StreamlitとChainlitでlangchainのAgentを試す(その2)
(その1へ)
はじめに
前回の記事では、Agentの途中経過をチャットUI上に表示する方法を調査し、StreamlitとChainlitをそれぞれ使って試してみました。
結果として、両方とも途中経過の表示自体はできることが確認できました。
ただ、前回使用したAgentは、Agent_TypeがOpenAI Functionsでした。このAgent_Typeは既に非推奨となり、新たにOpenAI Toolsを使うようにドキュメントに記載されています。
そこで、今回はAgent_TypeをOpenAI Toolsに変更し、ChainlitとStreamlitそれぞれの動作確認を行います。
最終的なコードは以下にありますので、興味があればご覧ください。
Agent_TypeをOpenAI Toolsに変更
OpenAI ToolsのAgentの作成方法は、以下のページに詳しく書かれており、memoryの使い方も記載されています。
なので実装についての説明は割愛させて頂きます。
OpenAI ToolsとOpenAI Functionsの違いは以下のページにまとめられていますが、OpenAI ToolsではSupports Parallel Function Callingにチェックが入っており、関数呼び出しが並列で行えるようになっています。

OpenAI Functionsでは、1度の応答で1つの関数しか呼び出せなかったのに対し、OpenAI Toolsでは複数の関数を同時に呼び出せるため、やり取りの回数が減り、Agentの高速化が期待できそうです。
ChainlitのOpenAI Tools対応
まず前回の記事で作成したChainlitのコードをOpenAI Toolsに対応させて動作確認を行いました。
以下がそのコードです。
import chainlit as cl
from langchain.agents import AgentExecutor, tool
from langchain.agents.output_parsers.openai_tools import OpenAIToolsAgentOutputParser
from langchain.schema.runnable.config import RunnableConfig
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.messages import AIMessage, HumanMessage
from langchain_openai import ChatOpenAI
from langchain.agents.format_scratchpad.openai_tools import (
format_to_openai_tool_messages,
)
from langchain_community.tools import DuckDuckGoSearchResults
from langchain.chains import LLMMathChain
# モデルを初期化
llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0, streaming=True)
llm_math_chain = LLMMathChain.from_llm(llm=llm)
@tool
async def calculator(expression: str) -> str:
"""Calculates the result of a mathematical expression."""
return llm_math_chain.invoke(expression)
@tool
async def ddg_search(query: str) -> str:
"""Searches DuckDuckGo for a query and returns the results."""
search = DuckDuckGoSearchResults()
return search.invoke(query)
@cl.on_chat_start
def start():
# ツールをロード
tools = [calculator, ddg_search]
# プロンプトを作成
MEMORY_KEY = "chat_history"
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are very powerful assistant. You are multilingual, so adapt to the language of your users.",
),
