WebサイトをRAGアプリに変換するリポジトリを24時間で作成して公開した話
TL; DR
- OllamaのローカルLLMで動く、完全ローカルRAGアプリをパブリックに公開。
- パブリックリポジトリで、誰でもclone, fork, PRできます。
- 技術的には以下の特徴
A. Ollamaモデル: (生成モデル:gpt-oss:20b, 埋め込みモデル:mxbai-embed-large)
B. AI駆動開発 / AI開発ツール: (Claude 4 Sonnet,Claude 4.1 Opus,Gemini 2.5 Pro,Cline,Kilo Code,Gemini CLI,Jules,Amazon Q Developer,Claude Code,MCP Server,Willow Voice...)
C. ベクトルデータベース: (Milvus), 生成AIフレームワーク: (LangGraph), APIサーバFastAPI...
D. TypeScript: (React,Vite)
できあがったもの
| 初期画面 |
|---|
 |
| チャット画面 |
|---|
 |
| 全画面モード |
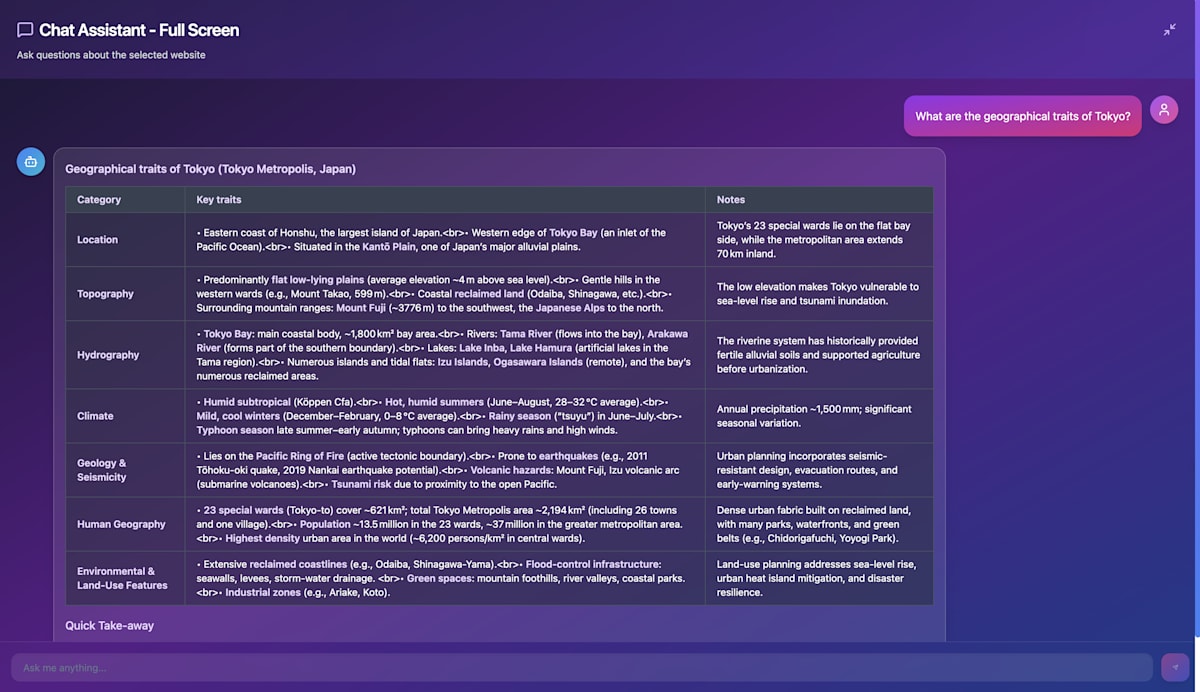 |
リポジトリ公開の背景・価値
1. 製品やオープンプロジェクトのWebサイトを読む時間の節約するため
AIエンジニアは忙しい
- AIエンジニアは人数が少なく、需要も多い。そのため、効率的に働く必要がある。
- その反面、日々AI製品や概念実証プロジェクトは増えており、これらを人間が1から理解するための十分な時間はもはやない。
- → 少ない人数でより多くのプロダクトや技術を理解し、実装やリリースに結びつけるには、非常に効率的な情報検索が必要。
WebのAI化が進んでいない
- サイトによってはAIチャットインターフェイスを提供していることもあるが、不十分なものや、未提供のサイトも多いため、短時間で簡単にWebサイトのAIチャットアプリ化を可能にするアプリがあると便利。
- ブラウザのAI化なども進められているが、現実としては、任意のWebサイトをAIチャットで十分に検索できるかというと...(あることにはあるが、それだけに$10sも払いたくない方が多いでしょう)
- → 無料(安価)でWebサイトをAIで検索できる小規模なシステムがローカルにあると、簡便にWebをAI化でき、必要な情報をアドホックに検索できたり、理解形成のスピードが早まる。
2. 開発した成果物を公開し、AI開発者コミュニティの開発スピードを上げるため
日本のAI開発者コミュニティをよりオープンにしたい
- AI開発者の記事などでは、開発方法や課題を書き連ねているが、実際にどうなのか?という第三者による検証や改善へとつながるほどの公開があるケースは少ない(気がする)。
- 背景には、Qiitaブログとはいえ、実際にはプレセンス向上目的やソリューションの広告活動など、企業活動の一環として行ったりしているケースも多いため、成果物の公開に踏み切る(?)のに二の足を踏むこともあるのかもしれない。
- → とはいえ、今まさにグローバルなAI開発(競争)で起こっているように、人間やAIが開発したものの上に、さらに人間やAIが開発を重ねることで、加速度的に開発を進めるというAIエンジニアのスタンダードな認識を広めるべき(?)だと認識。
3. グローバルな技術スタックを一通り知ることができるリポジトリの必要性
AIエンジニアを育成する必要がある
- AIエンジニア(将来の開発者)の育成にあたり、手を動かしつつ、実践的な経験を積んで、幅広い技術スタックに関心を広げるための機会が必要。
- ここ3年程度のAI技術発展にキャッチアップしていない人向けに、とりあえずどんな技術が出ていたのかを見せるためにも、"論"だけではなく、"証拠"を与える必要がある。(特に後輩育成で。)
- 特に、AI技術は急激に成長している領域なため、エンタープライズであろうと、スタートアップであろうと、とにかく継続的な人材育成に貪欲(なはず)。その基盤として、個人的に技術を試して、よければ製品や社内システムに取り込むという開発者個人の経験知がより重要になっていると思う。
- 一例として、
Milvusは、エンタープライズレベルでのVectorDBとして優秀だが、あまり日本では知られていない印象。ChromaDBでも、Qdrantでもよく、VectorDBで宗教戦争はしたくないですが、よい製品を数多く経験するのは、SEやクラウドエンジニアであろうと、AIエンジニアであろうといいことでしょう。
- 一例として、
成果物
成果物の概要
今回開発したのは、「どんなWebサイトでも、そのURLを入力するだけで対話型のAIチャットボットに変身させられるRAGアプリケーション」です。
使い方は非常にシンプルです。
