LLM周りの技術メモ
Llama2
Llama2は、Meta社が開発した最新の大規模言語モデル(LLM)であり、前モデルであるLlamaの後継。2023/02に発表された。
ChatGPTと同様に、Google社による深層学習モデルであるTransformerによる自然言語処理をベースとしている。
LLaMAは、小型サイズかつ高性能なモデルで、少ないリソースでLLMを用いたアプローチのテストや活用方法の探求が可能。
性能の高さに直結するパラメータ数がOpenAI社のGPT-3を大幅に上回っており、最大モデル(650億)ではDeepMind社のChinchilla(70B)やGoogle社のPaLM(540B)に匹敵するとされている。
Llama 2は先述したLlamaの後継版。
ChatGPTと互角の性能を持つとされるLlama2では、パラメータ数が70億・130億・700億という3つのモデルがある。
以下の2タイプが発表されている。
- 事前学習済みバージョン
- チャット用のファインチューニングされたもの
事前学習に使われたトークンは2兆個で、Llamaの2倍ほどである4000を超えるコンテキストの長さを持ち合わせている。
また、Llama-2-chatモデルでは、10万回以上の教師あり学習にてファインチューニングされ、さらに100万以上の新しい人による注釈で訓練されている。
Llama-2-chatの初期バージョンは、教師ありの微調整により作成された後、人間のフィードバックからの強化学習(RLHF)により改良されている。
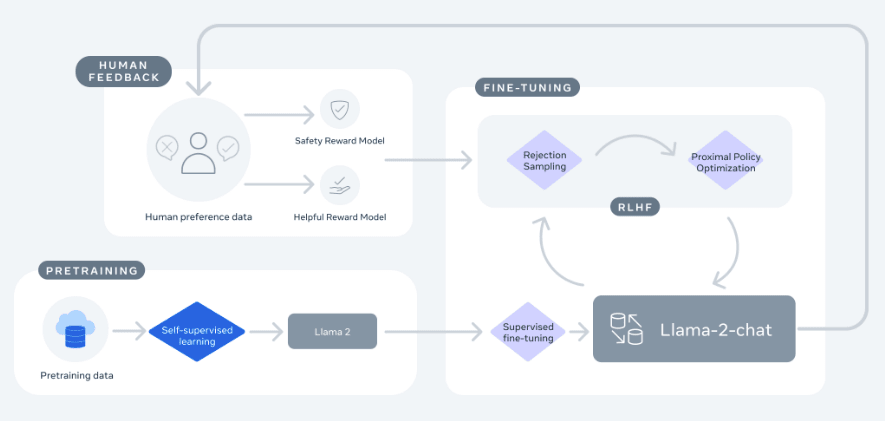
Llama2と前作であるLlamaや他のモデルとの比較
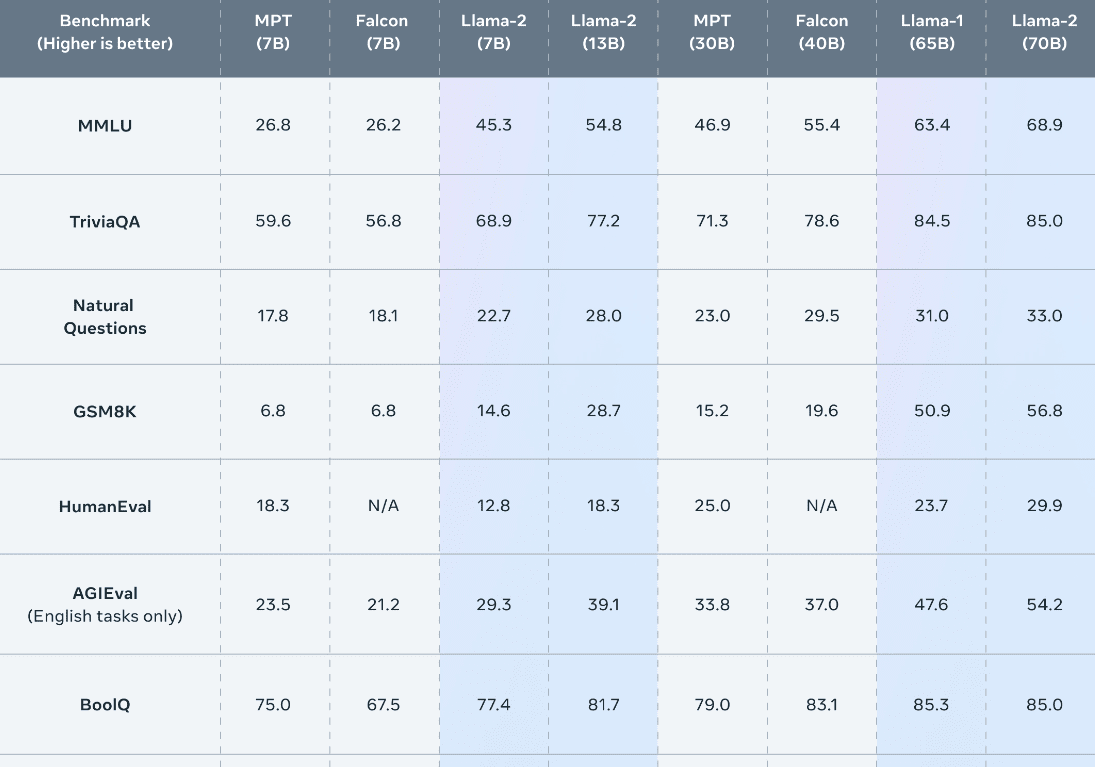
Llama2の700億パラメータは、Llama(650億パラメータ)を含め、すべてのベンチマークで他のモデルよりも優れたパフォーマンスを見せている。
特に、一番上のMMLU(Massively Multi-Tasked Language Understanding/マルチタスク性能)では、Llama2が前モデルや競合に差をつけていることがわかる。
Llama2の性能
Llama2では、マルチタスク性能をはじめ推論やコーディング、知識テストを含む多くのベンチマークにおいて、前モデルのLlamaや他の言語モデルを上回っていることが示されている。
また、LLaMAでは、パラメータ数が70億、130億、330億、650億という4種類が用意されていたが、Llama2では、70億、130億に加えて700億の3タイプが提供されている。
PaLM
2022年にGoogleから発表されたモデルでPathways Language Model。
以下が論文
https://arxiv.org/pdf/2204.02311.pdf
ベースとなるのはやはり2017年にGoogleが発表したTransformerというモデル。
5400億個のパラメータ
まずは、パラメータの数。
PaLMよりも前に発表されたOpenAIのGPT-3のパラメータが1700億個。
そしてMicrosoftから発表されたMegatron-Turing NLGのパラメータが5300億個。