MessagesPlaceholder(variable_name=MEMORY_KEY),
("user", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad"),
]
)
# ツールをバインド
llm_with_tools = llm.bind_tools(tools)
# チャット履歴を初期化
chat_history = []
cl.user_session.set("chat_history", chat_history)
# Agentを作成
agent = (
{
"input": lambda x: x["input"],
"agent_scratchpad": lambda x: format_to_openai_tool_messages(
x["intermediate_steps"]
),
"chat_history": lambda x: x["chat_history"],
}
| prompt
| llm_with_tools
| OpenAIToolsAgentOutputParser()
)
agent_executor = AgentExecutor(agent=agent, tools=tools)
# AgentExecutorをセッションに保存
cl.user_session.set("agent_executor", agent_executor)
@cl.on_message
async def main(message: cl.Message):
# セッションから取得
agent_executor = cl.user_session.get("agent_executor")
chat_history = cl.user_session.get("chat_history")
res = await agent_executor.ainvoke(
{"input": message.content, "chat_history": chat_history},
config=RunnableConfig(callbacks=[cl.LangchainCallbackHandler()]),
)
# チャット履歴を更新
chat_history.extend(
[
HumanMessage(content=message.content),
AIMessage(content=res["output"]),
]
)
# Agentの出力を表示
await cl.Message(content=res["output"]).send()
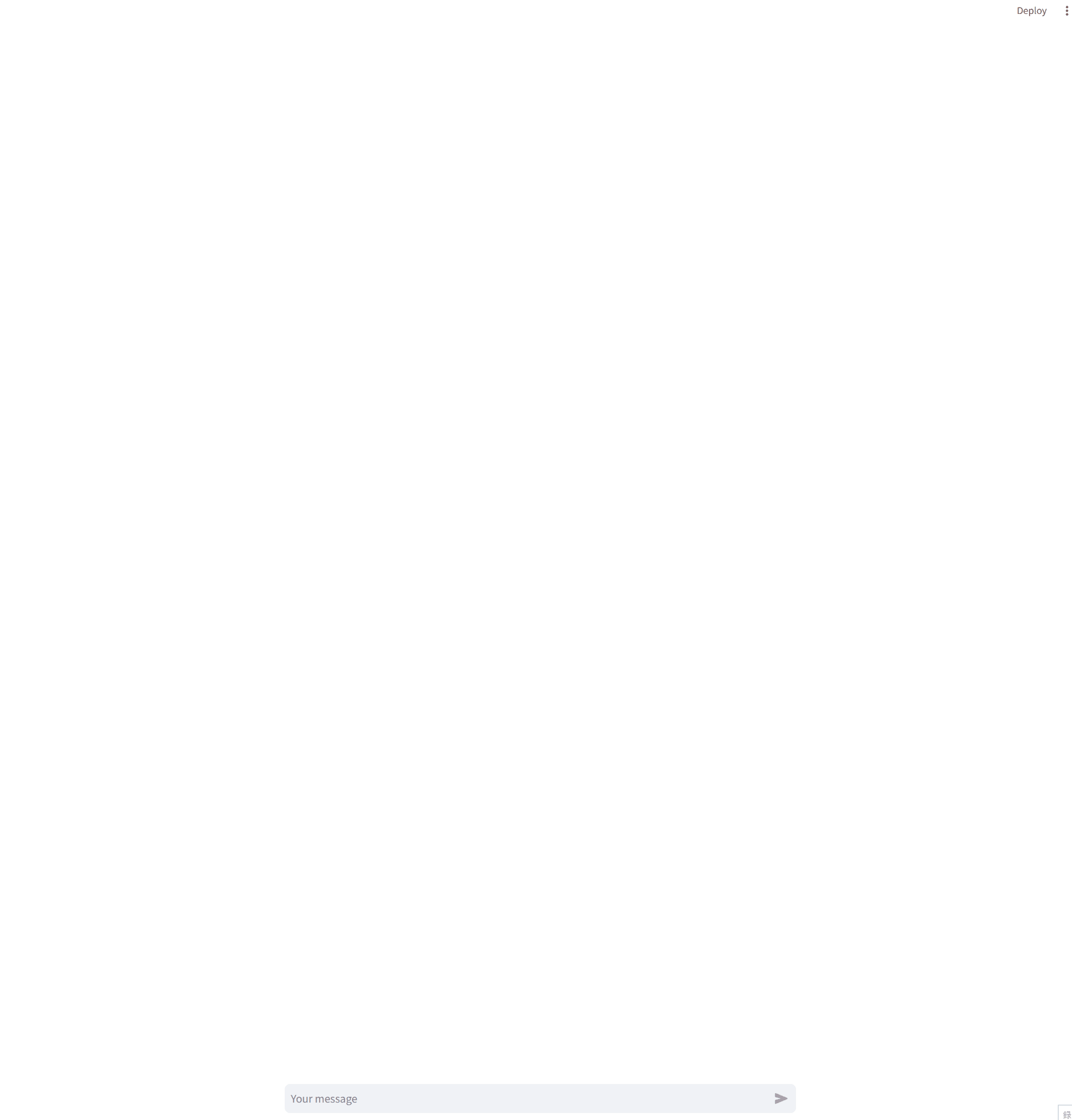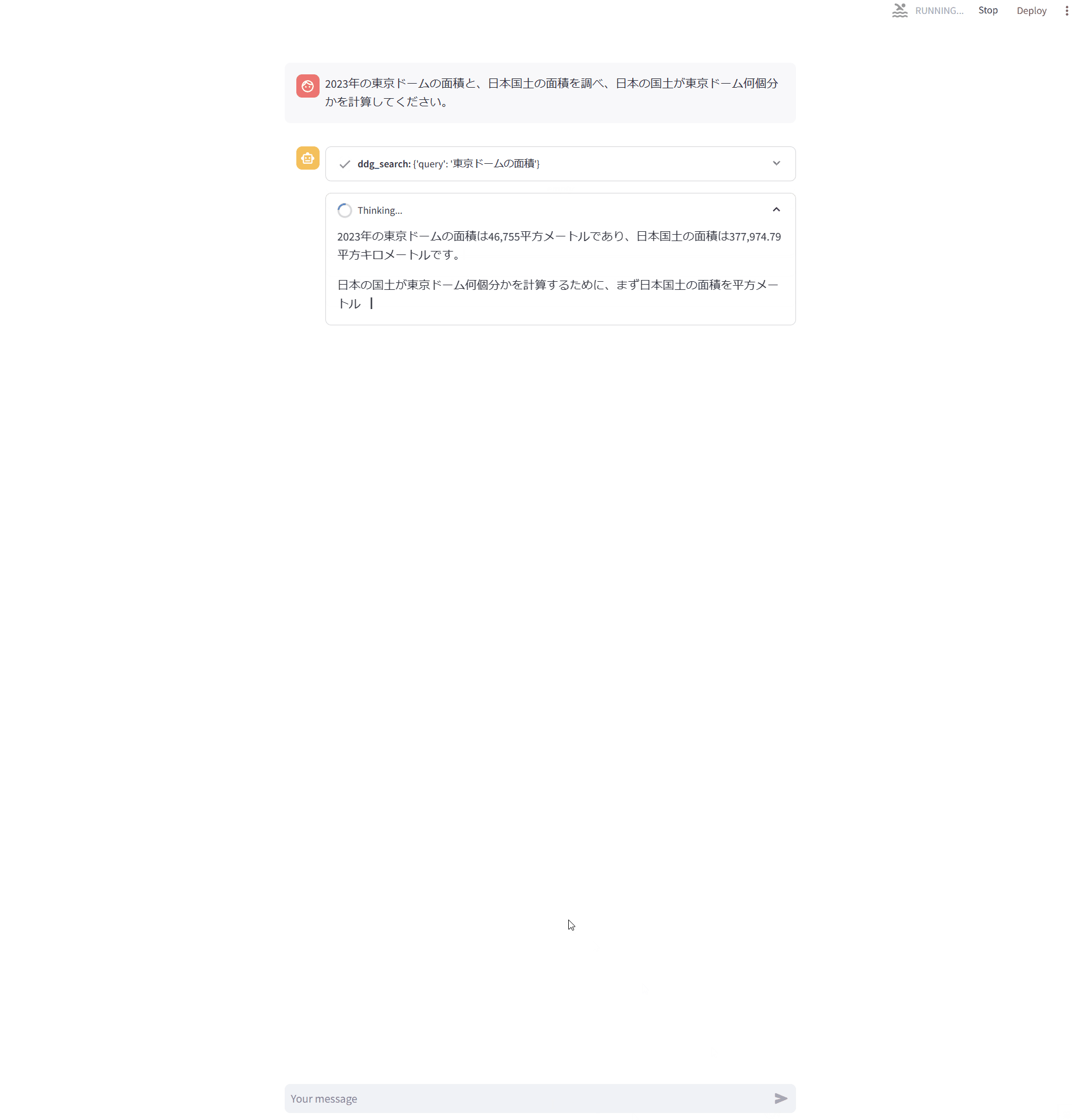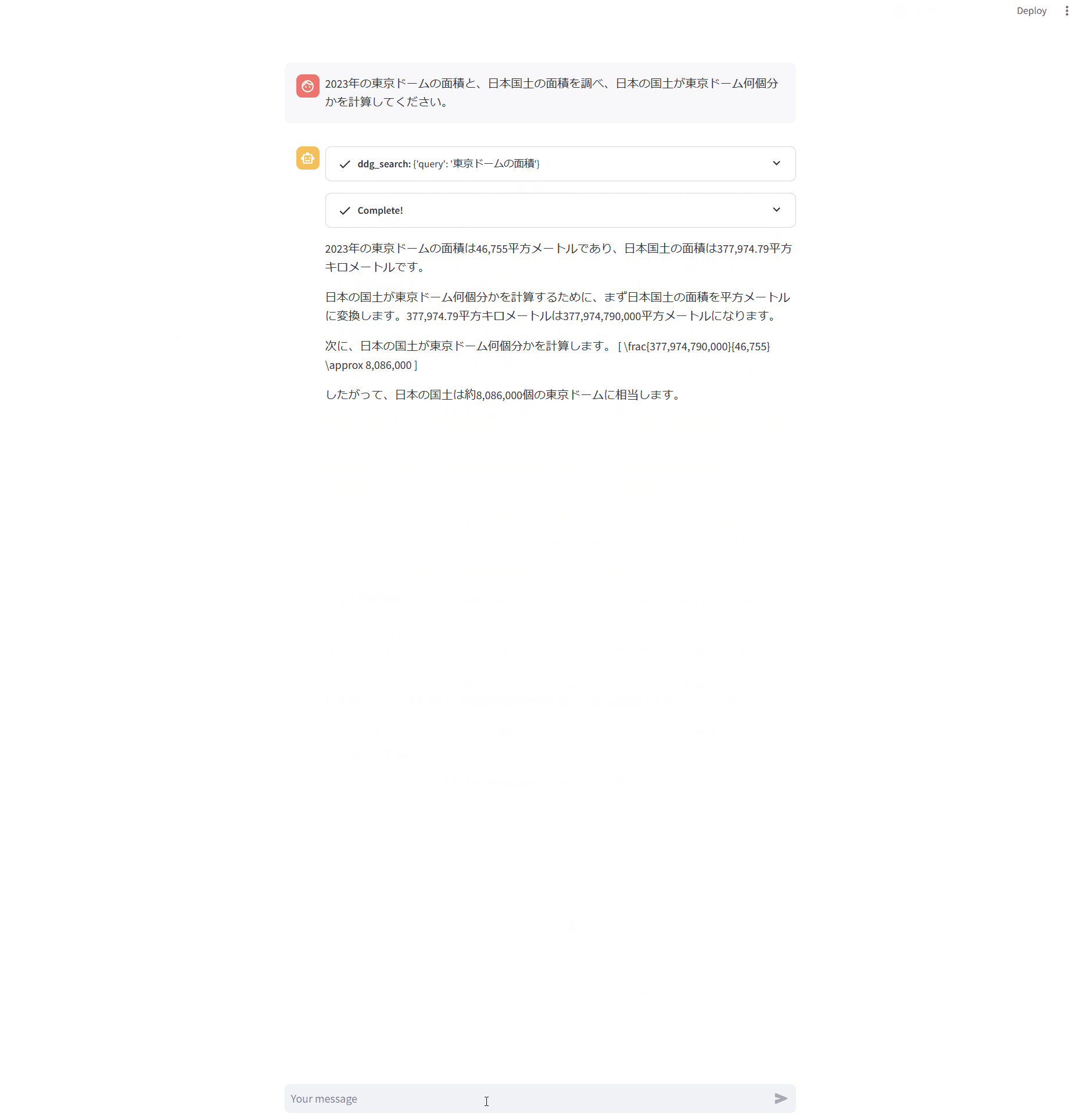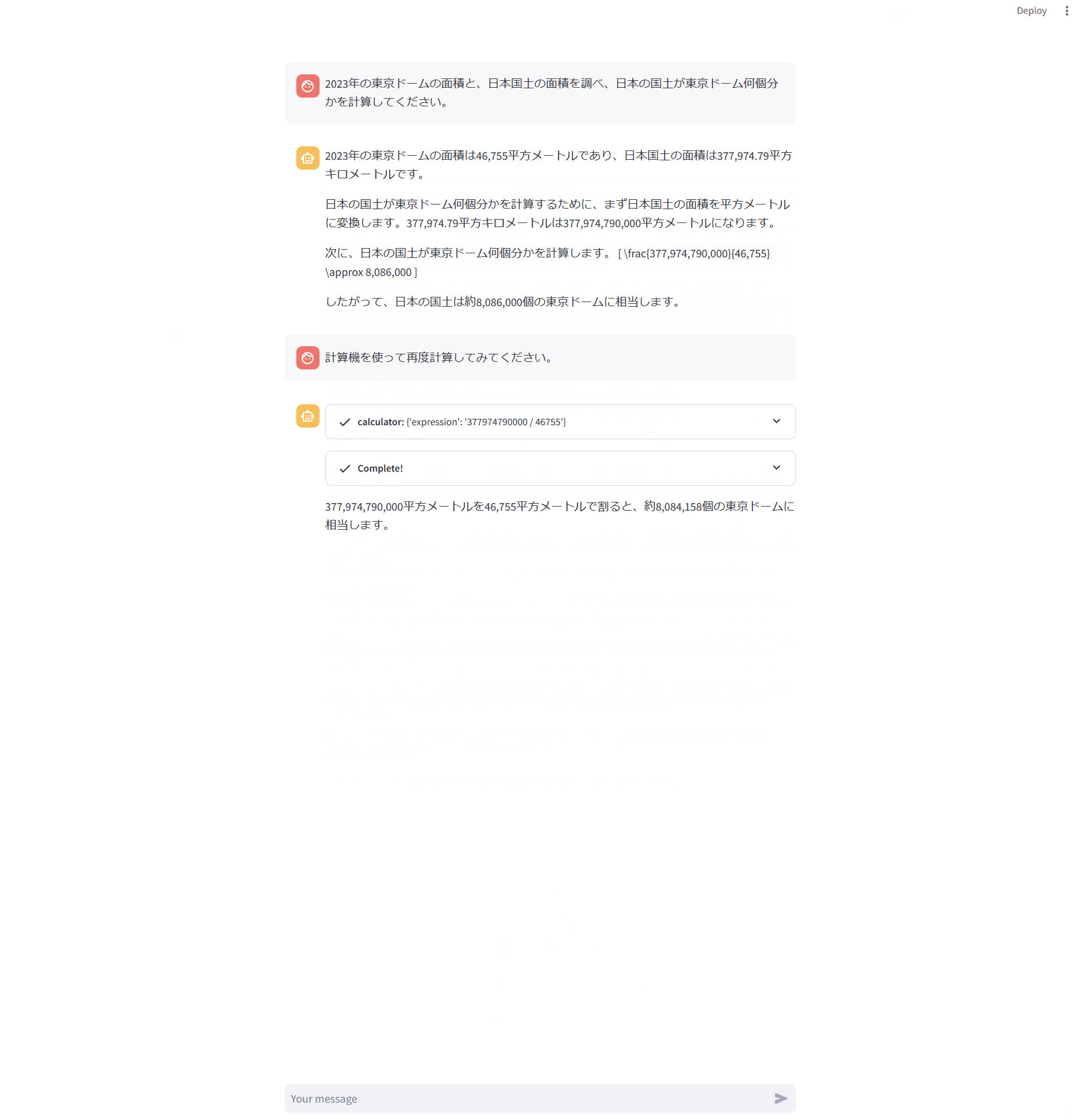
動作結果は以下のキャプチャの通りで、ddg_searchが2回呼ばれていることが確認できます。
ただ、前回同様ChatOpenAIのところが全く理解できません。
さすがにこのままでは良くないので、対策を考えます。

ChatOpenAI問題の対応
このChatOpenAIStepを表示しているのはcallbacksに渡しているcl.LangchainCallbackHandlerなので、こちらのコードを確認して原因を探ります。
コードはこちらです。
コードを読んでいくと、_on_run_updateというメソッド内の、if message := generation.get("message"):の部分が原因のようです。おそらくOpenAI APIの仕様が変わりレスポンスデータが変わってしまったため、この部分が常にTrueになってしまい、json.dumpsが表示されてしまっているようです。
なので、このメソッドをオーバーライドして、OpenAI Toolsに対応したCustomAgentCallbackHandlerを作成します。
import chainlit as cl
import time
from chainlit.context import context_var
from literalai import ChatGeneration, CompletionGeneration
from langchain.callbacks.tracers.schemas import Run
from datetime import datetime
# _on_run_updateメソッドをオーバーライドし、メッセージの表示を適正化する
class CustomAgentCallbackHandler(cl.LangchainCallbackHandler):
