Suphx: Mastering Mahjong with Deep Reinforcement Learning
Abstract
gameAIはGo、将棋などの2plyaer完全情報ゲームからポーカー、StarCraft2などのmulti player不完全情報ゲームへとと進化している。
麻雀は人気のあるmulti player不完全情報ゲームだが、そのゲームの性質上(知り得ない情報が多い、スコアリングルール、鳴きによる手番飛ばし)のため、難しいゲームである。
Suphxという名で、global reward prediction, oracle guiding, run-time policy adaptationといった新しいテクニックを加えた麻雀AIを設計した。
天鳳というオンラインゲームで公式にランク付けされた人間プレイヤーのtop99.99%の段位に位置。(10段?)
麻雀AIで人間を凌駕したのは初。
Introduction
人間を超えるgameAIを作るには長期的なゴール
麻雀はmulti-round tile-based game with imperfect information and multiple players game
麻雀は難しい
- 複数のラウンドがあって、ゲームの最終順位はそれらのラウンドの累積によって決定
- 1つのラウンドで負けることが必ずしも最終的な負けにつながらない
- 自身が点を多く持っていて、最後のラウンド早く終わらせたくてわざと振るとかも戦略の一つ
→ラウンドの勝ち負けをそのまま学習のフィードバックに使えない
-
和了り手が多すぎ
- 親と子、ツモとロンなどの条件によって得点が全然違う
-
相手の手がわからない
- 見えない相手の手は13 or 14
- 川にはだいたい70
→ 1回の意思決定で平均
相手の手牌に行動の良し悪しが大きく依存している(自分の手牌だけで良し悪しを決めるのは困難)
ルールがむずい
- action: リーチ、チー、ポン、カン、ツモ切り
- 鳴きによるプレイ順の割り込み
- 相手の鳴き予測はむずい
出来ることが多すぎ → MCTSの適用は難しい(従来研究でそれらのアプローチは人間には程遠い )
Suphxは、CNNを採用し、最初はプロフェッショナルの人間の対局ログから教師あり学習を行い、self-play RLで更に学習
RL: よく知られている方策勾配法
工夫
1, Global reward prediction
対局の最終的なスコアを予測する予測器を学習(今と過去ラウンドから)
この予測器により、ポリシーの学習が可能になる?
また、RLの意思決定のサポートのために、勝ち手とスコアの豊富な可能性をエンコードするlook-ahead機能を設計
2. Oracle guiding
Oracle guideingでは、相手の情報が100%見えるagentを導入
だんだん見える情報を減衰させて、最終的には通常の入力になる
これにより収束速度が向上
3. Run-time policy adaptation
麻雀の複雑なルールのため、parametric Monte-Carlo tree searchを導入
parametric Monte-Carlo policy adaptation(pMCPA) はrun-timeを改善
pMCAPAはオフラインで学習した方策を、河が増えてきたら、徐々にそのラウンドに合わせて修正、適応
Overview of Suphx

5つのモデルを使う
和了りはルールベースで決定(Winning-model)
- 基本的にはちゃんと上がれるか(フリテンかどうか、河に全部落ちてないかなど)
- 和了るかどうかは以下の簡単なルールで決定
- オーラスじゃなかったら和了る
- オーラスだけど和了っても最下位なら上がらない
- オーラスで和了ったら最下位を回避できるなら和了る
麻雀playerは2回actionがある
ツモ
和了れたらWinning-modelが和了るか決定
- カンステップ
- リーチステップ
- ツモ切りステップ
鳴き, ロン
ロン可能ならwinning-model
鳴きがモデルから提案されたらargmaxモデルの行動を採用し、ツモパートへ

Features and Model Structures

CNNに入れる特徴量を設計
34 uniqueな牌 → 状態は4 x 34 x 1チャネル

オープンな牌、河なども同様
+ look-ahead features (手牌から特定の牌を捨て、手牌をツモれる確率(4メンツ1雀頭になる)とラウンドスコア)
ただ切り/つも牌 の組み合わせ列挙は不可能なため、以下のように簡単化
- 深さ優先探索で可能な和了り手を探索
- ツモ/ 切りのみ考慮(相手の行動は無視)
100以上の先読み(look-ahead feature)が得られる
- 自分の手牌のAを捨てて、B、Cを引いたら12000点みたいな
5モデルは似たようなアーキテクチャ
鳴きモデルには、何が切りされたら鳴けるのかの情報も入ってる
Poolingを使っていないことに注意
すべての入力に意味があるので、プーリングは情報を落とすことになるから

