Open Font Format(OFF)について読んでみたまとめ
読んだ文書
ISO[1]/IEC[2]規格のOpen Font Formatの文書。「Download」から2019年の規格と2020年の追加企画(たぶんカラーフォントについての文書)がダウンロードできる。
最近、次期規格がプロジェクトされたようなのでいずれは古いまとめになると思われる。
なお、OpenTypeはMicrosoftの商標であり、規格としてはOpen Font Formatなので以降はOFFと略する。
序文
OFFは、Appleが開発したTrueTypeフォントを拡張し、AdobeのPostScriptフォントのCompact Font Format形式のアウトラインデータをも使用できるようにした規格であり、OFFは先にあげた2つ(TrueTypeフォント、Compact Font Format)が使用できないOSやプラットフォームでも提供できるようにした形式である。
このへんはWikipediaにも記載されている。
あとはOFFが目指していることや、OFFに基づくフォントを使用するユーザーが形式(TrueTypeフォントとか、Compact Font Formatとか)を意識せずに使用できるようにしたいこと、レイアウトを自由にし、Unicodeなどの大規模文字セットに柔軟に対応することなどが記載されている。
1.規格の範囲
序文でも述べたOFFがTrueTypeやCompact Font Formatを含んでいることの言及。
2.参照している規格
ISO/IEC 10646
Universal Coded Character Set:Unicode互換のISO/IEC規格
ISO/IEC 14496-18
音声/動画(特にMPEG-4)におけるフォントの圧縮とストリーミングのISO/IEC規格
ISO/IEC 15948
Portable Network Graphics(PNG画像)のISO/IEC規格
IEC 61966-2-1/Amd 1:2003
標準色空間(sRGB)のIEC規格
TrueType Instruction Set
MicrosoftによるTrueTypeの仕様書
Unicode 11.0
Unicode は現在(2023.11 時点)すでにUnicode 15.1がリリースされていることに注意
Scalable Vector Graphics (SVG) 1.1 (Second Edition)
IETF BCP 47 specification, “Tags for Identifying Languages"
3.用語と定義、略語について
3.1.用語と定義
この定義書では新たに定義はしていないので、気になったことはISOやIECのデータベースで調べてください、とある。
正直、知らないことだらけだから仕様書を見てるのにこれは非常に困る。
3.2.使用する略語について
いろいろ略語が書いてあったが一部しか使用していないものも多かったのでここで使用しそうなものだけ
- ANSI
ここでは3つの意味がありうるので文脈に注意が必要。- 米国国家規格協会(American National Standards Institute)の略。仕様書ではたいていの場合これを指している。
- Windowsコード ページ のこと。
旧来、ANSI規格で定義された文字集合をWindows上で定義したが規格にのっとっておらず、また各国の標準文字セットにANSIと表示していたらしい。Windows ANSIという文字列を見つけたのでこちらも文章上に存在している。 - Microsoftコードページ932(CP932) のこと。
Windowsコードページの誤解により、日本ではANSIがCP932を参照していたため、そう呼ばれているらしい。とてもややこしい。
ちなみにCP932はShift_JISとある程度の互換があるため、Shift_JISをANSIと呼んでいる場合もある。
- BMP
ここでは2つの意味がありうるので文脈に注意が必要。- 基本多言語面のこと。Unicodeの用語でU+0000~U+FFFF(仕様としてはU+FFFDが最後)に配置されている文字のことをいう。仕様書ではたいていの場合これを指している。
