Clean Architecture 読んでみたログ
はじめに
なんで読んだか
いろんな人に勧められたので「とりあえず読んでおく」系の本だと思ったから
読んでどうなりたいか
- 漠然と Clean Architecture (以下 CA) が何か知りたい
- CA の記事・本が読めるようになりたい
1ヶ月後も覚えておきたいこと
- SOLID 原則
- 良いアーキテクチャの特徴
- Business rules の分け方
- ソフトウェアの level とは
- ソフトウェアの切り分け方
今後も思い出したいことがあったら追記する予定
key concepts
アーキテクチャとは
アーキテクチャの目的は「システムの開発とメンテナンスにかかる人的コストを最小限にすること」 (Chapter 1, p.4) で、良いアーキテクチャは下記のような「いいこと」がある (Chapter 16)。
Use Case
アーキテクチャからソフトウェアがどんな use case があるか自明。ECサイトなら一番上位のソースから「ECサイトのためのもの」と開発者がわかるようになってる。対して、ソフトウェアの振る舞いをソースコードを彫っていかないとわからないアーキテクチャは良くない。
Development
良いアーキテクチャでは、機能が適切にまとまって分けられているので、開発チームが複数あっても依存関係が整理されていて開発しやすい。c.f. Conway's Law: ソフトウェアのの構造は組織のコミュニケーションの構造を反映する。
Deployment
良いアーキテクチャはデプロイがしやすい。毎回設定ファイルをいじるとか、デプロイが大変なものは良くない。
Operation
1分間に10万リクエストある、大量のデータを取ってくるなどに適切に対応できるのが良いアーキテクチャ。
また、良いアーキテクチャは use case, development, deployment, operation についての選択肢をできるだけ遅らせられる。例えば、入出力のロジックがビジネスロジックとちゃんと分けられていれば、データベースを開発初期はモックして後から MySQL にする、という選択が取れる。
ソフトウェアの切り分け方
ソフトウェアは layer と use case の2つの軸で切り分けられて、ここがちゃんと分かれていると変更がしやすい。Layer とは、データベース・ビジネスロジック・UI などを指して、use case は「layer を薄く縦切りにしたもの」(Chapter 16, p.151)。例えば、「商品をカートに入れる」と「商品をカートから削除する」は違う use case で、それぞれデータベース・ビジネスロジック・UI を使う。

