エンドツーエンド会話モデル「Mini-Omni」の論文を読む
この記事では、2024年8月末に出た「Mini-Omni」の論文を翻訳して読んでいきます。「Mini-Omni」とは、音声認識→LLM→音声合成のようにステップを踏む形式ではなく、音声を入力し、その回答を音声で出力するエンドツーエンドの会話モデルです。
Mini-Omni
Arxiv
GitHub
Abstract
最近の言語モデルの進展は大きな進歩を遂げています。GPT-4oは新たなマイルストーンとして、人間とのリアルタイムの会話を可能にし、ほぼ人間のような自然な流暢さを示しています。このような人間とコンピュータのインタラクションには、音声モダリティで直接推論を行い、ストリーミングで出力を生成する能力を持つモデルが必要です。しかし、現在の学術モデルでは、音声合成のために追加のTTSシステムに依存しているため、望ましくない遅延が生じています。本論文では、リアルタイムの音声インタラクションが可能な音声ベースのエンドツーエンド会話モデル「Mini-Omni」を紹介します。この能力を実現するために、テキスト指示による音声生成方法と、推論中のバッチ並列戦略を提案し、パフォーマンスをさらに向上させます。私たちの方法は、元のモデルの言語能力を最小限の劣化で保持するのにも役立ち、他の研究がリアルタイムインタラクション能力を確立することを可能にします。このトレーニング方法を「Any Model Can Talk」と呼びます。また、音声出力に最適化されたモデルを微調整するためのVoiceAssistant-400Kデータセットも紹介します。私たちの知る限り、Mini-Omniはリアルタイム音声インタラクションのための初の完全なエンドツーエンドのオープンソースモデルであり、今後の研究にとって貴重な可能性を提供します。
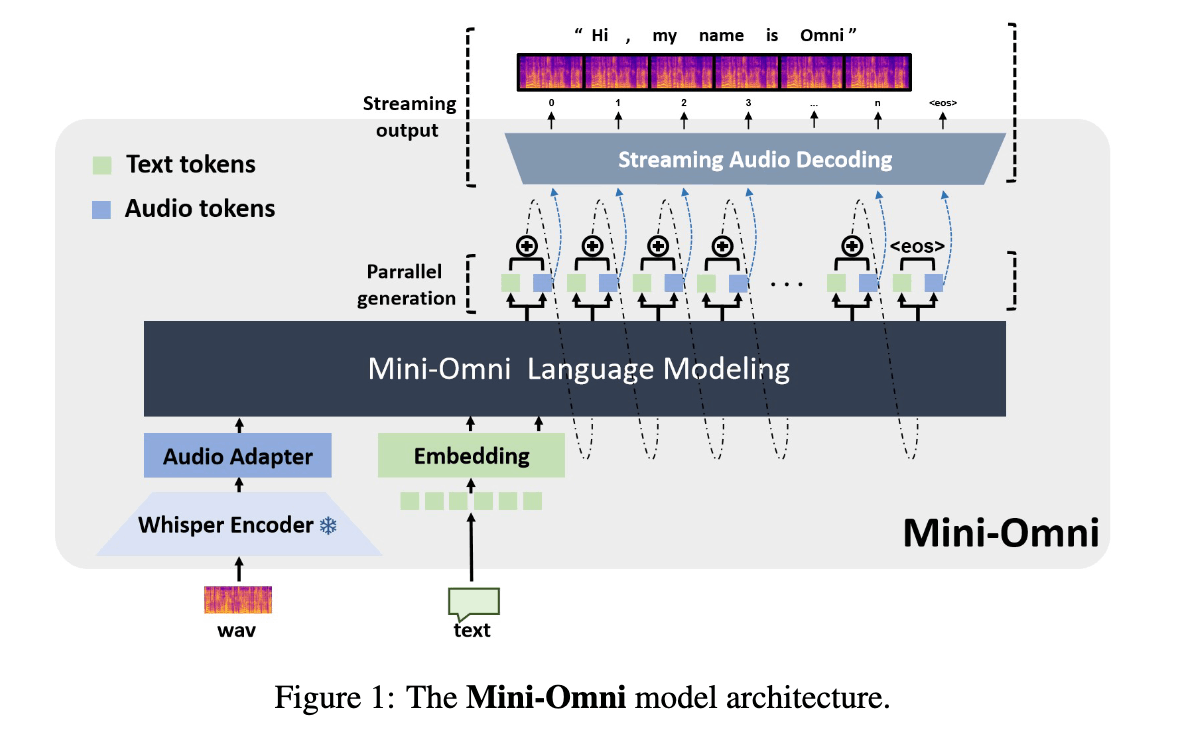
Introduction
長いので省略
最近の大規模言語モデルの進展は急速に進んでおり、Llama 3.1 [meta, 2024]、Mixtral [mixtral, 2024]、Qwen-2 [Yang et al., 2024a]、そしてよく知られたGPT-4のように、モデルはますます強力になっています。これらの能力の拡張として、言語モデルは他のモダリティの理解をマスターし始めており、LLaVA [Liu et al., 2024]、Qwen2-Audio [Chu et al., 2024]、Video-llama [Zhang et al., 2023b]がその例です。特定のタスクにおける強さにもかかわらず、大規模言語モデルを日常的なアプリケーションにさらに統合するのを妨げる大きなギャップが残っています。それはリアルタイムの音声インタラクション能力です。OpenAIによって導入されたGPT-4o [openai, 2024]は、リアルタイムのマルチモーダル音声インタラクション機能を備えた最初のモデルです。これは、視覚、音声、テキストを理解し、リアルタイムの音声会話を可能にしますが、ソースコードは非公開のままです。他のモデルは通常、音声機能を組み込むために二つのアプローチを採用しています。一つはカスケード方式で、言語モデルがテキストを生成し、その後にテキストから音声への変換(TTS)モデルで音声合成を行います。このアプローチは、テキスト生成にかかる時間のために大きな遅延を引き起こし、ユーザー体験に深刻な影響を与えます。もう一つは、SpeechGPT [Zhang et al., 2023a]のようなエンドツーエンド方式で、テキストを生成した後に音声を生成します。しかし、これでもテキスト生成を待つ必要があります。大規模言語モデルは、リアルタイムのフィードバックを提供するために、真のエンドツーエンドの音声出力機能が必要です。