- URLを入力: 知りたい情報が載っているWebサイトのURLを入力し、「Add URL」ボタンを押します。バックグラウンドでサイトのコンテンツがスクレイピングされ、ベクトル化されてデータベースに保存されます。
- コンテキストを選択: 取り込んだWebサイトがドロップダウンリストに表示されるので、質問したいサイトを選択します。
- チャットで質問: あとはチャットで自由に質問するだけ。選択したWebサイトの内容に基づいて、LLMが回答を生成してくれます。
システムアーキテクチャ
このアプリケーションは、フロントエンド、バックエンド、データベース、そしてLLM実行環境が連携して動作します。全体像をMermaid記法で示すと以下のようになります。
ポイント:
- コンテナ化: フロントエンド、バックエンド、Milvusは
docker composeによってコンテナとして起動します。これにより、環境構築が容易になります。 - Ollamaの配置: Ollamaはホストマシン上で直接実行します。これは、Dockerコンテナのメモリ制限を回避し、GPUリソースを最大限に活用するためです。バックエンドコンテナからは、host.docker.internalを通じてホストマシンのOllama APIにアクセスします。
データ処理フロー
このアプリケーションの主要な機能は「Webサイトの取り込み(Ingestion)」と「質問応答(Querying)」の2つです。それぞれのデータフローを解説します。
1. 取り込みフロー (Ingestion Flow)
ユーザーがURLを入力してから、チャットで利用可能になるまでの流れです。
- URL入力: ユーザーがフロントエンドでURLを入力し、「Add URL」ボタンをクリックします。
-
APIリクエスト: フロントエンドからバックエンドの
/api/v1/scrapeエンドポイントにPOSTリクエストが送信されます。 -
スクレイピング:
scraping_serviceがBeautifulSoupを使い、指定されたURLのHTMLからテキストコンテンツを抽出します。 - テキスト分割: 抽出した長文テキストを、意味のある塊(チャンク)に分割します。これにより、LLMが扱いやすいサイズになります。
-
ベクトル化:
llm_serviceが、分割された各チャンクをOllamaの埋め込みモデル(mxbai-embed-large)に渡し、テキストをベクトル(数値の配列)に変換します。 -
DB保存:
vector_db_serviceが、元のテキストチャンクと生成されたベクトルをペアにして、Milvusに保存します。このとき、URLをパーティションキーとして指定します。 - 応答: 保存が完了したら、バックエンドは成功ステータスをフロントエンドに返します。
2. 質問応答フロー (Querying Flow)
ユーザーが質問を入力してから、回答がストリーミング表示されるまでの流れです。ここがLangGraphの腕の見せ所です。
-
メッセージ送信: ユーザーがチャット入力欄に質問を書き込み、送信します。
-
APIリクエスト: フロントエンドからバックエンドの
/api/v1/chat-streamエンドポイントに、質問内容と選択中のコンテキスト(URL)を含めてリクエストします。 -
クエリルーティング (LangGraph):
langgraph_serviceがリクエストを受け取ります。最初のノードroute_queryがLLMに「この質問はWebサイトの知識が必要か、それとも挨拶のような一般的な会話か?」を問いかけ、処理ルートを決定します。 -
条件分岐:
-
4a. RAG実行: Webサイトの知識が必要と判断された場合、
perform_ragノードが実行されます。vector_db_serviceを呼び出し、コンテキストURLでパーティションを絞り込んでMilvusから関連性の高いテキストチャンクを検索します。 -
4b. 直接応答: 一般的な会話と判断された場合、
direct_answerノードが実行され、ベクトル検索はスキップされます。
-
-
回答生成: 検索結果(または空の情報)と元の質問をプロンプトに組み込み、Ollamaの生成モデル(
gpt-oss:20b)に渡して回答を生成させます。この処理はストリーミングで行われます。 -
ストリーミング応答: FastAPIの
StreamingResponseを使い、生成されたテキストの断片(トークン)を逐次フロントエンドにServer-Sent Eventsとして送信します。これにより、ユーザーはタイプライターのように表示される回答をリアルタイムで見ることができます。
バックエンドの深掘り (FastAPI & LangGraph)
バックエンドは、責務分離を意識したディレクトリ構成になっています。
-
/api: エンドポイントの定義 (HTTPリクエストの受付) -
/services: ビジネスロジックの核心 (スクレイピング、DB操作、LLM連携) -
