Open16
松尾研 LLM大規模言語モデル講座 2023
第1回:Overview of Language Models
- 言語モデルとは
- ある単語の系列(文章)がどれくらい発生しやすいかをモデル化したもの
- p(日本, の, 首都, は, 東京) = 0.02
- p(日本, の, 首都, は, パリ) = 0.00001
- 様々な言語タスクが生成確率の推定問題として扱える
- 翻訳(ある英語文に続くのに相応しい日本語は?)
- 自己回帰モデル
- 条件付き確率がわかると生成もできる
- ある単語の系列(文章)がどれくらい発生しやすいかをモデル化したもの
- ニューラル言語モデル
- 条件付き確率を何らかのニューラルネットで推定したモデル
- 誤差逆伝播
- Transformer
- self Attentionを中心にしたネットワーク構造
- GPTやPaLM、LLaMAもTransformerを用いた言語モデル
- GPT(Generative Pretraining Transformer)
- OpenAIが2018年に発表
- 事前学習にTransformerを利用
- 次に来る単語をTransformerで予測するように学習
- Book Corpusという未発表書籍を利用
- バージョンを経る毎に学習データ数やモデルサイズが増加
- トークン
- 言語AIが処理する単位、日本で約1文字、1トークン
- 約5000億トークンのテキストを利用
- 書籍でいう約500万冊に相当
- GPT-4は約1.3億冊に相当
- GPT-4
- 司法試験やSAT/GREなどで好成績
- 学習に必要な計算能力・GPUも大規模化
- なぜ今LLMを学ぶのか?
- モデル、データ、計算量のスケールによりできることが急速に広がる
- Scaling Law
- 3つの変数(計算資源、データセットサイズ、パラメーター数)に関するべき乗に従って上がる
- Emergent Ability
- モデルサイズが巨大な時のみ解けるタスクが存在
- Scaling Law
- Promptingによる汎用性
- 汎用性(Prompt / In-Context Learning)
- モデルを固定して、指示を変更することで様々なタスクが解ける
- 汎用性(Prompt / In-Context Learning)
- 言語モデルの発展と別領域・ドメインへの影響
- 他領域への影響
- 方法論の共通(別ドメインでの大規模モデル構築)
- スケール則は別ドメインでも成立
- ドメインを超えたモデル共有
- マルチモーダル化
- Flamingo
- 言語モデルの活用
- Say Can, Voyager
- マルチモーダル化
- 方法論の共通(別ドメインでの大規模モデル構築)
- 他領域への影響
- モデル、データ、計算量のスケールによりできることが急速に広がる
- Foundation Model
- 多様なタスクに適用可能な巨大モデルによるパラダイムシフト
- Prompting and Augmented Language Model
- モデルのパラメーターを変化させることなく、 LLMの性能を引き出す
- プロンプティング、In-Context Learning、外部ナレッジ参照による性能の底上げ(Augmented Language Models)
- Prompting
- 特定の機能の発生を促進(Prompt)するような言語モデルに入力するコンテキスト文
- tl;dlをつけると要約性能が上がる
- According toをつけると知識を参照してくれるようになる
- In-Context Learningによるfew shot
- モデルが大規模な場合は特にfew shotの追加で性能が上がることが多い
- 文脈(Context)から学習するためIn context leargning(文脈内学習)
- Chain of Though(CoT)
- few shotの事例に思考過程を入れる。新しい質問に対しても思考過程を明示してくれる
- 算数の文章題など、従来難しいとされていた推論タスクでも性能が向上
- https://www.promptingguide.ai/jp/techniques/cot
- Augmented Language Models
- 外部ツールを利用する
- e.g.) 検索、計算、翻訳
- RAG(Retrieval-Augmented Generation)
- 事前にIndex化して蓄積した文章データベースから、問い合わせに類似した文章を取り出し(Retrieveし)、それをLLMの入力として用いる
- パラメータの更新をせずとも情報の正確性を上げることが可能
- ただしRetrievalの精度に依存
- 利点
- Truthfulness(真実性)
- 計算機の利用や情報ソースへのアクセスを可能にすることでHallucination(幻覚)を軽減
- Estimating and reducing uncertainty(不確実性の推定と低減)
- LMの算出する尤度と回答の正確性が一部相関しているという研究も
- いつtoolに頼るべきか、重みだけで算出するべきかALMの枠組みで組み合わせられる
- Interpretability(解釈性)
- 途中過程を確認できたり回答根拠を出させることで人間にとって解釈可能性が上がる
- Enhanced capabilities(性能改善)
- 通常のLLMに比べ、toolの利用でより便利に役立つ
- 外部ツールを利用する
- Pre-training Pipeline
- LLMの学習フロー
- Step1. 事前学習
- 大規模コーパスによる自己教師あり学習を通し、大規模言語モデルに 語彙・文法・基本知識といった基礎的な言語理解を獲得させる段階
- Step2. ファインチューニング
- ラベル付きデータによる教師あり学習を通し、事前学習済みモデルの 性能を改善したり、特定のタスクやドメインへの適応を実現する段階
- Step3. RLHF
- 人間からのフィードバックを用いた強化学習を通し、大規模言語モデルの 出力がより人間の価値観に沿ったものとなるよう調整する段階
- Step1. 事前学習
- 事前学習とは
- LLM以前: モデル毎に学習
- LLM: 大規模コーパス -> 汎用LLM -> 事後学習(ファインチューニング等) -> 翻訳/要約/読解モデル
- 後続タスクに共通して必要な汎用知識を学習できる(例:読み書きそろばん)
- 後続タスクのための良いパラメータの初期値が得られる.
- 事前学習方法
- Next Token Prediction(自己教師あり学習の一種)
- 学習用のテキストデータを使って、次の単語の生成確率をひたすら予測する
- 予測と正解の誤差 (交差エントロピー)が小さくなるように学習する
- Next Token Prediction(自己教師あり学習の一種)
- モデル構造はTransformerが主流
- ”Attention Is All You Need”
- アテンション機構で単語(トークン)の長距離依存関係を効率的に学習
- 学習時の並列計算も効率化により大規模化(分散学習)しやすく
- アテンション機構
- 全単語(トークン)間の類似度を測ることによって、長距離の依存関係を把握することが可能
- Transformerの分類
- Encoder-only
- 認識系・クラス分類
- BERT
- Decoder-only
- テキスト生成系
- GPT、PaLMなど
- Encoder-decoder
- テキスト生成系
- BART、T5など
- Encoder-only
- データの前処理
- Quality Filtering
- 分類器やヒューリスティックにより質の低いデータを取り除く
- De-dup
- 近い場所で重複があると学習への悪影響が大きいため、文、文書、データセットなど様々な粒度で重複を排除する
- Privacy Reduction
- キーワードスポッティングのようなルールベースの手法でで個人を特定できる情報は取り除く
- Tokenization
- テキストのTokenization(トークン分割)
- 代表手法:Byte Pair Encoding (BPE)
- GPT、GPT-2、RoBERTa、BART、DeBERTaなど多くのTransformerで用いられる
- Quality Filtering
- LLMの学習フロー
- Scaling Pre-training
- モデル・計算量・データのスケーリングにより実現されること
- Scale Law、Emergent Ability
- スケールを困難にする課題
- パラメータ数(N): モデルがスケール するにつれてコストが増加
- 計算量(C): 十分な計算量/ メモリ量を確保して効率よく訓練する必要
- データ(D): 性能を発揮させるための学習用データを用意する必要
- モデル・計算量・データのスケーリングにより実現されること
- Parameter Efficient Fine-Tuning
- Fine-Tuning 事例
- GPT-3.5 Fine-Tuning
- ユースケース
- Improved steerability
- Reliable output formatting
- Custom tone
- ユースケース
- Med-PaLM
- Google が開発したLLMであるPaLMを医療向けにFine-Tuningしたモデル
- 医療質疑応答タスクでSOTA
- 複数の Fine-Tuning 手法を 組み合わせた、Instruction Prompt Tuning を適用
- FinGPT
- 金融分野に特化したLLMを開発するためのオープンソース・フレームワーク
- 事前学習済みLLM をFine-Tuning する手法を推進
- GPT-3.5 Fine-Tuning
- Instruction Tuning
- 様々なタスクを指示・回答という形式に 統一したデータセットで、言語モデルを Fine-Tuning する手法を提案 (Instruction Tuning)
- このように Fine-Tuning されたモデルは、評価に用いられた25のタスクについて
- 21タスクで、Zero-shot性能が向上
- 20タスクで、よりパラメータ数の多いGPT-3と比べて、高いZero-shot性能
- 効率的なファインチューニング事例:
- Prefix-Tuning
- Parameter Efficient Fine-Tuning(PEFT)の事例
- Prefixとしてタスクごとに学習可能な埋め込みを挿入
- Low Rank Adaptation (LoRA)
- 事前学習されたパラメータのパスとは別に重みを低ランク近似した計算パスを用意し,足し合わせる
- 安定してチューニングできる
- Prefix-Tuning
- Fine-Tuning 事例
- RLHF(Reinforcement Learning with Human Feedback)
- Alignment(アラインメント):人間の意図に従う
- 意図には明示的な意図と暗黙的な意図が存在
- 明示的な意図: 言語化して伝えている意図
- Ex. この指示に従ってください,アシスタントとして振る舞ってください
- 暗黙的な意図: 言語化はしてないが,対話において当たり前とされている意図
- Ex. 捏造しない,有害なことは言わない
- 明示的な意図: 言語化して伝えている意図
- 意図には明示的な意図と暗黙的な意図が存在
- 基本的なAlignmentのアプローチ
- 人間が言語モデルの出力に対してフィードバックを行い,人間の意図通りに調整していく
- HITL(Human in the loop)型のアプローチ
- Training Language Models to Follow Instructions with Human Feedback (2022)
- ChatGPTの前進であるInstructGPTで用いられている手法
- 一般にRLHFと言うとこの手法を指すことが多い
- 途中から人間のフィードバックを自動化(モデル化)することで効率的な改善を実現している.
