データベースとその設計について
今回はデータベースやその設計について、基本的なことを書いていきたいと思います。
データベースとは
そもそもデータベースとは何なのでしょうか。
データベースは、大量の情報やデータをコンピューターからアクセスしやすいように加工し、効率的に保存、管理、検索できるようにするためのシステムです。データはテーブルやレコードといった形式で整理されます。データベース内のデータにアクセスし、操作するためのソフトウェアツールの集まりをデータベース管理システム(DBMS)と言い、データの整合性とセキュリティを維持しながら、ユーザーがデータを容易に追加、更新、削除、検索できる機能を実現しています。
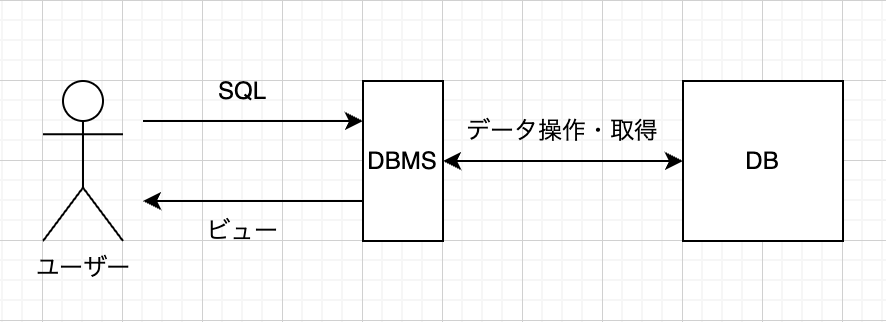
現代のシステムのほとんどは裏側にデータベースが存在しており、システム開発を行う上でデータベースは必須のものとなっています。データベースには様々な種類がありますがそのほとんどがリレーショナルデータベース型で運用されています。
RDB(リレーショナルデータベース)とは
RDB(リレーショナルデータベース)は関係データベースとも呼ばれ、データをテーブルと呼ばれる行と列によって構成された表形式で管理するデータベースです。直感的に扱えることや拡張性、柔軟性に優れていることから現在最も広く利用されているデータベースです。
RDB以外のデータベース
RDB以外のデータベース型には以下のようなものがあげられます。
グラフ型データベース
グラフ型データベースはその名の通りグラフ構造を備えたデータベースです。データをノード(エンティティ)、エッジ(関係)、プロパティ(属性)のグラフ構造で表現します。グラフ型データベースは、複雑な関係性やネットワーク構造を持つデータを効率的に管理・探索するのに適しています。Amazon Neptuneがグラフ型データベースの例です。
キー・バリュー型データベース
キーバリュー型データベースは、キー(一意の識別子)とバリュー(データ)のペアでデータを保存するシンプルなデータベースです。高速な読み書きが可能で、大量のデータを効率的に処理できるため、Webアプリケーションのセッション情報やキャッシング、リアルタイムのデータ収集などに適しています。キーに対してバリューを迅速に検索・取得できるため、パフォーマンスが重要視される用途でよく利用されます。RedisやAmazon DynamoDBがキー・バリュー型データベースの例です。
ドキュメント指向型データベース
ドキュメント指向型データベースは、データをドキュメント(JSON、XMLなどの形式で表現されるデータ構造)として保存するデータベースです。各ドキュメントは一意のキーによって識別され、複雑なデータ構造を柔軟に扱うことができ、構造が頻繁に変更される可能性があるデータを扱う場合に適しています。MongoDBがドキュメント指向型データベースの例です。
RDB以外のデータベースは総称してNoSQLと呼ばれています。
DBMS(データベース管理システム)とは
DBMS(データベース管理システム)は、データベース内のデータの作成、格納、更新、管理、取得を効率的に行うためのソフトウェアシステムです。DBMSは、データの整合性、セキュリティ、アクセス効率の向上を目的として設計されており、エンドユーザーやアプリケーションがデータベースとやり取りする際のインターフェースとして機能します。主要なDBMSとして、商用のものであればOracleDatabaseやSQLServer、オープンソースではMySQLやPostgreSQLなどがあげられます。
データベースとDBMSの違い
データベースとDBMSは混同されがちですが、異なるものです。データベースは構造化されたデータそのものや、データの集合のことを指します。データを整理して格納しておく容器のようなものと考えておくと良いでしょう。対してDBMSはデータベース内のデータに対して作成、取得、更新などの操作を行うためのソフトウェアです。データベースはデータを整理して保管することが目的ですが、DBMSの目的はそのデータの効率的な管理と操作、およびアクセスの制御を行うことです。この違いはしっかりと抑えておきましょう。
RDBにおけるデータベース設計