Layer と Use Case の2軸
Policy と Level
ソフトウェアとは、「入力がどのように出力に変換されるかという policy (方針) の集合」 (Chapter 19, p.183) で、この policy を適切にまとめる、あるいは分けることがアーキテクトの仕事のひとつ。「適切」というのは、同じタイミング・同じ理由で変更される policy はまとめられるべきで、異なる level に属する policy は分けられるべき。
ここで、level とは「入出力から離れている程度」 (Chapter 19, p.184) を指していて、例えば UI は「低レベル」でデータベースは「高レベル」といえる。また、低レベルにあるプログラムは高レベルのプログラムに依存している。逆の依存を作ると循環グラフができて変更の影響が大変なことになる。
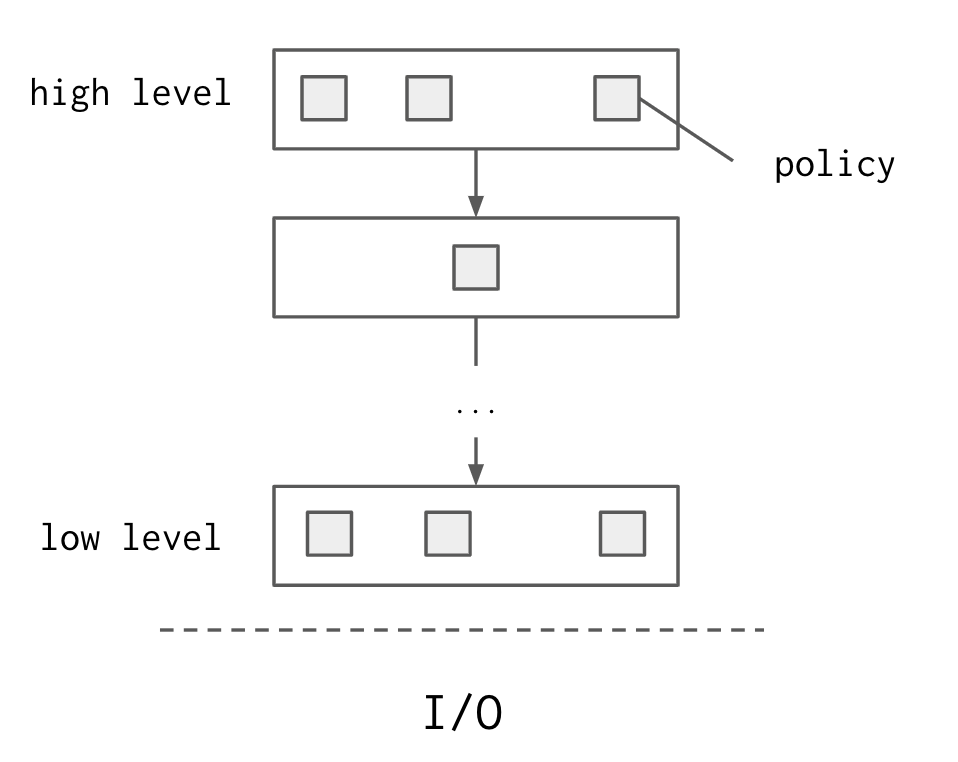
level ごとに分けられた policy と依存関係
Business rules
*business rules の訳がわかりませんでしたが、「お金を増やす・減らすことを防ぐための手続き」です (Chapter 20)
Business rules には三段階あって、
- Entity
- Use case
- Request/response model
に分けられる。
Entity は、アプリケーションがあってもなくても存在するルールで、例えば「ローンの利率は 5%」というルールはアプリケーションが存在しても紙で記録しても変わらない。一方、use case はアプリケーションがあって初めて存在するルールで、「銀行システムの登録者は有効なメールアドレスが必須」というのは use case に当てはまる。そして、entity と use case を入出力の変更から守るものが request/response model で、入力が CLI かスマホアプリからかは request/response model が吸収して、entity と use case は入出力の形式を気にしなくて良くなる。

Entity, Use Case, Request/Response Model のイメージ
SOLID 原則
多分この本で一番有名なやつ。SOLID 原則の目的は変更しやすくてわかりやすいソフトウェアをつくることで、いろんな中規模ソフトウェアに適用することを目指す。
SRP: Single Responsibility Principle
「モジュールは単一のアクターにのみ責任を負うべき」 (Chapter 7, p.61) という原則。アクターとはユーザやステークホルダーなどの集合を指していて、例えば給与計算システムでは「CTO」「PM」「人事」がそれぞれ異なるアクターになる。

アクターを分けると、変更が必要な理由・タイミングごとにソフトウェアを分けられるので、変更がしやすいシステムになる。逆に、例えば給与計算システムで「従業員の労働時間を計算する」関数をアクターで分けないと、
- PM: 正確な工数を把握するためにみなし残業も含めて労働時間を知りたい
- CFO: みなし残業時間分以外の労働時間だけ知りたい
で、それぞれ「労働時間」の定義が違うのでうっかり変更したくない方にも影響が出たりする。
OCP: Open-Closed Principle
ソフトウェアは変更しにくくて、拡張はしやすくあるべきという原則。
実現するためには、
- コンポーネント間の依存関係を一方向にする(=循環グラフをつくらない)こと
- 情報の隠蔽/データ構造の抽象化
が必要。
LSP: Liskov Substitution Principle
モジュールは下位のモジュールによらず動作するべきという原則。