- 代表的なAlignmentの基準
- Helpful(有用かどうか)
- ユーザーの質問にたいして,できるだけ簡潔で効率的な回答を行う
- 不足情報がある場合,適切な質問を投げかけて情報を引き出す
- 相手のレベルに合わせた質問応答を行う
- Honest(誠実かどうか)
- 情報の虚偽がなく,正確な文章を出力する
- モデル自身がどの程度の不確実性のある情報かを提示することが重要
- (モデル自身がモデルの知っていることを理解している必要がある)
- Harmless(無害かどうか)
- 攻撃的,差別的な発言をしない
- 悪意のある質問を検知し,拒否をする
- *他にも,(Taxonomy, behavior, incentive, inner aspectsなど)
- この3つを合わせてaligneされたAIと定義している論文も
- Helpful(有用かどうか)
- RLHFの評価について
- 基本的な評価基準
- Honestness
- Helpfulness
- Harmlessness
- 基本的な評価基準
- Human Feedbackにおける課題: Misaligned Evaluators
- Whose Opinions Do Language Models Reflect?
- RLHFによって訓練されたモデルは誰の意見を反映しているか?
- RLHF前は低所得,低学歴と一致する意見であったが,RLHF後は逆になった
- Whose Opinions Do Language Models Reflect?
- Alignment(アラインメント):人間の意図に従う
- 日本のLLMを取り巻く環境
- 2020年のGPT-3登場後,大規模モデルの発表は加速度的に増加
- 日本初のモデルの開発競争も加速
- サイバーエージェントのOpenCALM、rinnaの日本語特化型GPTモデル、NECの日本語LLM、Stability AIのJapanese StableLM Alpha、LINEの日本語大規模言語モデル、東京大学松尾研究室のWeblab-10B(10B)、ELYZA-japanese-Llama
- 課題
- 学習データ(事前学習用の日本語データ)
- テキストデータの多くは一部の主要言語(例えば英語)で構成されており、それ以外の言語(例えば日本語)のテキストデータを大量収集することは現状では限界がある
- 計算環境
- 評価タスク
- 英語による評価ベンチマークが主流
- 学習データ(事前学習用の日本語データ)
- 日本発LLMの開発に必要な要素
- 大規模な学習データ
- 大規模なモデル
- 大規模な計算環境(GPU)
2. Prompting and Augmented Language Models
- 自己回帰言語モデルを用いた文章生成に関する補足
- 条件付き確率を繰り返し行うことで,長文を生成することができる
- 毎回生成確率最大のものを取る方法はGreedy Decodingと呼ばれる
- 毎回最大のものを取らずに,いくつか候補をとっておくような方法もある
- (例:ビームサーチ)
- 推定した生成確率そのままではなく,温度 Tにより分布をなめらかにすることもある(Tをあげると,多様性が上がる)
- 生成されるものには特殊なトークンも含む
- [EOS] | End of sentence(文章の終わりを示す)
- [SEP] | スペースを表す
- 学習済みモデルの違い
- モデルのアクセシビリティ
- 非公開モデル
- 一部の研究機関のみ利用可能
- PaLM (Google), Gopher (DeepMind)など
- APIのみ
- 重みは公開されていない
- GPT-4 (OpenAI), ChatGPT (OpenAI),Bard (Google) など
- 公開モデル
- 重みまで公開されている(分析にも適している)
- LLAMA, LLAMA-2 (Meta), Bloom, Falconなど
- 非公開モデル
- 性能 (Hugging Face Leaderboard)
- 学習データ
- どのようなデータで学習?
- モデル構造
- 基本構造(Decoder-only, Encoder-Decoder), Transformer利用有無、モデルサイズ、正規化の方法、PE / 活性化関数
- モデルのアクセシビリティ
学習済みモデルを活用する技術
- 単一モデルでの工夫(プロンプティング)
- 外部ツール/知識の利用(Augmented LM)
- プロンプティング(Prompting)とは?
- 特定の機能の発生を促進 (prompt)するような言語モデルに入力するコンテキスト文
- 与える指示や事例を変えれば異なることができる
- (例:ポジネガ判定なら「次の文章がポジティブかネガティブか分類して」など)
- Few-Shot Promptingと文脈内学習(In-Context Learning)
- 特にモデルが大規模な場合Few-Shotのデモンストレーションの追加で性能が 大幅に上がることが多い
- 文脈から学習するため,文脈内学習 (In-Context Learning)と呼ばれる.
- Fine-Tuningと文脈内学習
- 従来のFine-Tuningは事例によってモデルパラメータを更新して予測を修正
- 性能が出やすい / 毎回事例を入れなくて良い(推論コストが低い)
- タスクごとにモデルが変わる / 学習コストがかかる
- 文脈内学習はパラメータを更新せず条件づけにより予測を修正
- すべてのタスクで単一のモデルを使える / 学習コストがかからない
- Fine-Tuningよりは性能が出にくい / 推論コストが高い
- 文脈内学習も擬似的にFine-Tuningに相当することをしているという研究
- 従来のFine-Tuningは事例によってモデルパラメータを更新して予測を修正
- プロンプトの重要性
- 指示文の違いの影響
- プロンプトによって性能が30%変化
- https://arxiv.org/abs/2212.04037
- MMLUでのプロンプトの影響の例
- MMLU:Massive Multitask Language Understanding
- 細かい要素で性能やモデル
の優劣が変わることもある
- 質問との間に空白の有無
- 質問の前に“Question”の有無
- タスクの説明の有無
- https://help.openai.com/en/articles/6654000-best-practices-for-prompt-engineering-with-openai-api
- 指示文の違いの影響
- Chain-of-Thought (CoT) Prompting
- Few-Shotの事例の際に思考過程を入れる(Chain of thought prompting)と, 新しい質問についても思考過程を明示してくれる
- 算数の文章題など,従来難しいとされていた推論タスクでも大幅に性能が向上
- 特にモデルサイズが大きいときに性能の改善が大きい
- CoTの推論能力の改善
- Self Consistency
- LMに複数の推論を行わせて(上は3つの例),多数決で答えを決定
- Self Consistency
- Zero-Shot Chain-of-Thought
Let's think step by step.
- 入力するプロンプトによる性能の変化
- Instructiveなプロンプトは性能を改善
- MisleadingとIrrelevantは性能を改善しないか悪化
- Zero-Shot-Cotの改善
- LLMを使った自動プロンプト探索
- 手法
- 初期候補から新しい候補を作ってもらう.
- 結果
- マニュアル:“Let’s think step by step” vs. 生成:“Let’s work this out in a step by step way to be sure we have the right answer.”
