🤖
Roo Code(Roo-Cline)でローカルLLM(Ollama)のQwen3を設定する
動作イメージ


step1: Ollamaをダウンロードする

ollama download

step2: ダウンロードするモデルを確認する

# ハードウェア互換性(いわゆる量子化)
4-bit Q4_K_M 9 GB
5-bit Q5_0 10.3 GB
5-bit Q5_K_M 10.5 GB
6-bit Q6_K 12.1 GB
8-bit Q8_0 15.7 GB
# Quantization Types
# GGUF
## https://huggingface.co/docs/hub/gguf#gguf

step3: Qwen3をダウンロードする
※powershellで作業する
# 管理者権限
setx /M PATH "%PATH%;%LOCALAPPDATA%\Programs\Ollama"
# ollama version check
& "$env:LOCALAPPDATA\Programs\Ollama\ollama.exe" --version
ollama version is 0.6.7
## ollama download model command
& "$env:LOCALAPPDATA\Programs\Ollama\ollama.exe" run hf.co/Qwen/Qwen3-14B-GGUF:Q4_K_M
pulling manifest
pulling 500a8806e85e: 100% ▕██████████████████████████████████████████████████████████▏ 9.0 GB
pulling 5de36594c108: 100% ▕██████████████████████████████████████████████████████████▏ 11 KB
pulling eb4402837c78: 100% ▕██████████████████████████████████████████████████████████▏ 1.5 KB
pulling 79712d8831ed: 100% ▕██████████████████████████████████████████████████████████▏ 247 B
pulling 46771b859aa5: 100% ▕██████████████████████████████████████████████████████████▏ 697 B
verifying sha256 digest
writing manifest
success
>>> Send a message (/? for help)
# ollama download list
& "$env:LOCALAPPDATA\Programs\Ollama\ollama.exe" list
NAME ID SIZE MODIFIED
hf.co/Qwen/Qwen3-14B-GGUF:Q4_K_M dd1715a0104f 9.0 GB 3 hours ago
step4: Roo-Clineの設定する
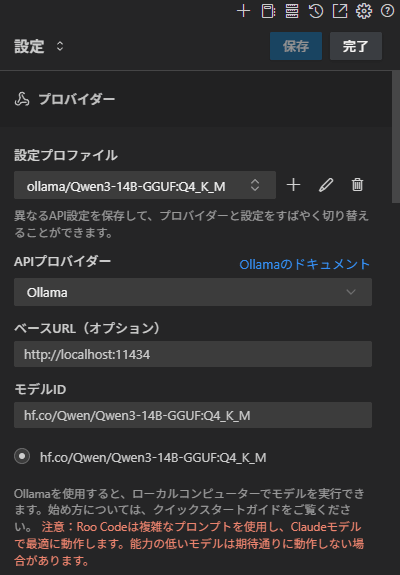
# roo-cline settings
## APIプロバイダー
Ollama
## ベースURL
http://localhost:11434
## モデルID
hf.co/Qwen/Qwen3-14B-GGUF:Q4_K_M
補足:PCスペック
# 動作環境
### プロセッサ
プロセッサ Intel(R) Core(TM) i7-14700KF 3.40 GHz
### グラフィックス カード
グラフィックス カード NVIDIA GeForce RTX 3090 24GB
ドライバー 32.0.15.7283
### RAM
実装 RAM 64.0 GB (63.8 GB 使用可能)
速度 4800MHz
### ストレージ
SSD NVMe 2TB
### OS
エディション Windows 11 Pro
バージョン 24H2
OS ビルド 26100.3915
余談:
LM Studioでも同様にモデルをダウンロードしてRoo-Cline側でベースURLなどを指定したが、コンテキストが4096に制限されたのか(3090なら問題ないはずだが)18kくらいに増やすとPCがクラッシュして電源OFF/ONを5回くらい繰り返させられた。
LM Studio自体はオフラインChatGPT的な使い方はできるのでWEB検索はQwen3対応していないらしいが、そのうちできるようになるでしょう。
この記事は久々に人間が書いた記事。
それでは、また次回。
Discussion