データベース設計とは、システム開発の設計のプロセスにおいて、データをどのように保持するかを決める設計のことです。データベース設計はシステムの拡張性やパフォーマンスに大きく影響を与えるためシステム開発において重要なプロセスとされています。では、具体的にデータベース設計はどのように行われているのでしょうか。今回はRDBで行うデータベース設計にフォーカスして書いていきたいと思います。
3層スキーマ
RDBにおけるデータベース設計を行う上で、スキーマの概念の理解が欠かせません。スキーマとは枠組みのような意味ですが、データベース設計においてはデータ構造やフォーマットという意味で用いられます。データベース設計はこのスキーマと強く関連するものであり、一般的にスキーマは3つに分けられます。これを3層スキーマと呼び、3層スキーマに基づいてシステムを記述したモデルを3層スキーマモデルと言います。
外部スキーマ(外部モデル)
外部スキーマはユーザー視点のデータベースで、データベースのオブジェクトのビューに相当します。外部スキーマは、ユーザーが必要とする情報のみを提供し、それ以外のデータベースの詳細は隠蔽します。このスキーマによって、同じデータベースを使用しながらも、異なるユーザーやアプリケーションがそれぞれのニーズに合わせたデータビューを持つことができます。
概念スキーマ(論理データモデル)
概念スキーマは開発者視点のデータベースで、データベース内の全データの構造と関係性を記述するスキーマです。データベースの全体像を表すスキーマであるため、データベース設計においても重要な位置にあることになります。概念スキーマの設計を論理設計と呼びます。
内部スキーマ(物理データモデル)
内部スキーマはDBMS視点のデータベースで、概念スキーマで定義されたデータの実際の格納方法や物理的な配置を定義します。コンピューター上のデータは最終的にファイルの形で管理されるので、そのファイルで表現される場所であるとも言えます。内部スキーマの設計を物理設計と呼びます。
データの流れ
3層スキーマにおけるデータは、物理的なファイルから始まり(内部スキーマ)、データベース全体の論理的な構造を通じて(概念スキーマ)、最終的に特定のユーザーやアプリケーション向けのカスタマイズされたビューへと変換される(外部スキーマ)という流れに沿っています。

概念スキーマの必要性
各スキーマの役割を見てみると、外部スキーマでユーザーにどのようにデータを見せるかを表現し、実際のデータが格納されているのは内部スキーマなので、概念スキーマを介さなくても内部スキーマから直接外部スキーマにデータを渡せば良いのでは?という考えが浮かんできます。しかし結論から言うと、概念スキーマがないと色々と不都合が生じてしまいます。概念スキーマは外部スキーマと内部スキーマの緩衝材としての役割を担い、データの独立性を確保する役割を担っており、堅牢なデータベース設計を行う上で必要不可欠なスキーマです。概念スキーマが存在しないと、ユーザーがデータの見方を変えるために外部スキーマを変更する場合、内部スキーマを変更する必要も出てくる場合があります。反対に内部スキーマの変更が外部スキーマに影響を及ぼす可能性もあります。このように、概念スキーマがないとスキーマ同士の依存性が高い変更に弱いシステムになってしまうのです。概念スキーマが存在することで外部スキーマと内部スキーマが独立性を保つことができます。この独立性をデータ独立性と呼びます。外部スキーマからの独立性を論理的データ独立性、内部スキーマからの独立性を物理的データ独立性と呼びます。
概念スキーマが外部スキーマと内部スキーマの緩衝材となっていることはわかったと思うのですが、逆に言うと概念スキーマを変更すると外部スキーマと内部スキーマ両方に影響が出てしまうことがわかると思います。そのため概念スキーマの設計である論理設計はデータベース設計を行う上で非常に重要なのです。
論理設計と物理設計
ここからは論理設計と物理設計について書いていきます。先ほど3層スキーマの説明のところでも書きましたが、概念スキーマを定義する設計を論理設計、内部スキーマを定義する設計を物理設計と呼びます。
論理設計