Learning Algorithm
3ステップ
- 5モデルを教師あり学習 (top playerのstate, action pairで)
- self-playで改善 (モデルをpolicyとして, 方策勾配法), global reward prediction, oracle guiding
- online playing時にrun-time policy adaptationを使用
Distributed Reinforcement Learning with Entropy Regularization
分散強化学習を使用
(多分)分散強化学習のため、非同期による古い軌跡を使って最新の方策を更新できるように、Importance Sampling


RL trainingはエントロピーにセンシティブ
- エントロピーが小さいとすぐ収束(方策を大きく改善しない)
- エントロピー大きいと不安定(方策のバリアンスが増える)

そのためエントロピーを正則化
エントロピー項の係数は適宜動的に調整
Global Reward Prediction
1つのラウンドで負けることが必ずしも最終的な負けにつながらない
最終的な点数での評価は、途中のラウンドでの良し悪しのフィードバックにはならない
RLに正しい評価を与えるためには、ゲームの最終報酬を各ラウンドに適切に割り当てる必要がある
→ 最終報酬の予測モデルを構築(入力は今まですべてのラウンド)

モデル構成↑
学習データはtop playerの過去ログ
以下のMSEの最小化

N: 学習データのゲーム数
feature vector
- このラウンドのスコア
- 現在の累計スコア
- 親のポジション
- 連チャン
- リーチ
reward
self-play gameでの報酬
kラウンド目の報酬は
reward = predictor(
Oracle Guiding
学習のspeed upのために行う
(1) 自分の手牌
(2) 鳴いた牌(チー、ポン)
(3) 累計スコア、リー棒
ここまでは通常のエージェントが観測可能な範囲
(4) ターチャの手牌
(5) 牌山
(5)まで見えるエージェントはすぐ強くなった
強くなったエージェントでknowledge distllation試したが効かなかった

where
- 学習率を 1/10に減衰
- importance weightがある一定値より大きいstate-action pairは使わない
これらの工夫がないとtrainingがunstable, さらなる改善につながらない
Parametric Monte-Carlo Policy Adaptation
手牌が良ければアグレッシブに、悪ければ勝負から降りることもある
これにはMCTSがよく働くが鳴きのせいで使えない
そこでpMCPAを提案
ラウンドが始まり手牌が決まると、そこからオフラインでtrainingされたpolicyをこの初期手牌に適応させる
- Simulations: 3人の対戦相手の手牌と、自分の手牌を除いた山のプールからサンプルし、offline-trained policyを使ってrollout. K traejctoryを得る
- Adaptation: trajectoryを使ってoffline-policyをfine-tuneing
- Inference: fine-tuned policyを使ってplay

where
Kの数はそれほど多くはいらない
pMCPAはparametricは手法であるため、updated policyはまだ訪れてないこのラウンドの状態の推定値も更新できる
run-time adaptationは限られたシミュレーションから得られた知識を未知の状態に一般化するのに役立つ
注意点として戦略の更新は各局で独立して行われる
つまり更新された戦略は次の局に引き継がれず、次の局ではオフライン環境で訓練された戦略からまた始める
Offline Evaluation
Supervised Learning
5つのモデルは別々に訓練
データはtop player log
Accuracyで評価
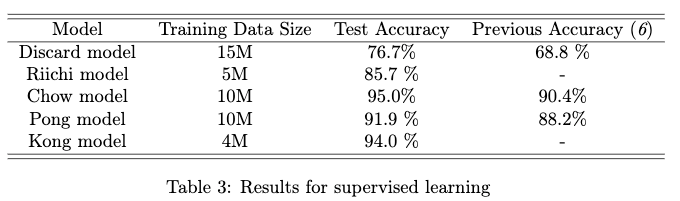
val 10K, test 50K
discard modelは34クラス分類のためデータ増やした
Reinforcement Learning
SL: supervised learning agent
SL-weak: under-trained version of the SL agent (opponent)
RL-basic: discardモデルのみpolicy gradientでboost (ラウンドスコアが報酬)
RL-1: RL-basic with global reward prediction (discard model only, others are SL)
RL-2: RL-1 + oracle guiding (discard model only, others are SL)
手牌はwin/lose rateに大きなインパクト
→ 1M games で評価
相手3人はSL-weak
評価だけで20 Tesla K80 GPUs for two days...
天鳳のランクルールで評価
800K gamesをランダムサンプリング (1000times)
学習には1.5M game , 44 GPUs (4 Titan XP for the parameter server and 40 Tesla K80 for self-play workers) two days.............

