仮想通貨自動売買botで学ぶMLOps
はじめに
数年前、richmanbtcさんの本を読んでMLを用いた仮想通貨自動売買botを作ってみました。バックテストできれいな右肩上がりの結果が得られて「これでFIREだー!!」と思って実運用してみたものの、全く利益が得られず。。。よくよくコードを見てみると特徴量にリークがあった、ということを何度も経験しました。bot開発では「分析→バックテスト→実運用・ログ収集→分析」のループが重要です。しかし、bot開発を始めた当初はそのような仕組みを用意していなかったどころか、どのようにすれば効率よく「分析・開発⇔運用」を回せるかの知見が全くありませんでした。そのため、損失がでたあとの分析がだんだん億劫になり、開発をやめてしまいました。その後、仕事でシステム開発を行うようになり、DevOps関連の知識・技術が少しついてきたので、改めて0からbot開発を行いました。
リポジトリ
留意事項
- 本記事ではシステム構築をメインテーマとしています。モデルの性能向上などについて知りたい方はブラウザバックしてください。
- 本記事は、自動売買システム構築に関する知識や情報を提供することを目的としており、特定の投資行動を推奨するものではありません。
- 本記事の内容に基づく投資行動に対して、筆者は一切の責任を負いません。
- 筆者はMLを専門としていません。(普段の業務では使用しておりません。)本記事に誤り等あればコメントお願いします。
- 記事内のコードは一部を抜粋したものなので、全体を知りたい場合はリポジトリをご確認ください。
MLOpsとは
MLOpsとは「DevOps for ML」で、「MLを用いたシステム・プロジェクトの開発・運用を効率よく進めるための文化や仕組み」のことです。
- 実験基盤
- 学習パイプライン
- 推論サービス
- バージョン管理
- CI/CD
- 継続的学習
- 監視
等の要素から成ります。
以下の書籍、資料が非常にわかりやすかったです。
機械学習システムデザインパターン
サイバーエージェントのMLOpsの資料
本記事では、MLflowを使用して実験管理、モデル管理を行う仮想通貨自動売買botの実装例を紹介します。
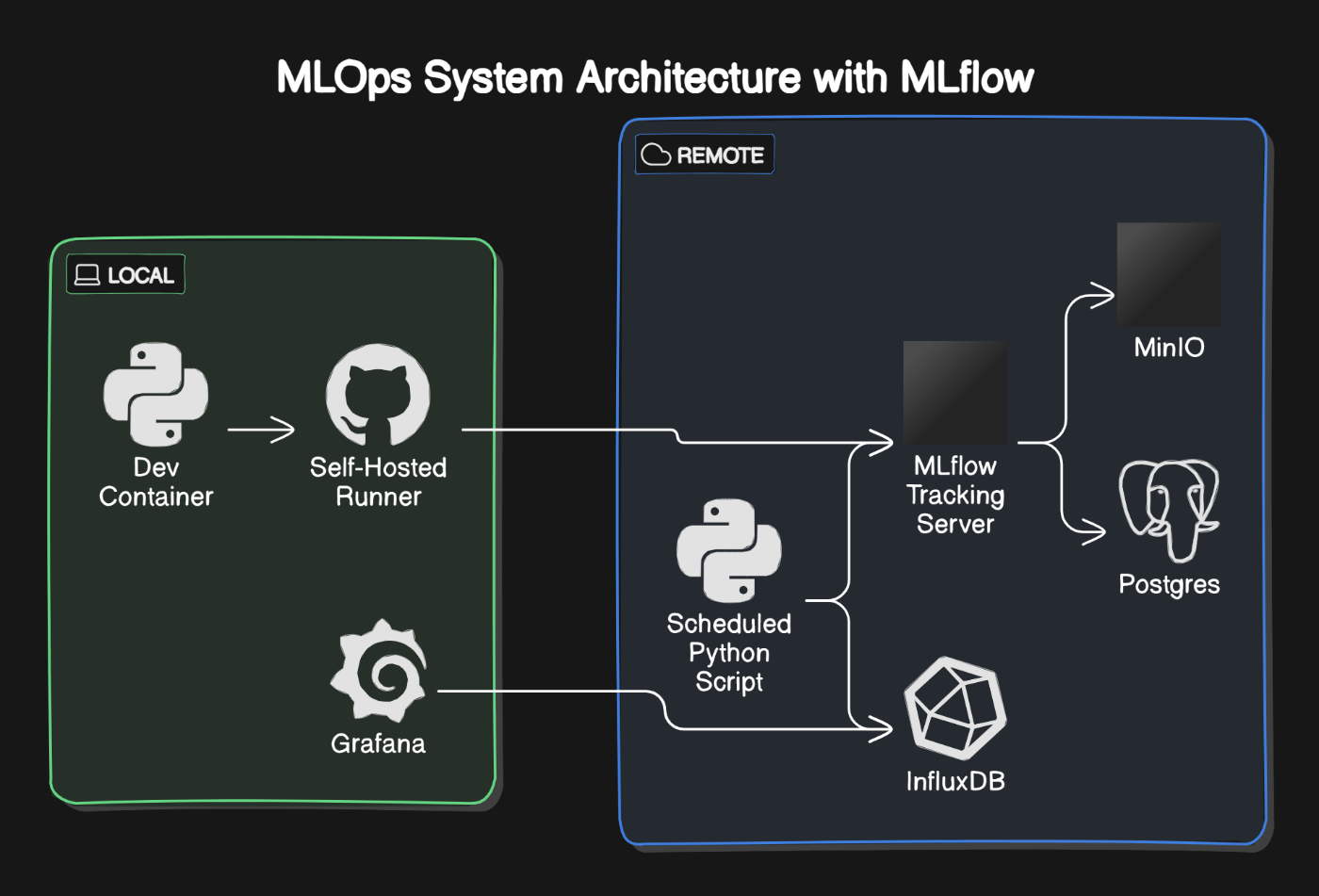
システムの全体像
以下の言語、フレームワーク、OSS…を使用します
- Python
- Git, GitHub, GitHub Actions
- Docker, Docker Compomse, Dev Container
- MLflow
- PostgreSQL
- InfluxDB
- MinIO
- Grafana
ディレクトリ構成
.