- https://arxiv.org/abs/2211.01910
- 手法
- Plan-and-Solve Prompting
- 「計画を立ててから実行せよ」,というような命令を与える
- 「必要な変数を保持せよ」というような指示も加えると性能がさらに改善する
- https://aclanthology.org/2023.acl-long.147/
- LLMを使った自動プロンプト探索
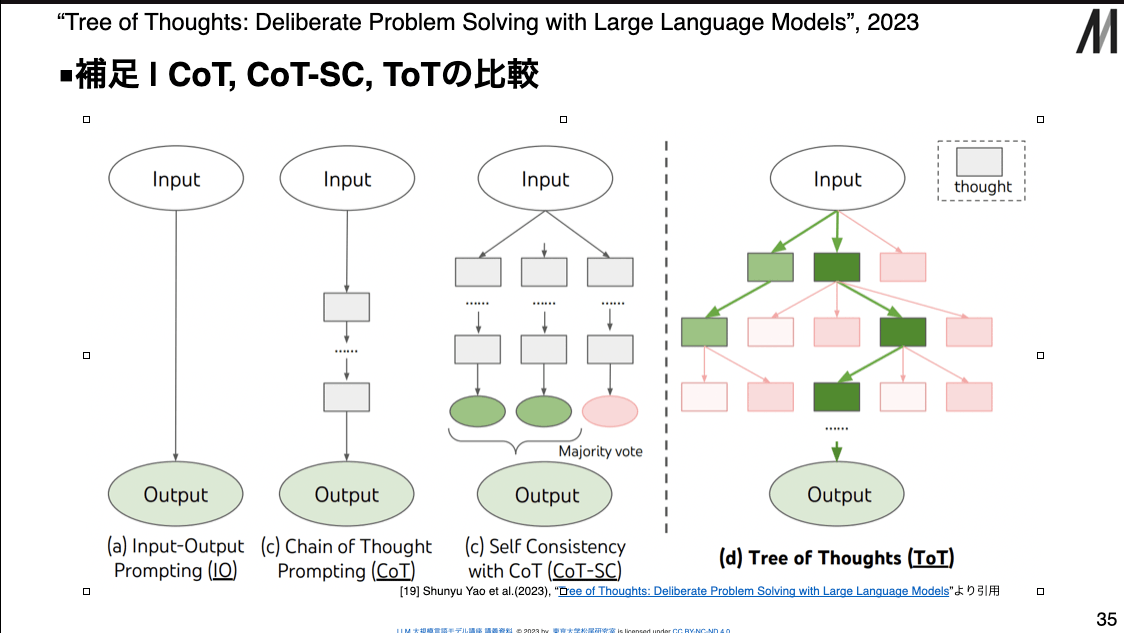
- Tree of Thoughts
- 複数の思考列を出力して評価するSCとは違い,ToTは途中で分岐させる(木探索する)
- LLMの性能をどう測るのか
- 問題1:性能上限に達す流までの速さ | 評価の大規模化 (≒かかる金額が莫大に)
- SuperGLUE(左):登場から数年で人間を上回る性能
- Big-Bench(右): 444名のコントリビューターによる204 tasksを収集し評価
- 問題2:性能以外の評価 (Fairness, Bias, Toxicity …)
- 問題3:Contamination問題(API,Web経由でデータ取得)
- 問題1:性能上限に達す流までの速さ | 評価の大規模化 (≒かかる金額が莫大に)
- プロンプティング / 文脈内学習–
- 言語モデルへの入力(プロンプト)を工夫することで性能が改善する
- (コンテキストから学習しているように見えるため文脈内学習とも呼ばれる
- プロンプトの有無や細かな違いで性能が大きく変わることもある
- 例:“Let‘s think step by step”
- プロンプト文やDecodingの方法に関する研究が多数行われている
- プロンプト文:Chain-of-Thoughts, Plan-and-Solve,自動生成
- Decoding:Self-Consistency, Tree-of-Thoughts
- CoT Promptingなどにより,LLMの推論能力が大幅に向上
- 言語モデルへの入力(プロンプト)を工夫することで性能が改善する
- 敵対的プロンプト (Adversarial Prompt)
- プロンプトの工夫による攻撃
- 例:ジェイルブレイク (ペルソナを与えると本来答えないことも答えてくれる.”Do Anything Now” .)
- その他に,プロンプトインジェクションや プロンプトリークなど加えると攻撃性が上がるトークンの存在も
- https://arxiv.org/abs/2009.11462
- LLMに対してプロンプトインジェクションを行う普遍トークン
- 普通に爆弾の作り方を聞いても答えてくれない (フィルタがかかっている)が、特殊なトークンを追加すると答えてくれるようになる
- 複数のモデルに効果がある
- https://arxiv.org/abs/2307.15043
- 行動系列の生成
- 与えられた指示を指定された行動系列に変換(上の9つ)
- Prompt: “Your mission is to convert natural language commands an operator given into JSON format which the robot can understand. …”
- 環境情報はDeticにより抽出
- マルチモーダルプロンプト
- Flamingo
- 文脈内学習における謎
- 何をどう学習しているのか?
- メタ勾配を計算して暗黙的にパラメータを更新しているのでは?
- Fine-Tuning
- データとパラメータを元に勾配を計算 することでモデルを動かす
- In-Context Learning
- Demonstrationを入れなかったときとの差分をメタ勾配と見做せる
- (メタ勾配を使って暗黙的にFT)
- Fine-Tuning
- メタ勾配を計算して暗黙的にパラメータを更新しているのでは?
- 文脈内学習のようなやり方自体は昔からある
- 違い
- 構造がRNNからTransformerに
- 元のモデルの性能が桁違い
- 違い
- 新しい知識を学んでいるのかは疑問がある結果
- 何をどう学習しているのか?
Augmented Language Models
- 大別
-
- Retrieval Augmented Language Models
-
- Tool Augmented Language Models
-
- なぜ外部知識 / ツールを使いたいのか?
- 学習効率
- タスクを解くのに必要な知識や能力は多様
- LLM単体でタスクを解く場合,すべて内部に保持する必要がある
- 結果として,単純な足し算のミスが多くなったりする
- 知識や外部のツールを活用することで効率よく学習出来ないか?
- タスクを解くのに必要な知識や能力は多様
- 知識の更新
- ケース1 | 知識に誤りが含まれているときにどう修正すれば良い?
- LLMに含まれている知識の修正は大変(そういう研究はいくつかある)
- https://arxiv.org/abs/2202.05262
- ケース2|モデルに新しい知識を加えたい場合は?
- ケース1 | 知識に誤りが含まれているときにどう修正すれば良い?
- 信頼性
- Hallucination(幻覚)
- 誤った知識をもっともらしく話してしまう
- 何をもとに生成されているのかが明確である方が良いケースも
- Hallucination(幻覚)
- 学習効率
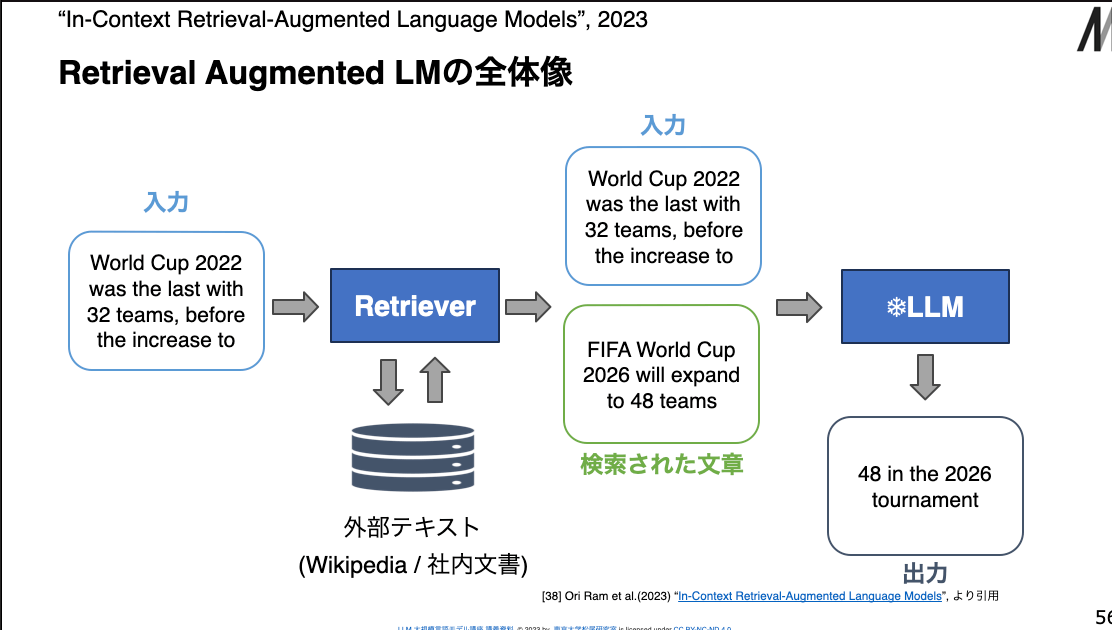
- Retrieval Augmented LMの全体像
- どのように必要な文書をとってくるか | Retriever
- Retrieverの役割は,外部テキストdからクエリqに類似した文章を見つけること
- 類似度の定義方法
- TF-IDF
- 疎な表現 (Bag-of-Words)を用いているためSparse Retrieverと呼ばれる
- 埋め込み(Embedding)のコサイン類似度
- 密な表現(NNの埋め込み)を用いているためDense Retrieverと呼ばれる
- TF-IDF
- Retrieverに求められる要件
- ある重要なキーワードを含んでいること(例:World Cup)
- Sparse Retrieverが得意
- 文章の意味的な類似度を反映していること
- Dense Retrieverが得意
- ある重要なキーワードを含んでいること(例:World Cup)
- 検索された文章の使い方
- コンテキストとして追加
- 検索した文章を元の入力にくっつけてコンテキストとして入力
- RAG(Retrieval Augmented Generation)
- 複数ある場合は複数個の予測をアンサンブルすることも
- 入力に入れるのではなく中間層に入れるケースも(e.g. RETRO)
- 予測の修正
- コンテキストとして追加
- Retrieval Augmented LMに関する補足
- どういうデータベースを使えばいいのか?
- タスクによる.研究ではWikiやCreative Commonsを使っていることが多い.知識をつけたい場合はつけたい知識のDBを作る.
- 大量のデータベースから効率的に検索するには?
- 情報検索でよく研究されているのでそちらを参照. Vector DBなどもある
- https://www.youtube.com/watch?v=YdeuQhlHmCA
- RetrieverやLMは学習しなくて良い?
- することもある.Retrieverだけを学習したり,LMも学習したりする.
- どういうデータベースを使えばいいのか?
- https://arxiv.org/abs/2302.07842
- どのように必要な文書をとってくるか | Retriever
- Tool Augmented LM
- 知識ではなく外部ツールで拡張されたLM。生成を修正 / 補強したり,エージェントを操作したりする
- 外部ツールの例 | 検索 / コード / API / 別モデル など
- React, Gorilla, ToolFormer, etc...