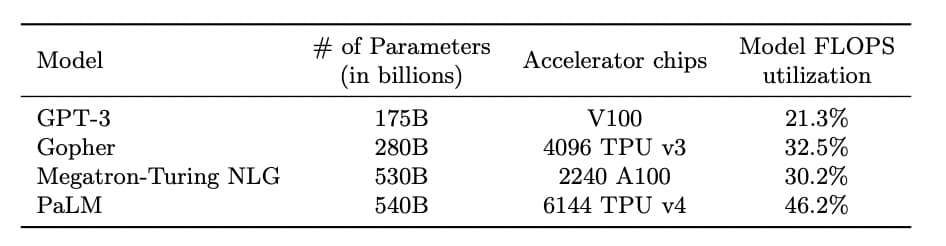
Transformers
Hugging Faceが公開している、最先端の NLP モデルの実装と事前学習済みモデルを提供するライブラリ。
Transformersを利用することで、BERT やその派生モデルを誰でも無料で手軽に利用することができる。
また、以下のようなNLPの代表的なタスクの実装も用意されている。
- 文書分類
- 文書生成
- 質問応答
- 要約
- 固有表現抽出
BERTをはじめとする事前学習済みモデルと組み合わせることで、簡単にモデルの構築を行うことが可能。
Transformersは Python の実行環境があれば利用可能で、pip コマンドや conda コマンドで簡単にインストールできる。
機械学習のフレームワークとしては PyTorch や TensorFlow、JAX が利用できる。
BERTの登場によってNLPは急速に進化し、現在では NLP をやるなら BERT といえるぐらい。
BERTでは大規模コーパス (大量の自然言語のデータ)を用いて事前学習を行っている。
これにより、文法や単語の意味といった汎用的な言語知識を捉えたモデルが作成される。
BERTを利用して特定のタスクを解きたい場合は、この事前学習済みのモデルをベースにして、タスク用のデータセットでFine-Tuning (事前学習済みモデルを再学習し調整)を実施することで、タスクに特化させたモデルを作成することが一般的となる。
BERT では事前学習のタスクの 1 つとして、文中でマスクされた単語の穴埋めタスクを行っています。マスクされた単語を推測するためには、その周辺の文脈や文法の情報をうまくとらえられる必要があります。BERT では Attention 機構という特徴的な仕組みによって、文中の単語間の関係性が学習でき、文脈や文法の情報をうまく捉えられるモデルとなっています。この結果、より人間に近い文章の解釈が可能となり、様々な NLP タスクで高い性能を示しています。
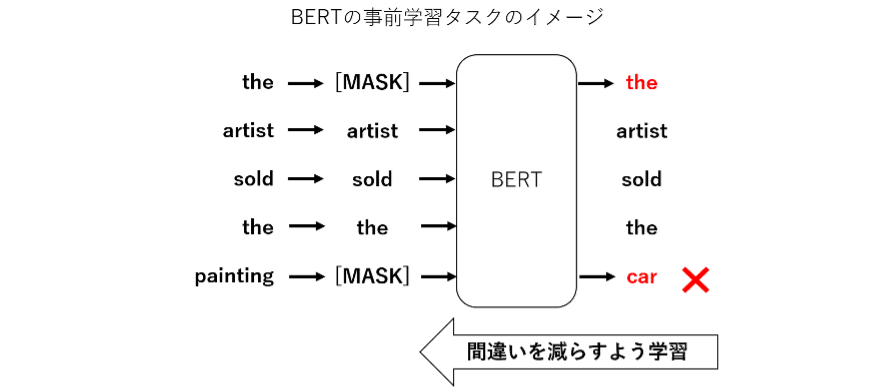
BERTの登場後、たくさんの派生モデルが考案されている。
その中でも BERT の後継ともいえるモデルとして ELECTRA がある。
ELECTRA は Google が 2020 年に発表したモデルで、BERT の事前学習を改良して性能向上を報告しているもの。
ELECTRA は Generator と Discriminator という2つのモデルから構成されており、それぞれのモデルは BERT と同様の構造となっている。
Generator は従来の BERT 同様のマスク穴埋めを学習するのですが、Discriminator では Generator が穴埋めした文に対して、各単語が穴埋めされたものか否かの識別を学習する。
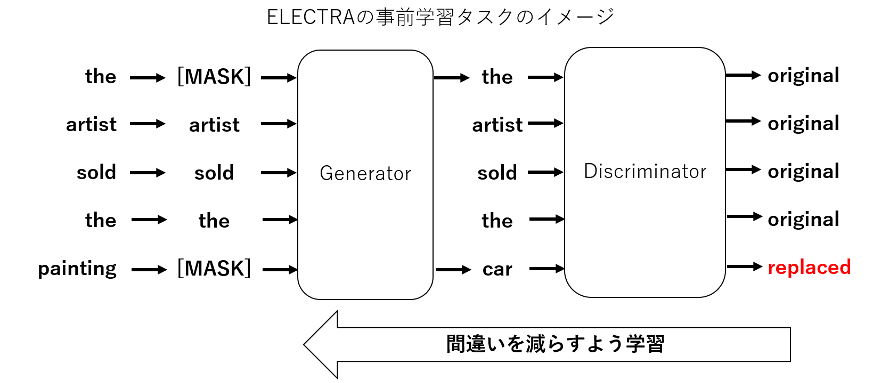
ELECTRA の提案論文において、同じ計算量・モデルサイズであれば ELECTRA は BERT を超える性能を示すことが報告されています。本記事では、Transformers を使って、BERT と ELECTRA の事前学習済みモデルを利用していきます。