/core: 設定管理など
LangGraphによるインテリジェントなエージェント
このアプリの頭脳であるlanggraph_service.pyでは、StateGraphを用いて状態を持つエージェントを構築しています。
# 状態を定義するクラス
class RAGState(TypedDict):
query: str
context_url: str
conversation_history: List[Dict[str, str]]
top_k: int
requires_rag: bool
routing_reasoning: str
answer: str
sources: List[Dict[str, Any]]
method: str
# ...
class IntelligentRAGService:
def __init__(self, ollama_service: OllamaService, milvus_service: MilvusService):
self.ollama = ollama_service
self.milvus = milvus_service
self.workflow = self._create_workflow()
def _create_workflow(self):
"""LangGraphワークフローを作成"""
workflow = StateGraph(RAGState)
# ノードを定義
workflow.add_node("route_query", self._route_query)
workflow.add_node("perform_rag", self._perform_rag)
workflow.add_node("direct_answer", self._direct_answer)
# エッジを定義
workflow.set_entry_point("route_query")
# 条件分岐エッジ
workflow.add_conditional_edges(
"route_query",
self._decide_next_step,
{
"rag": "perform_rag",
"direct": "direct_answer"
}
)
# 終了エッジ
workflow.add_edge("perform_rag", END)
workflow.add_edge("direct_answer", END)
return workflow.compile()
add_conditional_edgesを使うことで、LLMの判断に基づいてグラフの実行パスを動的に変更できるのがLangGraphの強力な点です。これにより、単純なパイプラインではない、より柔軟な処理が可能になります。
ベクトルデータベース(Milvus)
エンタープライズレベルの拡張性がありながら、スタンドアロンでも稼働できます。加えて、FAISSのインデキシングが簡単に使用できるのもMilvusの利点です。
class MilvusService:
def __init__(self, host=MILVUS_HOST, port=MILVUS_PORT):
self.host = host
self.port = port
self.collection = None
try:
logger.info(f"Connecting to Milvus at {self.host}:{self.port}")
connections.connect("default", host=self.host, port=self.port)
logger.info("Successfully connected to Milvus.")
self._initialize_collection()
except Exception as e:
logger.error(f"Failed to connect to Milvus: {e}", exc_info=True)
raise RuntimeError("Could not connect to Milvus. Is it running?") from e
def _initialize_collection(self):
"""Checks if the collection exists and creates it if it doesn't."""
if utility.has_collection(COLLECTION_NAME):
logger.info(f"Collection '{COLLECTION_NAME}' already exists.")
self.collection = Collection(COLLECTION_NAME)
else:
logger.info(f"Collection '{COLLECTION_NAME}' not found. Creating it now.")