stable ranks 1000 samplings
RLが効いてることがわかり、工夫も効いてることがわかる

赤枠がRL-basic、オーラスで点数めっちゃ持ってるのに勝とうとしている
青枠がRL-1 and RL-2、現物落とししてる (6切ると東家が和了る)
Evaluation of Run-Time Policy Adaptation
pMCPAの評価
- Data generation: 手牌を固定し、100K trajectoryを生成
- Policy adaptation: 得られた100K trajectoryに対してfine-tunening
- Test of the adapted policy: 手牌を固定し、調整された方策で10K play
数百の初期ラウンドでのみテスト(めっちゃ時間かかるから)
RL−2でpMCPAなしに比べてwinning rateが66%

またまたオーラス
満貫以上で和了らないと最下位は避けられない(この図だと満貫ツモの場合西家がリーチしてないと捲れないし、直撃なら9600で足りるのにどういうこと??)
before adaptation: 赤枠、安い手
after adaptation: 青枠、満貫狙いに行く
Online Evaluation
天鳳の特大卓(expert room) 4段 でプレイした結果
鳳凰卓 phoenix roomはhuman 7段+のみプレイ可能のため特大卓へ
5000+ gameで10段になった (AI初)
安定段位 8.74段

他の麻雀AI(爆打、NAGA)と上位プレイヤと成績を比較している。爆打、NAGAの安定段位はそれぞれ6.59と6.64、上位プレイヤの安定段位は7.46である。安定段位の観点ではSuphxは他の麻雀AIや上位プレイヤよりも強いことが明らかになった。

段位とプレイヤー数の分布
top 0.001%

record rankは評価として好ましくない(少ないゲーム数でたまたま勝ちまくると上振れ?)
stable rankの方がより良い
ただこっちもバリアンスがあるので、(playerのゲーム数が少ないときとか)K gamesをサンプル、をN回

詳細な統計量
- 低い放銃率(振り込み率) (top playerのお墨付き)
- 最下位になることが少ない(これがstable rankを押し上げている?)
安牌の維持が得意で、混一色を好むなどの特徴がある
top playerのお墨付き

安牌を持ちつつ攻めている例
北を安パイとして持っておき、代わりに青枠のちーそーを捨てる
こうすることで柔軟性をもたせ、攻撃と防御のバランスを取っている
例えば相手がリーチしたとき、北を捨てることによって1ターン延命でき、和了の形を崩すことはないが、もし北を予め切っていたとき、和了に近い形ができていたにも関わらず降りることになる← これが勝率を下げるらしい
Conclusuion and Discussion
Suphxは最強の麻雀AI
しかし まだ改善の余地あり
global reward prediction
配牌が良くて和了るのが簡単な局と、難しい局とで和了った場合、難しさを考慮した報酬にするべきである
oracle guiding
oracleとnormalを同時に訓練し、知識蒸留(2エージェント間の距離を制限?)
oracle ctiric
局単位ではなく、状態レベルのフィードバック
pMCPA
最初しかやってないから最初の配牌に依存しちゃう
局が進んだ方がいろんな情報見える
現実問題(finance market, logistic optimization...)は、囲碁将棋などと違い、複雑な操作、報酬ルール、不完全情報などの麻雀と同じ性質を持っている
Suphxで使われたテクニックが幅広いアプリケーションで役に立つと考えている