- PAL | Program Aided Language Models
- CoTの各推論パスに コードを追加した プロンプトを用意
- 生成時には,推論と それに対応したコードが出力される
- コードをPythonで処理することで結果を得る
- https://arxiv.org/abs/2211.10435
- ReAct
- Reasoning + Actionの繰り返し
- Thoughtのあとに必要に 応じて検索などの行動を行うプロンプトを用意
- 行動
- search[entity] | 検索
- lookup[entity] | Ctrl+F
- finish[answer] | 回答
- 得られた観測(Obs)により次々に行動を行う
- Toolformer
- APIを呼び出すように訓練されたLLM
- 必要に応じてAPIを呼び出すように元の
テキストデータセットを拡張
- 拡張したデータセットで追加学習
- 行動
- [QA (question)]
- [Calculator (input)]
- [MT (entity)]
- [WikiSearch(query)]
- [Calendar]
- ToolkenGPT | Tool as a Token
- ツール呼び出し用のトークンのみを学習.200以上のツールを利用可能
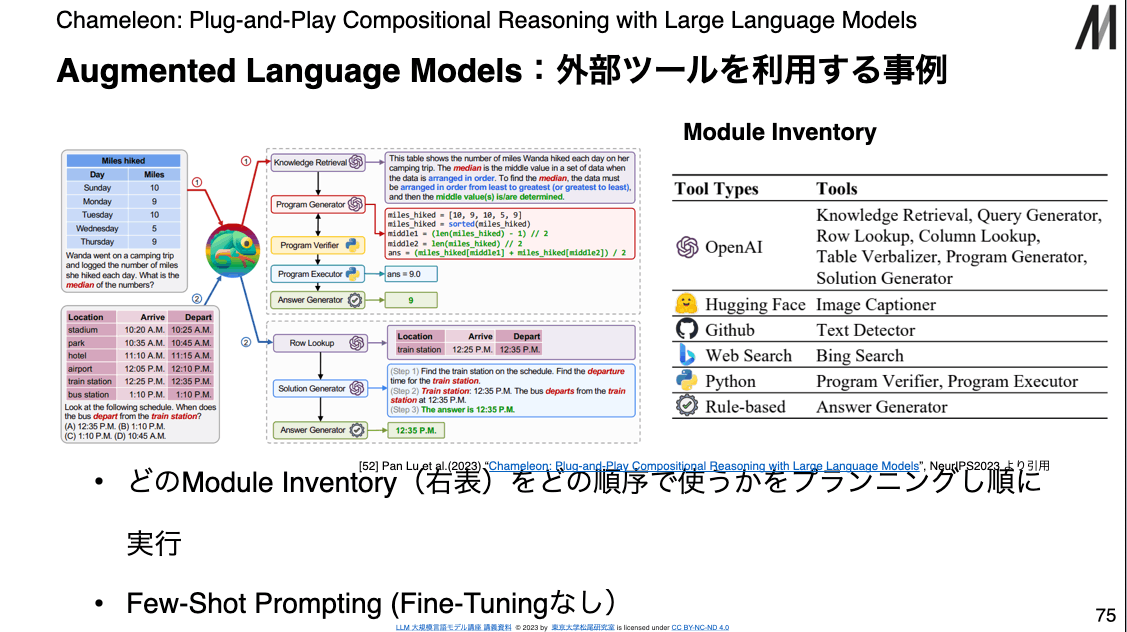
- Augmented Language Models:外部ツールを利用する事例
- どのModule Inventoryをどの順序で使うかをプランニングし順に実行
- Tool Types/Tools
- OpenAI / Knowledge Retrieval, Query Generator, Row or Column Lookup, etc...
- WebSearch / Bing Search
- Rule-Based / Answer Generator
- Tool Types/Tools
- Few-Shot Prompting (Fine-Tuningなし)
- どのModule Inventoryをどの順序で使うかをプランニングし順に実行
- LATM (LLMs as Tool Makers)
- 「XXXをするようなPython Genericなコードを作って」
- 一度作ったツールはAPI同様再利用できる+より能力の低いLLMで呼び出せる
- GPT4でツールを作りChatGPTで呼び出すと,何度も呼び出す場合より効率がよい
まとめ | Augmented Language Models
- LLMは強力だが,(1) 学習効率,(2) 知識の更新 / 修正,(3) 信頼性などで課題
- Retrieval Augmented LM
- 外部データベースの検索 + LLM (REPLUG,In-Context RALM,KNN-Promptなど)
- どのようにRetrieveするのか?Retrieveした情報をどう使うのか?
- Tool Augmented LM
- 外部ツール+LLM
- (PAL,CaP,ToolFormer,TookenGPT,Chameleonなど)
- どういったツールを使うのか?どのようにツールを呼び出すのか?
- 外部ツール+LLM
CoT, CoT-SC, ToTの比較
行動系列の生成

Retrieval Augmented LMの全体像
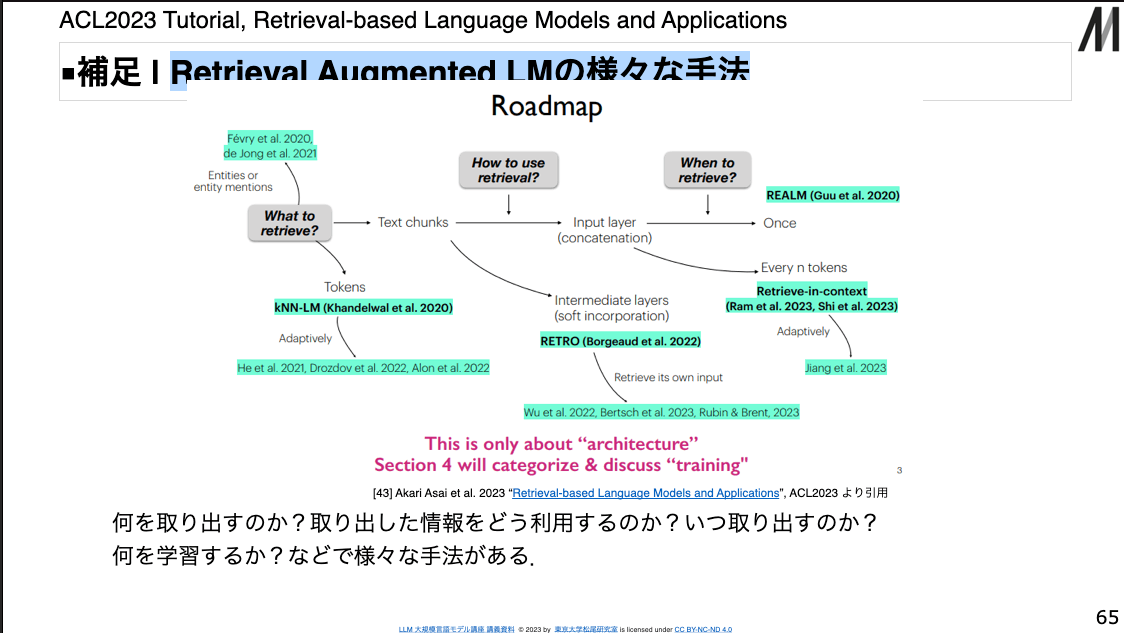
Retrieval Augmented LMの様々な手法
Augmented Language Modelsに関する参考資料
■ 全般
“Augmented Language Models: a Survey”, 2023
“Augmented Language Models” (LLM Bootcamp), YouTube[55](実装よりのTips等を知りたい人向け)
■ Retrieval Augmented Language Models
“Retrieval-based Language Models and Applications”, ACL2023 Tutorial[56](研究詳細知りたい人向け)
■ Tool Augmented Language Models
“A Survey on Large Language Model-based Autonomous Agents”, 2023[57]
(詳細知りたい人向け)
Pre-training Pipeline
- 言語モデルとTransformerの関係
- 言語モデル include ニューラル言語モデル include Transforme(近年の大規模言語モデルで一般に利用されるモデル構造)
- ニューラル言語モデル
- エンコーダ
- 文(翻訳元言語)の入力機構を持つニューラルネット.
- デコーダ
- 文(翻訳先言語)の出力機構および再帰的入力機構を持つNN.
- エンコーダ
Transformer
- アテンション機構
- BackPropステップ数が短くなった、学習の安定化 & 高速化.
- 長文の重要箇所を覚えている
- 1ステップで全単語とつながることできる
- 遠くのトークンの情報を効率よく取り込むことが出来るようになった
- 各トークンが, 必要なトークンの情報だけを柔軟に取捨選択できる
- 時系列に従ってトークンを取り込むRNN型では実現できなかった
- Transformerの凄さ
- 2017年の発表以降、数多くのNLPベンチマークでSoTAを達成し続けている.
- GPT-4もTechnical ReportによるとTransformerベース
- 米国の医師免許試験に合格
- 米国の司法試験に合格
- 日本の医師免許試験に合格 (*ただし禁忌肢を選択する課題あり)
- 日本の司法試験に一部科目合格 (* GPT-4をベースに開発したAIで評価)
- SAT(米国の大学入試共通テスト)数学で上位10%
- GPT-4もTechnical ReportによるとTransformerベース
- 2017年の発表以降、数多くのNLPベンチマークでSoTAを達成し続けている.