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name="url", dtype=DataType.VARCHAR, max_length=2048),
FieldSchema(name="text", dtype=DataType.VARCHAR, max_length=65535),
FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=EMBEDDING_DIM)
]
# A collection can have at most one partition key field.
schema = CollectionSchema(
fields,
description="Collection for partitioned web page content",
partition_key_field="url"
)
self.collection = Collection(COLLECTION_NAME, schema, num_partitions=64) # Pre-allocate partitions
logger.info("Creating index for the embedding field...")
index_params = {
"metric_type": "L2",
"index_type": "IVF_FLAT", # FAISSのインデキシングが様々に選択できます
"params": {"nlist": 128}
}
self.collection.create_index(field_name="embedding", index_params=index_params)
logger.info("Index created successfully.")
self.collection.load()
logger.info(f"Collection '{COLLECTION_NAME}' loaded into memory.")
検索時には、exprパラメータでURLを指定するだけで、対象のパーティションのみを高速に検索できます。
# 検索時に式(expr)でパーティションを絞り込む
search_params = {"metric_type": "L2", "params": {"nprobe": 10}}
results = self.collection.search(
data=[query_embedding],
anns_field="embedding",
param=search_params,
limit=top_k,
expr=f'url == "{context_url}"', # 検索対象を限定
output_fields=["text", "url"]
)
これにより、複数のWebサイトの情報を同じコレクションに格納しても、コンテキストが混ざり合うことなく、テナント分離のような挙動を実現できます。
フロントエンドの工夫 (React & Shadcn/ui)
フロントエンドはVite + React + TypeScriptというモダンな構成です。UIコンポーネントにはshadcn/uiとTailwind CSSを採用し、迅速な開発を実現しました。
Chat.tsxコンポーネントでは、バックエンドからのストリーミングデータをリアルタイムに処理しています。
const handleSendMessage = async (message: string) => {
// ...
const response = await fetch(`${import.meta.env.VITE_API_URL}/chat-stream`, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ query: message, context_url: selectedContext }),
});
const reader = response.body?.getReader();
const decoder = new TextDecoder();
while (true) {
const { done, value } = await reader.read();
if (done) break;
const chunk = decoder.decode(value);
const lines = chunk.split('\n\n');
lines.forEach(line => {
if (line.startsWith('data: ')) {
const data = JSON.parse(line.substring(6));
if (data.type === 'chunk') {
// ストリーミング中のチャンクを既存のメッセージに追加
setMessages(prev => /* ... */);
}
}
});
}
// ...
};
fetch APIとReadableStreamを使い、Server-Sent Events形式で送られてくるデータをデコードし、状態を更新することで、スムーズなストリーミング表示を実現しています。
セットアップと実行方法
このアプリケーションはDockerで簡単に起動できます。
前提条件:
- Docker Desktop
- Ollama (ホストマシンにインストール済みであること)
手順:
-
リポジトリをクローン
git clone https://github.com/beginnersguide138/simple-web-chat.git cd simple-web-chat -
Ollamaで必要なモデルをダウンロード
