【建築向け】ComfyUIのすゝめ(StableDiffusion)
トピックとしては少々遅れていますが、建築用途で画像生成AIがどのように使えるのか、ComfyUIを使って色々試してみようと思います。
ComfyUIとは
ComfyUIとはStableDiffusionを簡単に使えるようにwebUI上で操作できるようにしたツールの一つです。こういったツールは他に有名なものだと「Stable Diffusion WebUI(AUTOMATIC1111)」がありますが、ComfyUIはノードベースである(ノードを繋いで処理をカスタマイズできる)のが特徴です。

最初は低解像度で生成して、それを引き延ばしながらデノイズして高解像度の画像を生成する、みたいなことができる。
公式のExampleもあるので、こちらを見ると何ができるのかが大体把握できます。
導入方法
ComfyUIは導入方法がいくつかありますが、ここでは誰でも使えるように、ローカルの環境に依存しないGoogle Colabでの導入方法を紹介します。別のインストール方法が知りたい方は公式githubなどを参照してください。
まず、以下のnotebookにアクセスします。
基本、上から3つのセルを順番に実行していくだけでUIは起動できます。
各セルの詳細を以下に記述します。
セットアップ
ComfyUIのリポジトリをgithubからダウンロードし、必要なライブラリをインストールします。
ここで、USE_GOOGLE_DRIVEにチェックを入れておくと、自身のGoogleDriveに保存され、マウントされます。

モデルのダウンロード
必要なモデルをwgetコマンドでダウンロードします。
今回はCivitaiからいい感じのモデルをいくつかダウンロードします。下記のコードを追加してください。(各モデルの詳細は後述)
+ !wget -c "https://civitai.com/api/download/models/138529?type=Model&format=SafeTensor&size=full&fp=fp16" -O ./models/checkpoints/architectureExterior_v60.safetensors
+ !wget -c "https://civitai.com/api/download/models/130072?type=Model&format=SafeTensor&size=pruned&fp=fp16" -O ./models/checkpoints/realisticVisionV51_v51VAE.safetensors
+ !wget -c "https://civitai.com/api/download/models/138529?type=VAE&format=PickleTensor" -O ./models/vae/vae-ft-mse-840000-ema-pruned.ckpt.vae.pt
+ !wget -c "https://civitai.com/api/download/models/72978?type=Model&format=SafeTensor" -O ./models/loras/CWG_archi_sketch_v1.safetensors
ControlNetのScribbleモデルもダウンロードしちゃいましょう。下記のようにコメントアウトを消すだけです。
# ControlNet
...
- #!wget -c https://huggingface.co/comfyanonymous/ControlNet-v1-1_fp16_safetensors/resolve/main/control_v11p_sd15_scribble_fp16.safetensors -P ./models/controlnet/
+ !wget -c https://huggingface.co/comfyanonymous/ControlNet-v1-1_fp16_safetensors/resolve/main/control_v11p_sd15_scribble_fp16.safetensors -P ./models/controlnet/
...
↓こんな感じになっていればok
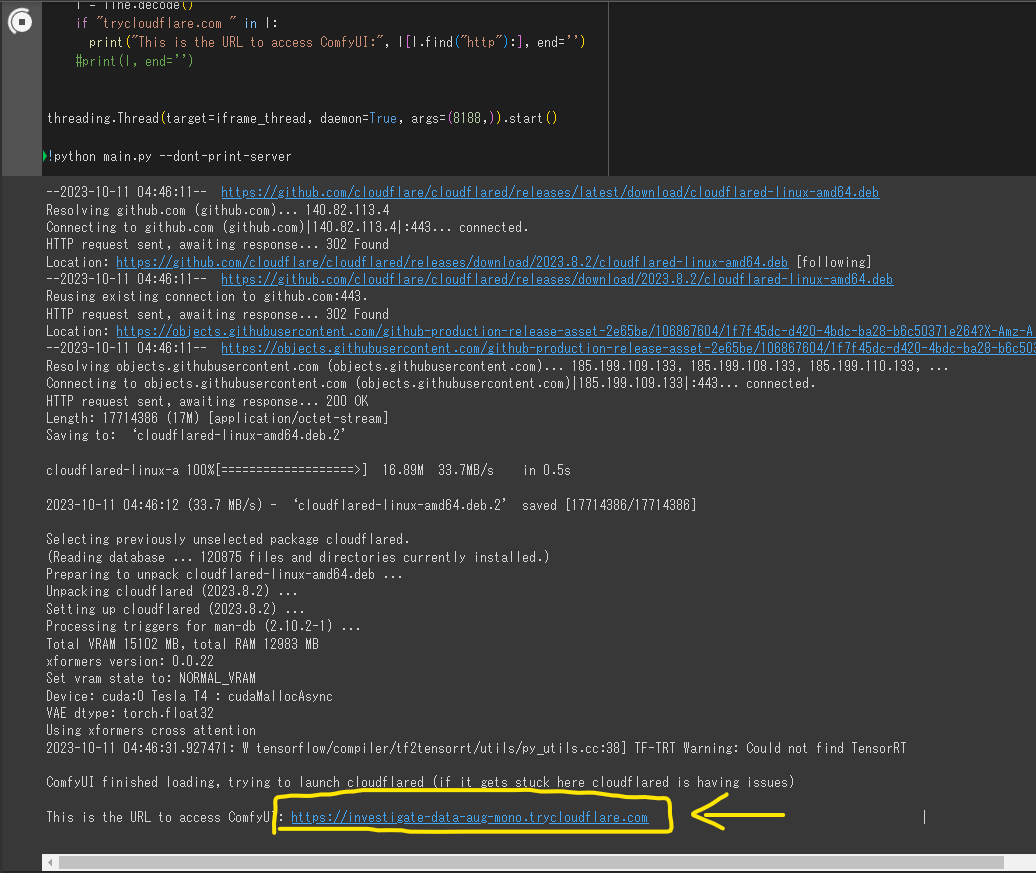
webUIの起動
Run ComfyUI with cloudflared (Recommended Way)と書かれているセルを実行します。
しばらくすると(2~3分くらい?)、コンソールにURLが表示されるので、そこに飛ぶとブラウザ上でUIが起動します。
生成する
右のQueue Promptボタンを押すと処理が走り、生成した画像がSave Imageノードに表示されます。