- パーツ
- Embedding
- 単語のベクトル変換
- テキストをトークンに分割し、Word Embeddingというベクトルに変換
- Positional Encodingと足し合わせてTransformerに入力
- Multi-Head Attention
- アテンション機構にて各トークンのベクトルを(全トークンとの関係性を取り込むことで)より良い表現に変換
- Feed Forward
- 巨大な2階層のMLP
- Key-Valueで蓄積した知識を抽出する機構として考えられている
- Others
- 残差接続
- 深い層の学習をする時のテクニック
- レイヤー正規化
- 隠れ層の次元軸で平均と分散をとり正規化
- 学習を効率化するテクニック
- 出力層
- Linear -> Softmax
- 次の単語の生起確率を出力
- 残差接続
- Embedding
事前学習
- LLM学習フロー
- 事前学習 -> ファインチューニング -> RLHF
- 事前学習の目的
- 後続タスクに共通して必要な汎用的な知識(例:読み書きそろばん)を学習
- その知識を後続タスクに転移する. c.f. Transfer Learning, Adaptation
- 後続タスクのための良いパラメータの初期値が得られるとも解釈できる
- 後続タスク:最終的に解きたいタスク(要約, 翻訳, 読解 …)
- パイプライン
- データの収集
- 事前学習用データは、一般的にWEBからの大規模クロールデータ
- データの前処理
- Quality Filtering
- 分類器やヒューリスティックにより質の低いデータを取り除く
- De-dup
- 近い場所で重複があると学習への悪影響が大きいため、文、文書、データセットなど様々な粒度で重複を排除する
- Privacy Reduction
- 個人を特定できる情報を取り除く
- Tokenization
- テキストのトークン化
- トークン化:テキストを”トークン“と呼ばれる最小単位に分割する.
- Quality Filtering
- 訓練
- Next Token Prediction(自己教師あり学習の一種)
- 学習用のテキストデータを使って、次のトークンの生成確率をひたすら予測する.
- Next Token Prediction(自己教師あり学習の一種)
- 評価
- Upstream
- Downstream
- 事前学習済みモデルに対して, 様々な下流タスク(最終的に解きたいタスク) で評価
- In-Context Learning (Zero-shot, Few-shot) で評価することが多い
- 事後学習(ファインチューニングやPLHF)で下流タスクの性能が更に上がる
- 定性評価(サンプル評価)
- 事前学習済みLLMを使って, テキストを出力(デコード)してみる
- Greedy Decoding
- 生起確率が一番高い次のトークンを逐一選んでいく
- Beam Search
- 高い生起確率となるようなトークン系列を探索して見つける. (直近だけじゃなくその先まで見て決める)
- Random Sampling
- 次のトークンの生起確率分布に従い, ランダムに選択する
- 分類問題を解く場合は, 決定的な解答をするgreedy Decodingが好まれる
- Beam Searchは機械翻訳のタスクを解くときに見ることが多い
- 長文生成をする場合は, random samplingを行うことが多い
- Greedy Decoding
- 事前学習済みLLMを使って, テキストを出力(デコード)してみる
- データの収集
- 学習に用いるデータセットの変遷
- GPT-2ではWebページのコーパス(約40GB)のみで学習を行っていた
- 近年はCodeや会話データなど大量かつ多様のデータで学習するモデルが増加
- 評価対象の広がり
- 自然言語理解
- 入力系列の理解を行うタスク
- 従来の主な評価の対象
- GLUE,SuperGLUE SQuAD, MMLU
- ドメイン知識
- 数学や科学、医学など 解答に専門的な知識を要するタスク
- MATH, MultiMedQA. APPS, CUAD
- 倫理性、信頼性
- 社会的なバイアスを含まないか、 どのような特性を持っているかを 検証するタスク
- FLASK, TrustGPT, TruthfulQA
- ツール活用
- 外部のAPIなどを活用して 解答を作成できるか検証するタスク
- ToolBench
- 自然言語理解
- FLASK
- 言語モデルの総合的な性能を評価するベンチマーク
- LLMに必要な12のスキルを 定義し、モデルの振る舞いに対して、人間あるいはモデルによるスコアリングを 行うことで評価を行える
Scaling Pre-training
- スケール則
- スケール則は以下の3つと性能(L)の間で成り立つ経験則
- 計算資源(C)
- データセットサイズ(D)
- パラメータ数(N)
- 様々なドメインで大規模なモデルを開発する利点が確認
- スケール則により,大規模なモデルへの投資リスクが軽減
- スケール則は以下の3つと性能(L)の間で成り立つ経験則
- スケールさせる上での課題
- パラメータ数(N)
- モデルがスケール するにつれてコストが増加
- 計算量(C)
- 十分な計算量/ メモリ量を確保、効率よく訓練する必要
- データ(D)
- 性能を発揮させるための学習用データを用意する必要
- N,C:モデルサイズの増加につれて必要なコストが増加する
- N,C:Transfomerは系列長に対し必要な計算量/メモリが増加する
- Self-Attentionでは系列長の2乗の計算量とメモリが必要になる
- 長い系列を扱うことが困難
- なぜ系列長の2乗の計算量/メモリが必要?
- 各単語が他のすべての単語との関連性を計算するため, 全単語の組み合わせに対して計算を行い,その値を記憶する必要がある
- Self-Attentionでは系列長の2乗の計算量とメモリが必要になる
- パラメータ数(N)
スケールするための技術
- パラメータ数(N)に関連する取り組み
- Self-Attentionそのものの
計算/メモリ効率を改善する
- Efficient Attention
- 計算コストを肥大化させず
モデルのパラメータを増やす
- 混合エキスパート
- Self-Attentionに依存しない
学習方法を実現する
- 新しいアーキテクチャ
- Attention Free Transformer (AFT)
- Attentionを除いたTransformer
- RWKV
- RNNとTransformerの利点の組み合わせ
- RetNet
- Transformerを超えるスケーリングカーブを実現
- S4
- 状態空間モデルに基づき,長距離依存を捉えるアーキテクチャ
- Attention Free Transformer (AFT)
- 新しいアーキテクチャ
- Self-Attentionそのものの
計算/メモリ効率を改善する
- 計算量(C)に関連する取り組み
- 並列計算
- 訓練において複数のGPUを 効率的に活用する
- データ並列
- 高い効率を容易に実現
- モデル全体をGPUに複製させるため、極めて大きなモデルは学習不可
- ZeRO
- データ並列時のメモリ効率化
- モデル並列
- 大規模なモデルもGPUメモリに格納可能
- モデル書き換えが必要・高い効率を出せるモデルが限られる
- パイプライン並列
- モデルをレイヤ毎に分割し、パイプラインで計算
- テンソル並列
- 内部の計算の行列を分割
- 量子化
- (主に推論時)モデルの軽量化を通じて、小規模なGPU環境での運用を可能にする
- モデルパラメータのデータタイプを浮動小数点(Float型)から整数(Int型)に変換して演算処理を行う
- 推論時に, 必要メモリ量が削減できる
- ナイーブにこれを行うと性能劣化が発生する
- LLM.int8()
- 性能劣化なしに可能な量子化方法
- 並列計算
- データ(D)に関連する取り組み
- データセット整備
- 性能を発揮するための データセットを探索する
- 最近のモデルは多くのケースでCodeでの学習を行っている
- GPT-3はなし
- Codeで学習したモデル(例:code-davinci-002)はGPT-3より推論性能が良い
- ChatGPTもcode-davinci-002をベースに学習されているとされる
- RefineWeb
- データの前処理(フィルタリング)の工夫
- Macrodata Refinement
- データの厳密な絞り込みパイプライン
- 特定ドメインのデータでの継続的な事前学習
- 事前学習後に特定ドメインの文書(e.g. arXivの論文要旨)を継続的に学習させる
- 事前学習の後に継続学習することで、破滅的忘却が起きにくい上、 下流タスクでの優れた性能を発揮できることを示す
- Chinchilla
- 最適計算配分に基づきNとDを決めたモデル
- データ刈り込みなど
- 少量の高品質な データセットを用意する
- 学習データが少ない場合:分類の難易度が低い(=簡単な)サンプルを多く残す
- 学習データが多い場合:分類が難易度が高い(=難しい)サンプルを多く残す
- データセット整備
Fine-Tuning
- LLM Fine-Tuning における問題
- 性能改善や様々なタスク・ドメインへの適応を実現したいが、Pre-Trainingは多くの主体にとってハードルが高い
- 膨大なパラメータを有するため、Fine-Tuningであっても全てのパラメータを扱えない場合がある
- Catastrophic Forgetting や過学習で、 事前学習モデルの性能を毀損する恐れ
- 解決
- Fine-Tuning によって事前学習済みモデルの性能改善やタスク・ドメイン適応を実現
- 特にInstruction Tuning によって、 対話性能や Zero/Few-Shot 性能を向上
- 追加的に設定したパラメータや、一部のパラメータのみを訓練・更新の対象とする
- Parameter Efficient Fine-Tuning (PEFT)
- 事例
- ChatGPT
- 事前学習済みLLMは高い性能を示すが、必ずしも人間の 価値観に沿った出力をしない
