From data to insights: Clojure for data deep dive (by Kira McLean) を見ながら作業したメモ
いつもとはちょっと違うことをしようと思ってこのYoutube見始めたので、作業メモ取っていきます
From data to insights: Clojure for data deep dive (by Kira McLean) - YouTube - https://www.youtube.com/watch?v=eUFf3-og_-Y
一緒に作業をするためには、workshops/london_clojurians_april_2024/README.mdに従って環境を作る必要があります。
何が必要かというと
- レポジトリのClone
- python 3.12 環境を作成
- statsmodels 0.14.0 以上を環境にインストール
- レポジトリ内の
python.ednにPython環境へのPathを設定
です。仮想環境はお好きな方法でいいと思います。 python.edn にPython環境へのPathを設定ができていない場合、評価すると以下のような例外が発生すると思います。
; Syntax error compiling at (libpython_clj2/require.clj:1:1).
; namespace 'libpython-clj2.metadata' not found
ところで、READMEのInstructionはCondaを使って環境を作っていますが、間違いがあって、
conda env create -n libpython-clj -f london_clojurians_april_2024/python-env.yml
の -f オプションに渡してあるファイルは python-env.txt です。
あと、clone したレポジトリに cd した前提で書いてあります。お気をつけください。
ここまでできれば、REPLで評価できるようになります。
clay で notebook 表示が出来るので
(def housing
(tc/dataset "data/housing-data.csv"))
housing
これで housing を clay make current form as HTML すると、ブラウザで表示できる。
clay に関しては、以前とったメモを参照:→Clay 勉強メモ
描画は、 src/utils/hana.clj で定義されていて、kindly が使われている。kira さんいわく、まだ experimental だって言ってたけど、問題なく色々描画できてよい。

GrLivArea が 4000 より大きいのは外したい
(-> housing
(tc/drop-rows #(> (% "GrLivArea") 4000))
(hana/plot {:X "GrLivArea" :Y "SalePrice"})
(hana/layer-point))
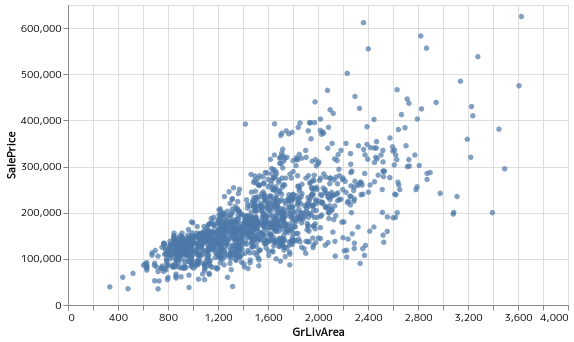
おお。いいな。
このデータを束縛しとくと便利
(def without-outliers
(-> housing
(tc/drop-columns "Id") ;; ID はいらないのでDropしておく
(tc/drop-rows #(> (% "GrLivArea") 4000))))
tc/info で pandas の df.describe() に近いことをしてくれる。describe より情報多め。
(-> without-outliers
tc/info