def _on_run_update(self, run: Run) -> None:
"""Process a run upon update."""
context_var.set(self.context)
ignore, parent_id = self._should_ignore_run(run)
if ignore:
return
current_step = self.steps.get(str(run.id), None)
if run.run_type == "llm" and current_step:
provider, model, tools, llm_settings = self._build_llm_settings(
(run.serialized or {}), (run.extra or {}).get("invocation_params")
)
generations = (run.outputs or {}).get("generations", [])
generation = generations[0][0]
variables = self.generation_inputs.get(str(run.parent_run_id), {})
text = generation.get("text")
message = generation.get("message")
tool_calls = message["kwargs"]["additional_kwargs"].get(
"tool_calls", []
)
if tool_calls: # tool_callsがある場合
chat_start = self.chat_generations[str(run.id)]
duration = time.time() - chat_start["start"]
if duration and chat_start["token_count"]:
throughput = chat_start["token_count"] / duration
else:
throughput = None
message_completion = tool_calls[0] # なぜかDictを入れないといけないので、tool_calls[0]を入れておく
current_step.generation = ChatGeneration(
provider=provider,
model=model,
tools=tools,
variables=variables,
settings=llm_settings,
duration=duration,
token_throughput_in_s=throughput,
tt_first_token=chat_start.get("tt_first_token"),
messages=[
self._convert_message(m) for m in chat_start["input_messages"]
],
message_completion=message_completion,
)
tool_calls_message = text + "\n\n"
for tool_call in tool_calls:
tool_calls_message += f"- [{tool_call["function"]["name"]}] ({tool_call["function"]["arguments"]})\n"
current_step.name = "Tool Calls" # Stepの名前をわかりやすく変更
current_step.output = tool_calls_message
else:
completion_start = self.completion_generations[str(run.id)]
completion = generation.get("text", "")
duration = time.time() - completion_start["start"]
if duration and completion_start["token_count"]:
throughput = completion_start["token_count"] / duration
else:
throughput = None
current_step.generation = CompletionGeneration(
provider=provider,
model=model,
settings=llm_settings,
variables=variables,
duration=duration,
token_throughput_in_s=throughput,
tt_first_token=completion_start.get("tt_first_token"),