├── README.md
├── docker
│ ├── bot
│ │ ├── Dockerfile // bot本体用
│ │ ├── cron15m.sh
│ │ ├── cron1m.sh
│ │ ├── cron5m.sh
│ │ ├── entrypoint.sh
│ │ └── requirements.txt
│ ├── dind
│ │ └── Dockerfile// runner用
│ ├── docker-compose-bot.yml
│ ├── docker-compose-dev.yml
│ ├── docker-compose-mlflow.yml
│ ├── docker-compose.yml
│ ├── mlflow
│ │ └── Dockerfile
│ ├── nginx
│ │ ├── certs
│ │ ├── conf.d
│ │ │ └── proxy.conf
│ │ └── htpasswd
│ └── py_dev
│ ├── Dockerfile
│ └── requirements.txt
├── migration-prepare.py
├── mypy.ini
├── src
│ ├── MLproject
│ ├── backtest
│ │ └── vector // バックテスト実行用
│ │ └── vector_backtester.py
│ ├── bot
│ │ ├── recorder // 定期実行でヒストリカルデータを収集する用
│ │ │ ├── lsr_recorder.py
│ │ │ ├── oi_recorder.py
│ │ │ ├── recorder.py
│ │ │ ├── recorder.sh
│ │ │ ├── save_log.py
│ │ │ └── wallet_balance_recorder.py
│ │ └── trader // 定期実行で取引を行う用
│ │ ├── trader.py
│ │ └── trader.yml
│ ├── build_model // パイプライン-ビルド用
│ │ ├── MLproject
│ │ └── build.py
│ ├── common // 共通モジュール
│ │ ├── git_utils.py
│ │ ├── imported_modules.py
│ │ ├── influxdb_utils.py
│ │ ├── optimize_utils.py
│ │ ├── postgres_utils.py
│ │ ├── preprocess_utils.py
│ │ └── wallet.py
│ ├── config.py // 設定用
│ ├── entity // entity
│ │ ├── backtest_params.py
│ │ ├── optimize_params.py
│ │ └── s3.py
│ ├── evaluate // パイプライン-評価用
│ │ ├── MLproject
│ │ └── evaluate.py
│ ├── feature // 特徴量計算用
│ │ └── feature_calculator.py
│ ├── for_test // テストコードで使うモジュール
│ │ └── generate_data.py
│ ├── logic // 取引ロジック
│ │ ├── __init__.py
│ │ └── sample_logic_limit.py
│ ├── main.py // 機械学習パイプラインのメインスクリプト
│ ├── notebook // JupyterNotebook
│ │ └── yyyymmdd.ipynb
│ ├── preprocess // パイプライン-前処理用
│ │ ├── MLproject
│ │ └── preprocess.py
│ ├── python_env.yaml // MLflow Run 実行環境をまとめたもの
│ └── train // パイプライン-学習用
│ ├── MLproject
│ ├── first
│ │ └── train_1st.py
│ └── second
│ └── train_2nd.py
└── test // 単体テスト
├── logic