音声出力機能を強化することは、主に四つの要因から難しい課題です。(1) 音声推論の複雑さ:私たちの実験では、音声モダリティの推論のための直接的なトレーニングが非常に難しく、モデルからの出力が一貫性を欠くことが多いことが示されています。(2) モデルの複雑さ:音声入力と出力のための追加モジュールを組み込むことで、全体の複雑さが増します。(3) モダリティの整合性の難しさ:テキストのために発展した推論能力を音声ドメインに移すのは難しいです。(4) リソースの要求:モデルのテキスト機能を音声モダリティに適応させるには、すべてのデータラベルを音声に変換し、再トレーニングする必要があり、リソース消費が大幅に増加します。
本論文では、リアルタイムの会話能力を持つ最初のオープンソースのマルチモデル大規模言語モデル「Mini-Omni」を提案します。これは、完全なエンドツーエンドの音声入力と出力機能を備えています。また、自動音声認識(ASR)などのさまざまな音声からテキストへの機能も含まれています。現在利用可能なオフ・ザ・シェルフの方法を適応させて音声トークンを離散化し、最もシンプルなモデルアーキテクチャを採用することで、他の研究者が私たちのモデルとアプローチを簡単に適応できるようにしています。直接的な音声推論は大きな課題ですが、私たちのアプローチは0.5Bのモデルと限られた量の合成音声データのみを使用してこれに成功しています。重要なのは、私たちのトレーニングフレームワークが、広範なモデル機能や大量のデータに重く依存することなくこれを達成していることです。
言語モデルの元々の能力を活用し、保持するために、トランスフォーマーが同時に音声とテキストトークンを生成する並列生成パラダイムを提案します。その後、音声モダリティがテキスト能力に与える影響が最小限であることを観察し、バッチベースの並列生成を導入しました。これにより、ストリーミング音声出力中のモデルの推論能力が大幅に向上します。ポイントとして、音声推論の複雑さを減らすために、シンプルで低ビットレートの音声エンコーダーのために音声品質を犠牲にしないことを選びました。しかし、音声品質を確保するために、8層のコードブックを持ち、1秒間に数百のトークンを処理する音楽グレードのエンコーダーSNAC [Siuzdak, 2024]を選びました。革新的に、長いSNACコードブックシーケンスの問題に対処するために、テキスト指示による遅延並列生成を適用しました。実験の結果、音声出力の品質は一般的なTTSシステムと同等であることが示されています。
また、元のモデルのトレーニングと修正を最小限に抑える方法を提案し、他の研究が迅速に独自の音声機能を開発できるようにします。このアプローチを「Any Model Can Talk」と呼び、限られた量の追加データを使用して音声出力を実現するように設計されています。このアプローチは、追加のアダプターと事前トレーニングされたモデルを通じて音声機能を拡張し、少量の合成データでファインチューニングします。これは、前述の並列モデリングアプローチと組み合わせて、新しいモダリティでのストリーミング出力を可能にしながら、元のモデルの推論能力を保持します。