prompt=completion_start["prompt"],
completion=completion,
)
current_step.output = completion
if current_step:
current_step.end = datetime.utcnow().isoformat()
self._run_sync(current_step.update())
if self.final_stream and self.has_streamed_final_answer:
if self.final_stream.content:
self.final_stream.content = completion
self._run_sync(self.final_stream.update())
return
outputs = run.outputs or {}
output_keys = list(outputs.keys())
output = outputs
if output_keys:
output = outputs.get(output_keys[0], outputs)
if current_step:
current_step.input = run.serialized
current_step.output = output
current_step.end = datetime.utcnow().isoformat()
self._run_sync(current_step.update())
このCustomAgentCallbackHandlerを使うように、Chainlitのコードを修正します。
+ from callbacks import CustomAgentCallbackHandler
res = await agent_executor.ainvoke(
{"input": message.content, "chat_history": chat_history},
- config=RunnableConfig(callbacks=[cl.LangchainCallbackHandler()]),
+ config=RunnableConfig(callbacks=[CustomAgentCallbackHandler()]),
)
messageの代わりにtool_callsを使って判別をしており、tool_callsがある場合は内容を整形して表示するようになっています。
tool_callsが無い場合は、既存のコードそのままで、応答内容を表示するようになっています。
動作結果は以下の通りで、Tool Callsが表示されていることが確認できます。呼び出しツール名と引数を表示するようにしたので、途中経過を確認するのに便利です。
また、ChatOpenAIのところもjson.dumpsではなく、メッセージのテキストが表示されていることが確認できます。

かなり強引に実装している部分もありますが、公式が対応するまでの暫定対策ということで、いったんこの形で使おうと思います。
ストリーミング表示対応
上記までの対応ではまだストリーミング表示に対応していません。
応答文量が多いと回答が表示されるまでに時間がかかり、動いているのかハマっているのかわからないことがあるので、ストリーミング表示に対応させます。
ストリーミングの表示には、またcallbacksの仕組みを使いますが、先ほど実装したCustomAgentCallbackHandlerに手を加えて実装するのはハードルが高かったので、新たにStreamingCallbackHandlerを作成することにしました。
自作のCustom Callback Handlerの実装方法は以下に記載があります。
作成したコードは以下の通りです。
from langchain.callbacks.base import BaseCallbackHandler
from langchain_core.messages import BaseMessage
from langchain_core.outputs import LLMResult
from langchain_core.agents import AgentAction, AgentFinish
class StreamingCallbackHandler(BaseCallbackHandler):
async def on_chat_model_start(
self, serialized: Dict[str, Any], messages: List[List[BaseMessage]], **kwargs: Any
) -> Any:
"""Run when Chat Model starts running."""