論理設計は、データベースの構造を抽象的に考えるプロセスです。この段階では、実際の物理的な制約を考慮せずに、データベースに格納されるデータの論理的な構造と関係を決定します(システムの世界では、論理的という言葉はしばしば「物理層の制約にとらわれない」と言う意味で使われます)。ここでいう物理的な制約とはハードウェアのスペックやDBMSで使えるデータ型やSQL構文などの具体的な技術的実装部分のことを言います。この段階では一旦それらに焦点は当てず、代わりにデータベースがどのようなデータを保持し、それらのデータがどのように関連しているかに注目します。ここでの目的は、実際に格納される情報の種類とその構造を理解し、エンティティ間の関係性を明確にすることです。システム開発におけるデータベース設計は論理設計を行った後に物理設計が行われます。
論理設計は以下のステップに沿って進められます。

各ステップでは具体的には以下のようなことを行います。
エンティティの抽出
まずエンティティとは何かについてなのですが、RDBにおいてエンティティとはテーブルのことを指します。つまりまず第一に行うことは、システムにおいてどのようなデータを管理する必要があり、そのデータを管理するためにどのようなテーブルが必要になるかを抽出することです。
エンティティの定義
エンティティの定義は、エンティティ(テーブル)にはどんな属性が必要かを明確にするステップになります。ここでいう属性とはテーブルにおけるカラムのことです。特に重要なのがキーと呼ばれる特定のデータを引き出すための鍵となるカラムを定義することです。キーにはいくつか種類がありますが、特に重要なのが主キーと外部キーです。
- 主キー
主キーとは、その値を指定すれば必ず1行のレコードを特定できるようなカラムの組み合わせのことで、テーブルにおいて必ず1つ存在すると同時に1つしか存在し得ないものです。1つのカラムで主キーとすることが多いですが、場合によっては複数のカラムを組み合わせなけれが主キーが作れない場合もあります。このような複数のカラムを組み合わせて作るキーを複合キーと言います。 - 外部キー
外部キーは2つのテーブル間のカラム同士の関連性を設定するものです。外部キーを使用することで、テーブル間のリレーションを表現し、データの整合性を保つことができます。以下の例で言うと生徒テーブルの部活IDが外部キーにあたります。これにより、各生徒がどの部活に関連しているかを識別できます。
生徒テーブル
| 生徒ID | 名前 | 部活ID |
|---|---|---|
| 1 | 田中 | 1 |
| 2 | 鈴木 | 3 |
| 3 | 山田 | 2 |
部活テーブル
| ID | 部活名 |
|---|---|
| 1 | 演劇部 |
| 2 | 囲碁将棋部 |
| 3 | 野球部 |
外部キーは、外部キー制約(参照整合性制約)を通じて、関連するテーブル間でデータの整合性を保ちます。どういうことかと言うと、上の例の部活テーブルを親テーブル、生徒テーブルを子テーブルとします。子テーブルにデータを追加するとき、外部キー制約が設定されたカラムには親テーブルのカラムに登録されている値しか登録できなくなり、親テーブルに存在しない値を含むデータを追加しようとするとエラーになります。上の例だと生徒テーブルの部活IDに部活テーブルに存在するIDの1、2、3以外の値を含んだデータを登録しようとするとエラーになると言うことです。また親テーブル側のデータに対して削除や更新を行おうとしたとき、対象となる値がすでに子テーブル側で使用されている場合には、エラーにするか同時に子テーブルの値を削除や更新を行うか選択することができます。ただ、本来であれば余計な問題を発生させないために常に子データを先に操作した後で親データを操作することが望ましいです。
正規化
続いて3つ目のステップの正規化についてです。正規化とは、論理設計におけるデータの重複を避け、冗長性を排除してデータの一貫性を高めるためにデータ構造を整理するプロセスのことです。正規化には何段階かレベルがあり、一般的には第1〜第5正規化までがよく知られています。業務では第3正規化まで達成するとそれ以降の正規化の条件も満たしていることがほとんどなので、第3正規化までを考えることが多いです。正規化によって作られるデータ構造を正規形と呼びます。
- 第1正規形
第1正規形の定義は「1つのフィールドの中には1つの値しか含まない」ことです。例えば以下のように1つのフィールドに2つ以上値が含まれている場合は第1正規形の条件を満たしていないと言えます。
| 生徒ID | 生徒名 | 趣味 |
|---|---|---|
| 1 | 田中 | 料理 運動 |
| 2 | 佐藤 | |