Mini-Omniの能力を評価するために、まずは従来のテキストから音声へのマルチモーダルタスク、つまりテキストベースの質問応答(textQA)、自動音声認識(ASR)、テキストから音声への応答、音声ベースの質問応答(speechQA)におけるパフォーマンスを評価しました。このモデルは、これらの基本的なタスクにおいて強力な能力を示しました。さらに、元のモデルの能力に対する影響を調査し、推論手法の効果とバリエーションを評価するために一連の実験を行いました。予備実験では、バッチ並列推論がモデルの元の能力を保持することが示されました。今後、さらなる実験を行い、追加の詳細を提供する予定です。
最後に、ほとんどのオープンソースのQAデータセットには混合コードや過度に長いテキストが含まれており、音声モデルには不適切であることがわかりました。この制限を克服するために、音声アシスタントの監視付きファインチューニング(SFT)用に特に生成された40万件以上のエントリーからなるVoiceAssistant-400Kデータセットを導入します。
要約すると、以下の貢献を行います:
• Mini-Omniを紹介します。これは、音声入力と音声ストリーミング出力機能を持つ初のオープンソースのエンドツーエンドマルチモーダル大規模モデルです。テキスト指示並列生成手法を提案し、最小限のデータで音声推論出力をテキスト能力に合わせて実現します。さらに、遅延並列性を強化し、音声推論速度を加速します。
• 「Any Model Can Talk」という革新的なアプローチを導入し、大規模モデルのアーキテクチャを変更することなく、トレーニングと推論に焦点を当てることでパフォーマンスを向上させます。私たちの手法は、音声からテキスト、テキストから音声のアダプターのための三段階のトレーニングプロセスを採用し、アニーリングとSFTを含みます。私たちの手法は、元のモデルの最小限のトレーニングと修正を伴い、他のモデルにインタラクション機能を組み込むための参考を提供することを目指しています。
• 音声アシスタントのトレーニングにおける既存のオープンソースQAデータセットの欠点を特定し、音声モデル出力用の専用データセットであるVoiceAssistant-400Kを提案しました。このデータセットは、GPT-4oを使用して合成されており、モデルをファインチューニングして音声アシスタントのトーンを開発するために使用できます。
2.関連研究
長いので省略
マルチモーダル理解 最近、研究者たちはクロスモーダル理解のための統一モデルの進展にますます注目しています。これらのアプローチは通常、関連するモダリティのエンコーダーとしてよく訓練されたニューラルネットワークを使用し、軽量なアダプターを使ってエンコーダーの出力を言語モデルのテキスト入力に合わせます。LLaVA [Liu et al., 2024]、Flamingo [Alayrac et al., 2022]、BLIP [Li et al., 2022] などの古典的な研究は視覚理解に使われており、音声分野ではWhisper [Radford et al., 2023] やBeats [Chen et al., 2022] のようなモデルが意味的および音響的特徴のエンコーダーとして一般的に利用されています。Llama 3.1ではWhisperが使用され、SpeechVerse [Das et al., 2024]はWavLM [Hu et al., 2024]を活用しています。SALMONN [Tang et al., 2023]はWhisperとBeatsを組み合わせて特徴を抽出しています。このような研究は、テキストモダリティで出力を生成することに制約されることが多いです。
