AKS ScaleDown mode の違いによって、どのくらい所要時間が変わるのか?
AKS にて、スケールダウン時にノードを削除ではなく割り当て解除に機能がプレビュー提供されました。
その効用は
スケールダウン モードを使用すると、ノードを事前にプロビジョニングしたり、コンテナー イメージを事前にプルする必要がなくなるため、コンピューティング コストを削減できます。
とのことで、後者については結構イメージ付くのですが、前者がどれくらい効果があるのか気になったので、実際にやってみました。
環境・準備
- Azure Kubernetes Service (v1.21.9)
- Windows 10
- Windows PowerShell
- Azure CLI (v2.30.0)
- kubectl (v1.22.2)
プレビュー機能を使う準備
公式ドキュメントの「aks-preview CLI 拡張機能をインストールする」「AKS-ScaleDownModePreview プレビュー機能を登録する」を実施しておきます。
リソースグループ名とクラスター名の変数登録
PowerShell にて、下記を実行して変数に登録しておきます。
$RGNAME = <リソースグループ名>
$CLNAME = <クラスター名>
やってみた
下記のような操作に要する時間を測ってみました。
- ノードプールの作成 (6 ノード)
- ノード数を減らす (6 -> 1)
- ノード数を増やす (1 -> 6)
- ノード数を減らす (6 -> 1)
- ノード数を増やす (1 -> 6)
ノードプールの作成
「削除」モード (Delete)
ノードプール作成時の --scale-down-mode で Delete を指定します。
az aks nodepool add --node-count 6 --scale-down-mode Delete `
--node-osdisk-type Managed --max-pods 10 --name nodepool2 `
--cluster-name $CLNAME --resource-group $RGNAME
「割り当て解除」モード (Deallocate)
ノードプール作成時の --scale-down-mode で Deallocate を指定します。
az aks nodepool add --node-count 6 --scale-down-mode Deallocate `
--node-osdisk-type Managed --max-pods 10 --name nodepool3 `
--cluster-name $CLNAME --resource-group $RGNAME
ノード数を減らす (6 -> 1)