Save Imageノードに入力された画像はComfyUI/outputの中に自動で保存されます。
ちょっと解説(知りたい人向け)
StableDiffusionについて
ざっくりとStableDiffusionの原理について説明します。ComfyUIでの処理と照らし合わせるとより理解が深まると思います。
StableDiffusionは下図のようなイメージでノイズを除去しながら画像を生成しています。U-Netは事前学習済みのデノイザーみたいなものです。
引用元:https://qiita.com/omiita/items/ecf8d60466c50ae8295b
本来は画像そのものではなくて、VAE Encoderによってエンコードされた「潜在表現」と呼ばれる情報をU-Netで扱っています(VAEの詳しい概要は解説している記事を参照)。この潜在表現が肝で、これによって初期のDiffusion Modelの欠点であった計算量が大きすぎる問題を解決しています。推論時に生成された潜在表現はVAE Decorderによってデコードし、画像に復元します。こういったモデルをLatent Diffusion Modelと呼んだりします。
プロンプトはText Encoderによってベクトル化され、U-Netに埋め込まれます。これによってテキストに沿ったデノイズが行われます。
全体の流れをざっくりまとめると以下のようになります。ComfyUIでのノードの繋ぎ方とほとんど同じですね。
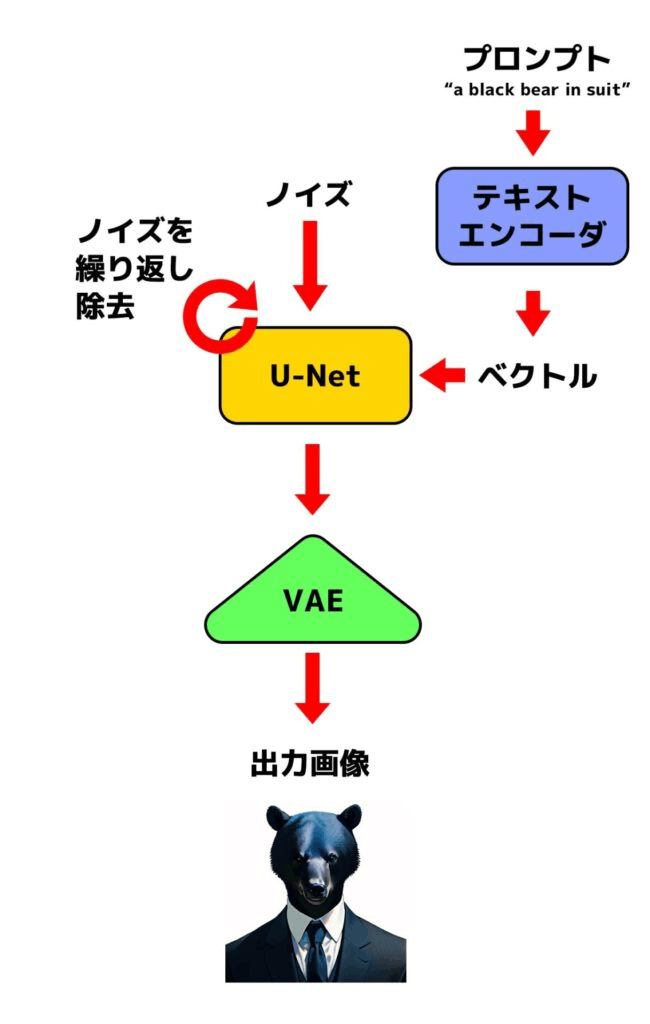