音声言語モデリング 最近、音声トークン化を用いて音声とテキストのギャップを埋める研究が増えています。音声トークン化は連続した音声信号を離散的な音声トークンに変換し、大規模言語モデルが推論を行ったり、クロスモーダルな相互作用を実現したりできるようにします。その結果、ASR、TTS、音楽理解と生成、音声編集など、さまざまなスピーチテキストタスクが実現可能になります。MegaTTS [Jiang et al., 2023]は音声合成のために音声コーデックを利用し、InstructTTS [Yang et al., 2024b]、SpearTTS [Kharitonov et al., 2023]、Voicebox [Le et al., 2024]のような取り組みは、トークンから音声への変換にDiffusionを用いて、デコーディング手法や条件付け技術の最適化をさらに探求しています。
リアルタイム人間-機械インタラクションモデル GPT-4o [openai, 2024]の導入以来、リアルタイム会話モデルは前例のない成果を上げ、ユーザー入力に対してほぼ瞬時に音声フィードバックを提供し、次世代のマルチモーダル大規模モデルにとって重要なマイルストーンとなっています。しかし、技術的な実装は依然として独自のものであり、リアルタイムインタラクション機能を持つモデルは現在ほとんど存在しません。SpeechGPT [Zhang et al., 2023a]は初期のエンドツーエンドの音声インタラクションモデルですが、Audio-Text-Text-Audio (A-T-T-A)プロセスのためにレイテンシーの問題があります。LauraGPT [Chen et al., 2023]も同様のアプローチを採用していますが、音声会話シナリオには使用されていません。VITA [Fu et al., 2024]とQwen-audio2 [Chu et al., 2024]は音声入力をサポートする2つのモデルですが、テキストを出力し、音声合成には外部のTTSシステムに依存しています。Mini-Omniは完全なエンドツーエンドの音声対音声会話モデルです。私たちの探求を通じて、この分野の進展における最大の課題を特定しました。それは、音声モダリティのみが存在する場合の推論における論理的不整合性であり、次の章でこれに対処します。
3.Mini-Omni
私たちの革新は、SpeechGPT [Zhang et al., 2023a] や Spectron [Nachmani et al., 2023] などの既存の手法に基づいており、A-T-T-Aアプローチを利用しています。これにより、テキストを通じて音声生成プロセスをガイドすることで、直接音声学習の課題を軽減しています。しかし、テキストを先に生成し、その後に音声を生成するのは、リアルタイムの対話シナリオには最適ではありません。これに対処するために、同時にテキストと音声を生成する新しい方法を提案します。