Kaggle体験談


はじめに
データサイエンスに興味を持ち、Kaggleに挑戦してみようと思い立ってチュートリアルの'Titanic - Machine Learning from Disaster'に取り組みました。データを眺めながら考えたことや役立つコードことを自分用の備忘録としてまとめました。有識者の方にはたくさんご指摘いただくことがあるかもしれないけど温かく見守っていただければ嬉しいです...
備忘録
ライブラリの読み込み
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import os
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
データの俯瞰
データを読み込みます。
base_dir = 'data\inputs\kaggle-titanic-master\input'
train = pd.read_csv(base_dir + '/train.csv')
test = pd.read_csv(base_dir + '/test.csv')
まずは生データを眺めます。
train.head()
数値データの諸統計量を眺めます。"Survived"の平均値が0.5よりも低いため死者のほうが多いようです。
train.describe()
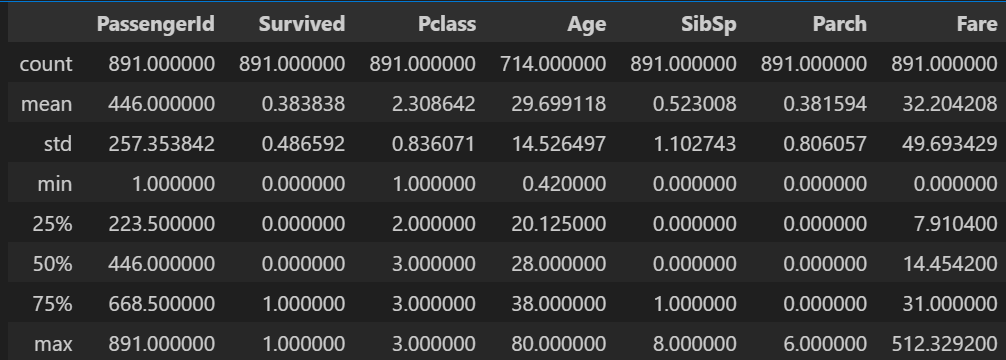
ここで見る価値があるのは"Age"と"Fare"だけですね。なんとなくですが、平均と標準偏差、四分位数をみて"Age"は正規分布してそうです。逆に"Fare"は右に裾が長そうな気がします。後で可視化したときに答え合わせします。また、この時点で"Age"のカウントが他より少ないので欠損値が多いことがわかります。
各カラムの欠損値、型を調べます。
train.info()
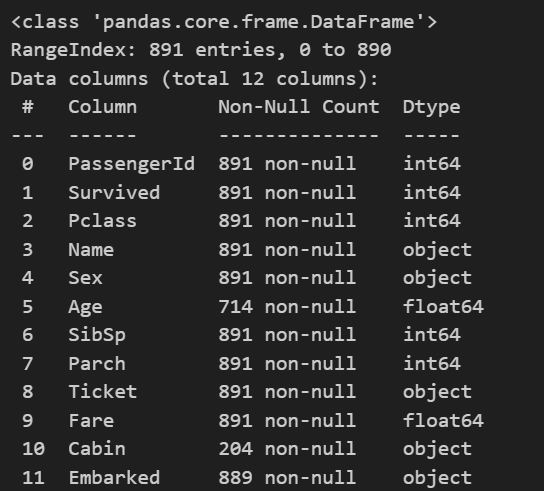
object型が5つあり処理に骨がおれそうな雰囲気あります。
データ処理
実施した処理は以下です。
- 「キャビンがいると誘導してもらえそう」、「キャビンがいるほうがお金持ってそう」という安直な理由からhave_cabinカラムを追加。Pclassと相関ありそう...
- 性別と乗船した港のダミー化。
- Pclassをダミー化。
- 不必要なカラムを削除
- 欠損値を埋める
# 1.
train['have_cabin'] = train['Cabin'].isna().apply(lambda s: 1 if not s else 0)
# 2.
dummies = pd.get_dummies(train, columns=['Sex', 'Embarked'],)
train['is_male'] = dummies['Sex_male'].apply(lambda s: 1 if s else 0)
train['Embarked_C'] = dummies['Embarked_C'].apply(lambda s: 1 if s else 0)
train['Embarked_Q'] = dummies['Embarked_Q'].apply(lambda s: 1 if s else 0)
train['Embarked_S'] = dummies['Embarked_S'].apply(lambda s: 1 if s else 0)