引用元:https://kurokumasoft.com/2023/07/31/how-does-stable-diffusion-work/
KSamplerノードについて
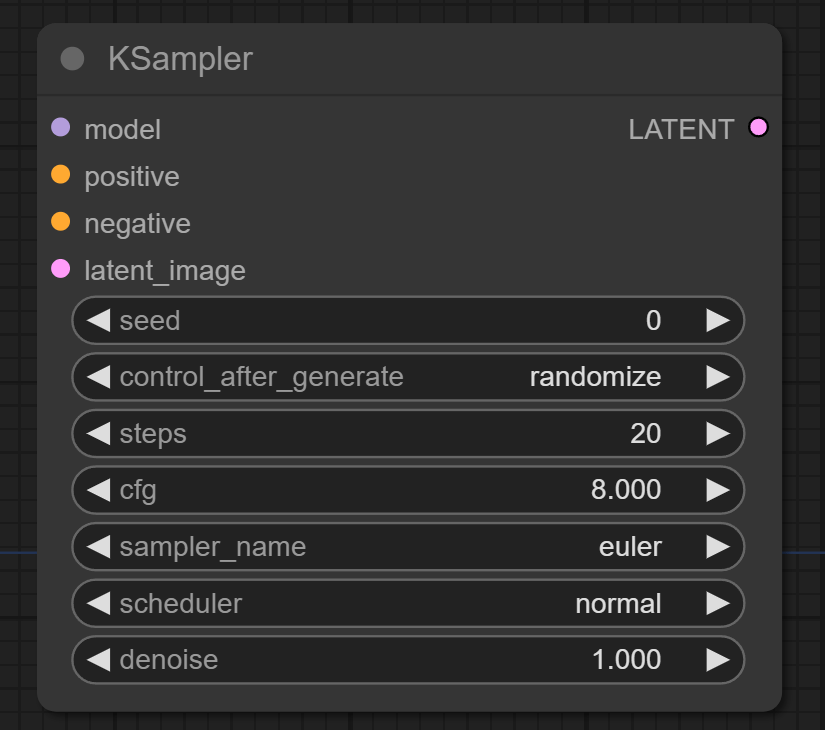
ComfyUIでは画像生成するときに必ずこのKSamplerノードを使うことになるのですが、このノードは上記でいうU-Netの役割を担っています。各パラメータの役割は以下の通りになっています。
-
seed:
ノイズのシード値。 -
control_after_generate:
次のシード値どうするかを決定する。 -
steps:
ノイズを除去するステップ数。 -
cfg:
CFG scale を指定する。 値を大きくすると、よりプロンプトが効くようになるが、大きすぎると破綻する。6~13辺りが適切? -
sampler_name:
使用するサンプラーを指定する。 サンプラーは、U-Net による推定ノイズをもとにノイズを除去する。迷ったらdpmpp_2m_sde辺りを使っておけばok。 -
scheduler:
使用するスケジューラを指定する。 スケジューラは、各ステップでどのくらいのノイズを除去するかを決定する。多くの場合、normal、karras、exponential のどれかを使う。 -
denoise:
デノイズする割合。1.0にすると入力画像を全部デノイズする。0.0にするとまったくデノイズしない。
実践
具体的なケースとして、以下のような高架下を敷地として想定します。建築系で特に有効的だと思われるControlNet、LoRA、Inpaintingを使ってあれこれしてみます。