| 3 | 鈴木 | 読書 |
このような場合ではテーブルを分割するなどして複数の値がフィールドに含まれないようにする必要があります。
| 生徒ID | 生徒名 |
|---|---|
| 1 | 田中 |
| 2 | 佐藤 |
| 3 | 鈴木 |
| 生徒ID | 趣味 |
|---|---|
| 1 | 料理 |
| 1 | 運動 |
| 3 | 読書 |
なぜ1つのフィールドに複数の値を入れてはいけないのかと言うと、主キーがカラムの値を一意に識別できなくなってしまうからです。上の悪い方の例で言うと、生徒IDが主キーであるとして、本来であれば生徒IDが決まれば趣味カラムの値は1つに決まるべきですが、ここには2つの値が含まれてしまっており、値を確定させることができません。こうなってしまうと正規化というよりリレーショナルデータベースとしての構造に反してしまうことになります。
このように、1つの値が決まればもう1つの値も確定することを関数従属性と言います。リレーショナルデータベースのテーブルは全てのカラムが関数従属性を満たすよう整理されているべきです。その条件を満たすためにテーブルを整理するプロセスが第1正規化であるということです。
- 第2正規形
第2正規化は、第1正規化の条件を満たした上で部分関数従属を解消し、完全関数従属のみのテーブルにすることです。具体的にどういうことなのか解説していきます。
生徒テーブル
| 学校ID | 学校名 | 生徒ID | 生徒名 | 年齢 | 部活ID | 部活名 |
|---|---|---|---|---|---|---|
| 1 | A高校 | 1 | 田中 | 16 | 1 | 野球部 |
| 1 | A高校 | 2 | 鈴木 | 17 | 3 | テニス部 |
| 2 | B高校 | 1 | 山田 | 16 | 4 | バスケ部 |
| 2 | B高校 | 2 | 矢野 | 18 | 2 | サッカー部 |
| 2 | B高校 | 3 | 鈴木 | 17 | 3 | テニス部 |
このテーブルの主キーは学校IDと生徒IDです。そのため全てのカラムはこの2つのキーに従属しますが、学校名は主キーの一部である学校IDに従属しています(学校IDが決まれば学校名の値も確定する)。このように主キーの一部の列に対して従属する列がある場合、この関係を部分関数従属と呼びます。対して、主キーを構成するすべてのカラムに従属性がある場合を完全関数従属と呼びます。今回の例で部分関数従属を解消するためには以下のようにテーブルを分割する必要があります。
生徒テーブル
| 学校ID | 生徒ID | 生徒名 | 年齢 | 部活ID | 部活名 |
|---|---|---|---|---|---|
| 1 | 1 | 田中 | 16 | 1 | 野球部 |
| 1 | 2 | 鈴木 | 17 | 3 | テニス部 |
| 2 | 1 | 山田 | 16 | 4 | バスケ部 |
| 2 | 2 | 矢野 | 18 | 2 | サッカー部 |
| 2 | 3 | 鈴木 | 17 | 3 | テニス部 |
学校テーブル
| 学校ID | 学校名 |
|---|---|
| 1 | A高校 |
| 2 | B高校 |
これにより両方のテーブルの全てのカラムが主キーに完全関数従属している状況となりました。このような観点から見ると、第2正規化は異なるエンティティ(実体)をテーブルとしても分離する作業とも言えます。今回の例だと元々生徒テーブルに生徒と学校という異なるエンティティが存在していましたが、第2正規化を行うことで2つのテーブルに分離した、ということです。
第2正規化を行うメリットとしては、データの更新の手間が少なくなることがあげられます。第2正規化前のテーブルだとA高校の名前をD高校に変更しようとした場合、2箇所に変更を加えることになります。テーブルを分離した状態だと、学校テーブルのA高校の高校名だけを変更すればよいので手間が少なくなります。例の場合はレコード数が少ないので大きな問題にはなりませんが、実際に運用されているデータベースのレコード数は膨大なので、無駄な更新の手間は削減するべきです。
- 第3正規形
第3正規化は、第1正規化、第2正規化の条件を満たした上で推移的関数従属を解消したテーブルにすることです。推移的関数従属とは段階的な関数従属が存在する状態のことです。先ほど第2正規化を行った生徒テーブルを見てみましょう。