- ビットマップ画像のこと。OFFではアウトライングリフ(ベクター画像で字形を表現する方法)とビットマップグリフ(ビットマップ画像で字形を表現する方法)がある。
- BTBD
ベースライン間の距離 - CFF
PostScriptフォントのCompact Font Format形式のアウトラインデータのこと - CID
ここでは2つの意味がありうるので文脈に注意が必要。- CID(キャラクタID)のこと。字形ひとつひとつに識別番号を割り振り、言語と文字コードと字形の組み合わせを作ることで同一文字コードの異体字を表現できるようにする方法。この組み合わせ表のことCMapと呼び、同じ文字でも言語セットごとに表示される文字が異なるのはこの仕組みを使用している。仕様書ではたいていの場合これを指している。
- CIDの仕組みを利用したPostScriptフォントのことをCIDフォントと呼ぶ
- CJK, CJKV
漢字のこと。歴史上、漢字は中国(C)、日本(K)、韓国(K)、ベトナム(V)を中心とした地域で使用されていたためこのように表現する。 - GID
TruTypeやOFFで使用するCIDのこと。 - ICF
平均字面のこと。文字を上下に揃える場合、3つの手法が存在する- 欧文基準
たとえば英語アルファベットの場合、大文字Xの上端を通る「アセンダライン」、小文字xの上端を通る「ミーンライン」、小文字xの下端を通る「ベースライン」、小文字gの下端を通る「ディセンダライン」の4つの基準が存在するが、一般的にはベースラインを基準に揃えて表示する。[1]
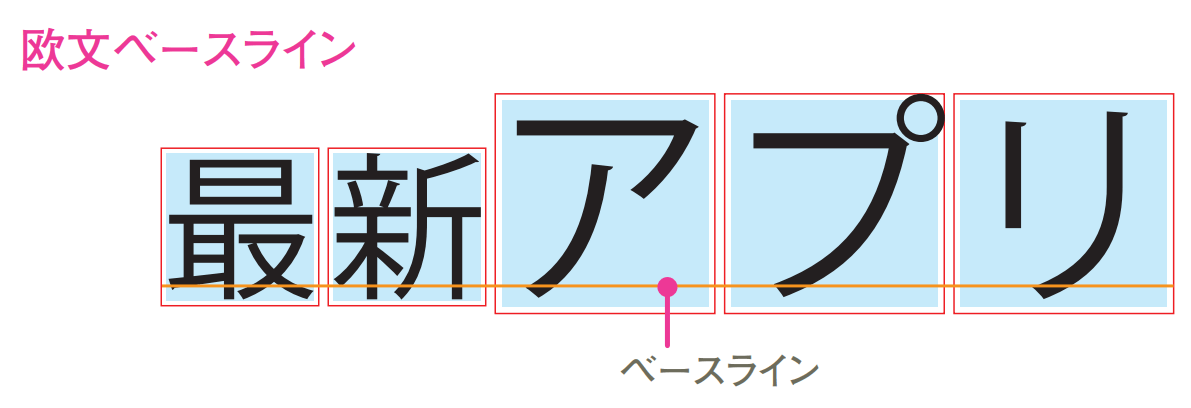
- 字形の最大位置基準
フォント内の字形で最大の文字の一番外側に揃える方法がある。この時に揃える線(一番外側)を「仮想ボディ」と呼び、この仮想ボディの外に文字ははみ出すことができない。[2]
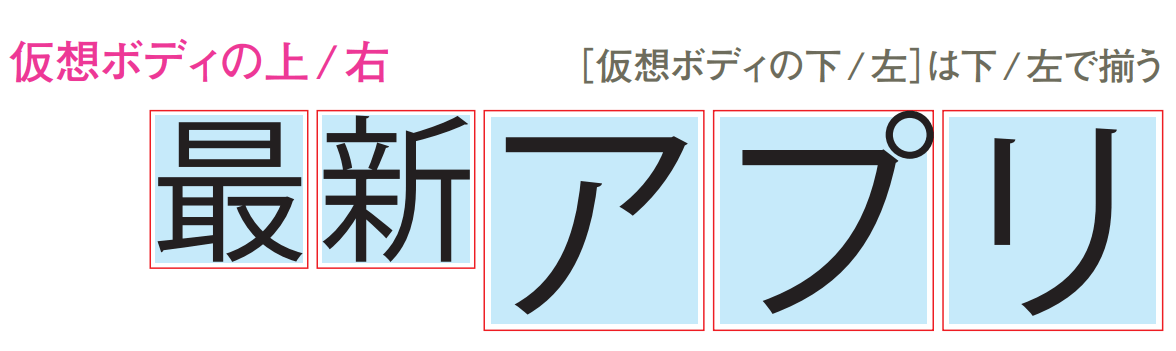
- 平均字面基準
フォント内の全字形での平均に揃える方法がある。この時に揃える線を「平均字面」といい、平均であるため「仮想ボディ」よりは当然内側になる[3]
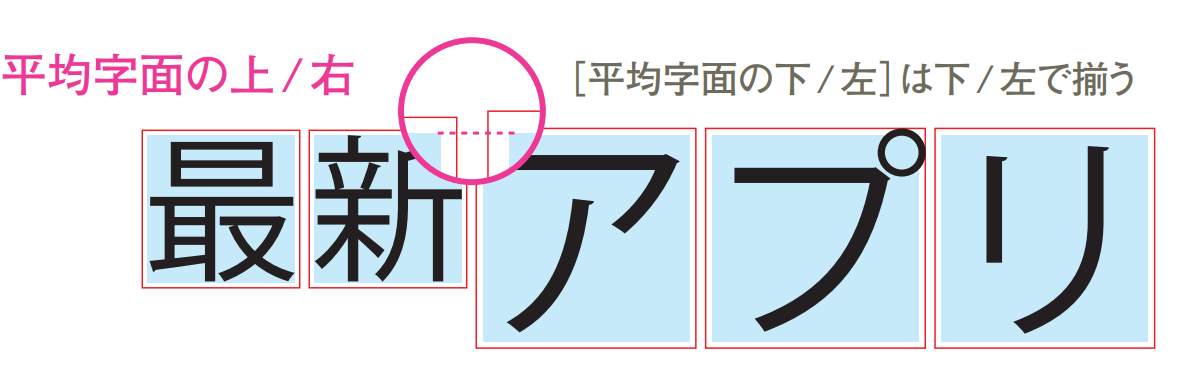
- 欧文基準
-
画像は「世界一わかりやすい InDesign 操作とデザインの教科書」より引用 ↩︎
-
同じく ↩︎
-
同じく ↩︎
- LTR
左書き(Left to Right)のこと - NRC
日本の文化審議会国語分科会(旧:国語審議会)のこと。 - OMPL
鏡文字対応表[1](OpenType Mirroring Pairs List)。
例えば括弧((や))は、右書き、左書きと同じ字形が使えない。たとえば(abc)が右書きになると)cba(のようになってしまう。
これを対応するには、字形をそのまま反転させる方法もあるだろうけれども、OFFでは文字コードが参照すべきGIDを入れ替えて対応しているらしい。
どういうことかというと、U+0028((例えばGID:1)とU+0029()例えばGID:2)は対であることを示した表を用意する。左書きの場合はU+0028は(、U+0029は)と出力するが、右書きの場合は対応している文字コードの持つGIDを参照するのでU+0028は)、U+0029は(を表示する。
この対応表がOMPLらしい。OMPLはMicrosoftが公開している。
仕様書上にも「Annex C」(596頁)に収録されている。
- PCL
Printer Control Languageの略。HP社が開発したページ記述言語(プリンタへ指示するためのプログラミング言語)のこと。 - PPM, PPEM
ピクセル(単位:px)を字幅(単位:em)で割った数字。
フォントサイズの変換式[2]に基づいている。
- RTL
右書き(Right to Left)のこと。 - UVS
異体字シーケンス(Unicode variation sequence)のこと。