これをみて、例えば :n-missing がゼロより大きいものだけのコラムを取得して前処理するとかに使う
(-> without-outliers
tc/info
(tc/select-rows #(< 0 (:n-missing %)))
:col-name)
ここでは missing-value を replace することにする。
tc/replace-missing を使ってスレッドマクロ使うと、とてもわかり易い。
(def no-missing-values
(-> without-outliers
(tc/replace-missing ["LotFrontage" "MasVnrArea"] 0)
(tc/replace-missing ["Alley" "MasVnrType"] "None")
(tc/replace-missing ["BsmtQual" "BsmtCond" "BsmtExposure" "BsmtFinType1" "BsmtFinType2"
"Fence" "FireplaceQu" "GarageType" "GarageFinish" "GarageYrBlt"
"GarageQual" "GarageCond" "MiscFeature" "PoolQC"] "No")
(tc/drop-rows #(nil? (% "Electrical")))))
(tc/info no-missing-values)
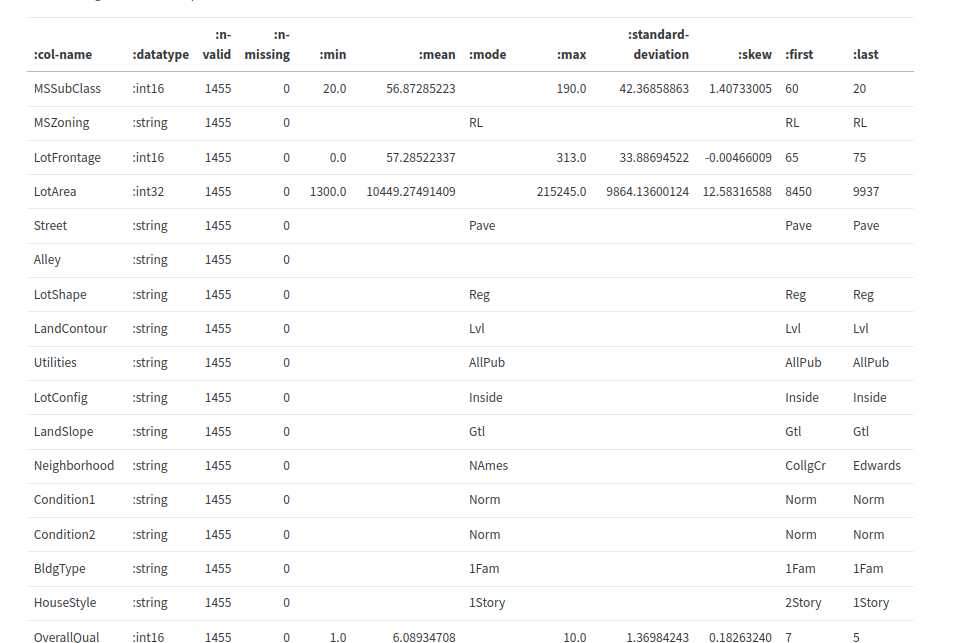
データ分析する時に、文字列はカテゴリー別に数値に置き換えると楽だったりします。↑の表でいえば :datatype が :string のものはグループごとに適当に数値化してくれると楽です。
そのために tech.v3.dataset/categorical->number を使います。
(def numeric-values-only
(let [string-col-names (-> no-missing-values
tc/info
(tc/select-rows #(= :string (:datatype %)))
:col-name)]
(-> no-missing-values
(ds/categorical->number string-col-names))))
numeric-values-only
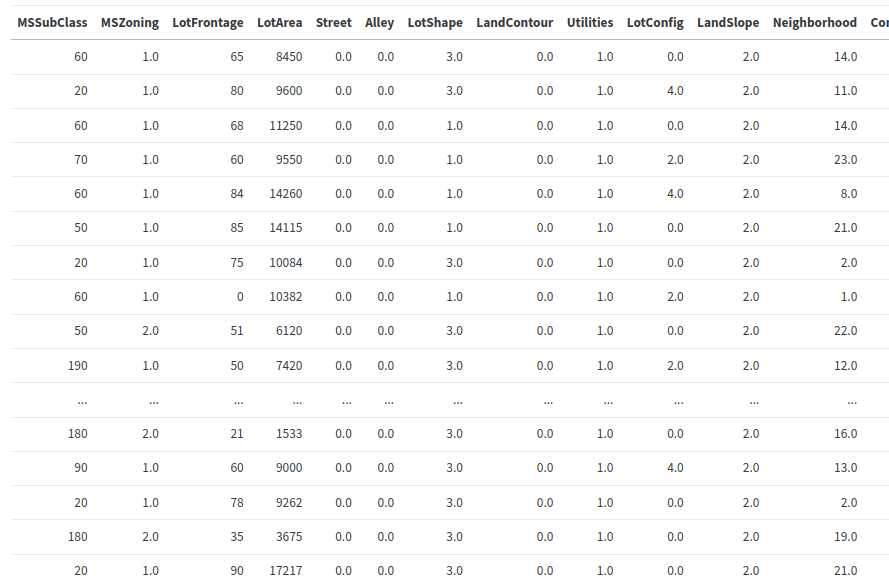
では、SalePrice とCorrelationが大きいものを見ていきます。tech.v3.dataset.math/correlation-table で実現できます。
(-> numeric-values-only
math/correlation-table)

結果はマップになっているのでほしいSalePrice だけ取ります
(-> numeric-values-only
math/correlation-table
(get "SalePrice"))
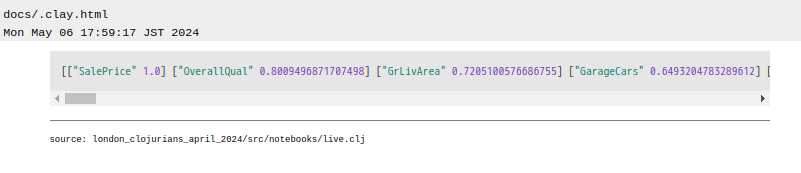
sort-by second > して take 10 してみます
(->> (-> numeric-values-only
math/correlation-table
(get "SalePrice"))
(sort-by second >)
(take 10))
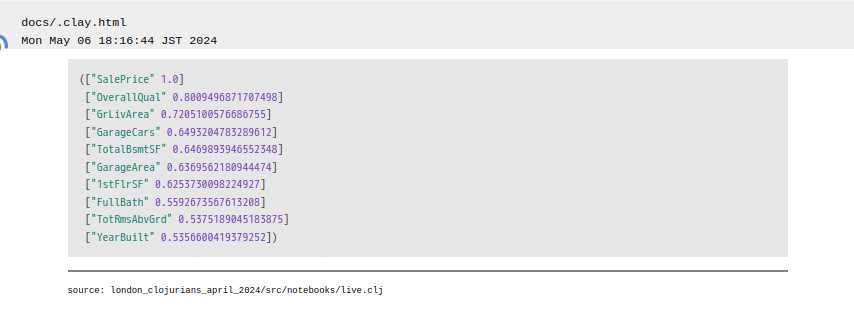
サイコー
コラムを組み合わせて新しいコラムを作りたい場合、tablecloth.api/map-columns を使います。
たとえば、"OverallCond" と"OverallQual" を掛けて新しいコラム"OverallGrade"を作るには
(-> numeric-values-only
(tc/map-columns "OverallGrade" ["OverallCond" "OverallQual"] tcc/*)
(tc/select-columns ["OverallGrade"]))

最後のパラメータ tcc/* はカスタム関数でももちろん大丈夫です。例:
(-> numeric-values-only
(tc/map-columns "TotalBath" ["BsmtFullBath" "BsmtHalfBath"
"FullBath" "HalfBath"]
(fn [bsmt-full-bath bsmt-half-bath full-bath half-bath]
(tcc/+ bsmt-full-bath (tcc/* 0.5 bsmt-half-bath)
full-bath (tcc/* 0.5 half-bath)))))