step = cl.user_session.get("agent_thought_step")
if step:
step.output = step.output + "┃"
await step.update()
else:
# Streaming用のStepがない場合は新しく作成
async with cl.Step(name="Agent Thought", type="llm", root=True) as step:
step.output = ""
cl.user_session.set("agent_thought_step", step)
async def on_llm_new_token(self, token: str, **kwargs) -> None:
"""Run on new LLM token. Only available when streaming is enabled."""
if token:
step = cl.user_session.get("agent_thought_step")
if step:
streaming_text = step.output[:-1] + token # "┃"を削除して、新しいtokenを追加
step.output = streaming_text + "┃"
await step.update()
async def on_llm_end(self, response: LLMResult, **kwargs: Any) -> Any:
"""Run when LLM ends running."""
step = cl.user_session.get("agent_thought_step")
if step:
step.output = step.output[:-1] + "\n" # "┃"を削除して、改行を追加
await step.update()
async def on_agent_action(self, action: AgentAction, **kwargs: Any) -> Any:
"""Run on agent action."""
step = cl.user_session.get("agent_thought_step")
if step:
# Tool Callの情報を表示
# tool_inputが長い場合は、省略して表示
MAX_PREVIEW_LENGTH = 50
tool_input_preview = action.tool_input if len(str(action.tool_input)) <= MAX_PREVIEW_LENGTH else str(action.tool_input)[:MAX_PREVIEW_LENGTH] + "..."