│ └── logic_io_test.py
└── preprocess
└── preprocess_io_test.py
ざっくりと以下のような流れで開発・運用を進めます
- localのdevcontainer内でjupyter notebookを用いてデータ分析、デバッグ等を行う
- 機械学習パイプラインやbot本体で使用するために
.pyファイルに書き換え - github actionsで単体テスト、機械学習パイプライン実行
- 実験結果はpostgres,minioに保存され、mlflowのUIから確認する
-
trader、recorderの2種のスクリプトをbot用コンテナ内でcronで定期実行する -
traderはmlflowのui操作で選択したモデルを取得、現在価格をこのモデルに入力し、出力に従い売買を行う -
recorderはbtcのヒストリカルデータ、ウォレット残高、売買記録等をinfluxdbに保存する - grafanaでinfluxdbに保存されたデータを可視化する、notebookでの実験に戻る
リモートマシンはWebArena Indigoの4GBのプランを使用しています(安かったので)。
Grafanaとrunnerはローカルでなくていいのですが、botを置いているマシンのリソースが限られているので、一旦ローカルにしています。
ちなみにこの図ですがEraser AIに以下のおまじないで作ってもらいました。
mlflowを使用したmlopsのシステム構成図を書いてください。
ローカルには以下の3つのコンテナがあります。
- pythonのdevcontainer
- github actions の self hosted runner 用のコンテナ (これは docker-in-docker でjobを実行します)
- grafanaのコンテナ
リモートには以下のコンテナがあります
- mlflowのトラッキングサーバー用コンテナ
- mlflowのartifactを保存するminioコンテナ
- mlflowのartifact以外を保存するpostgresコンテナ
- pythonスクリプトを定期実行するコンテナ
- 時系列データを格納するinfluxdbコンテナ
データ分析
後の項目で説明するrecorder.pyでohlcvデータをinfluxdbに保存しています。
import influxdb_client
client = influxdb_client.InfluxDBClient(url=INFLUXDB_URL, token=INFLUXDB_TOKEN, org=ORGANIZATION)
query_api = client.query_api()
query = """from(bucket: "ohlcv")
|> range(start: -1h)
|> filter(fn: (r) =>
r._measurement == "bybit_btcusdt_15m" and
(r._field == "close" or r._field == "open" or r._field == "high" or r._field == "low" or r._field == "volume")
)"""
tables = query_api.query(query=query,org=ORGANIZATION)
このようなコードでohlcvデータを取得し、整形してから分析を行います。(influxdbのbucket名:ohlcv、measurement名:bybit_btcusdt_15m としています。)特徴量計算や売買ロジックの最終的なコードは.pyにして保存します。(.ipynbはバージョン管理しづらいので。)
単体テスト
売買ロジック、前処理等のメソッドのIN-OUTの関係を確認するための単体テストコードを用意します。ロジックや前処理方法を変更したあとにbotが落ちることがよくありますが、ほとんどの場合IN-OUTの関係が変わってしまっているためです。毎回手動でデバッグを行うのは面倒なので、単体テストでその部分に問題がないことを確認します。
これはgithub actionsでpush時に自動で実行するようにします。
unit-test:
runs-on: self-hosted
needs: build-image
steps:
