ローカルLLMに入門してみた#1


ローカルLLMに入門してみた#1
はじめに
最近、LLM界隈は様々な動きで盛り上がっています。その中でもローカルLLMが静かに注目を集め始めています。このビッグウェーブに乗らない手はありません。今回は、Ollamaをインストールしてgemmaモデルを動かしてみた体験をご紹介します。
Ollamaのインストール
インストールはこちらのサイトを参考にしました。このサイトの手順通りに進めることで簡単にインストールすることができます。
今回使用したPCのスペックは以下の通りです:
- CPU: AMD Ryzen 9 5900X
- GPU: NVIDIA GeForce RTX 3060
- RAM: 64GB DDR4 3200MHz
- OS: Windows11
無事にインストールを完了することができました。
モデルを別ディスクに退避
デフォルト設定では、モデルは「\ユーザー名.ollama\」に保存されます。しかし、一部のモデルは10GB以上のサイズになることもあるため、別のディスクに退避させました。私の場合は、データ保存用ディスクに.ollamaフォルダを作成し、上記のディレクトリにシンボリックリンクを設定しました。
Gemmaのインストール
Windows PowerShellを開いてollama run gemma3:1bコマンドを実行しました。これによりモデルがダウンロードされ、対話が可能になります。まずは、gemmaの最軽量モデルである1Bを試してみました。
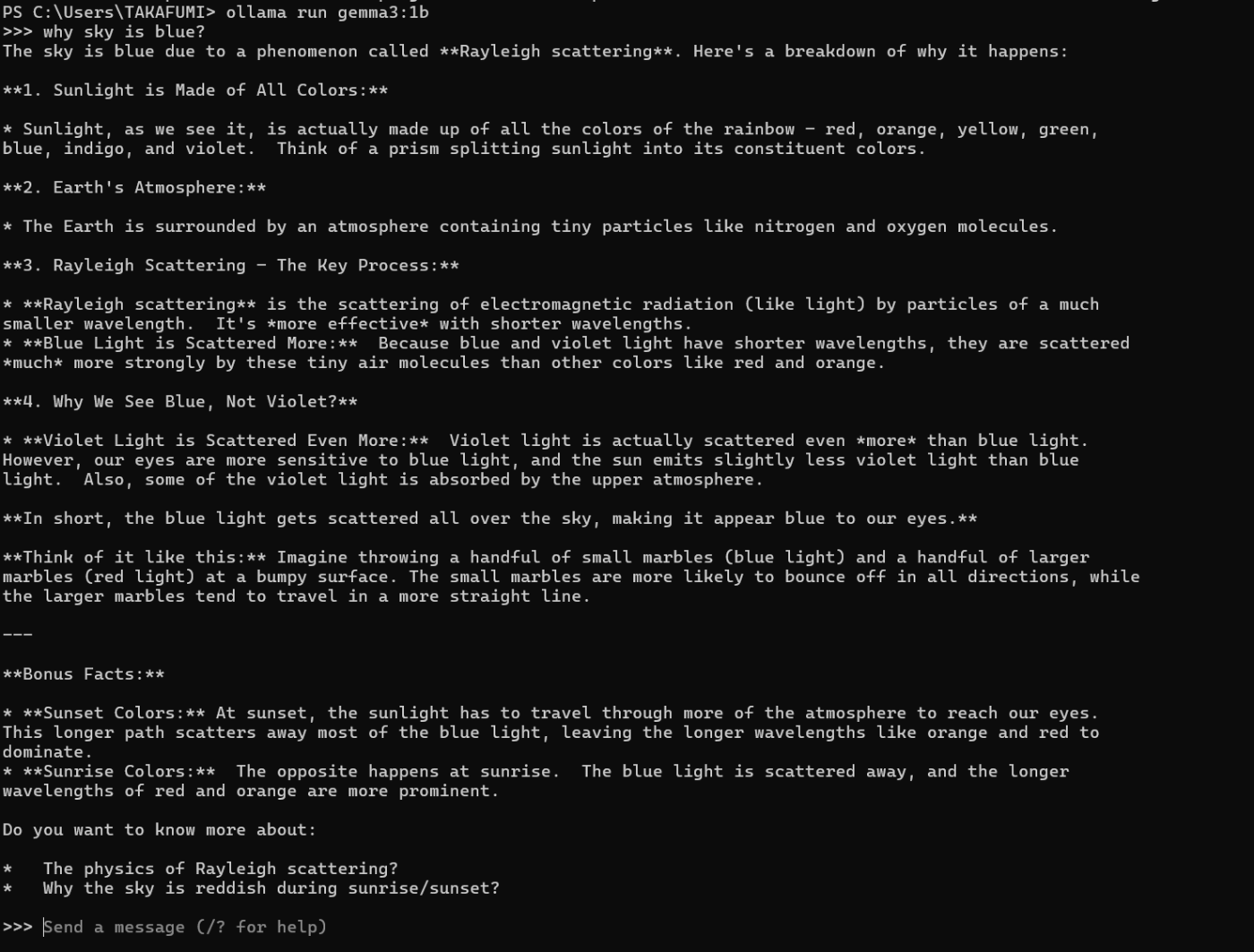
「Why is the sky blue?」と質問してみたところ、適切に回答してくれました。しかも、予想していたよりもはるかに高速でした。
日本語も多少は理解できるようですが、すぐに英語での返答に切り替わるので、日本語での利用は少し制限されるかもしれません。対話を終了するにはCtrl + Dを押します。

Gemmaの他のモデルも試してみる
次に、ollama run gemma3:27bを実行して27Bモデルも試してみました。これはollama公式で利用可能なgemmaモデルの中で最大のものです。それでも約18GBのサイズです。

このモデルは日本語もしっかりと理解し、応答することができました。ただし、実行速度は1Bモデルと比較するとかなり遅く感じられました。

テキストの読み取りはGPUを使用し、出力はCPUを利用しているようです。
出力速度は約2tps(トークン/秒)程度でした。

Windows版ではGPUをうまく活用できていないようなので、GPUの性能を最大限に活かすにはLinux環境での利用が推奨されそうです。
Discussion