# 埋め込みモデル(必須) ollama pull mxbai-embed-large # 生成モデル(どちらかを選択、gpt-ossは高品質だがハイスペックマシンが必要) ollama pull gpt-oss:20b # または ollama pull tinyllama -
(オプション)
.envファイルで生成モデルを選択
デフォルトはgpt-oss:20bです。軽量なモデルを使いたい場合は、.envファイルを作成して以下のように記述します。GENERATION_MODEL=tinyllama
メモリに不安がある場合、軽量で日本語性能も一定程度高いモデルを選択するといいでしょう。
Gemma3(gemma3:12bなど)は、その選択肢の一つです。
-
Dockerコンテナを起動
docker-compose up --build -
ブラウザでアクセス
http://localhost:5173 にアクセスしてください。
AI駆動開発/AIツール支援の開発過程
このプロジェクトは、単一のAIツールに頼るのではなく、複数のAIを適材適所で使い分けて開発しました。そのプロセスを紹介します。
1. プロジェクトの始動: 自律エージェント Jules によるブートストラップ
- まず最初に投入したのは、自律型AIエンジニアの
Julesです。GitHubリポジトリを渡すだけで、まるで新しい開発者がチームに加わったかのように、自律的にコードを生成し、ブランチを切って開発を進めてくれます。プロジェクトの初期段階で、基本的な骨格や雛形を短時間で構築してもらう上で非常に強力でした。Julesの能力自体はGemini 2.5 Proベースなので、Claude 4 SonnetをベースとしたGitHub SparkやKiroのようにはおそらく高くないと思いますが、しっかりと要件を伝えれば、(0→1ならぬ)0→0.5くらいのタスクには向いているのではないかと思います。
 |
|---|
| Julesがまっさらなリポジトリに書き込んでいきました |
2. 設計と理論の深化: Gemini 2.5 Pro との対話
- 開発の方向性やアーキテクチャで迷った部分は、
Gemini 2.5 Proとの対話を通じて解決しました。特に、このリポジトリを公開する意義や、技術選定の背景にある理論を深める上で、その長大なコンテキストウィンドウとマルチエージェントのような対話能力が役立ちました。単なるコード生成に留まらない、「なぜこう作るのか?」という問いに対する思考のパートナーでした。
3. 実装のコア: Kilo Code, Cline, Amazon Q Developer と Claude 4 ファミリー そして Gemini 2.5 Pro
- メインのコーディングは
Kilo CodeとClineやAmazon Q Developerというツール上で行いました。いずれもVSCode拡張で利用でき、補助として複数のMCP(Model Context Protocol) を活用したので、AIの自律的な開発過程を適宜監視しつつ、大抵の時間は、他の作業を行うこともできました。CC-MCPというMCPを自作しており、これを活用することで、LLMが長期的なコンテクストを要求するタスクでもループから効率的に抜け出していき、より低コストでプロジェクトを進めることが可能でした。-
ClineやAmazon Q Developerは、Kilo Codeのようにユーザーにも見えるタスクリストを生成しないので、CC-MCPのようなタスク管理ツールは有効でした。また、別の観点で作成したタスク分解プロンプトのMCPも役立ったと見えました。 -
playwrightMCPは、それぞれ、フロントエンドのテストや、バックエンドとの結合テスト、最終的な画面の調整やフロントーバックの接続問題、スタイルの適用問題などに使用できました。(このときにCC-MCPなどの自作MCPも併用することで、ループからすぐに抜けて、非常に効率的にLLMが作業していました。) -
tavily-mcpは、LangGraphの構文などの知識が不足した場合に役立ちました。(普通のWeb検索MCPです。)
-
- モデルには思考の深さに定評のある
Claude 4 SonnetやClaude 4.1 Opusを使い分けました。複雑なロジックの実装や、質の高いコードスニペットの生成において、その能力を遺憾なく発揮してくれました。- とはいえ、現実としては、Claude Max PlanでもAPI上限に達するので、
Kilo Code経由でGemini CLI(Gemini 2.5 Pro)を使用したり、Amazon Q Developer Proを使用していました。
- とはいえ、現実としては、Claude Max PlanでもAPI上限に達するので、
4. 補助ツール群による効率化
-
テストの効率化: 繰り返しのテストケース入力などには、
playwrightMCP やClineデフォルトのbrowser-use機能でLLMに代行させたり、Willow Voiceを使った音声入力を活用し、手作業による負担を軽減しました。
このように、各ツールの特性を理解し、開発フェーズごとに最適なAIを切り替えていくことで、個人開発とは思えないスピード(約24時間以内)と品質を実現することができました。
まとめと今後の展望
この記事では、OllamaとMilvusを活用した完全ローカルRAGアプリケーションのリポジトリを紹介しました。
このプロジェクトを通じて伝えたかったのは、単なる技術の紹介だけではありません。
- 情報収集のあり方を改善していく提案
- オープンな開発文化の重要性
- 実践を重視した学習の提起
- グローバルなAIコミュニティにおける実践の集約・体系化
といった、AI時代のエンジニアにとって重要な思想です。
ぜひ、皆さんもこのリポジトリをクローン、フォークし、スターを付け、そして改善のプルリクエストを送ってみてください。一緒にこのツールを育て、AI開発者コミュニティを盛り上げていきましょう!
最後までお読みいただきありがとうございました!
Discussion