- uses: actions/checkout@v3
- name: Login to GitHub Container Registry
uses: docker/login-action@v2
with:
registry: ghcr.io
username: ${{ github.actor }}
password: ${{ secrets.ACCESS_TOKEN_GITHUB_ACTIONS }}
- name: Set up Docker
run: |
bash ~/actions-runner/_work/mlbot2/mlbot2/.github/workflows/removeContainersAndImages.sh
docker pull ghcr.io/t448/mlbot2:latest
docker run -v /home/runner/actions-runner/_work/mlbot2/mlbot2/:/home/runner/mlbot2 --name unit-test -p 1111:1111 --network host -e AWS_ACCESS_KEY_ID=${{ secrets.AWS_ACCESS_KEY_ID }} -e AWS_SECRET_ACCESS_KEY=${{ secrets.AWS_SECRET_ACCESS_KEY}} -e MLFLOW_S3_ENDPOINT_URL=${{ secrets.MLFLOW_S3_ENDPOINT_URL }} -e MLFLOW_TRACKING_URI=${{ secrets.MLFLOW_TRACKING_URI }} -e PYTHONPATH=/home/runner/mlbot2/src -e POSTGRES_HOST=${{ secrets.POSTGRES_HOST }} -e POSTGRES_DB=${{ secrets.POSTGRES_DB }} -e POSTGRES_USER=${{ secrets.POSTGRES_USER }} -e POSTGRES_PASSWORD=${{ secrets.POSTGRES_PASSWORD }} -e POSTGRES_PORT=${{ secrets.POSTGRES_PORT }} -dt ghcr.io/t448/mlbot2:latest
- name: unit-test
run: |
set -o pipefail
docker exec unit-test /bin/sh ~/mlbot2/.github/workflows/run_unit_test.sh
- name: Pytest coverage comment
uses: MishaKav/pytest-coverage-comment@v1.1.47
with:
pytest-coverage-path: /home/runner/actions-runner/_work/mlbot2/mlbot2/pytest-coverage.txt
junitxml-path: /home/runner/actions-runner/_work/mlbot2/mlbot2/pytest.xml
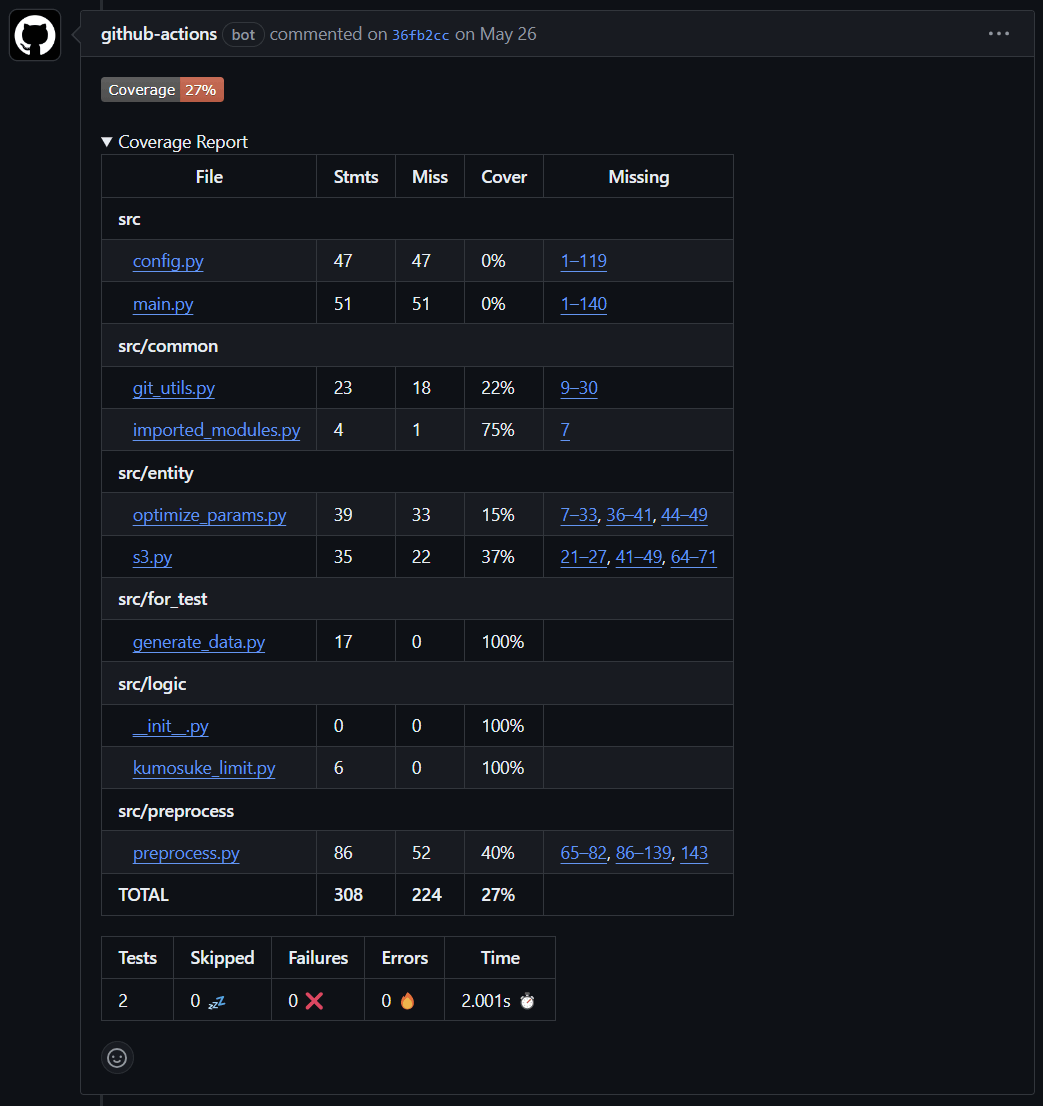
pytest-coverage-comment を使うとPull Request上でカバレッジを確認できるので便利です。
機械学習パイプライン
機械学習パイプラインは
「前処理 → 1次モデル → 2次モデル → ビルド → 評価」の順に行います。MLflowのMLflow Projectsという機能を使います。各ステップごとに処理を記述した.pyファイルとパラメータ等を記載したMLprojectファイル(yaml形式)を用意します。そしてmain.pyでそれらをまとめて実行します。MLflowのUI上ではrunが親子になって表示されます。mlflowにはlog_params,log_metrics,log_artifactsなど値や成果物等を保存するための機能があります。他のステップでも使うような値や成果物系は親runに、それ以外は子runに紐づく形で保存すると、後から見やすいかと思います。これもgithub actionsでpush時に自動で実行します。

関連するファイル
.