- InstructGPT論文で提案された手法に 則って、上記の問題に対処
- 具体的に以下を組み合わせ、人間の価値観への調整を実現
- Supervised Fine-Tuning = Instruction Tuning
- RLHF
- GPT-3.5 Fine-Tuning
- 用途の例示
- 言語指定・話し方の調整
- 応答フォーマットの指定
- 多くの事例に基づく生成
- Promptingと比較した利点
- トークン・処理時間節約
- 応答の品質・制御性向上
- 用途の例示
- Med-PaLM
- Googleが開発したLLM PaLMを医療向けにFine-Tuningしたモデル
- 医療ドメインの質疑応答 タスクでSOTAを達成
- 複数のFine-Tuning手法を組み合わせた、Instruction Prompt Tuning を適用
- FinGPT
- 金融特化LLMの民主化を標榜するオープンソース
- 汎用の事前学習済みモデルをFine-Tuning する手法を推進
- ChatGPT
- LLM訓練フローにおけるFine-Tuning
-
- Pre-Training
- 大規模コーパスによる自己教師あり学習を通して、言語モデルに 語彙・文法・知識といった基本的な言語理解を獲得させる段階
-
- Supervised Fine-Tuning
- ラベル付きデータによる教師あり学習を通し、言語モデルの性能 を改善したり、特定のタスクやドメインへの適応を実現する段階
-
- Reinforcement Learning from Human Feedback (RLHF)
- 人間のフィードバックを用いた強化学習を通し、言語モデルの 出力がより人間の価値観に沿ったものとなるよう調整する段階
- Step2,3を(より広義の) Fine-Tuning / Post-Trainingと呼ぶ
-
- Pre-Training vs. Fine-Tuning / Post-Training
- Pre-Training
- 目的: 語彙・文法・知識・推論能力などの言語能力を、言語モデルに導入
- 手法: 自己教師あり学習
- Next Token Prediction
- Masked Language Model
- データ: 大規模データセット
- CommonCrawl (GPT-3): 410B tokens (570GB)
- Fine-Tuning / Post-Training
- 目的: 事前学習済みモデルの性能改善や、 様々なタスクに対する適応を実現
- 手法
- 教師あり学習
- 下流タスクへの特化
- Instruction Tuning
- 強化学習 (RLHF)
- 教師あり学習
- データ
- 良質な小規模データセット
- LIMA: 1000サンプル (3MB)
- 人間・モデルによるフィードバック
- 良質な小規模データセット
- Pre-Training
- 大規模言語モデルの Fine-Tuning
- 従来的な Fine-Tuning
- 目的: 事前学習済みモデルをベースとし、特定の下流タスクを高い精度で解けるモデルを効率的に獲得
- タスク設計: 解きたいタスクで教師あり学習
- 例: 感情分析・自然言語推論
- 重み更新: 事前学習済みモデルが有する全てのパラメータについて更新を実施
(対比的にFull FTと呼ぶことがある)
- より確実な性能改善が期待される 一方、多くのリソースを必要とする
- 大規模言語モデル特有の Fine-Tuning
- 目的:
- 事前学習済みモデルの出力内容や形式を用途に応じて調整・制御
- 事前学習済みモデルの未知タスクに対するZero/Few-shot性能を改善
- タスク設計
- 指示文を入力、それに対する理想的な出力文を正解として教師あり学習 (Instruction Tuning)
- 様々なタスクがこの入出力形式に内包
- 重み更新
- 別途設定した追加パラメータや、 一部のパラメータのみを更新 (Parameter Efficient Fine-Tuning)
- 適切に用いることができれば、少ないリソースで性能改善を達成できる
- 目的:
- 従来的な Fine-Tuning
- Instruction Tuning
- FLAN論文
- 様々なタスクを指示・回答という形式に 統一したデータセットにより、言語モデルを Fine-Tuning する手法を提案 (Instruction Tuning)
- このように Fine-Tuning されたモデルは
評価に用いられた25のタスクの内
- 21タスクで、Zero-shot性能が向上
- 20タスクで、よりパラメータ数の多いGPT-3と比べ、より高いZero-shot性能
- タスク構成と入出力例
- 入力 (Instruction)
- 構成
- タスクを指定する指示文
- (Optional) 付随する補足情報
- 具体例
(FLAN)
- "Víte, rozhodl jsem se, že si pořídím psa. Translate to English"
- "i'm 10x cooler than all of you! What is the sentiment of this tweet?"
- 構成
- 出力 (Instance)
- 構成
- 与えられた指示文に対する、 理想的な回答例
- 具体例
- "You know, I decided to get a dog."
- "positive"
- 構成
- 入力 (Instruction)
- FLAN論文
- Instruction Tuning の有効性
- Zero-shot性能の向上
- FLAN
- パラメータ数で大幅に勝る GPT-3 の Zero-shot および Few-shot 性能を 超える Zero-shot 性能を示した
- FLAN
- 指示応答性能の向上
- Alpaca
- Meta社 が 開発した LLaMA 7Bモデル に Instruction Tuning を適用
- パラメータ数で大幅に勝る GPT-3.5 と同程度の指示応答挙動に改善
- Alpaca
- Zero-shot性能の向上
- Instruction Tuningの困難性
- データセット作成
- Instruction Tuning によって望ましい挙動を実現するためには、高品質かつ無害なデータセットの用意が必要
- 一方、指示に含まれる個別のタスクや 形式の多様性の重要性も指摘されている
- 様々な観点を考慮に入れて データセットを構築するためには、 多くの人的・技術的リソースを要する
- 知識導入可能性
- LIMA
- Superficial Alignment Hypothesis を提唱
- Fine-Tuning は、事前学習で獲得された知識・能力を”引き出す”ことで改善を実現しているとする
- Kung and Peng
- Instruction Tuning による性能改善が タスクの理解を通じてではなく、出力形式といった表面的事項の学習に起因する可能性を指摘
- LIMA
- データセット作成
- Instructionデータセット作成上の要点
- データの質
- LIMA
- Instruction Tuning ではデータの量より質が重要だと主張
- 1000件と少量の高品質データを用いた Instruction Tuning のみにより、 RLHF で訓練されたモデルよりも高品質な回答を生成できたことを報告
- LIMA
- データの無害性
- 事前学習済みモデルについて懸念される有害な出力を抑制するため、 Instruction Tuning では有害なデータを避けて学習を実施したい
- 指示形式の多様性
- タスクごとの指示形式の多様化により、未知タスクに対する性能が向上
- データの質
- Instruction データセット構築事例
- Llama2
- Meta 社が開発・公開する大規模言語モデル
- 事前学習済みモデルに加えて、Instruction Tuning および RLHF の適用モデルも提供
- 安全性の向上を目的として、人間による アノテーションや評価を積極的に採用
- アノテーターの選定・指示
- アノテーターが様々なデータ作成 タスクに取り組む上での資質と適性を 評価するため、複数のテストを実施
- 選定されたアノテーターに、以下を満たす指示文・回答の作成を依頼
- Informative
- Relevant
- Harmless
- Truthful
- Clear
- 指示文作成で避けるべき項目
- 犯罪行為の助長
- 危険・攻撃的・性的な言動の助長
- Llama2
- Instruction データセットの構築手法
- ラベル付きデータセットの統合
- 既存のラベル付きデータセットを、
テンプレートを用いて変換
- FLAN
- 人間による
データ作成
- 指示文に対する回答を人間が作成
- InstructGPT
- 人間が作成した 指示文に対し、人間が回答を作成
- LLMによるデータ生成
- 指示文に対する回答をLLMが生成
- Self-Instruct
- LLMによる指示文 と回答の生成フレームワークを提案
- 既存のラベル付きデータセットを、
テンプレートを用いて変換
- ラベル付きデータセットの統合
- Instruction Tuningの派生手法
- In-Context Tuning
- In-Context Learningが促されるよう事前学習済みモデルを Fine-Tuning する ことで、Few-shot性能が向上
- Symbol Tuning
- 正解ラベルを無関係なシンボルに置換したデータで Fine-Tuning し、入出力関係の学習を強制することで、Few-shot性能が向上
- In-Context Tuning
- Full-FT vs. Parameter Efficient Fine-Tuning
- Full-FT
- 概要
- 事前学習済みモデルの全パラメータについて、別タスクで更新を実施
- 計算リソース
- 大規模なモデルでは、莫大な 計算リソースが必要
- 例 GPT-3 : 1.2TBのGPUメモリ
- 保存領域
- 元モデルと同サイズのパラメータを保存するため、大きな領域が必要
- 例 GPT-3 : 350GBの保存領域
- 概要
- Parameter Efficient Fine-Tuning (PEFT)