| 学校ID | 生徒ID | 生徒名 | 年齢 | 部活ID | 部活名 |
|---|---|---|---|---|---|
| 1 | 1 | 田中 | 16 | 1 | 野球部 |
| 1 | 2 | 鈴木 | 17 | 3 | テニス部 |
| 2 | 1 | 山田 | 16 | 4 | バスケ部 |
| 2 | 2 | 矢野 | 18 | 2 | サッカー部 |
| 2 | 3 | 鈴木 | 17 | 3 | テニス部 |
この状態には問題点があります。それは部活として存在しているが、生徒がいない部活をテーブルに反映することができないことです。例えばA高校に生徒が所属していないパソコン部が存在していたとしても、生徒が存在しないと生徒テーブルの主キーである生徒IDが存在しないためレコードに登録を行うことができません(仮の値を登録することもできますがアンチパターンと言えます)。この原因はテーブルの中に関数従属性が残っているからです。現在の状態だと部活名は部活IDに従属しています。また、生徒IDと部活IDの間にも関数従属が存在しています。全体としては学校コード・生徒ID→部活ID→部活名という従属性が存在していると言えます。このような段階的な関数従属のことを推移的関数従属と呼ぶのです。
推移的関数従属を解消するためには、第2正規化で行ったのと同じように、テーブルを分離する必要があります。
生徒テーブル
| 学校ID | 生徒ID | 生徒名 | 年齢 | 部活ID |
|---|---|---|---|---|
| 1 | 1 | 田中 | 16 | 1 |
| 1 | 2 | 鈴木 | 17 | 3 |
| 2 | 1 | 山田 | 16 | 4 |
| 2 | 2 | 矢野 | 18 | 2 |
| 2 | 3 | 鈴木 | 17 | 3 |
部活テーブル
| 部活ID | 部活名 |
|---|---|
| 1 | 野球部 |
| 2 | サッカー部 |
| 3 | テニス部 |
| 4 | バスケ部 |
| 5 | パソコン部 |
こうすることで生徒が所属していない部活のデータもテーブルに登録できるようになります。
無損失分解
ここまで正規化について書いてきましたが、テーブルを分割すると元の状態に戻せないのではないかという疑問も浮かんでくると思います。結論としてはこの心配をする必要はなく、正規化したテーブルは元の状態に戻すことができます。これはテーブルを正規化しても元の状態から情報が失われるわけではないためです。このように、情報を完全に保持したままテーブルを分割する操作のことを無損失分解と呼びます。具体的にはSQLを叩く際にJOIN句を利用して結合することで分割前の状態に戻してデータを取得することができます。
正規化とは
ここまで書いてきたように、正規化はテーブル内の従属性を見抜くことで実現することができます。こうした従属性はテーブルだけを見ていてもわからない部分も多くあります。実際にどのカラムがどのキーに従属しているかはサービスやビジネスのルールで決まることなので、そのような業務上のルールを理解することが重要になります。そのため、正規化を含む論理設計自体が業務やビジネスのルールをテーブルとして過不足なく表現することであると言えるでしょう。
高次正規形
第3正規形まで説明してきましたが、第3を超える正規形のことを高次正規形と呼びます。具体的には第3と第4正規形の間のボイス・コッド正規形、第4正規形、第5正規形が高次正規形にあたります。先ほど書いたように第3正規化まで達成するとそれ以降の正規化の条件も満たしていることがほとんどなので、今回は高次正規形の詳細説明は割愛します。
ER図の作成
論理設計の最後のプロセスはER(Entity Relationship)図の作成です。ER図は複数のテーブルの関係性を表現する図です。大規模なシステムなどではテーブル数が膨大になるため、個々のテーブルを見るだけで全体像を把握するのは困難になります。そのため、テーブルの関係性を視覚的にわかりやすくするためにER図を作成します。正規化の時に例として使った情報をもとにER図を書いてみます。
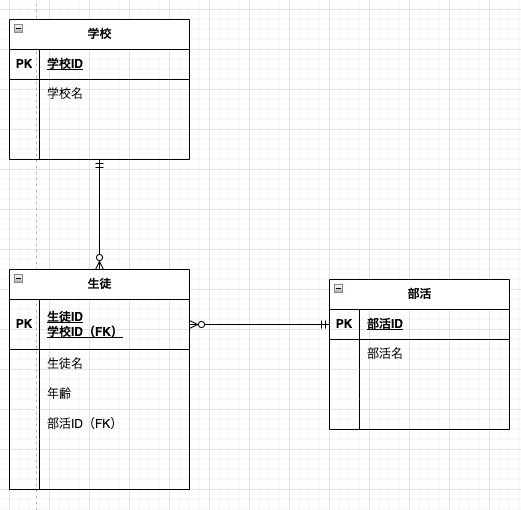
図内の記号の意味や詳しいER図の書き方は以下の記事がわかりやすかったです。