├── MLproject
├── build_model
│ ├── MLproject
│ └── build.py
├── evaluate
│ ├── MLproject
│ └── evaluate.py
├── main.py
├── preprocess
│ ├── MLproject
│ └── preprocess.py
├── python_env.yaml
└── train
├── MLproject
├── first
│ └── train_1st.py
└── second
└── train_2nd.py
main.py
main.pyでは実験条件の設定を行い、パイプラインの各ステップを実行するためのコードを記述します。
import argparse
import mlflow
from logging import getLogger, StreamHandler, INFO
from common.postgres_utils import get_last_run_commit_hash
logger = getLogger(__name__)
handler = StreamHandler()
handler.setLevel(INFO)
logger.setLevel(INFO)
logger.addHandler(handler)
logger.propagate = False
def main():
logger.info("start pipeline")
parser = argparse.ArgumentParser()
parser.add_argument("--mlflow_run_id")
args = parser.parse_args()
if args.mlflow_run_id:
with mlflow.start_run(run_id=args.mlflow_run_id):
# 実験条件の設定
backtest_params = {
"backtest_params_jpy": 5000, # 口座残高初期値
"backtest_params_usdjpy": 160, # ドル円
"backtest_params_lot": 0.003, # ポジションの最大サイズ
"backtest_params_lot_min": 0.001, # 最小取引単位
"backtest_params_commision": 0.01, # 手数料
"backtest_params_use_ml": True, # 2次モデルを使う/使わない
"backtest_params_use_binary_label": True, # 2次モデルを2クラス問題とする/多クラス問題とする
"backtest_params_seed": 42, # 乱数シード
}
optimize_params = {
"optimize_params_pyramiding": 3, # 最大ピラミッディング数
"optimize_params_optimize_target": "pnl", # 1次モデル評価指標 pnl:最終的な損益、sr:シャープレシオ、max_dd:最大ドローダウン
"optimize_params_optimize_target_clf": "sr", # 2次モデル評価指標
"optimize_params_n_trials": 200, # 1次モデル optunaでの試行回数
"optimize_params_n_trials_clf": 100, # 2次モデル optunaでの試行回数
"optimize_params_class_weight": "balanced", # "balanced" or "None"
# ↓↓↓↓↓ TimeSeriesSplit用 ↓↓↓↓↓
"optimize_params_n_splits": 5, # 分割数
"optimize_params_max_train_size": None,
"optimize_params_test_size": None,
"optimize_params_gap": 5, # 学習データとテストデータの間何点あけるか