https://www.softbanktech.co.jp/special/blog/dx_station/2021/0038/
Retrieval-Augmented Generation (RAG)
関連文章を検索して、既存モデルのプロンプトに載せる手法
LangChain
LangChainには大きく以下の6つにモジュールから構成されている。
- Model I/O
- Prompts
- LLMs
- Chat Models
- Output Parsers
- Retrieval
- Document loaders
- Text Splitting
- Text embedding models
- Vector stores
- Retrievers
- Indexing
- Agents
- Agent
- AgentExecutor
- Tools
- Toolkits
Additional
- Chains
- Memory
- Callbacks
Model I/O
様々な言語モデル・チャットモデル・エンべディングモデルを切り替えたり、組み合わせたりすることができる機能
本来であれば、各ライブラリを理解し、それぞれの記法でコーディングする必要がありますが、LangChainではすでに複数のモデルが統合されているため、かなり手間が省ける。
また、タスクに応じたプロンプトテンプレートの管理や出力フォーマットの指定ができるため、かなり効率的にモデルを操作できる。
LLMsまたはChat Modelsというモジュールを使用することにより、さまざまな言語モデルを共通のインターフェースで使用することができる。
OpenAI の文章生成 API には、Completions APIとChat Completions APIの2つがあり、前者を LangChain で使用するには LLMs モジュール、後者を使用するには Chat Models モジュールを使用する。
Retrieval
言語モデルが学習していない事柄に関して、外部データを用いて、回答を生成するための機能。
たとえば、言語モデルが学習していない最新情報やインターネットで公開されていない社内データに基づいて、回答を生成できる。
また、LangChainは外部データを読み込むための機能も用意している。
132個のデータ読み込みに対応している。
主に以下の形式がある。
- CSV
- PowerPoint
- Word
- HTML
- Markdown
- URL
SaaSのサービスには主に以下がある。
- Notion
- Figma
- EverNote
- Google Drive
- Slack
- YouTube
Retrivalを用いることで、幅広いデータ形式から、回答に必要な情報を取得し、そのデータから回答を生成できる。
Chains
複数のプロンプト入力を実行する機能。
この機能は、ChatGPTがたくさんの指示を一度に処理できない場合に特に役立つ。
具体的には、複数のプロンプトに分けて、順番に実行することで、より精度の高い回答が得られる。
また、複雑な問題を解きたい時に、中間的な回答を一度出力することで、より正確な回答を得ることもできる。
このように中間的な推論ステップを踏むことで性能向上を図る手法を、CoTプロンプティングと呼ぶ。