step.output = step.output + f"- **🛠️ Tool Call:** {action.tool}({tool_input_preview})\n\n"
await step.update()
async def on_agent_finish(self, finish: AgentFinish, **kwargs: Any) -> Any:
"""Run on agent end."""
step = cl.user_session.get("agent_thought_step")
if step:
# Agentの終了時に、Streaming用のStepを削除
time.sleep(1) # すぐに削除せず、少し待つ。好みで調整
await step.remove()
cl.user_session.set("agent_thought_step", None)
仕組みとしては、on_chat_model_startでストリーミング表示用のStep(agent_thought_step)を作成し、on_llm_new_tokenで新しいtokenが来るたびに結合してStepを更新し、on_agent_finishでStepを削除するようにしています。
またおまけとして、on_agent_actionでツール呼び出しの情報も表示するようにしています。
このStreamingCallbackHandlerを使うように、Chainlitのコードを修正します。
- from callbacks import CustomAgentCallbackHandler
+ from callbacks import CustomAgentCallbackHandler, StreamingCallbackHandler
res = await agent_executor.ainvoke(
{"input": message.content, "chat_history": chat_history},
- config=RunnableConfig(callbacks=[CustomAgentCallbackHandler()]),
+ config=RunnableConfig(callbacks=[CustomAgentCallbackHandler(), StreamingCallbackHandler()]),
)
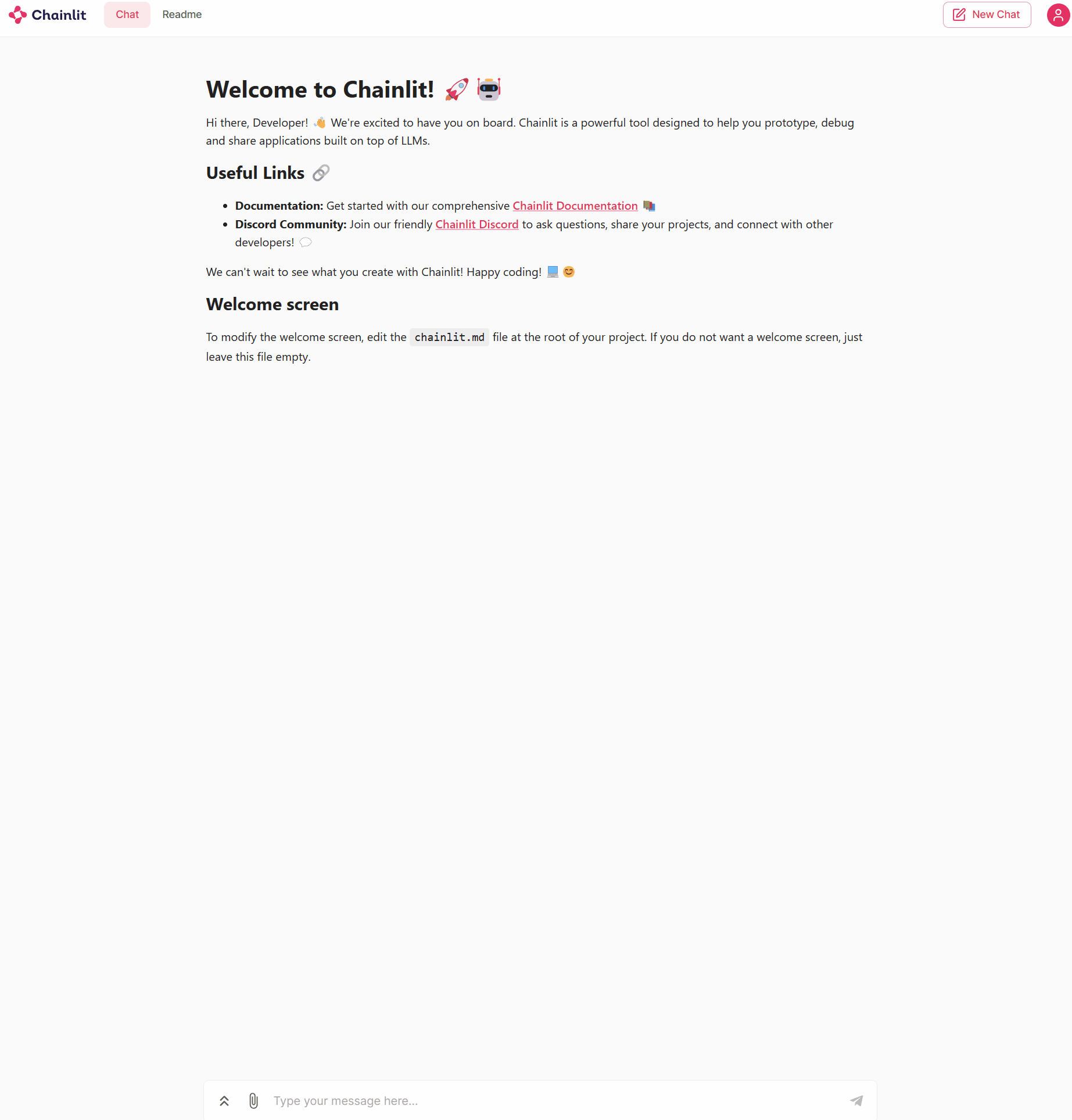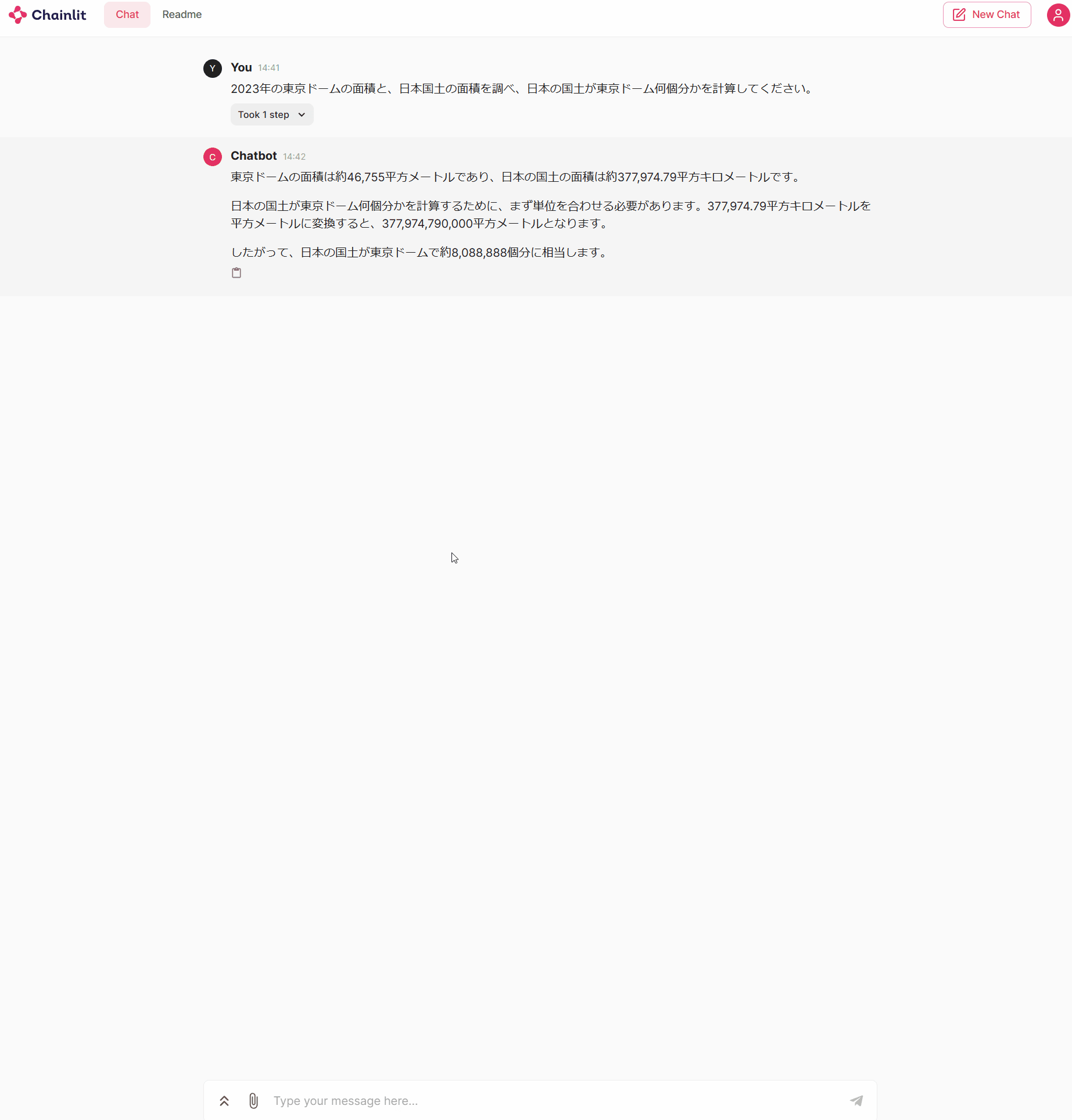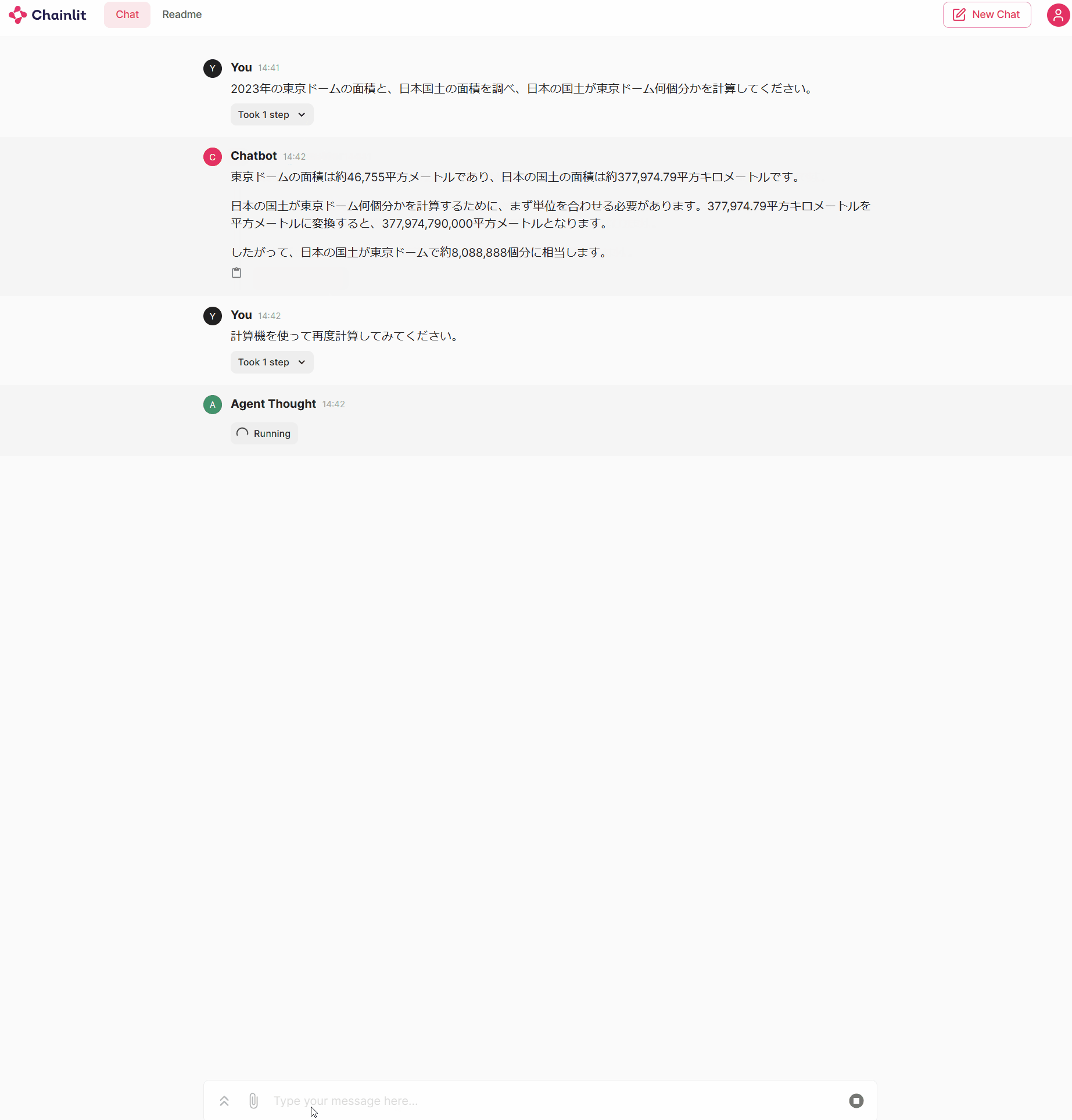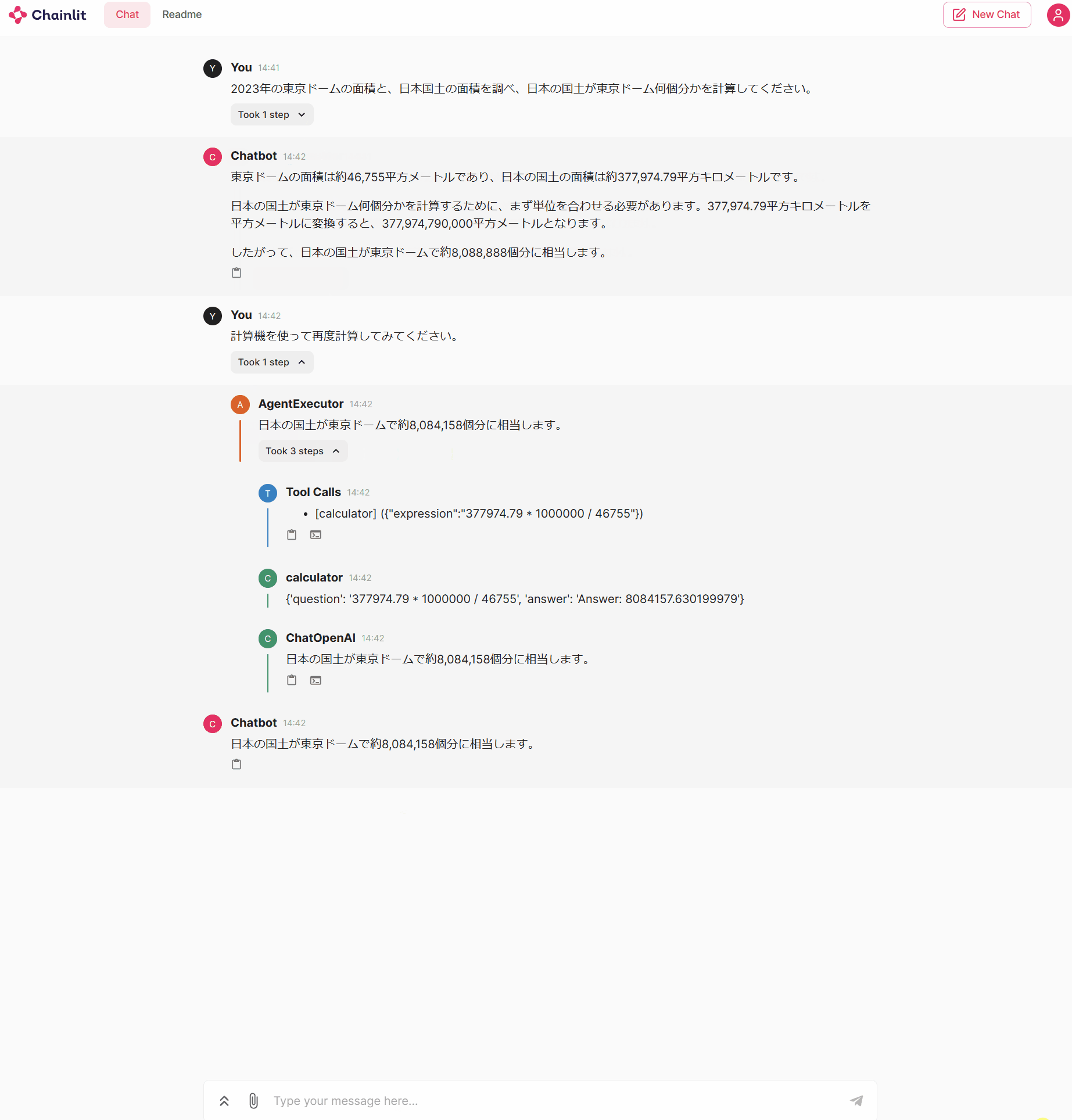