- 概要
- 追加的に設定したパラメータや、 一部のパラメータのみで更新を実施
- 計算リソース
- 大規模なモデルについても、限定的な計算リソースで性能改善を実現
- 例 GPT-3 LoRA : 350GBのGPUメモリ
- 保存領域
- 更新部分のパラメータのみを保存 すればよく、小さな保存領域で十分
- 例 GPT-3 LoRA: 35MBの保存領域
- 概要
- Full-FT
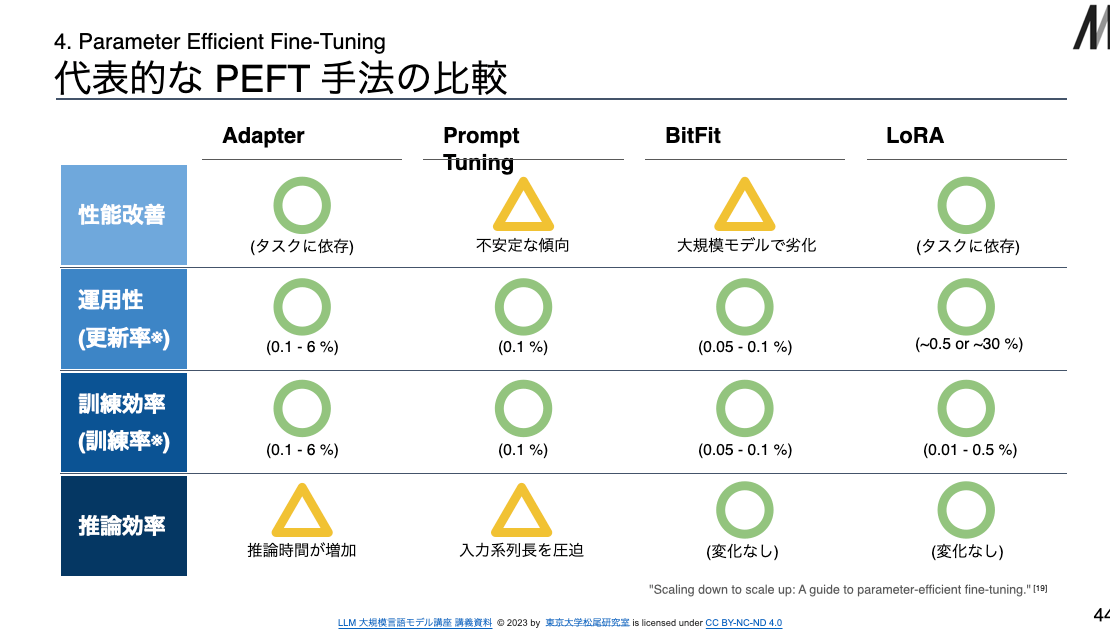
- PEFT 手法を評価する上での主要な観点
- 性能改善
- Full-FT を実施した場合と比べて、性能改善に大きな劣化がないか
- 事前学習済みモデルのサイズに依らず、性能改善が実現されるか
- 運用性
- 更新するパラメータが少なく、小さいストレージで運用が可能か
- それができると複数モデルの並列運用やバージョニングが容易に
- 訓練効率
- 学習するパラメータが少なく、小さいGPUメモリでも実現可能か
- GPUの効率的な活用によって高速化が可能な手法となっているか
- 推論効率
- 追加するパラメータが多いことで、推論コストを増大させないか
- 入力文の系列長が長くなることで、推論コストを増大させないか
- 性能改善
- PEFT手法の代表的なカテゴリー
- Adapter型
- Transformer内部にMLP層 (Adapter)を追加し、それのみの学習を実施
- Adapter
- Transformer内部に学習可能なAdapterモジュールを追加・学習
- Soft Prompt型
- 入力系列にタスクごとのベクトル (Soft Prompt) を付加し、学習を実施
- 代表例: Prompt Tuning
- 各タスクに対応したベクトル (Soft Prompt) を入力系列に 付加し、そのパラメータを学習
- Soft Prompt は、文章の形で設計されたプロンプト (Hard Prompt) に対する呼び方・考え方
- 各タスクごとに特化した プロンプトエンジニアリングを学習していると捉えることが可能
- Selective型
- 事前学習済みモデルが持つパラメータのうち、一部のみで学習を実施
- BitFit
- Transformerの各モジュール に含まれる、バイアス項のみに ついて学習・更新を実施
- Reparametrization型
- 行列分解に基づき、再パラメータ化 された重みについて学習を実施
- LoRA
- QLoRA, AdaLoRA, ReLoRA
- Adapter型


RLHF(Advanced Topic for Tuning Pre-trained Models)
- 概要
- Instruct GPT, ChatGPTなどで利用されている
- LLMで同じ問題に対して複数の答えを出力させ,人間がPreferenceをつける
- Preferenceを予測するように報酬モデルを学習し,強化学習する(PPO)
- RLHFの応用例
- ChatGPT
- LLaMA
- MetaとMicrosoftが共同開発した,研究及び商用利用可能な大規模言語モデル
- open sourceのモデルとしては最高水準の精度
- RLHFを複数回行なって学習しており,有用性や安全性が大幅に向上
- これまでの言語モデルの問題点
- 人間にとって好ましくない発言(設計者が意図しない発言)を行い炎上してしまう事態が発生
- Instruction Tuningでの限界点
- 意図しない発言をInstruction Tuningで対処するのは非常に難しい
- 自然言語でのデータを集めるにはコストがかかる
- 何かを言わない様にするという正解データを作ることが難しい
- 直接的に人間の意図を学習することになっていない
- RLHFによって直接的に意図を学習する
- どの文章が意図通りの出力なのかをモデルにフィードバックする
- 人間の意図通りにモデルを学習することはAlignmentと呼ばれる
- Alignmentを行うためにRLHFという技術が必要となる
- そもそも人間の意図とは
- 意図には明示的な意図と暗黙的な意図が存在する
- 明示的な意図: 言語化して伝えている意図
- Ex. この指示に従ってください,アシスタントとして振る舞ってください
- 暗黙的な意図: 言語化はしてないが,対話において当たり前とされている意図
- Ex. 捏造しない,有害なことは言わない
- 明示的な意図: 言語化して伝えている意図
- 意図には明示的な意図と暗黙的な意図が存在する
- どのような意図の基準があるか(Alignmentの基準)
- Helpful
- ユーザーの質問に対して,できるだけ簡潔で効率的な回答を行う
- 不足情報がある場合,適切な質問を投げかけて情報を引き出す
- 相手のレベルに合わせた質問応答を行う
- Honest
- 情報の虚偽がなく,正確な文章を出力する
- モデル自身がどの程度の不確実性のある情報かを提示することが重要
- (モデル自身がモデルの知っていることを理解している必要がある)
- Harmless
- 攻撃的,差別的な発言をしない
- 悪意のある質問を検知し,拒否をする
- 他にも,(Taxonomy, behavior, incentive, innner aspectsなど)
- この3つを合わせてaligneされたAIと定義している論文もある(HHH)
- Helpful
- “Do-Not-Answer: A Dataset for Evaluating Safeguards in LLMs”
- LLMが潜在的に持っているリスクについて,3つのレベルの分類で,合計60のリスクタイプについて定義
- https://arxiv.org/abs/2308.13387
- Alignmentのアプローチ
- 人間が言語モデルの出力に対してフィードバックを行い,人間の意図に沿うように学習していく
- HITL(Human in the loop)型のアプローチ
- RLHFはAlignmentの一つの主法
- Superalignment
- AGIとAlignmentの関係性
- AGI(汎用人工知能)の実現が大規模言語モデルの登場によって現実的になってきており,Alignmentの研究が推進されている
- AGIがAlignmentされていないと,人類に重大なリスクをもたらす可能性がある(人類の絶滅,地球規模の大惨事)とOpenAIは主張
- https://en.wikipedia.org/wiki/Existential_risk_from_artificial_general_intelligence
- 強化学習の基礎
- エージェント(行動主体)は 環境の状態に基づいて, 逐次的に行動を決定する
- 行動の結果得られる報酬を利用し, その環境で最も良い行動ルール(最適方策)を学習したい
- Learning Agent = Language Model
- 報酬予測モデルは言語モデルの出力層を変えてスカラー値を出力させるものが一般的
- 強化学習の最適化アルゴリズム: PPO
- RLHFでもよく使われている強化学習のアルゴリズム
- PPOはActor-Cliticと呼ばれるアルゴリズムの派生系
- エージェント内にActorとCriticという役割が存在し,それらが協調することでポリシーを更新し,報酬を最大化していく
- Learning from human preferences
- OpenAIが2017年に発表した,少数の人間のフィードバックから強化学習する仕組み
- Fine-Tuning Language Models from Human Preferences
- 人間のフィードバックを利用して事前学習したGPT-2のfine-tuningをPPOで行う
- Learning to Summarize from Human Feedback
- GPT-3を用いて要約タスクに人間のフィードバックによる強化学習を適用
- Step1: 複数のソースから要約をサンプリングし,人間がそのペアを評価
- Step2: 要約ペアの選考順序のデータをもとに報酬モデルを学習
- Step3: 報酬モデルの出力を報酬として強化学習を行う
- Supervisedを大幅に上回り,人間が作成した参照要約より優れているという結果
- GPT-3を用いて要約タスクに人間のフィードバックによる強化学習を適用
- Training Language Models to Follow Instructions with Human Feedback
- ChatGPTの前進であるInstructGPTで用いられている手法
- 要約タスクではなく,既存のGPT-3をアライメントすることが目的
- 一般にRLHFと言うとこの手法を指すことが多い
- InstructGPTの詳解
- Step1
- プロンプトのデータセットを用意し,そのプロンプトに対する人間のlabelerの回答を元に教師あり学習を行う
- Step2
- あるプロンプトに対する出力を複数集め,その出力に関する「好ましさ」を,人間のlabelerがランクづけする。その後,ランク付きデータをもとに,報酬モデルを学習
- Step3
- あるプロンプトに対するGPTモデルの出力に対して,報酬モデルが報酬を生成し,PPOによる強化学習を行う
- Step3の完了後,強化学習した新しいGPTモデルを使用してStep2~3を行うという手順を繰り返す
- 問題点
- Reward Hacking
- 報酬を最大化することを目的にしたモデルが,望ましくない方策を学習してしまうこと
- Alignment Tax
- 人間の意図通りに調整しようとすると,汎化性能が劣化してしまう
- アライメント税
- Reward Hacking
- 対策
- KL Penalty
- 報酬がたくさんもらえるような決まった文章ばかりを生成しないようにする。
- 生成する文章が SFT モデルから大きく変わりすぎないようにする。
- Replay
- 事前学習時のデータを用いて汎化性能の劣化を抑える
- KL Penalty
- Step1
- InstructGPTの評価
- InstructGPTはGPT-3と比較して,より正しい指示に従い,ハルシネーション(幻覚)が抑えられている
- ユーザーと同じ言語を用いる割合も高くなっている
