PrismaとPlanetScale
Prismaは次世代のORM。以下のコンポーネントを含む:
- Prisma Client: Node.js & TypeScript向けの自動生成されるタイプセーフなクエリビルダ。
- Prisma Migrate: 専用のマイグレーションツール
- Prisma Studio: データベースを表示・操作するためのGUI
Prismaは専用のスキーマ言語を備える。Prisma Schemaはアプリケーションモデルの定義 (Data model) に加えて、データベースへのコネクションの定義 (Data source) と生成するPrisma Clientの定義 (Generator) を含む。
Prisma data model
PrismaのデータモデルはModelのコレクションからなる。データモデルはPrism Schemaに直接記述してPrisma Migrateによってデータベースに反映するが、Introspectionによってデータベースからデータモデルを生成することもできるようだ。
Introspectionについては今回は追わないため、 Prisma Client と Prisma Migrate を中心としたワークフローについて学んでいく。
Accessing your database with Prisma Client
とりあえず例に従って npx prisma generate してみる。
✔ Installed the @prisma/client and prisma packages in your project
✔ Generated Prisma Client (3.11.1 | library) to ./node_modules/@prisma/client in 52ms
コード生成された結果は ./node_modules/.prisma/client に配置されていて、 @prisma/client の実装がこの位置にコード生成された結果が存在することを前提として参照している。 node_modules/ 以下そういう風にも使えるんですねえ… (参考)
これによって以下のようなクエリをタイプセーフに発行できる:
import { PrismaClient } from '@prisma/client'
const prisma = new PrismaClient()
const allUsers = await prisma.user.findMany({
include: { posts: true },
})
Is Prisma an ORM?
To answer the question briefly: Yes, Prisma is a new kind of ORM that fundamentally differs from traditional ORMs and doesn't suffer from many of the problems commonly associated with these.
Traditional ORMs provide an object-oriented way for working with relational databases by mapping tables to model classes in your programming language. This approach leads to many problems that are caused by the object-relational impedance mismatch.
Prisma works fundamentally different compared to that. With Prisma, you define your models in the declarative Prisma schema which serves as the single source of truth for your database schema and the models in your programming language.
従来のData Mapperパターンではホストのプログラミング言語のデータモデル (に @Entity や @Column でアノテーションしたもの) と関係データベースのマッピングを行うが、PrismaではPrisma Schemaファイルを中心として、自動生成されるTypeScriptのデータ型、Prisma Clientの関数を用いる。 またPrismaではマイグレーションもPrisma Schemaから導出される (他のORMでは、.NETのEntity FrameworkやDjangoのmakemigrationsも似たようなことが出来る)。
Prisma SchemaにおけるモデルはデータベースモデルやActive Recordパターンのモデルとは少し毛色が異なる。
model Post {
id Int @id @default(autoincrement())
title String
content String? @map("post_content")
published Boolean @default(false)
author User? @relation(fields: [authorId], references: [id])
authorId Int?
}
model User {
id Int @id @default(autoincrement())
email String @unique