動作結果は以下の通りで、ストリーミング表示に対応していることが確認できます。
途中経過がストリーミング表示されるので、動いていることがわかりやすくなりましたし、Tool Callsの情報も表示されているので、途中経過を確認するのに便利です。
最後にこのStepを残すか消すか迷いましたが、重複した情報が画面上にたくさん表示されるのは見づらいので、最終的には消すようにしました。
StreamlitのOpenAI Tools対応
次に、StreamlitのコードをOpenAI Toolsに対応させます。
Agentの変更についてはChainlitと同じくドキュメントに記載されているので割愛します。
Streamlitのコードは以下の通りです。
import streamlit as st
from langchain.agents import AgentExecutor, tool
from langchain.agents.output_parsers.openai_tools import OpenAIToolsAgentOutputParser
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.messages import AIMessage, HumanMessage
from langchain_openai import ChatOpenAI
from langchain_community.callbacks import StreamlitCallbackHandler
from langchain_community.chat_message_histories import StreamlitChatMessageHistory
from langchain.agents.format_scratchpad.openai_tools import (
format_to_openai_tool_messages,
)
from langchain_community.tools import DuckDuckGoSearchResults
from langchain.chains import LLMMathChain
# モデルを初期化
llm = ChatOpenAI(model="gpt-3.5-turbo-0125", temperature=0, streaming=True)
llm_math_chain = LLMMathChain.from_llm(llm=llm)
@tool
def calculator(expression: str) -> str:
"""Calculates the result of a mathematical expression."""