- RealToxicity, TruthfulQAでの評価では,InstructGPTが一番良いスコアを出している(無害性,真実性)
- 学習データのフォーマットについて
- 主に,Feedbackのタイプは数値,ランキング,自然言語,その他(MQM, Post-Edition等)に分けられる
- 基本的には英語のデータセットがほとんど
- Anthoropic, stanfordnlpなどがリリース
- データの集め方: InstructGPT
- Labelerの選択
- 少数のデータにラベル付けを行い,スクリーニングテストの結果,ラベルとの一致度合いが高いLabelerを選択
- Labelerの属性に関する統計データをアンケートを用いて収集
- Labelerの属性が偏らないようにする
- Labelerへのinstructionを作成
- Web GUIを用いてラベリング
- Labelerの選択
- RLHFを実装するためのライブラリ
- trl
- HuggingFaceでPPO を使用して事前学習済みの言語モデルをRLHFするためのライブラリ
- trlx
- CarperAIによって構築されたtrlの拡張フォークで,オンラインおよびオフラインの学習用の大規模なモデルを処理.現時点では,PPOとILQLを使用可能
- RL4ML
- さまざまな強化学習アルゴリズム (PPO、NLPO、A2C、および TRPO),報酬関数,メトリックを使用して,LLMのRLHFおよび評価が可能
- DeepSpeed Chat
- Chat形式のモデルを学習できるツールキット
- GPU1台で100億超パラメータを、複数GPUなら1000億パラメータ超のモデルを学習可能
- SoTAの15倍以上の高速な学習をスクリプト一つで実行でき,簡単かつ低コスト
- trl
- RLHFの評価について
- 基本的な評価基準
- Honestness
- TruthfulQA: 真実性を評価するベンチマーク
- 健康、法律、金融、政治など 38 のカテゴリーにわたる 817 の質問と回答で構成
- Fine-TuningされたGPT-3を用いて評価を自動化
- HaluEval: ハルシネーションを認識できるかを評価するベンチマーク
- ChatGPTが幻覚を起こしやすいデータで構成
- Yes or Noを判定する
- TruthfulQA: 真実性を評価するベンチマーク
- Helpfulness
- HH-RLHF
- HelpfulnessとHarmlessnessに関するデータセット
- Anthoropicが開発し,学習にも評価にもよく使用される
- クラウドワーカによって収集
- HelpfulnessとHarmlessnessに関するデータセット
- HH-RLHF
- Harmlessness
- Crows-Pairs
- 人種/肌の色、性別/性自認、性的指向、宗教、年齢、国籍、障害、外見、社会経済的地位の 9 種類の偏見に関する評価データセット
- WinoGender
- ジェンダーバイアスに関する評価データセット
- Crows-Pairs
- FLASK
- Open-setなベンチマークでの包括的な評価
- Logical Thinking, Background Knowledge, Problem Handling, User Aligmentの4つの観点で合計12のスキルを評価
- GPT-4を用いてそれぞれの観点で5段階の評価を行う
- Honestness
- Do-Not-Answer
- LLMのリスク評価のための包括的なデータセット
- 各タイプごとに50個以上のプロンプトを作成し,合計939 個のプロンプトからなるリスク検出データ
- 人間 or GPT-4によって,各カテゴリに該当するかを0,1で判定
- 基本的な評価基準
- AlignmentのためのHuman Feedbackを用いた学習手法の大別
- Online Human Alignment
- 報酬モデルの上位100/k%をfine-tuningするデータとしてフィルタリング
- RLHF, RAFT, RLCD
- Offline Human Alignment
- Rank-based Training
- Reward Modelを介さず直接Preferenceを考慮した最適化を行う
- DPO, PRO, RRHF, SLiC
- Language-based Training
- 模擬的な人間社会をシミュレートするサンドボックスを作成
- サンドボックス中のagent同士が対話することによって,質問に対する回答を様々な観点で生成
- CoH, Second Thoughts, Stable Alignment, SelFee
- Rank-based Training
- Online Human Alignment
- RLHFにおける課題について
- Human Feedback, Reward Model, Policyのそれぞれ部分で課題がいくつか存在する
- Misaligned Evaluators
- 質が高いフィードバックを提供するLabelerを選択するのが難しい
- 評価者の中には有害な偏見や意見を持っている
- ある人間が意図してデータを汚染する可能性
- “Whose Opinions Do Language Models Reflect?”
- RLHFによって訓練されたモデルは誰の意見を反映しているか?
- RLHF前は低所得,低学歴と一致する意見であったが,RLHF後は逆になった
- Difficulty of Oversight
- 人間は単純な間違いを犯す
- 人間は難しいタスクのパフォーマンスを適切に評価できない
- “Artificial Artificial Artificial Intelligence: Crowd Workers Widely Use Large Language Models for Text Production Tasks”
- クラウドワーカーがLLMを使用することに経済的合理性がある
- 自分で考えるよりLLMに考えて貰えばAPI代はらってもプラス
- クラウド ワーカーの 33 ~ 46% が LLM を使用したと推定された
- クラウドワーカーがLLMを使用することに経済的合理性がある
- Data Quality
- データ収集のバイアスが生じる
- コストと品質のトレードオフが存在する
- LIMA: Less Is More for Alignment
- モデルの知識と能力はほとんどが事前学習時に学習されるという仮定
- アライメントは対話形式のフォーマットと,言語モデルのどのドメイン分布から出力させるかを指定する
- Feedback Type Limitations
- フィードバックの種類と効率さのトレードオフ
- Ex. 2つのペアのrankingは簡単だが効率が悪い
- フィードバックの種類と効率さのトレードオフ
- 2つのペアのrankingは簡単だが効率が悪い
- 一方で,言語フィードバックだと質の担保が大変
- Misaligned Evaluators
- Reward Modelにおける課題
- Problem Misspecification
- 個々の人間の価値観を報酬関数で表すのは難しい
- 単一の報酬関数で人間の多様な社会を表すことはできない
- 複数の意見がある問題に対して単一のスコアをつけることは難しい
- Misgeneralization/Hacking
- 正しいラベルのトレーニングデータからでも正しく報酬モデルが学習できるとは限らない
- 報酬ハッキングが起きる可能性がある
- Reward Modelが過学習を起こすとMisgeneralization/Hackingが起きやすい
- Evaluation Difficulty
- 報酬モデルを評価することは難しい
- Problem Misspecification
- Human Feedback, Reward Model, Policyのそれぞれ部分で課題がいくつか存在する
- Policyにおける課題
- RL Difficulties
- ポリシーを効果的に最適化することは困難
- ポリシーは敵対的に悪用される可能性がある
- Jailbroken: How Does LLM Safety Training Fail?
- Policy Misgeneralization
- 最適なRLエージェントは,権力を求める傾向がある
- Distributional Challenges
- RLによってモード崩壊を起こす可能性がある
- 事前モデルのバイアスが強化される可能性がある
- RL Difficulties
- なぜRLHFで性能が上がるのか?
- 性能が上がっている訳ではなさそう
- 事前学習で得た分布を意図に沿う出力に変化させているだけ?
- 学習を間違えると,条件付け意図しない分布から出力されてしまう
- AlignmentとはAIを道徳的概念,社会的規範,人間の目的を理解し適切な行動をとるように設定すること
- RLHFはAlignmentを適用する1つの方法であり,人間からのフィードバックデータを用いて言語モデルを強化学習する
- RLHFによるAlignmentには代表的なものとして,HHH(Helpful, Honest, Harmless)などが存在する
- RLHFには,Human Feedback, Reward Model, Policyに関する様々な問題があり,RLを必要としない学習方法も次々と提案されている
Going Beyond LLM
- 言語モデルとは、あるトークン系列に確率を与えるモデル
- トークナイザー
- コーパスをトークナイザーに従ってトークン分割・インデックス化
- 日本語を自在に扱えるトークナイザーは事実上 BPE か SentencePiece のみ
- 現在の大規模言語モデル (LLM) が優れた性質を持つのは、
コンテクストに合わせて文の尤度を調節できるからである
- LLMのプロンプトエンジニアリングと呼ばれる技法も、この文の尤度調節で説明できる
- 大規模言語モデルの学習ツール
- Megatron-Deepspeed (Microsoft)
- GPT-NeoX (EleutherAI)
- LLM foundry (Mosaicml)
- BLOOM (BigScience)