ER図は実際のところデータベースの内容を読み込んで自動で作成してくれるツールなどもあるので全て自分で書くことは少ないかもしれません。ただ、ツールで作成されたER図を読み解くためや論理設計の際にメモ程度に手書きできると設計の手助けになるので、書き方、読み方は覚えておきましょう。
論理設計が完了すると、次は物理設計に移ります。
物理設計
物理設計は、論理設計で決定したデータモデルをもとにデータを格納するための物理的な領域や格納方法を決めるプロセスです。物理設計は以下のステップに沿って進められます。
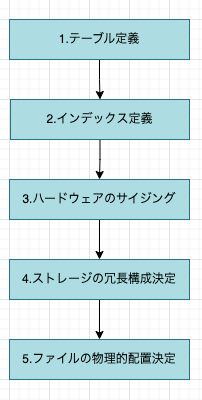
各ステップについて解説していきます。
テーブル定義
テーブル定義は論理設計で定義された概念スキーマをもとに、それをDBMS内の実際のテーブルに格納していく作業です。具体的には、論理設計で定義したエンティティ(テーブル)とリレーションシップをもとに、実際のテーブル名、カラム名に加え、主キーや外部キー、更にはインデックスといった、実際にテーブルを生成するために必要な細部の設計を行います。
インデックス定義
データへのアクセス効率を高めるために、インデックスを定義するプロセスです。インデックスは索引のことで、データアクセスの効率を高めるために作成するものです。大量のデータが保存されているデータベースから特定のデータを何もヒントがない状態で検索するのには効率が悪いので、インデックスというデータの目印を作ってデータの検索性能を向上させているようなイメージです。インデックスについては以下の記事で詳しく解説されています。
ハードウェアのサイジング
データベースシステムに必要なハードウェアリソースを決定するプロセスです。サイジングはデータの記憶容量(キャパシティ)と性能(パフォーマンス)の2つの観点から行います。ただ、実際のところサイジングの精度を高めることは困難なため、拡張性(スケーラビリティ)の高い構成を組むことが求められています。そのため近年ではAWSなどのクラウドサービスが利用されることが多くなっています。
ストレージの冗長構成決定
ストレージとはデータを保持する物理的な媒体のことで、その冗長構成を決定するプロセスです。データベースに保管されるデータが破損してしまうことは避けなければならないので、可能な限り高い耐障害性を持つような構成にする必要があります。一般的にはRAIDという技術が利用されています。RAIDは複数のディスクを組み合わせて1つの仮想的なストレージとする技術で、データの冗長性を確保し、システムの信頼性を高めることを目的としています。具体的なRAIDの種類などは以下の記事で詳しく解説されています。
ファイルの物理配置決定
物理設計の最後のステップではデータベースファイルをどのディスクに配置するかを決定します。データベースに格納されるファイルは大きく以下の5種類に分類されます。
1.データファイル
ユーザーがデータベースに格納するデータを保持するためのファイル
2.インデックスファイル
テーブルに作成されたインデックスが格納されるファイル
3.システムファイル
DBMSの内部管理に使われるデータを格納するファイル
4.一時ファイル
SQLのサブクエリやソートデータなど、DBMS内部で一時的に利用するデータを格納するためのファイル
5.ログファイル
データの更新を受け付けた際に、一旦変更分を溜め込んだ後に一括でデータファイルを更新するために利用されるファイル。ユーザーから更新処理を受け付けるたびにデータファイルを更新するよりも一括処理したほうがパフォーマンスが良くなるため利用される。
この中で特に重要なのがデータファイル(テーブルのデータ)とインデックスファイル(インデックスのデータ)で、残りの3つはDBMSの内部処理で使用されるファイルのためデータベースの管理者以外はあまり意識する必要はありません。ファイルをどのディスクに格納するかは、ファイルを格納するために十分なサイズをディスクが持っているかや、入出力の頻度をもとにどうファイルを分散して特定のディスクの負荷が大きくならないかなどを検討しながら決定されます。
最後に
今回はデータベースとその設計について基本的なことをまとめてみました。データベースはソフトウェア開発の基盤となるものなので、今後も理解を深めていきたいです。最後までご覧いただきありがとうございました。
参考
Discussion