このアプローチは、テキスト出力がより高い情報密度を持ち、同じ応答をより少ないトークンで実現できると仮定しています。音声トークンの生成中、モデルは対応するテキストトークンに効果的に条件付けを行い、オンラインTTSシステムに似た形になります。音声トークンを生成する前に、Nトークンでパディングすることで、対応するテキストトークンが最初に生成されることを保証し、これがハイパーパラメータの調整として機能します。さらに、モデルはスピーカーやスタイルの埋め込みにも条件付けを行うことができ、スピーカーの特性やスタイル要素を制御することができます。このセクションでは、私たちのアイデアをステップバイステップで実装する方法を詳しく説明します。
3.1 音声言語モデリング
ここで、
3.2 デコーディング戦略
テキスト指示による音声生成。言語モデルは大きな進歩を遂げており、テキストモダリティ内で優れた推論能力を示しています。それに応じて、Mini-Omni はこれらの推論能力をテキスト-音声並列デコーディングアプローチを通じてストリーミング音声出力に移行するよう再構築されました。この方法は、音声とテキストトークンの両方を同時に出力し、音声はテキストから音声合成を通じて生成され、リアルタイムでの配信を確保しながら、テキストベースの推論の強みを活用します。大規模モデルの入力に合わせるために、並列で生成されたすべてのシーケンスは、次のトークンを生成する前に合計されます。これにより、モデルは最小限の最初のトークン遅延でチャットシナリオにおけるリアルタイム音声出力を実現できます。
テキスト遅延並列デコーディング。並列生成は、音楽生成プロセスを加速するために MusicGen [Copet et al., 2024] によって初めて導入され、私たちはこのアプローチをテキストモダリティに統合して推論能力を向上させました。並列デコーディングは、言語モデルの訓練に使用される音声トークンのコードブックが通常複数の層で構成されているため、実現可能です。すべての層を同時に生成することで、モデルの速度を大幅に向上させることができます。リアルタイム音声出力モデルにとって、並列デコーディングはさらに重要であり、標準デバイスで毎秒数百の音声トークンを生成することが可能です。本論文では、SNACを音声エンコーダーとして使用し、補完的な関係を持つ7つのトークン層で構成されています。したがって、隣接する層の間に1ステップの遅延を維持しながら、テキストを含む8つのトークンを一度に生成するために8つのサブ言語モデルヘッドを使用します。音声トークンはテキスト合成から派生しているため、テキストトークンが最初に出力され、その後、最初の層から第七層までのSNACトークンが続きます。私たちが提案するテキストファースト遅延並列デコーディングのプロセスは、図2(b)に示されています。
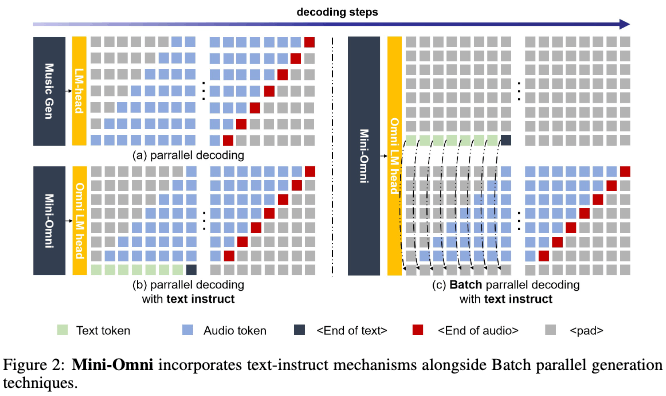