元画像(2:1)
今回使用するワークフローは下記のリポジトリに置いてあります。
ControlNet
ControlNetは、StableDiffusionの拡張機能で、生成される画像の構図や人物のポーズなどを細かく制御することができます。ControlNetの中にも様々な種類があるのですが、ここではScribleモデルを使用します。Scribbleは線画を基に画像を生成するモデルで、比較的ラフな線画を対象としています。
また、生成のベースとなるモデルとして"architecture_Exterior_SDlife_Chiasedamme_V6.0"を使用します。

生成例
手順
まず、用意したワークフローをComfyUI上で開いて、下図のようにLoad Imageノードに画像をセットします。これでQueue Promptボタンを押せば生成が走ると思います。

一応ざっくりと各ノードの役割について以下に記述しておきます。
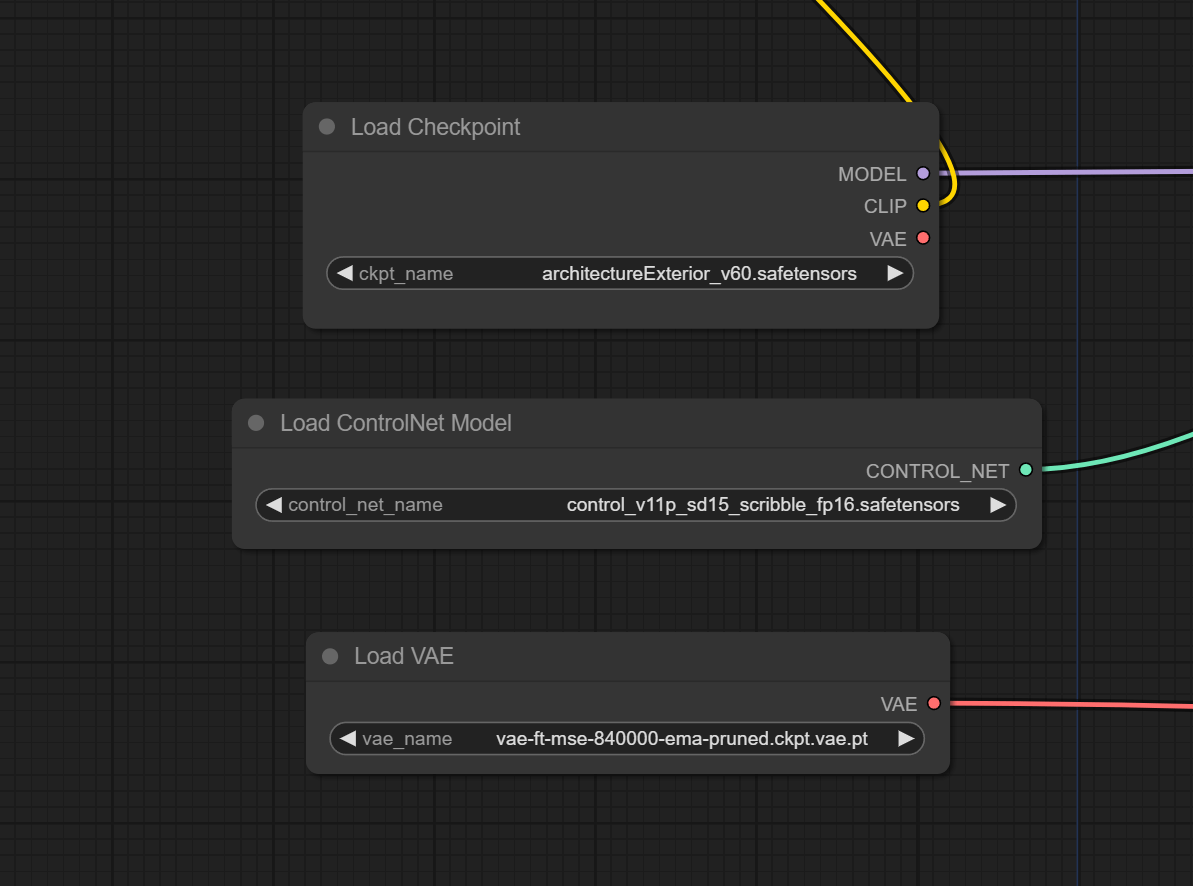
モデルをロードしています。実行時にここでエラーが出た場合は、指定したモデルがComfyUI/modelsにちゃんと保存されているか確認してください。

