Kaggle Expertになったコンペ振り返り
はじめに
Linking Writing Processes to Writing Quality において38th/1876(top3%)で銀メダルを取ることができ、Kaggle Competition Expertになりました。コンペからかなり時間が経ってしまいましたが、振り返ってみようと思います。

コンペ概要

- キーボードのタイピング動作の情報からエッセイの質(0.5~6の12段階)を予測するテーブルデータコンペ
- 以下のようなデータセットを使用

- エッセイの内容についてはすべて’q’に置換されており、見ることができません。
- 評価指標:RMSE
結果
public 21th → private 38th

- データセット数が少なかった(約2000ほど)ことから、揺れることが予測されており、実際かなり揺れたコンペでした。
- 自分たちのチームも多少揺れたが、銀メダル圏内はキープすることができました。実装した後処理(後で説明)はコンペの揺れによる影響をあまり受けないだろうと考えていたので、実際にあまり揺れなかったことは良かったです。
解法

以下のモデル(public notebook)のアンサンブルを行いました。
| モデル | 割合 |
|---|---|
| LGBM | 0.1 |
| LGBM×2+NN blending | 0.2 |
| LGBM×2+NN+LGBM(異なる特徴量) | 0.3 |
| VotingRegressor (7 models) | 0.4 |
LGBM分類モデルによる 後処理
スコアリング指標はRMSEであるため、ごく一部の外れ値がスコアに大きく影響する可能性があります。公開LGBMモデルを使用して、エッジターゲット(0.5または6.0pt)がスコアの悪化にどの程度寄与するかを評価しました。以下に示すように、これらのターゲットは訓練データの1.7%しか占めていないにもかかわらず、エラーに大きな影響を及ぼしていました。
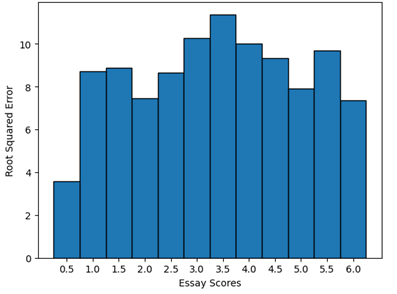
また、LGBMモデルの予測結果を調べてみると、最小予測値が1.3、最大予測値が5.4と、これらのエッジ値の予測がうまくできていないことが分かりました。
これに対処するため、6.0ptのエッセイを検出するLGBM分類モデルを別途トレーニングし、6.0ptである確率が高い場合に新たなスコアを代入することで後処理を行いました。aucは約0.90であり、モデル性能を高めるのに十分な高さでした。予測値を5.5に置き換えることでスコアの向上に成功しました。
上手くいかなかったこと
- catboost,xgboost,tabnetの使用
- スタッキングモデルの作成
- 回帰ではなく分類として解く
- 特徴量削減、特徴量追加(全データを時系列で分割し集計、PCAで次元圧縮した特徴量など)
- optunaハイパーパラメータ最適化
- 端数処理による後処理(例:4.94→5.0)
- 0.5pt,1.0ptなどのエッジ値の予測の後処理 など
まとめ
- 上位解法を見ると、特徴量から文章を復元し、その文章を用いてNLPコンペとして解いている解法が多かったです。
- 特徴量は公開notebookでかなり出し尽くされており、自分たちは新たな有用な特徴量を見つけることができなかったが、上位解法はさらにいくつか有用な特徴量を見つけることができていました(句読点の間違いの統計など)。
- 自分たちでは特徴量重要度による特徴量選択でスコアを上げることができなかったが、これによってスコアを上げているチームもありました(7thなど)。
- 特徴量から文章を復元するコードは公開されており、自分たちもそれを使用していたが、上位解法ではそのコードをさらに改良して復元精度を向上させて使用していました(1stなど)。公開コードでは文章の復元が完璧ではなかったようで、私は公開コードを疑いもせず使っていたので、もっと疑ってかかるべきだと反省しました。
おわりに
前回のkaggle初参加のコンペに続きメダルを取ることができ、順調にKaggle Competition Expertになることができました。学生中でのKaggle Competition Master昇格に向けて引き続き頑張りたいと思います!
Discussion