name String?
posts Post[]
}

Prisma Schemaのモデルでは、データベースのスキーマの定義と対応するPrisma Client上での表現が共に表現されている。例えば、2つの関係フィールド author および posts としてモデル間の1:Nの関係が定義されているが、これはデータベース上のテーブルには存在しない ((Annotated) relation fields)。一方で、Foreign keyとなる authorId が @relation 属性によって指定されている (Relation scalar fields)。指定されたフィールドはPrisma Client上ではread-onlyとなる。
Prisma Schema
Prisma Schemaで一番面白いところは Is Prisma an ORM? で既に取り上げた。
最初に書いたように、Prismaは prisma generate や prisma migrate (または prisma db push) でPrisma Clientのコード生成やデータソースへの反映を行うので、Prisma Schemaはこれらの定義を含む。
datasource db {
url = env("DATABASE_URL")
provider = "postgresql"
}
generator client {
provider = "prisma-client-js"
}
あとRelationsはPrisma Schemaが実際どう書かれるかというのが見えてくる。個人的な所感として、One-to-manyでもimplicitに出来そうではあるけどjoinが発生するか暗黙のフィールドが生えるかというところのトレードオフから出来ないようにしたのかなとか。
Prisma Clientについては、柔軟でType-safeなクエリビルダが得られるということで後でTypeScriptの生成結果をもう少し追ってみたいと思うが、Prisma Migrateの方をまず追ってみる。
Prisma Migrate
Prisma MigrateはPrismaと統合されたマイグレーションツール。こちらも Is Prisma an ORM? で取り上げたが、Prismaは常に Prisma SchemaをSource of truthとする…最新のスキーマとして解釈する ので、Prisma Schemaの 変更の検知 からマイグレーションヒストリを生成する形になる。
マイグレーションヒストリは生のSQLで、このSQLがデータモデルの 変更履歴のSource of truth となる。Prisma Schemaの変更の検知からは汲み取れない変更があったときは、この生成されたSQLを直接編集することになる (例えば、フィールドのリネームはデフォルトではdrop columnとadd columnによる差分として検知される)。
具体的なワークフローについてはCLIコマンドの動作を知るとわかりやすいが、先に3つの歴史上のポイントを把握しておきたい。
- (A) Prisma Schema:
スキーマのSource of truthで、目指す状態 - (B) マイグレーションヒストリを全て適用したときのスキーマ:
Aとの差分が 新たに生成されるマイグレーションファイル(SQL)となる - (C) 実際のデータソースの現在のスキーマ:
マイグレーションヒストリにデータソースに未適用のマイグレーションがある場合、CはBより古くなる
これらを考慮して、以下の一部のコマンドはshadow databaseという使い捨てのデータベースを用いる。
The shadow database is created and deleted automatically each time you run a development-focused command and is primarily used to detect problems such as schema drift.
prisma migrate dev [--create-only]
開発環境向けのマイグレーション適用&生成コマンド。以下のような動作をする:
- マイグレーションヒストリを最初からshadow database上でリプレイし、Cとの不整合を検知する。不整合があるときは、Prisma外でマイグレーションヒストリやデータソースのスキーマへの変更が起こっている。
- 新しいマイグレーションを生成する。1が終わるとshadow databaseのスキーマはBに追いつくので、Aとの差分を計算してマイグレーションヒストリにSQLとして出力できる。
- (
--create-onlyが指定されていない場合) データソースに未適用のマイグレーションを適用していく。- 既存のマイグレーションに未適用のものがあれば、まずそれが適用されることでデータソースのスキーマはBに追いつき、
- 次に2で生成されたマイグレーションを適用することで、データソースのスキーマはAに追いつく。
- 変更履歴を保持する
_prisma_migrationsテーブルも更新する。
-
prisma generate相当の関連するコード生成などをトリガーする
prisma migrate deploy
こちらは本番環境向けのマイグレーション適用コマンド。このコマンドはPrisma Schemaを参照せず、マイグレーションヒストリからデータソースに未適用のマイグレーションを順に適用していく。
(適用済みのマイグレーションとマイグレーションヒストリとの間に不整合が検知された場合は事前に警告される)