他にも、Chainsを用いることで、プロンプトの出力を組み合わせたりすることもできる。
例えば、AとBの2つのプロンプトの出力を用いたプロンプトを実行することもできる。
より具体的な例を挙げてみる。
一度では処理できない長い文章を要約したい時があるとする。
その文章を5分割にして、それぞれの塊に対して要約のプロンプトを実行する。
その後、出力された5つの要約を入力として、要約のプロンプトを実行することで、長い文章をひとつの文章に要約できる。
Memory
ChainsやAgentsの内部における状態保持をする機能。
基本的に、LangChainで使用するOpenAI社のAPIなどはステートレスであり、状態を持たない。
これは、各APIクエリーが独立して処理され、そのクエリーが終わると、状態や文脈がリセットされる。
一回の質問と回答が終わった後、次の質問は前の質問と回答について何も知らない状態になる。
Memoryを使うことで、過去の会話も記憶した自然な回答を生成できる。
Agents
言語モデルに渡されたツールを用いて、モデル自体が、次にどのようなアクションを取るかを決定・実行・観測・完了するまで繰り返す機能。
言語モデルに渡されるツールとは、言語モデルがタスク達成のために使用することができるリソースや機能を指す。
例えば以下のような機能などが含まれる。
- 数式演算
- 検索エンジンの利用
- 特定のデータベースへのアクセス
- 特定のAPIの呼び出し
Agentsは、与えられた目標を達成するために、渡されたツールを用いて、自立的に考え、行動する機能。
この機能によって、モデルは複雑なタスクを自動的に処理することができるようになる。
Callbacks
大規模言語モデルのアプリケーションのロギング、モニタリング、非同期処理などを効率的に管理する機能。
ここでは、代表的な2つの機能を紹介。
コールバックシステム
アプリケーションのログの記録やアプリケーションのモニタリングに特に有用。
これにより、何か問題が発生した場合やパフォーマンスが低下した場合に、すぐにその原因を特定し、対処できる。
非同期処理のサポート
Callbacks機能は非同期処理に対応しており、これにより処理の効率が向上する。
ストリーミングや他の非同期タスクもスムーズに行える。
たとえば、大量のデータをリアルタイムで処理するようなストリーミングタスクでも、アプリケーションは安定して動作するように設計できる。
この機能により、開発者がアプリケーションの動作をより細かく制御し、管理できる。
Model I/O
- Prompts
- LLMs
- Chat Models
- Output Parsers
Prompts
プロンプトの管理・最適化・シリアル化などをすることができる機能。
LangChainを使わずともオリジナルのスクリプトでプロンプト管理などをすることはできるものの、LangChainを使うとパッケージ化されているため、少ないコードで記述できるという点で便利。
他にも、チームで開発をしている時に統一された記法でコーディングできるという点でも便利。
Promptsは、さらに下二つに分かれる
- Prompt templates
- Example selectors
Prompt templates