# ↑↑↑↑↑ TimeSeriesSplit用 ↑↑↑↑↑
"optimize_params_evaluate_ratio": 0.25, # evaluate step で使用するデータの割合
}
re_calc_features = False # influxdbからohlcvを取得し、特徴量を再計算するフラグ。再計算には時間がかかる、使用するデータセットを揃えるため、基本的にはFalseにする。
mlflow.log_params(backtest_params)
mlflow.log_params(optimize_params)
mlflow.log_param(key="re_calc_features", value=re_calc_features)
last_run_commit_hash = get_last_run_commit_hash()
mlflow.log_param("last_run_commit_hash", last_run_commit_hash)
logger.info("start preprocess")
preprocess_run = mlflow.run(
uri="./preprocess",
run_name="preprocess",
entry_point="preprocess",
backend="local",
parameters={
"mlflow_run_id": args.mlflow_run_id,
},
)
preprocess_run_id = preprocess_run.run_id
preprocess_run = mlflow.tracking.MlflowClient().get_run(preprocess_run_id)
logger.info("complete preprocess")
logger.info("start train_1st")
train_1st_run = mlflow.run(
uri="./train",
run_name="train_1st",
entry_point="train_1st",
backend="local",
parameters={"mlflow_run_id": args.mlflow_run_id, "preprocess_run_id": preprocess_run_id},
)
train_1st_run_id = train_1st_run.run_id
train_1st_run = mlflow.tracking.MlflowClient().get_run(train_1st_run_id)
logger.info("complete train_1st")
logger.info("start train_2nd")
train_2nd_run = mlflow.run(
uri="./train",
run_name="train_2nd",
entry_point="train_2nd",
backend="local",
parameters={
"mlflow_run_id": args.mlflow_run_id,
"preprocess_run_id": preprocess_run_id,
"train_1st_run_id": train_1st_run_id,
},
)
train_2nd_run_id = train_2nd_run.run_id
train_2nd_run = mlflow.tracking.MlflowClient().get_run(train_2nd_run_id)
logger.info("complete train_2nd")
logger.info("start build")
build_run = mlflow.run(
uri="./build_model",
run_name="build",
entry_point="build",
backend="local",
parameters={
"mlflow_run_id": args.mlflow_run_id,
"preprocess_run_id": preprocess_run_id,
"train_1st_run_id": train_1st_run_id,
"train_2nd_run_id": train_2nd_run_id,
},
)