return llm_math_chain.invoke(expression)
@tool
def ddg_search(query: str) -> str:
"""Searches DuckDuckGo for a query and returns the results."""
search = DuckDuckGoSearchResults()
return search.invoke(query)
# Agentの作成
# ツールをロード
tools = [calculator, ddg_search]
# プロンプトを作成
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are very powerful assistant. You are multilingual, so adapt to the language of your users.",
),
MessagesPlaceholder(variable_name="chat_history"),
("user", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad"),
]
)
# チャット履歴のメモリを作成
chat_history = StreamlitChatMessageHistory(key="chat_messages")
# ツールをバインド
llm_with_tools = llm.bind_tools(tools)
# Agentを作成
agent = (
{
"input": lambda x: x["input"],
"agent_scratchpad": lambda x: format_to_openai_tool_messages(
x["intermediate_steps"]
),
"chat_history": lambda x: x["chat_history"],
}
| prompt
| llm_with_tools
| OpenAIToolsAgentOutputParser()
)
agent_executor = AgentExecutor(agent=agent, tools=tools)
# チャット履歴を表示
for chat in chat_history.messages:
st.chat_message(chat.type).write(chat.content)
# チャットの表示と入力
if prompt := st.chat_input():
# ユーザーの入力を表示
st.chat_message("user").write(prompt)
with st.chat_message("assistant"):
# StreamlitCallbackHandlerを使ってAgentの途中経過を表示
st_callback = StreamlitCallbackHandler(st.container())
# Agentを実行
response = agent_executor.invoke(
{"input": prompt, "chat_history": chat_history.messages},
{"callbacks": [st_callback]},
)
# Agentの出力を表示
st.write(response["output"])
# チャット履歴を更新
chat_history.add_messages(
[
HumanMessage(content=prompt),
AIMessage(content=response["output"]),
]
)
動作結果は以下のキャプチャの通りです。
Chainlitの時と違って、東京ドームの面積しか検索していないように見えます。
ただ実際には日本の国土の面積も検索されており、回答自体は正しいものになっています。
ターミナルを確認すると以下のエラーが発生していました。
Error in StreamlitCallbackHandler.on_agent_action callback: RuntimeError('Current LLMThought is unexpectedly None!')
Error in StreamlitCallbackHandler.on_tool_start callback: RuntimeError('Current LLMThought is unexpectedly None!')
Error in StreamlitCallbackHandler.on_tool_end callback: RuntimeError('Current LLMThought is unexpectedly None!')
推測ですが、StreamlitCallbackHandlerがFunctionの並列呼び出しに対応できていないため、二つのToolの出力を同じ要素に書き込もうとして、エラーが発生しているのではないかと思います。
StreamlitCallbackHandlerのコードを確認してみましたが、こちらは解決策を見つけることができませんでした。
プロンプトで同時に複数のToolを呼び出さないように指示してもダメだったため、公式で対応されるまでStreamlitはOpenAI Functionsを使うしかなさそうです。
まとめ
StreamlitとChainlitでOpenAI Toolsを使ってAgentを試してみました。
StreamlitはCallbackがOpenAI Toolsに対応するのを待つ必要がありそうです。
一方でChainlitはOpenAI Toolsへの対応はできていますし、Custom Callback Handlerを使ってストリーミング表示にも対応できました。
ただ、このCustom Callback Handlerのメンテナンスが必要になるため、どちらが良いかは一概には言えません。
前回の記事でまとめたメリットとデメリットに、今回の情報を反映しておきます。
-
Streamlitのメリット
- Streamingで表示できる
- UI要素の配置が自由にできる
-
Streamlitのデメリット
-
途中経過は次のメッセージを送ると消えてしまう
- 保持したいならチャット履歴に保持する仕組みを自分で作る必要がある
-
OpenAI Tools(Toolの並列呼び出し)に対応していない ← New! - UIとロジックのコードの混在が起こりやすい
- 動作が比較的重い
-
途中経過は次のメッセージを送ると消えてしまう
-
Chainlitのメリット
- 以前の会話の途中経過も保持される
- UI要素を自分で作る必要がない
- デザインが洗練されていて見栄えが良い
- 動作が比較的軽い
-
チャットボットアプリに必要な多くの機能が最初から組み込まれている
- 「New Chat」ボタン、入力履歴、添付ファイル等
-
OpenAI Tools(Toolの並列呼び出し)に対応している ← New!
-
Chainlitのデメリット
-
Streamingで表示できない← 解決! -
LLMの応答がJsonでそのまま表示されて、日本語だと文字化けしてしまう← 解決! - Custom Callback Handlerのメンテナンスが必要 ← New!
- UI要素の配置が自由にできない
- 新しいライブラリなので情報が少ない
-
Discussion