バッチ並列デコーディング。以前に紹介した並列生成手法は、テキストモダリティからオーディオモダリティへの推論能力の移転を効果的に行いますが、私たちの実験では、モデルの推論性能がテキストタスクとオーディオタスクで異なることが明らかになりました。オーディオの応答はよりシンプルになる傾向があります。これは、モデルの能力に限界があるか、オーディオデータが不十分であるためだと仮定しています。この問題に対処し、対話中のモデルの推論能力をさらに向上させるために、テキストベースの能力の移転を最大化するために、実験的にバッチアプローチを採用します。モデルがテキストモダリティでより強い性能を発揮するため、単一の入力に対する推論タスクをバッチサイズ2に拡張します:1つのサンプルは、前述のようにテキストとオーディオの両方の応答を必要とし、もう1つのサンプルはテキスト応答のみを必要とし、テキストベースのオーディオ合成に焦点を当てます。ただし、最初のサンプルからのテキストトークン出力は破棄され、2番目のサンプルからのテキスト出力は最初のサンプルの対応するテキストトークン位置に埋め込まれます。同時に、最初のサンプルのオーディオは、2番目のサンプルのテキストのみの応答からのコンテンツを使用してストリーミングされます。このプロセスをバッチ並列デコーディングと呼びます。この方法を通じて、リソースのオーバーヘッドを最小限に抑えながら、モデルのテキストベースの能力をオーディオモダリティに効果的かつほぼ完全に移転し、新しいモダリティでの推論能力を大幅に向上させます。バッチ並列デコーディングの推論プロセスは図2(c)に示されています。バッチ並列デコーディングは、このような小さなモデルが強力な会話能力を示すことを可能にする重要なアルゴリズムの革新であると考えています。
3.3 どんなモデルでも話せる
このセクションでは、私たちのトレーニング方法論を紹介します。私たちのアプローチは、元のモデルの能力をできるだけ保持するように設計されています。これは、まず私たちのベースモデルの強力な性能によって、次に私たちの方法がテキスト出力に優れた他の作品にも適用できるためです。
オーディオエンコーディング:オーディオ入力は主に入力オーディオからの特徴抽出に焦点を当てており、Hubertや別に事前トレーニングされたオーディオエンコーダーなどのオプションがあります。音声入力に焦点を当てているため、Whisper [Radford et al., 2023]やQwen2-audio [Chu et al., 2024]も一般的なオーディオタスクに対して効果的な性能を示しています。オーディオ出力では、マルチコードブックアプローチを使用してオーディオトークンを選択することで、オーディオの詳細をよりよく捉えます。オーディオトークンモデリングのためにフラット化を試みましたが、トークンが過度に長くなり、ストリーミングに悪影響を及ぼし、不安定な学習につながりました。代わりに、MusicGen [Copet et al., 2024]に触発された並列デコーディングは、テキスト条件と組み合わせた遅延パターンを採用しています。
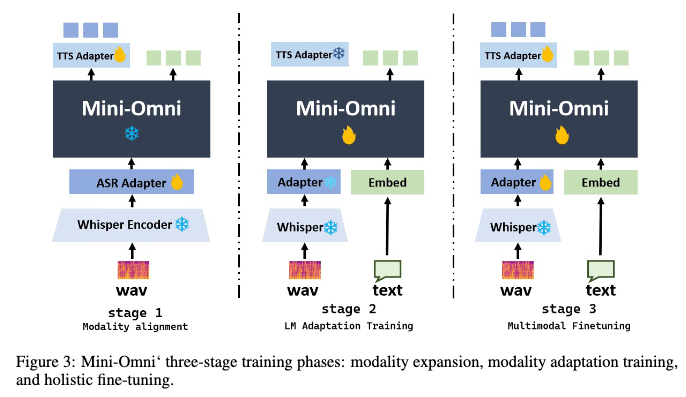
三段階トレーニング。私たちのトレーニング方法論は、次の3つの異なる段階に分かれています:(1) モダリティアラインメント。この段階の目標は、テキストモデルの音声理解と生成能力を向上させることです。Mini-Omniのコアモデルは完全に固定され、勾配は2つのアダプターのみに許可されます。この段階では、音声認識と音声合成のデータを使用してモデルの音声認識と合成能力をトレーニングします。(2) アダプショントレーニング。新しいモダリティがテキストモデルの入力と整合したら、アダプターは固定されます。この段階では、オーディオ入力が与えられたときのモデルのテキスト能力のトレーニングにのみ焦点を当てます。オーディオ出力は単にテキストから合成されます。モデルは音声認識、音声質問応答、テキスト応答タスクのデータを使用してトレーニングされます。(3) マルチモーダルファインチューニング。最終段階では、全モデルが包括的なデータを使用してファインチューニングされます。この時点で、すべてのモデルの重みが解凍され、トレーニングされます。主要なモダリティアラインメントタスクはアダプタートレーニング中に処理されるため、元のモデルの能力は最大限に保持されます。