build_run_id = build_run.run_id
build_run = mlflow.tracking.MlflowClient().get_run(build_run_id)
logger.info("complete build")
logger.info("start evaluate")
evaluate_run = mlflow.run(
uri="./evaluate",
run_name="evaluate",
entry_point="evaluate",
backend="local",
parameters={
"mlflow_run_id": args.mlflow_run_id,
"preprocess_run_id": preprocess_run_id,
"train_1st_run_id": train_1st_run_id,
"train_2nd_run_id": train_2nd_run_id,
"build_run_id": build_run_id,
},
)
evaluate_run_id = evaluate_run.run_id
evaluate_run = mlflow.tracking.MlflowClient().get_run(evaluate_run_id)
logger.info("complete evaluate")
logger.info("complete pipeline")
if __name__ == "__main__":
main()
前処理
非IID特徴量の対数差分をとる、標準化する、などの前処理を行います。前処理の部分は変えずに1次モデル、2次モデルのみを変える、ということがよくあるので、ここで結果を保存しておきます。次回以降同じデータを使用できるようになり、処理をスキップできます。

1次モデル
ファイナンス機械学習にあるように、1次モデル、2次モデルに分けてモデルを用意します。1次モデルではルールベースのモデルを作ります。そして、
- ベクトルバックテスト
- ハイパーパラメータチューニング
- 時系列cv
を行います。
2次モデル
1次モデル同様、ベクトルバックテスト、ハイパーパラメータチューニング、時系列cvをいます。

ハイパーパラメータチューニングの様子はこのように可視化されます。
ビルド
1次モデル、2次モデルを最適化結果を用いて再度学習します。本来はここでモデルを含んだ状態でDockerイメージをビルドすべきですが、今回は前処理や売買ロジックも含めて一つのオブジェクトにし、pklで保存します。15分毎の定期実行にしているので、わざわざ推論サーバを作るほどではないためです。
class LGBMClassifierWrapper(mlflow.pyfunc.PythonModel):
"""
calc_feature, preprocess_func, logic_func は pd.DataFrame のみを引数に取るようにする
Args:
mlflow (_type_): _description_
"""
def __init__(self, logic, calc_feature, preprocess, clf_buy, clf_sell):
self.logic = logic
self.calc_feature = calc_feature
self.preprocess = preprocess
self.clf_buy = clf_buy
self.clf_sell = clf_sell
def predict(
self, df: pd.DataFrame, context=None, params=None
) -> Dict[str, float]:
df_signal = self.logic(df)
df_features = self.calc_feature(df)
df_preprocessed = self.preprocess(df_features)
pred_buy = self.clf_buy.predict(df_preprocessed[self.clf_buy.feature_name_][-1:])
pred_sell = self.clf_sell.predict(df_preprocessed[self.clf_sell.feature_name_][-1:])