モードに依らず共通です (ノードプール名は合わせる必要があります)。
az aks nodepool scale --node-count 1 --name nodepool<n> `
--cluster-name $CLNAME --resource-group $RGNAME
ノード数を増やす (1 -> 6)
モードに依らず共通です (ノードプール名は合わせる必要があります)。
az aks nodepool scale --node-count 6 --name nodepool<n> `
--cluster-name $CLNAME --resource-group $RGNAME
時間を測るために
date コマンドで囲うことで実行前後の日時を取得し、差分を取りました。
例
date; az aks nodepool scale --node-count 1 --name nodepool<n> `
--cluster-name $CLNAME --resource-group $RGNAME; date
実験結果 1
| 実行内容 | 「削除」モード (秒) | 「割り当て解除」モード (秒) |
|---|---|---|
| 1. ノードプールの作成 (6 ノード) | 159 | 156 |
| 2. ノード数を減らす (6 -> 1) | 94 | 95 |
| 3. ノード数を増やす (1 -> 6) | 156 | 187 |
| 4. ノード数を減らす (6 -> 1) | 96 | 97 |
| 5. ノード数を増やす (1 -> 6) | 156 | 186 |
考察
お…おや…全然効果が無い、というかむしろ悪くなっていますね…
調べてみた
ノードの状況を見てみると、下記のことが分かりました。
ノードが削除されてしまっている
スケールダウン後の状況は、下記の通りです。
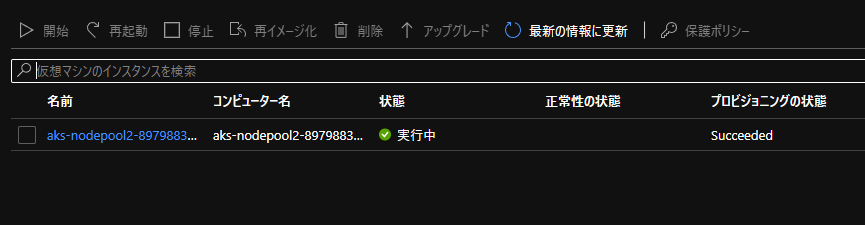
- 「削除」モードの場合
- 「割り当て解除」モードの場合
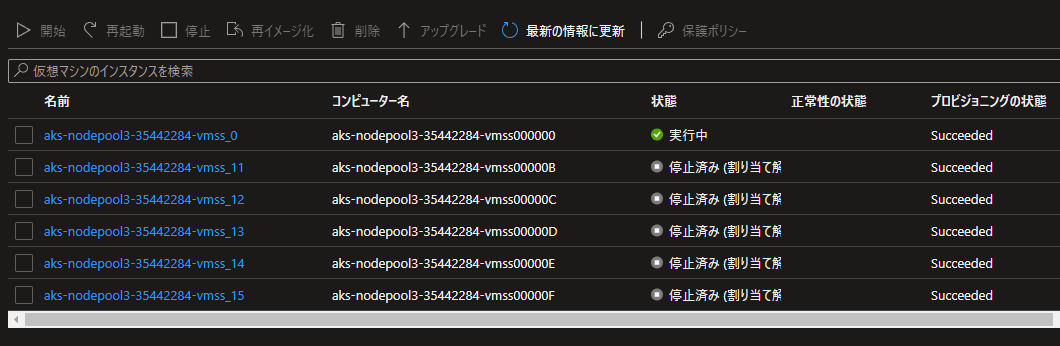
この状況は下記の抜粋の通り、(後述の一点を除き) 想定通りかなと思います。
--scale-down-mode Deallocate を設定すると、クラスターやノード プールのスケールダウン中にノードの割り当てが解除されます。 すべての割り当て解除されたノードが停止されます。
ですが、若干気になるポイントとして、ノードの名前がインクリメントされており、どうやら新しく作られているっぽい感じがします。
そこで、もう一度スケールアップ時の動作を見てみると、ノードが削除されてしまっていることがわかりました。それがわかる画面ショットがこちら。
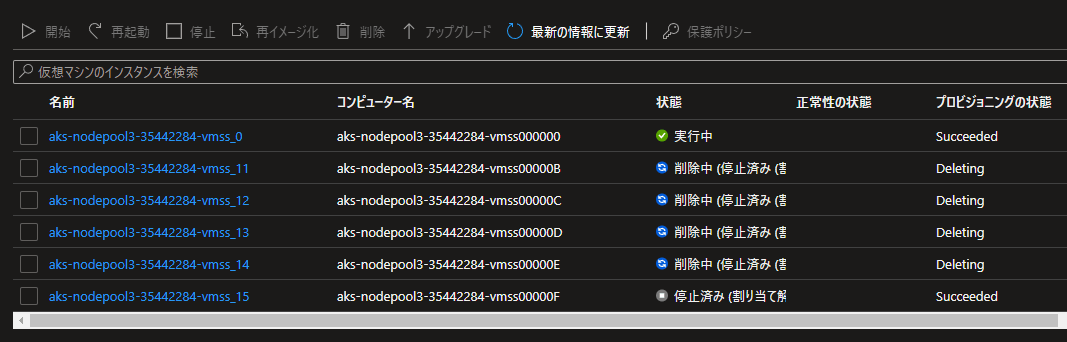