前提として同じ字でも複数の字形が存在する場合に、文字の後ろに選択子を付与することで別の字形を指定する方法があり、この選択子のことを「異体字セレクタ」という。[3]

異体字セレクタはUnicodeでは「U+FE00〜U+FE0F」及び「U+E0100〜U+E01EF」に割り振られており、それぞれ「VS1,VS2,……,VS256」と通番が割り振られている。この通番のことを「異体字シーケンス」と呼んでいる。
4.OpenFontファイル(Open Font File Formatについて)
4.1.説明
OpenFontファイルは、TrueTypeフォントやAdobeのPostScriptフォントのCompact Font Format形式といった文字のアウトラインデータをレンダリングすることでラスター画像(≒ビットマップ画像)に変換している。このアウトラインデータは表形式で管理している。
……といったことを説明に書いてあると思う(微妙にニュアンスがわからなかった)
仕様としての概要なので読み飛ばしても問題はないかなぁと。
ちなみに、この規格ではUniversal Coded Character Set(≒Unicode)にのみ対応しており、UCCSに批准していないOFFは規格の対象にならないらしい。たぶん。
4.2.ファイル名
拡張子は.OTF、.TTF、.OTC、.TTCの4つ。
簡単に説明は書いてあったが、後に解説があるらしいのでここでは省略。(8.4.を参照)
4.3.データ型
扱うデータ型は下記の通り。
| データ型 | 説明 | 長 |
|---|---|---|
| uint8 | 符号なし整数型 | 8 bit |
| uint16 | 符号なし整数型 | 16 bit |
| uint24 | 符号なし整数型 | 24 bit |
| uint32 | 符号なし整数型 | 32 bit |
| int8 | 符号あり整数型 | 8 bit |
| int16 | 符号あり整数型 | 16 bit |
| int24 | 符号あり整数型 | 24 bit |
| int32 | 符号あり整数型 | 32 bit |
| Fixed | 符号あり固定小数点型 | 32 bit (整数部16 bit、小数部16 bit) |
| UFWORD | フォントデザイン用のuint16(符号なし整数型) | 16 bit |
| FWORD | フォントデザイン用のint16(符号あり整数型) | 16 bit |
| F2DOT14 | 符号あり固定小数点型 | 16 bit (整数部2 bit、分数部14 bit) |
| LONGDATETIME | タイムスタンプ型。1904年1月1日[1]0時を基準にミリ秒で扱う | 64 bit |
| Tag | タグ型。テーブル、デザインバリエーション軸、スクリプト、言語システム、機能、ベースラインなどを識別するために使用~とあるが多分後述 | 32 bit (uint8 x 4 の 配列) |
| Offset16 | 表のオフセット。nullは0x0000として扱う | 16 bit(uinit16と等価) |
| Offset32 | 表のオフセット。nullは0x00000000として扱う | 32 bit(uinit32と等価) |
バイトオーダーはすべてビックエンディアンで扱うらしい。(規格としては「ネットワーク・バイト・オーダー」を基準にしているらしい)
F2DOT14
F2DOT14は下記で表現される。
0x3FFFは14 bit全部1の値のこと。
Tags
Tagsは極端に言うとASCII[2](0x20~0x7E)から4字で構成されるuint8配列の変数。
大文字と小文字は区別され、スペース(0x20)が配列に入っている場合、後続の文字も必ずスペースになる。
-
私は知らなかったがMacintoshでは日付システムの基準日は1904年1月1日らしい。へぇ。
https://learn.microsoft.com/ja-jp/office/troubleshoot/excel/1900-and-1904-date-system ↩︎ -
正しくはUnicodeの基本ラテン文字に該当する文字をUTF-8で扱う。 ↩︎