プロンプトをエンコードし、ControlNetを適用します。positiveは生成したい内容を、negativeは生成したくない内容を入力します。

CLipSkipの設定をします。今回使用したモデルのサンプルではskipを2でやっていたので-2を指定しています。ClipSkipについての詳細はここやここを参照

基となる画像をロードし、CannyノードでControlNet用の線画を抽出しています。Preview Imageノードで保存せずに結果を確認できます。
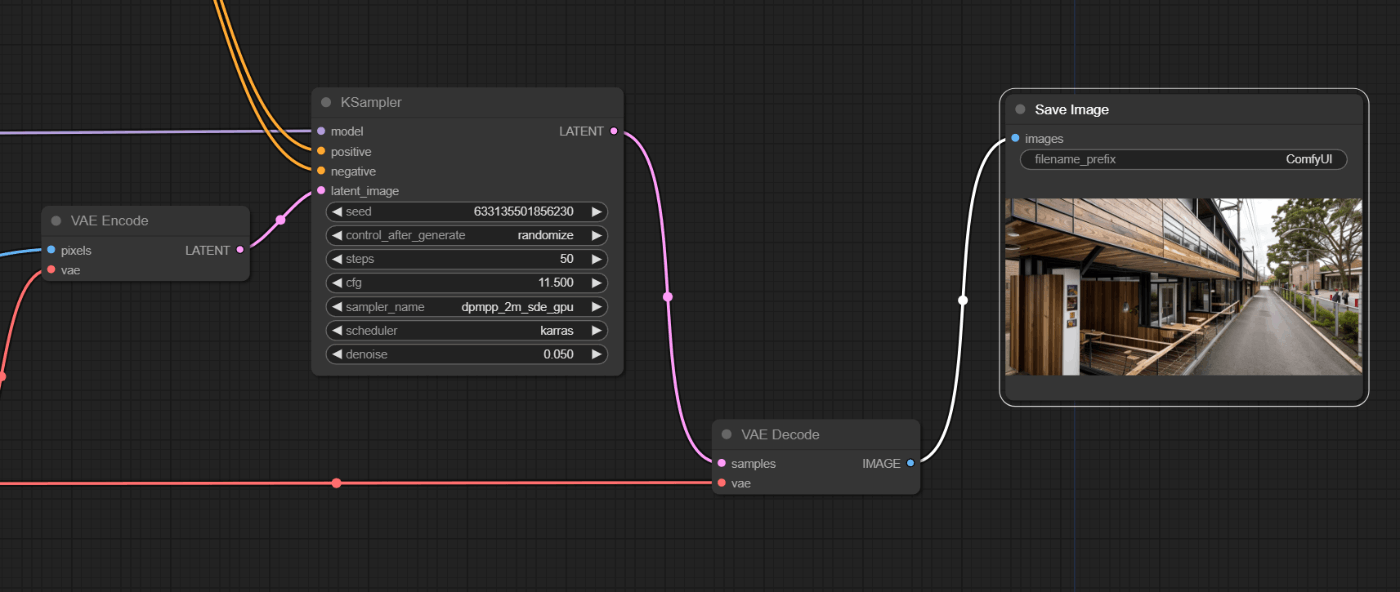
画像を生成します。基となる画像はVAE Encodeで潜在表現にして入力します。生成で出力されるのも潜在表現なので、VAE Decodeで画像に復元します。
ControlNet + LoRA
LoRAとは追加学習手法の名称です。StableDiffusionにおけるLoRAでは出力される画像の雰囲気だったり質感を学習した画像のものに寄せることができます。ここではLoRAによってスケッチ風の建築外観パースで追加学習されたモデル”CWG_archi_sketch_v1”を使用します。