# 3.
str_pclass = train['Pclass'].apply(lambda s: str(s))
dummy_pclass = pd.get_dummies(str_pclass, ).rename(columns={'1':'Pclass1','2':'Pclass2', '3':'Pclass3'}).applymap(lambda s: 1 if s else 0)
train = pd.concat([train, dummy_pclass], axis=1)
# 4.
train = train.drop(['Name', 'Pclass', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis=1)
train.head()
# 5.
train.loc[train['Age'].isnull(), 'Age'] = train['Age'].mean()
相関を調べてみます。分散共分散行列をヒートマップにして可視化します。
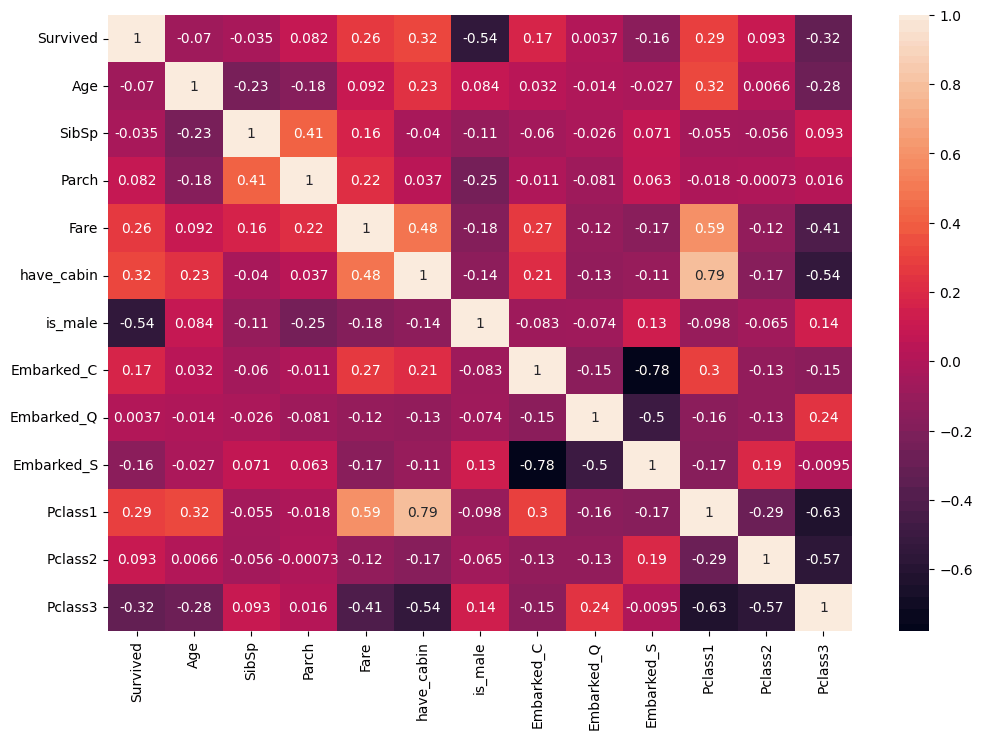
相関から以下のことを考えました。
- 女性のほうが生き残っている傾向が見て取れる(女子供が優先して助けられた?)
- キャビンがいるほうが生き残る傾向が見て取れる
- Pclassは1が高いクラス、3が低いクラス、クラスが低いと生き残れない傾向がある
- 'have_cabin'と'fare'の相関が高い、共線性をもってしまうからどちらかをdropしよう
- 乗船した港によってPclassの分布が違う→地域による景気格差?