ものの見事に削除されてしまっています。これは、公式ドキュメントの下記の記述とは異なる状況です。
クラスターやノード プールをスケールアップする必要がある場合は、新しいノードがプロビジョニングされる前に、割り当て解除されたノードが最初に起動されます。
この後、ノードが新しく作成されます。ノード名を見るとお分かりの通り、インクリメントされていますね。
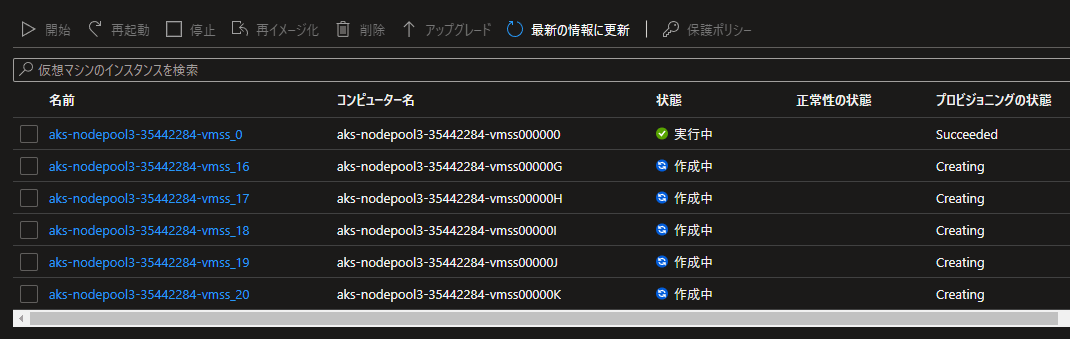
この削除処理があるおかげで、「削除」モードよりも時間がかかっているわけですね (「削除」モードの場合は上図の通りスケールダウン時に削除されるため)。
原因
2022年3月5日更新
本件、サポートに確認したところ不具合のようです。現在修正を順次デプロイする予定とのこと。
2022年3月14日更新
サポートから連絡があり、本件の改修がデプロイされたとのこと!
実験結果 2
本件の改修がデプロイされたとのことで、さっそく試してみました。
その結果がこちら。今回あらためて試したのは「割り当て解除」モードの箇所のみです。
| 実行内容 | 「削除」モード (秒) | 「割り当て解除」モード (秒) |
|---|---|---|
| 1. ノードプールの作成 (6 ノード) | 159 | 217 |
| 2. ノード数を減らす (6 -> 1) | 94 | 95 |
| 3. ノード数を増やす (1 -> 6) | 156 | 96 |
| 4. ノード数を減らす (6 -> 1) | 96 | 95 |
| 5. ノード数を増やす (1 -> 6) | 156 | 127 |
考察
期待通りですね! 3. や 5. といった、ノードを増やすための時間が短縮されています。
ノードを減らした時点では、下記の画面ショットのように削除ではなく起動していない状態となっており、再起動を行った際もノード名はインクリメントされませんでした。
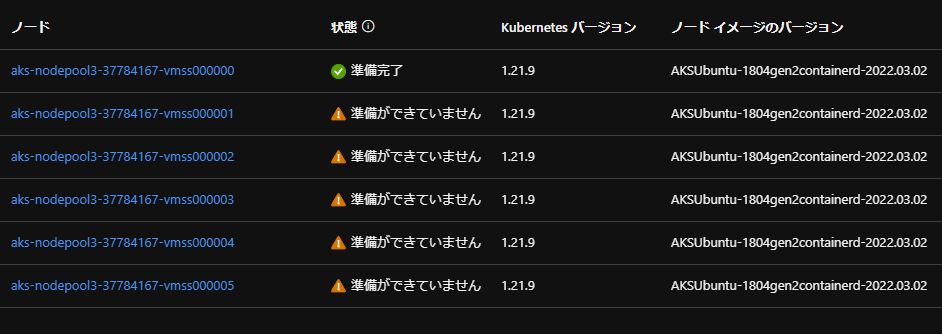
注意点としては、ノードの「状態」が 準備ができていません になり、ノードプールの状態も 1/6 といった出力をされるところでしょうか。この値を使って死活監視等を行っている場合には注意が必要そうですね。

また、当然ながらノードは削除されませんので、起動していないとはいえディスク等の課金は継続して発生することになります。不要となったノードは削除するといった対応も必要に応じて実施しなければなりませんね。
まとめ
このように、ノードプールのスケールダウンモードの変更によって、ノードを増やすための時間を短縮することができました。
まだプレビュー段階ではありますが、できる限りノードのスケーリング時間を短くしたい場合は検討に値する機能ですね!
Discussion