生成例
手順
ほぼ前回と同じです。LoRA用に用意したワークフローを開いて、元画像をセット→生成するという感じです。
新たに追加されているノードはLoad LoRAノードだけです。あと、ここら辺は好みによるとは思いますが、ベースのモデルを"Realistic Vision V5.1"に変えています(サンプルがこっちを使っていたので)。

学習済みのLoRAモデルをロードします。ノードで繋げてみるとLoRAがモデルに直接適用されるものであるのがよくわかります。
ControlNet + LoRA + Inpainting
Inpaintingは元画像上のマスクした部分だけを生成する手法です。ControlNetやLoRAと組み合わせることによって実写にCGを合成したような画像を作ることができます。

生成例1

生成例2(マスクの範囲を広げた)

生成例3(LoRAなし)
手順
前の例に倣って、ワークフローを開き、画像をセットします。
画像をセットしたらLoad Imageノードを右クリックし、Open in MaskEditorでエディタを開きます(Google Colabだと少し時間かかるかも)。
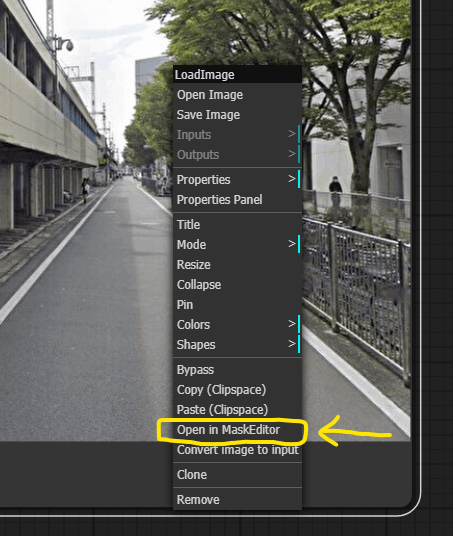
生成したい箇所だけを塗りつぶします。エディタを閉じたらこんな感じ↓になっていると思います。あとは処理を走らせて生成できてればok。

前回との差分はVAE Encode → VAE Encode(for Inpainting)だけです。お手軽ですね。

Maskを考慮して画像をVAE Encodeしています。
感想
ComfyUI、とても良いです。これはノードベースUI全般に言えることかと思いますが、特に以下の点がいいなと思いました。
- 機能を直列に繋いで組み合わせたり、並列に並べて比較したりできる
- 他者が作ったワークフローを再現、そこからアレンジができる
- 各機能の入力と出力が明示してあるので、技術の理解につながる
- 機能拡張する際は新しいノードを実装するだけ
また、開発され始めてからまだ一年もたっていない(?)のに既に多くの拡張機能やカスタムノードが開発されていて、コミュニティの勢いを感じます。
建築系の用途に関しては、構想の段階で目指したい雰囲気の方向性を探ったり、アイデアに煮詰まったときにとりあえず回してみる、みたいな使い方ができそうだなと思いました(素人目線)。
参考文献
StableDiffusion
ComfyUI
建築
Discussion