データの再処理
年齢に関する考察
年齢と生き残りとの相関係数は-0.07とほぼないに等しい値だったけど正直信じられない(子供は優先的に助けようとか年寄りも若い人のほうが生命力があるとかありそうだから)。
5歳おきに生き残ったか見てみる。
crosstab = pd.crosstab(pd.cut(train['Age'], range(0, 101, 5), right=False), train['Survived'])
(ax1, ax2), = crosstab.divide(crosstab.sum(axis=1), axis=0).plot.barh(subplots=True, layout=(1, 2), sharex=False)
ax1.invert_xaxis()
ax2.set_yticklabels([])
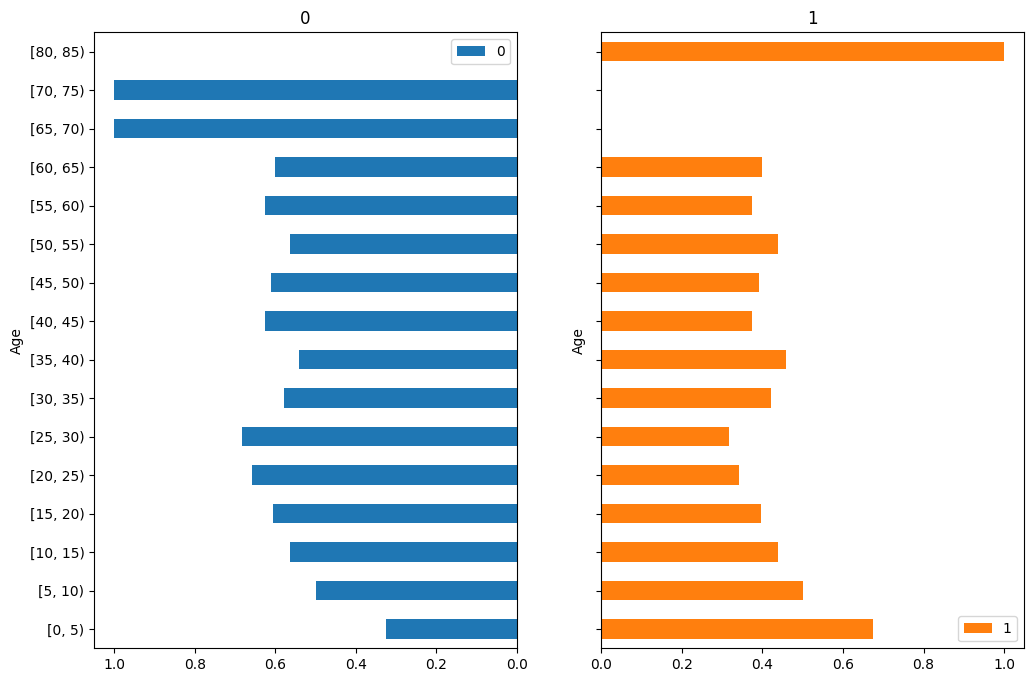
生存者よりも死者のほうが多いので基本的にはどの年齢においても死者の割合のほうが高いのですが、例外的に0~5歳の生存割合が高いです。危険な状況下だからこそ赤ん坊は優先して助けようという意思が働いたのか、赤ん坊は一人分の席をとらないから救援ボートに乗せてもらいやすかったのでしょうか。
理由はどうであれ、この情報を使わない理由はないです。"is_baby"カラムを追加します。
train['is_baby'] = (train['Age'] <= 5).apply(lambda x: 1 if x else 0)
最後に不要だと考えたカラムを削除します。
train.drop(['Embarked_Q', 'Fare', 'Pclass2', 'Age'], axis=1, inplace=True)
train.head()

予測
今回は機械学習の勉強というよりもデータ解析に力を入れたかったのでモデルの比較は行わず、シンプルにロジスティック回帰のみを使用しました。
X = train.drop(['Survived', 'PassengerId'], axis=1)
Y = train['Survived']
Xtrain, Xtest, Ytrain, Ytest = train_test_split(X,Y, test_size=0.2, random_state=2)
Ytest = np.reshape(Ytest, (-1, 1))
# ロジスティック回帰
model = LogisticRegression(max_iter=5000)
model.fit(Xtrain, Ytrain)
Ytrain_pred = model.predict(Xtrain)
training_accuracy = accuracy_score(Ytrain_pred, Ytrain)
Ytest_pred = model.predict(Xtest)
test_accuracy = accuracy_score(Ytest_pred, Ytest)
print(f'train accuracy: {training_accuracy}, test accuracy: {test_accuracy}')

訓練制度0.825、検証制度0.810という結果を得ました。初めての試みにしてはまずまずの結果を得たような気がします。Kaggleサイトでテスト精度の確認をしてみます。

結果は0.758でした!Leaderboardを見ると正答率100%の化け物が並んでいて驚きました...
今後はモデルの改善や特徴量選択をもっとまじめにやって80%を超えるように頑張ろうと思います。
まとめ
初めてKaggleのコンペに挑戦してみてたくさんの学びがありました。ネットで検索するとKaggleの先輩達が残した備忘録がたくさんあるのですごく勉強になりました。また、データからバックグラウンドを読み解く・想像することがとても楽しかったです。今後は特徴量選択に決定木を使ったり、今回は使わなかった"Ticket"や"Name"カラムの使い道を考えたり、ランダムフォレスト等のアンサンブル手法を試してハイパーパラメータ調整をしたりしてもっといいスコアの獲得を目指します。
Discussion