buy_limit_price = df_signal["buy"].values[-1] - (1 - pred_buy[-1]) * OFFSET
sell_limit_price = df_signal["sell"].values[-1] + (1 - pred_sell[-1]) * OFFSET
print("buy_limit_price", buy_limit_price)
print("sell_limit_price", sell_limit_price)
return {
"buy_limit_price": buy_limit_price,
"sell_limit_price": sell_limit_price,
}

評価
再度バックテストを行い、結果をmlflow.log_metricsで保存します。

パイプラインのすべてのステップを実行したので、親runの中身を見てみます。最適化で得られたパラメータやバックテストの結果を確認することができます。今回はMLを使うことで性能が下がってしまいました。


定期実行
売買を行うtrader.pyとヒストリカルデータの収集をする*_recorder.pyの2種類があります。どちらもcronで定期実行しています。今回のbotは15分に1回(recorderは速くて1分に1回)の頻度で動かしているので、常時稼働させる必要がないためです。
#!/bin/sh
# 定期実行したい処理
/usr/local/bin/python /home/pyuser/project/src/bot/recorder/recorder.py --interval 15 --measurement_name bybit_btcusdt_15m --limit 10
/usr/local/bin/python /home/pyuser/project/src/bot/recorder/wallet_balance_recorder.py
/usr/local/bin/python /home/pyuser/project/src/bot/trader/trader.py
シェルスクリプトで定期実行したい処理をまとめて記述します。そして以下のようにcronの設定をします。上の2行は自分の環境ではpathを通すために必要でした。
PYTHONPATH=/home/pyuser/project/src
PATH=/usr/local/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
*/15 * * * * sh /root/script/cron15m.sh
*/5 * * * * sh /root/script/cron5m.sh
*/1 * * * * sh /root/script/cron1m.sh
trader
trader内では以下のようなフローで処理を行います。
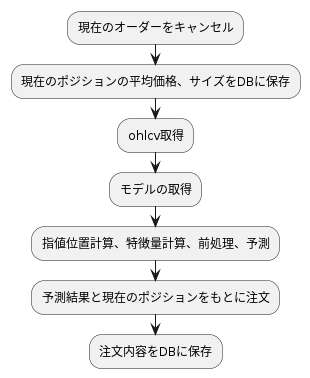
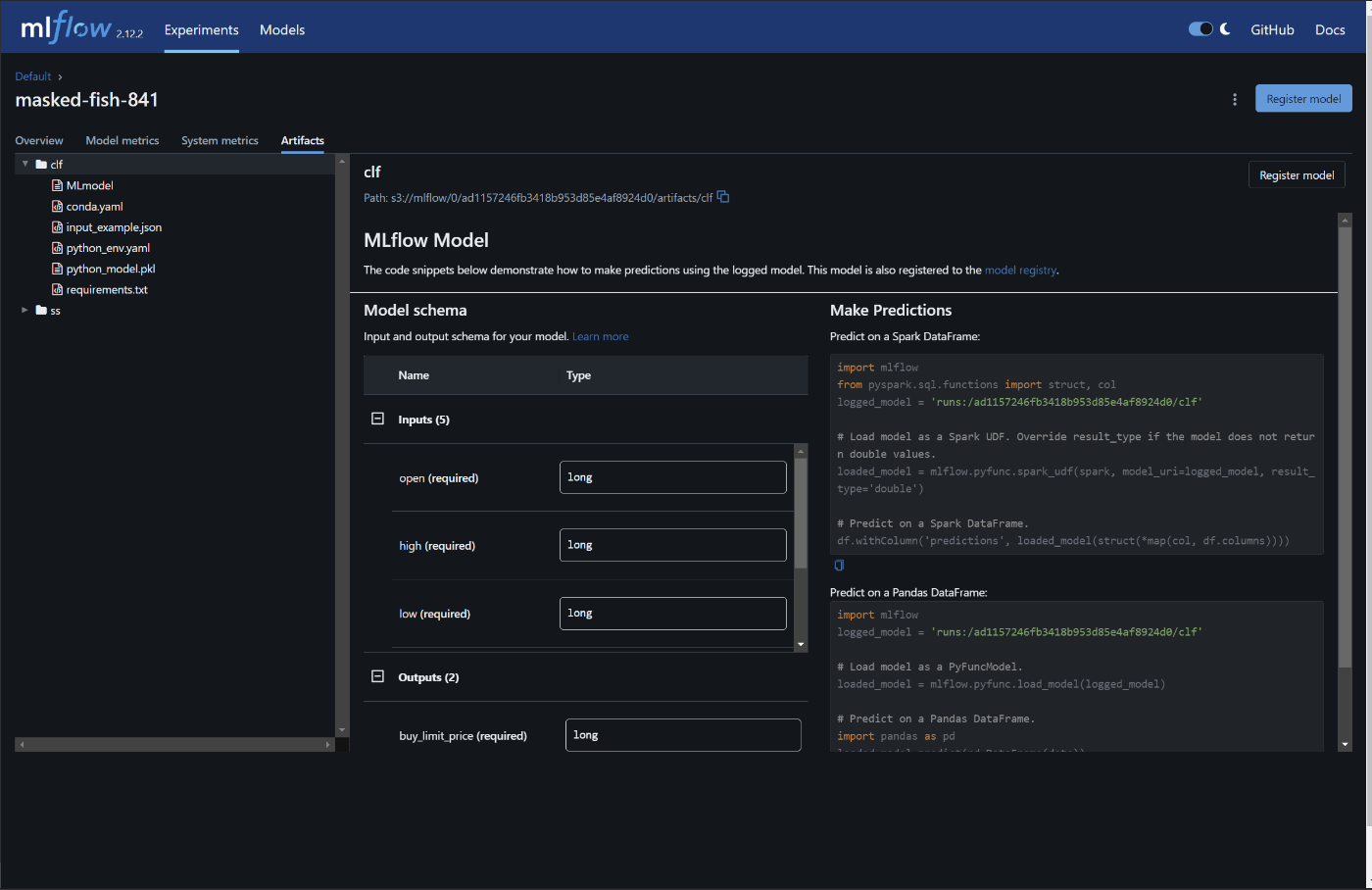
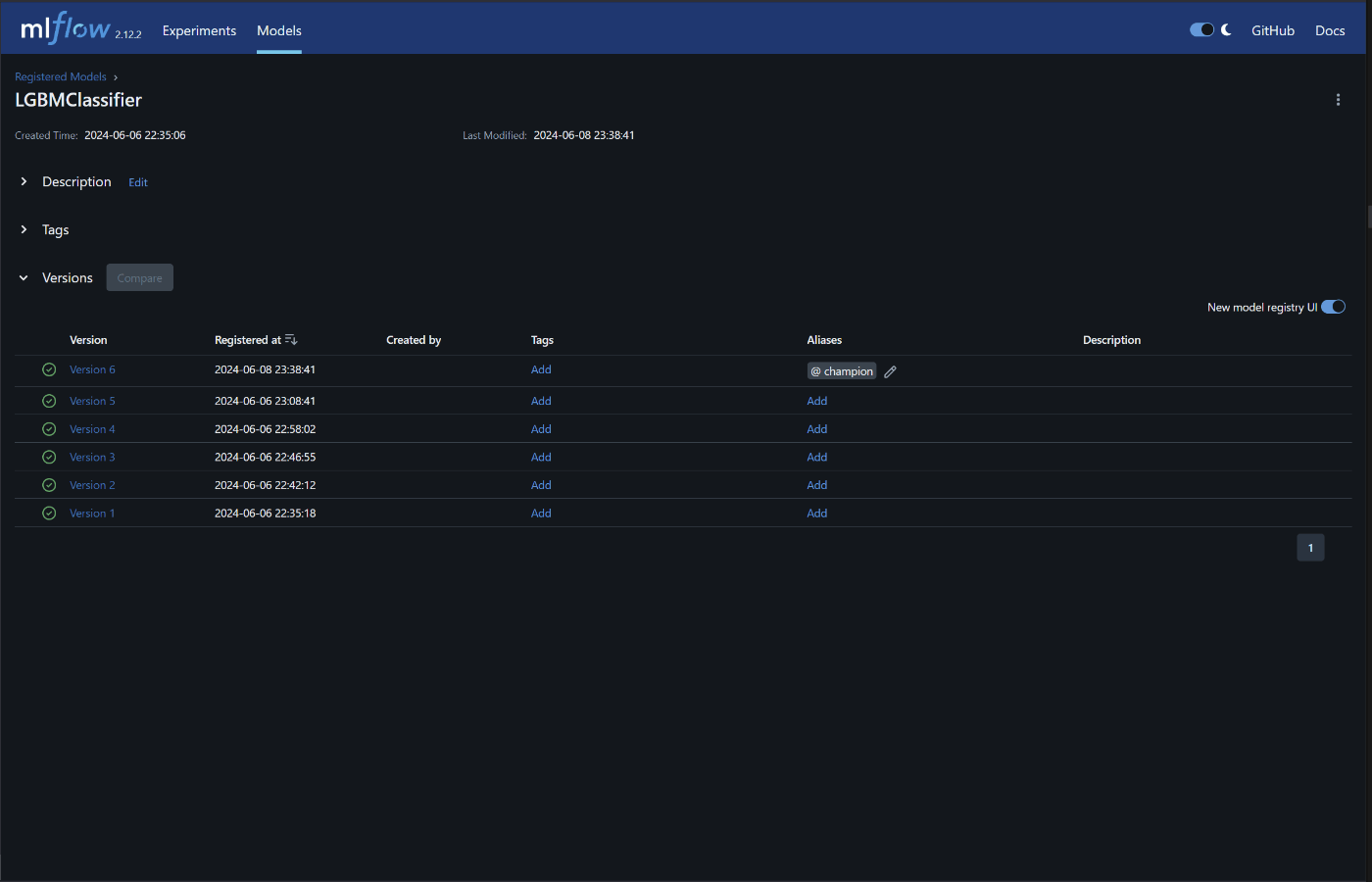
modelの取得ですが、mlflowの各実験のArtifactsからモデルの登録を行い、モデル一覧で
Aliasesの設定をします。このようにすることで、UI操作で指定したバージョンのモデルを自動的に参照してくれるようになります。(今回はcronでの定期実行なので、推論サーバをたてるということは行いません。)
recorder
botの稼働のためには最低限ohlcv、ウォレット残高、売買記録が欲しいです。売買記録はtrader.pyで保存します。それ以外だと、OIやLS比はまとまった期間のデータを取得することが難しいため、自分で取得するようにしたほうがよいです。
可視化
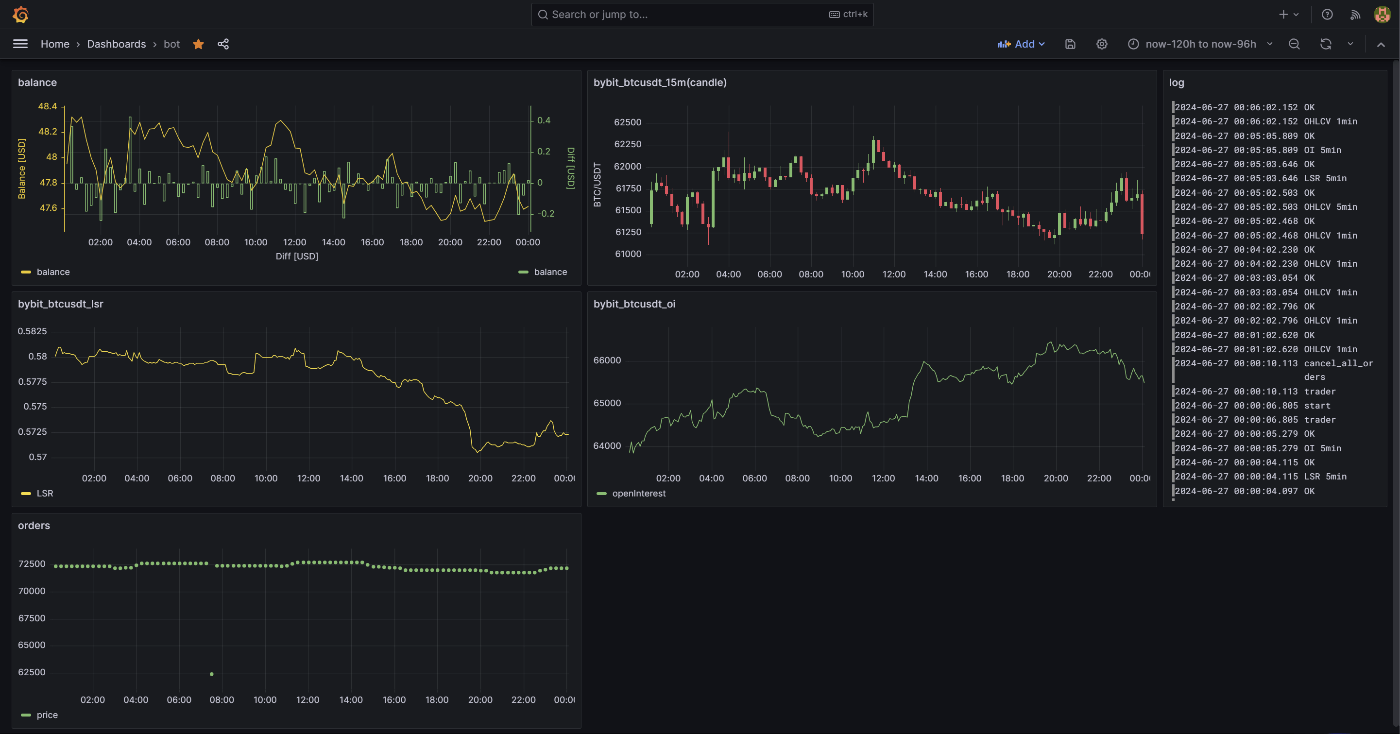
grafanaでウォレット残高、ohlcv、LS比、OI、注文履歴、botの動作履歴を表示しています。
おわりに
実験基盤、モデル管理等整えてbot開発を楽しみましょう!
botは儲からないからやめたほうがいい(本当に儲かっていない)
Discussion