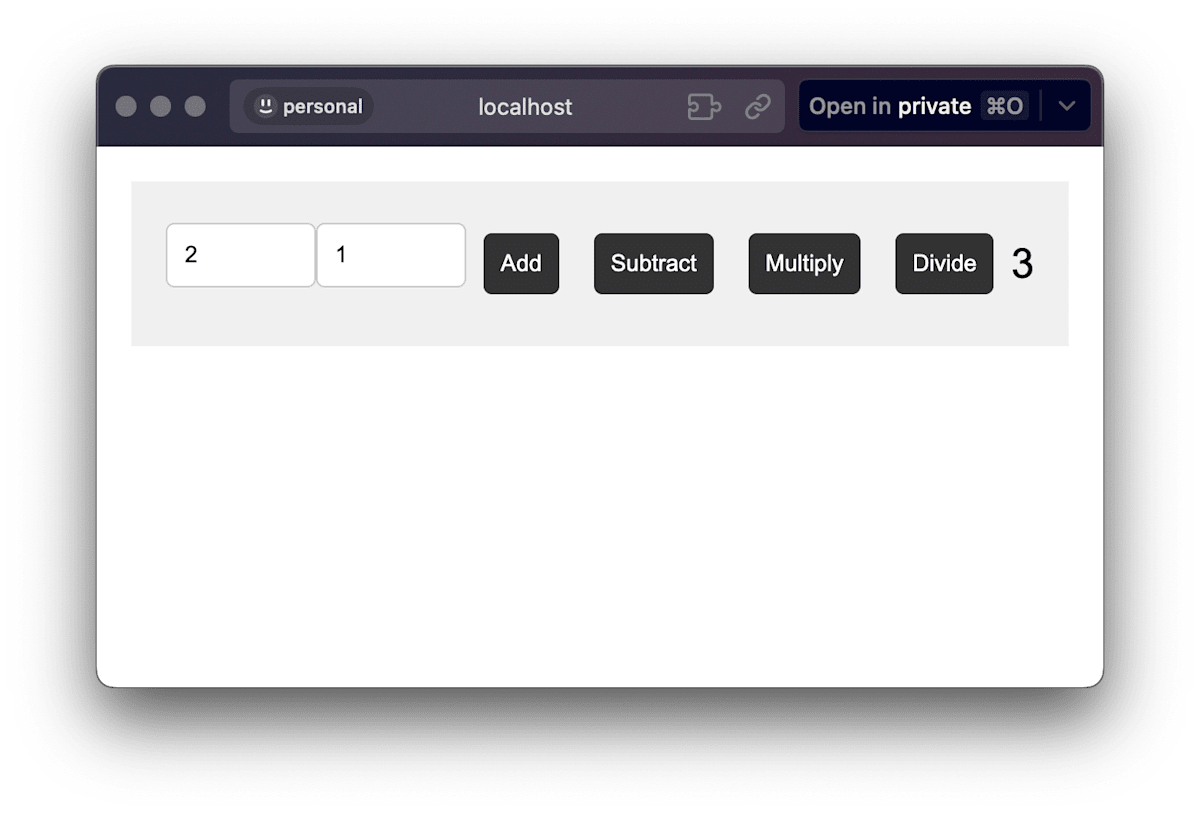
計算機を作ってもらった
python run_inference.py -m models/BitNet-b1.58-2B-4T/ggml-model-i2_s.gguf -p "Create a minimalist calculator in HTML." -t 8 -c 4096 -n 1024 -temp 0.1
<!DOCTYPE html>
<html>
<head>
<title>Calculator</title>
<style>
body {
font-family: Arial, sans-serif;
margin: 20px;
}
.calculator {
display: flex;
justify-content: center;
align-items: center;
font-size: 24px;
padding: 20px;
background-color: #f0f0f0;
}
.calculator input {
width: 100%;
padding: 10px;
margin-bottom: 10px;
border: 1px solid #ccc;
border-radius: 5px;
box-sizing: border-box;
}
.calculator button {
padding: 10px;
margin: 10px;
border: none;
border-radius: 5px;
background-color: #333;
color: white;
cursor: pointer;
}
.calculator button:hover {
background-color: #ddd;
}
.calculator button:active {
background-color: #ddd;
}
</style>
</head>
<body>
<div class="calculator">
<input type="number" id="num1" placeholder="Enter first number">
<input type="number" id="num2" placeholder="Enter second number">
<button onclick="add()">Add</button>
<button onclick="subtract()">Subtract</button>
<button onclick="multiply()">Multiply</button>
<button onclick="divide()">Divide</button>
<div id="result"></div>
</div>
<script>
function add() {
var num1 = parseFloat(document.getElementById('num1').value);
var num2 = parseFloat(document.getElementById('num2').value);
var result = num1 + num2;
document.getElementById('result').innerHTML = result;
}
function subtract() {
var num1 = parseFloat(document.getElementById('num1').value);
var num2 = parseFloat(document.getElementById('num2').value);
var result = num1 - num2;
document.getElementById('result').innerHTML = result;
}
function multiply() {
var num1 = parseFloat(document.getElementById('num1').value);
var num2 = parseFloat(document.getElementById('num2').value);
var result = num1 * num2;
document.getElementById('result').innerHTML = result;
}
function divide() {
var num1 = parseFloat(document.getElementById('num1').value);