モデル入力ID。8つの並列出力シーケンスがあるため、入力も8つのシーケンスを必要とし、複雑さが大幅に増します。したがって、ここではモデル入力の組織を簡単に説明します。モデルはテキストまたはオーディオ入力のいずれかを受け入れることができ、対応するモダリティシーケンスに配置されます。オーディオ入力の場合、入力トークンとWhisper特徴はアダプターを介して同じ次元のテンソルに変換され、その後連結されます。タスクに応じて、<answer>特別トークンを異なる位置に配置してモデルの出力を誘導し、マルチモーダル出力を実現します。一部のタスクの組織は図4に示されています。モデルに供給される前に、すべてのシーケンスは特徴を統合するために合計され、平均化されます。

4. 実験
このセクションでは、Mini-Omniの基礎的な能力テストの結果を示します。まず、トレーニングデータセット、データ処理方法、ハイパーパラメータについて説明します。その後、音声認識などのコアタスクにおけるモデルのパフォーマンスを評価し、いくつかのユースケースの例を提供します。関連するすべての実験は、次のバージョンにできるだけ早く含める予定です。
4.1 データセット
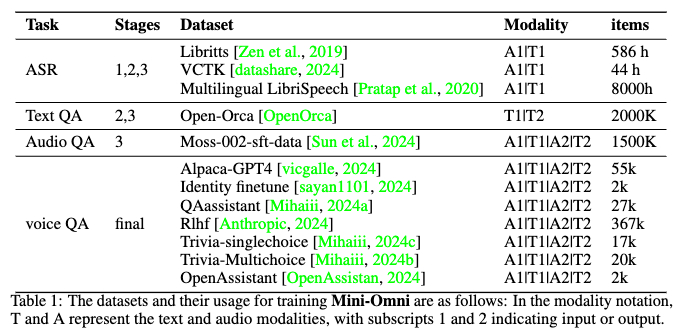
基礎的な音声能力を確立するために、約8,000時間の音声認識データセットを使用してモデルをトレーニングしました。音声理解と合成に焦点を当てています。テキストモダリティには、Open-Orca [OpenOrca] データセットからの200万のデータポイントを取り入れ、他のモダリティと統合してテキストの正確性を保ちました。MossのSFTデータセット [Sun et al., 2024] を使用して、ゼロショットTTSで150万の音声QAペアを合成しました。不適切なコードや記号的な出力を避けるために、GPT-4oを使ってVoiceAssistant-400Kデータセットを作成しました。データセットの詳細は表1に示されています。ステージ1では、音声アダプタのトレーニングのためのASRデータを使用します。ステージ2では、音声/テキスト入力とテキスト応答のトレーニングにTextQAとAudioQAを使用します。ステージ3では、AudioQAの音声モダリティを使用したマルチモーダルインタラクションに焦点を当てます。最終ステージのトレーニングには、アニーリングとVoice QAを用いたファインチューニングが含まれます。
4.2 トレーニングパラメータ
私たちのモデルは8台のA100 GPUでトレーニングされており、最小学習率4e-6、最大学習率4e-4のコサインアニーリング学習率スケジューラを利用しています。各トレーニングエポックは40,000ステップで構成され、各ステップのバッチサイズは192です。ベースの言語モデルはQwen2-0.5B [Yang et al., 2024a]を使用しており、24のブロックと内部次元896のトランスフォーマーアーキテクチャです。音声エンコーダーはWhisper-smallエンコーダーを使用し、ASRアダプタは2層のMLPを介して接続され、TTSアダプタは元のモデルに6つの追加トランスフォーマーブロックを加えています。ファインチューニング中は、学習率を4e-6から5e-5に設定しています。