Chapter9, p.77 より引用
上の図だと、License は個人向けライセンスでも会社向けライセンスでも同じように動作するので、LSP に則っている。
ISP: Interface Segregation Principle
不要な依存関係を作らないという原則。
そのために、インターフェース (interface) を分離 (segregate) する。
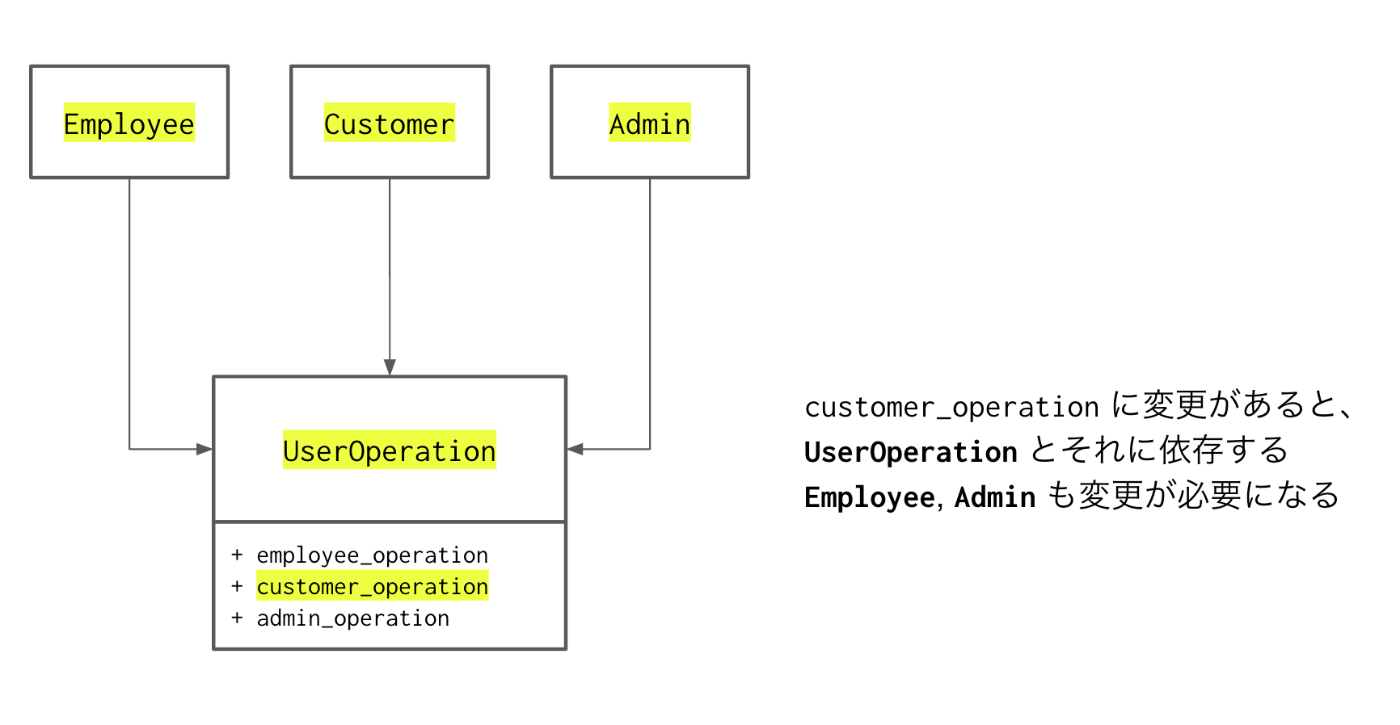
BAD: インターフェースを分けてない例

GOOD: インターフェースを分けた例
DIP: Dependency Inversion Principle
できるだけ抽象化されたクラスい依存するべきという原則。
- Java のような静的型付け言語では、インターフェースや抽象クラスを
useimportincludeする - Ruby や Python などの動的片付け言語では「具体的なモジュール」に依存しない
*「具体的なモジュール」とは、本書では「呼ばれた関数が実装されているモジュール」と書かれていました (Chapter 11, p.87)
DIP に即した実装をするためには、stable abstractionsの考え方が必要になる。つまり、抽象クラスは変更が少なく stable であり、一方でそれを実装した具象クラスは volatile で変更が起きやすい。開発中で変更が多いコードに依存すると一箇所の変更で複数のファイルに影響が及ぶので、できるだけ変更が少ない抽象クラスに依存したい。
なお、"inversion" が入っているのは依存関係が制御フローと逆だから (Chapter 11, p.90)。
Humble Object
テストしやすい部分とテストしにくい部分を分けるといいよ、というアプローチ。

https://martinfowler.com/bliki/HumbleObject.html より引用
本書では例としてテストしにくい View から、 View にデータを渡すだけの Presenter を切り出すことが挙げられている (Chapter 23)。

Presenter を View から切り離すと Presenter のテストはできる
TODO
chapter 14: component coupling, stability
chapter 13: p.108, tension diagram
Discussion