prisma db push
prisma migrate 系のコマンドと異なり、 _prisma_migrations テーブル、およびマイグレーションヒストリに頼らず、データベースのスキーマとPrisma Schemaを比較して差分を推論し、その変更を実行する。 (その後 prisma migrate dev と同様に prisma generate 相当の関連するコード生成などをトリガーする)
データロスが発生する場合は --accept-data-loss オプションを必要とする。
この後追っていくPlanetScaleを使う場合は db push が推奨されている。
PlanetScale
この記事がよくまとまっていて良かった。
Branching
ブランチ機能。コードをブランチで管理するように、PlanetScaleはデータベーススキーマをブランチで管理できる。
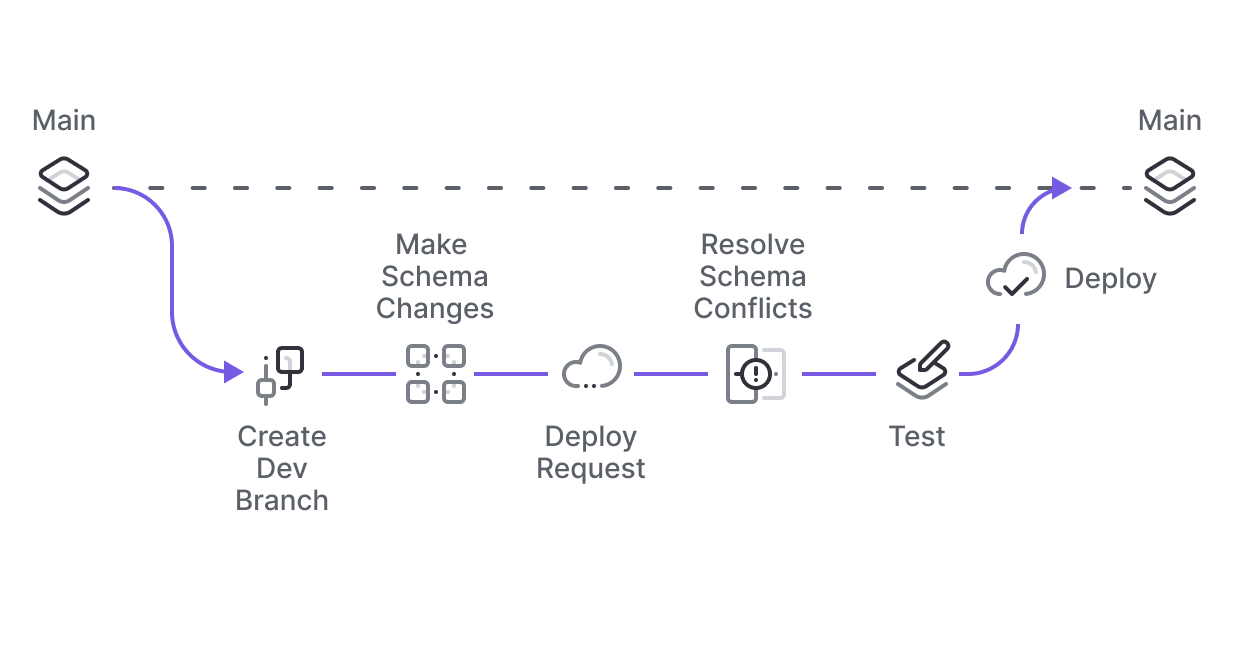
ブランチは最初はDevelopment branchで、promoteによってProduction branchとすることができる。Production branchは高い可用性と自動的なバックアップを伴い、スキーマの直接の変更がプロテクトされており変更にはdeploy requestを要する。
Online Schema Change
Prisma and PlanetScale
参考:
prisma migrate を色々と追ってきたがPlanetScaleでは prisma db push の使用が推奨される。ブランチのmerge時にはPlanetScale自身がスキーマを比較してdiffを計算するため、Prisma Migrateによるマイグレーションは実際のスキーマの変更を反映しない。
PlanetScale provides Online Schema Changes that are deployed automatically when you merge a deploy request and prevents blocking schema changes that can lead to downtime. This is different from the typical Prisma workflow which uses
prisma migratein order to generate SQL migrations for you based on changes in your Prisma schema. When using PlanetScale with Prisma, the responsibility of applying the changes is on the PlanetScale side. Therefore, there is little value to usingprisma migratewith PlanetScale.
また、PlanetScaleはForeign keyをサポートしない。PrismaではReferential actionsによってデフォルトで参照整合性(Referential integrity)が保たれるが、参照整合性の維持にはデフォルトで "foreignKeys" を用いるためそのままだとPlaenetScaleでは動作しない。現在はプレビュー機能だが、Prismaの参照整合性のエミュレート機能を有効にすることができる。現在のところ参照整合性をエミュレートする設定のときはインデックスは自動で生成されないため、パフォーマンスのためインデックスの指定が必要な場合もある。
Vercel and Prisma and PlanetScale
参考:
Vercelのpreview deployment用にPlanetScaleにpreviewブランチを設けておく。ただ、この方法では並列な2つのPRが共にデータベースに変更を加えたときは競合してしまう。この辺はいずれ改善されるかもしれない。
renaming column
prisma db push だとどうするのか。Expand and contract patternによるダウンタイムを伴わない変更が提案されている。このパターンについてはPrisma Data Guideに詳しい解説がある。
PlanetScaleを使ってみる
# サインイン
$ pscale auth login
# データベースを作成
$ pscale database create fekg [--region ap-northeast]
# Development branchとしてdevブランチをmainから作成、mainをProduction branchにpromote
$ pscale branch create fekg dev
$ pscale branch promote fekg main
$ pscale branch list fekg
# データベースと接続
$ pscale connect fekg dev
# データベース接続用のクレデンシャルを生成
$ pscale password create fekg dev <name>
クレデンシャルに基づいて、接続のためのURLはPrismaの場合 mysql://<USERNAME>:<PASSWORD>@<ACCESS_HOST_URL>/<DATABASE_NAME>?sslaccept=strict となる。(PlanetScaleにVercelとのintegrationがあるがこちらは試していない)