4.3 実験結果
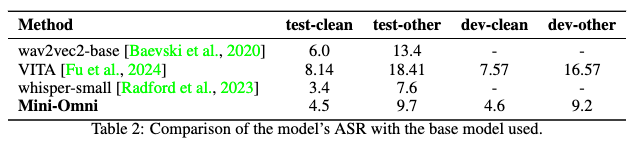
まず、ASRタスクにおけるモデルの性能を評価し、音声理解能力を確認しました。音声認識能力に関する基本的な実験は、LibriSpeech [Panayotov et al., 2015]の4つのテストセット(test-clean、test-other、dev-clean、dev-other)を使用して行いました。結果は表2に示されており、私たちが採用した音声認識システム、wav2vec2 [Baevski et al., 2020]とWhisper-small、さらにVITA [Fu et al., 2024]の精度を比較しています。結果は、Mini-Omniの音声認識性能がWhisper-smallの[Radford et al., 2023]デコーダーには若干劣るものの、依然として優れた音声理解レベルを達成していることを示しています。
4.4 ケーススタディ
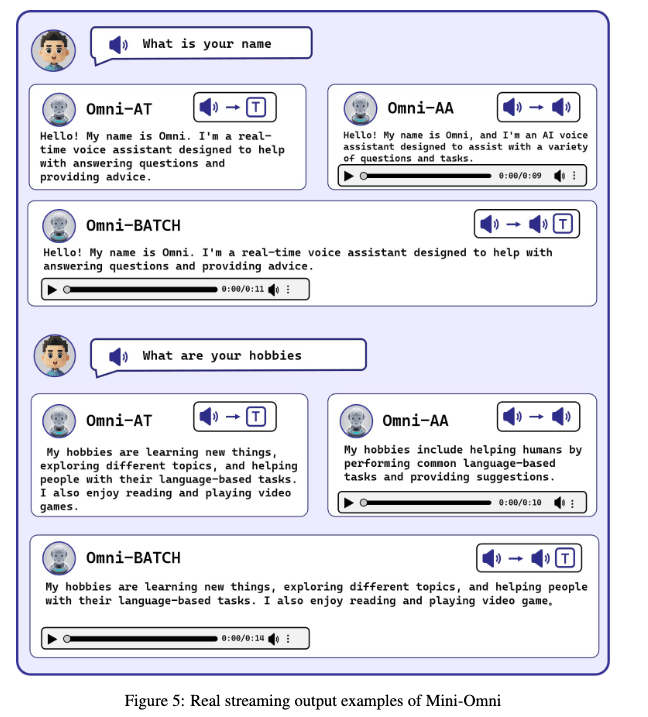
ここでは、Mini-Omniの音声理解と推論の能力を示すいくつかのケースを紹介します。これらの例は、音声ベースの推論がテキストベースの推論に比べてやや弱いことを明らかにし、バッチ生成の必要性を強調しています。より印象的な例については、https://github.com/gpt-omni/mini-omni を参照してください。
図5: Mini-Omniのリアルストリーミング出力例
5. 結論
本研究では、直接的な音声から音声への能力を持つ初のマルチモーダルモデル、Mini-Omniを紹介します。テキストに基づく音声生成を利用した以前のアプローチを基に、最小限の追加データとモジュールを活用して、言語モデルのテキスト能力を音声モダリティに迅速に移行するための並行テキストと音声生成手法を提案します。これにより、高いモデルとデータ効率でストリーミング出力インタラクションをサポートします。テキスト指示によるストリーミング並行生成とバッチ並行生成の両方を探求し、モデルの推論能力と効率をさらに向上させます。私たちのアプローチは、わずか0.5億パラメータのモデルを使用して、難しいリアルタイム対話タスクに成功裏に対処します。最小限の追加トレーニングで他のモデルの迅速な音声適応を促進するために、事前および事後アダプターデザインに基づいた「Any Model Can Talk」メソッドを開発しました。さらに、コードシンボルの生成を最小限に抑え、人間を音声アシスタントのように支援するために設計された音声出力のファインチューニング用データセット「VoiceAssistant-400K」をリリースしました。私たちのデータ、推論、トレーニングコードは、https://github.com/gpt-omni/mini-omni で段階的にオープンソース化される予定です。他の言語モデルの音声インタラクションに焦点を当てた作業に対して、ガイダンスとサポートを提供できることを願っています。