プロンプトをテンプレート化し、プログラミングによりプロンプトを生成するための機能。
単純に文章内の特定の単語を変数化して、虫食いにしたテンプレートだけでなく、教師データを入力するためのテンプレートも作成可能。
たとえば、フルーツの名前から色を出力する指示をするときに、「りんご:赤、キウイ:緑、ぶどう:紫」というように少数の教師データを入れるFew-shot Learningと言われる手法を使うときに便利。
Example selectors
大量の教師データからプロンプトに入力するデータを選択するための機能。
たとえば、100件の教師データがあった場合、その中から30個をランダム抽出するような機能を作るときに便利。
Language models
Language modelsとはOpenAIをはじめとした様々なサービスが提供しているモデルを切り替えたり、組み合わせたりすることができる機能。
LLMsとChat modelsの2種類に対応している。
LLMsとはLarge Language Modelsの略。
たとえば、OpenAIが出しているGPT3.5のモデル(text-davinci-003)やGoogleが出しているFlan-T5(flan-t5-xl)などがある。
Chat modelsとは、ChatGPTで用いられる「gpt-3.5-turbo」や「gpt-4」などのチャットに特化したモデル。
LLMs と Chat models 2つの違い
LLMsとChat modelsは、一見同じようなモデルに見えますが、大きく2つの違いがある。
基本的な動作
-
LLMs- 文字列(プロンプト)を入力として受け取り、文字列を出力(補完)する。 -
Chat models- チャットメッセージ形式で入力を受け取り、AIによるチャットメッセージを出力する。
APIのインターフェイス
-
LLMs- 単一の文字列をプロンプトとしてAPIに渡す
llm("AIを100文字で教えて。")
-
Chat models- 複数のチャットメッセージ(チャットのやり取り)をリスト形式でAPIに渡します。各メッセージには、内容(content)に加えて、役割(role)をラベル付けします。ロールには、"System"、"AI"、"Human"、"Function"などが用いられます。
messages = [
SystemMessage(content="あなたは英語から日本語に翻訳を行うアシスタントです。"),
HumanMessage(content="I love programming."),
]
chat(messages)
AIMessage(content="私は、プログラミングが大好きです。", additional_kwargs={})
このようにLanguage Modelsを用いることで、様々なLLMsやChat modelsを使うことができる。
LLMsだけでも、以下のようにかなりの数のサービスと連携しているため、複数のモデルを使いたい時にかなり便利。
Output Parsers
出力のデータ形式を指定するための機能。
たとえば、出力をカンマ区切りの形式や指定したクラスの形式で出力できる。
また、もしも指定したフォーマットにならなかった時に、そのフォーマットになるまで修正を繰り返してくれる機能などもある。