var num2 = parseFloat(document.getElementById('num2').value);
if (num2 !== 0) {
var result = num1 / num2;
document.getElementById('result').innerHTML = result;
} else {
document.getElementById('result').innerHTML = 'Error: Division by zero';
}
}
</script>
</body>
</html>
llama_perf_sampler_print: sampling time = 82.78 ms / 1032 runs ( 0.08 ms per token, 12467.38 tokens per second)
llama_perf_context_print: load time = 521.69 ms
llama_perf_context_print: prompt eval time = 292.89 ms / 8 tokens ( 36.61 ms per token, 27.31 tokens per second)
llama_perf_context_print: eval time = 29596.32 ms / 1023 runs ( 28.93 ms per token, 34.57 tokens per second)
llama_perf_context_print: total time = 30040.13 ms / 1031 tokens
ggml_metal_free: deallocating
計算できる! UI デザインしてる!
サーバーを作ってもらった
python run_inference.py -m models/BitNet-b1.58-2B-4T/ggml-model-i2_s.gguf -p "Create The Echo Server with Node.js" -t 8 -c 1024 -n 512 -temp 0.8
const express = require('express');
const app = express();
const port = 3000;
app.use(express.json());
app.get('/', (req, res) => {
res.send('Hello World');
});
app.get('/echo', (req, res) => {
const message = req.query.message;
if (message === '') {
res.send('This message is empty');
} else {
res.send(message);
}
});
app.listen(port, () => {
console.log(`Server is running on http://localhost:${port}`);
});
llama_perf_sampler_print: sampling time = 35.87 ms / 521 runs ( 0.07 ms per token, 14526.70 tokens per second)
llama_perf_context_print: load time = 525.84 ms
llama_perf_context_print: prompt eval time = 339.55 ms / 9 tokens ( 37.73 ms per token, 26.51 tokens per second)
llama_perf_context_print: eval time = 12836.04 ms / 511 runs ( 25.12 ms per token, 39.81 tokens per second)
llama_perf_context_print: total time = 13248.82 ms / 520 tokens
返ってきた!
❯ curl "http://localhost:3000/echo?message=hoge"
hoge
独白
そうです、最初から 2B の LLM にプログラミングさせるなど愚かな行為でした。何度も何度も生成を繰り返し、混沌の中から動くアプリケーションが生まれました。私が作り出したもののほとんどは、ただのガラクタ、デジタルのゴミに過ぎなかったのです。
Discussion