「SAT大蔵経DB 2018」で公開されているテキストの分析例
概要
「SAT大蔵経DB 2018」は以下のように説明されています。
このサイトは、SAT大蔵経テキストデータベース研究会が提供するデジタル研究環境の2018年版です。
SAT大蔵経テキストデータベース研究会は、2008年4月より、大正新脩大藏経テキスト部分85巻の全文検索サービスを提供するとともに、各地のWebサービスとの連携機能を提供することにより、利便性を高めるとともに、Webにおける人文学研究環境の可能性を追求してきました。
2018年版となるSAT2018では、近年広まりつつある機械学習の技術と、IIIFによる高精細画像との連携、高校生でもわかる現代日本語訳の公開及び本文との連携、といった新たなサービスに取り組んでみました。また、本文の漢字をUnicode10.0に対応させるとともに、すでに公開していたSAT大正蔵図像DBの機能の大部分も統合いたしました。ただし、今回は、コラボレーションを含む仕組みの提供という側面もあり、今後は、この輪組に沿ってデータを増やし、より利便性を高めていくことになります。
当研究会が提供するWebサービスは、さまざまな関係者が提供するサービスや支援に依拠しています。SAT2018で新たに盛り込んだサービスでは、機械学習及びIIIF対応に関しては一般財団法人人文情報学研究所、現代日本語訳の作成に関しては公益財団法人全日本仏教会の支援と全国の仏教研究者の方々のご協力をいただいております。
SAT2018が、仏教研究者のみなさまだけでなく、仏典に関心を持つ様々な方々のお役に立つことを願っております。さらに、ここで提示されている文化資料への技術の適用の仕方が、人文学研究における一つのモデルになることがあれば、なお幸いです。
今回は、上記のDBが公開するテキストデータを対象として、簡単な分析を試みます。
説明
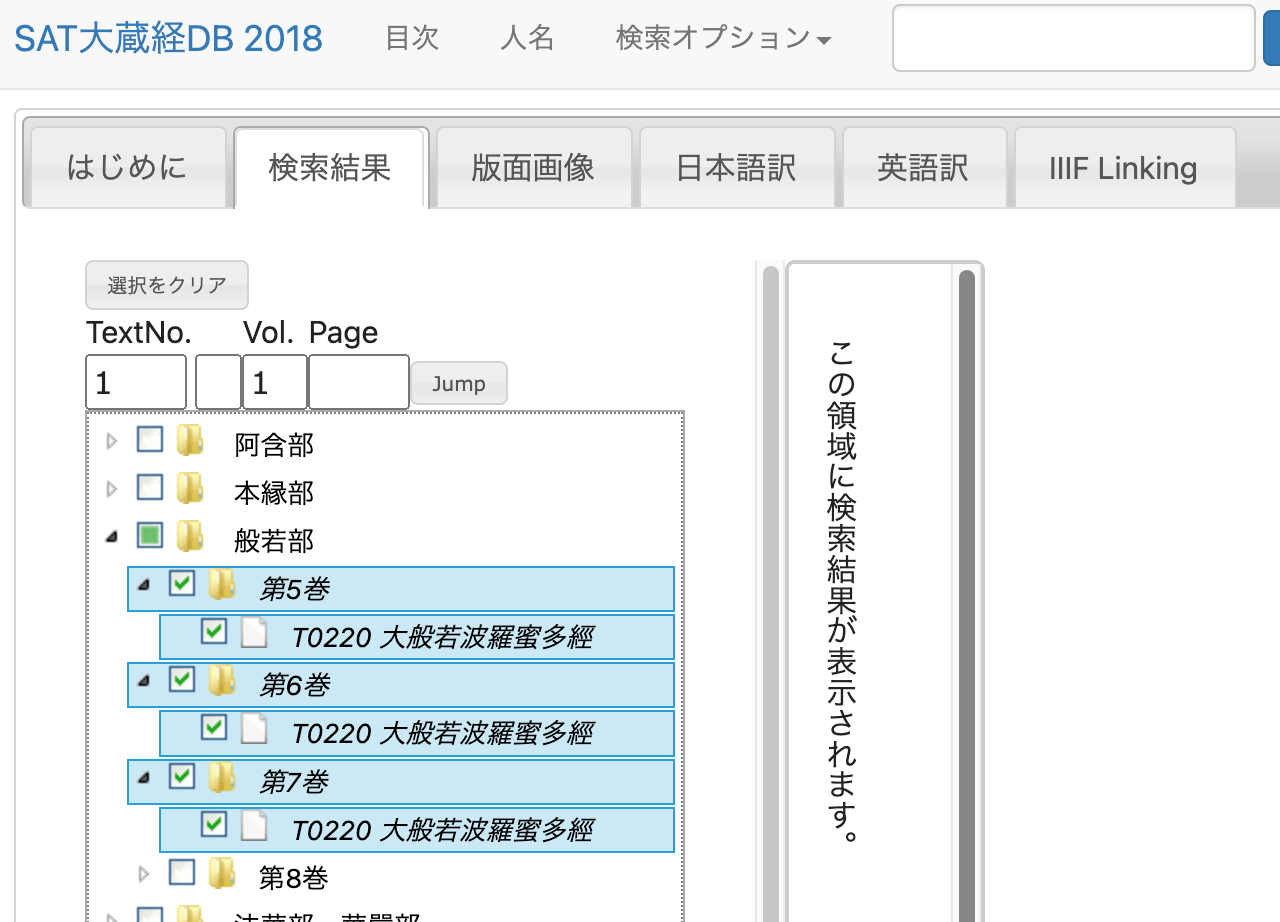
以下の「T0220 大般若波羅蜜多經」のテキストを対象にします。
方法
テキストデータの取得
ネットワークを確認したところ、以下のようなURLでテキストデータを取得することができました。
https://21dzk.l.u-tokyo.ac.jp/SAT2018/satdb2018pre.php?mode=detail&ob=1&mode2=2&useid=0220_,05,0001
0220_,05,0001の部分について、05を06に変えると6巻のデータが取得できました。また、末尾の0001を0011に変更すると、0011の前後を含むテキストが取得できました。
この傾向を踏まえて、以下のようなプログラムを実行しました。
import os
import requests
import time
from bs4 import BeautifulSoup
def fetch_soup(url):
"""Fetches and parses HTML content from the given URL."""
time.sleep(1) # Sleep for 1 second before making a request
response = requests.get(url)
return BeautifulSoup(response.text, "html.parser")
def write_html(soup, filepath):
"""Writes the prettified HTML content to a file."""
with open(filepath, "w") as file:
file.write(soup.prettify())
def read_html(filepath):
"""Reads HTML content from a file and returns its parsed content."""
with open(filepath, "r") as file:
return BeautifulSoup(file.read(), "html.parser")
def process_volume(vol):
"""Processes each volume by iterating over pages until no new page is found."""
page_str = "0001"
while True:
url = f"https://21dzk.l.u-tokyo.ac.jp/SAT2018/satdb2018pre.php?mode=detail&ob=1&mode2=2&useid=0220_{vol}_{page_str}"
id = url.split("useid=")[1]
opath = f"html/{id}.html"
if os.path.exists(opath):
soup = read_html(opath)
else:
soup = fetch_soup(url)
write_html(soup, opath)
new_page_str = get_last_page_id(soup)
if new_page_str == page_str:
break
page_str = new_page_str
def get_last_page_id(soup):
"""Extracts the last page ID from the soup object."""
spans = soup.find_all("span", class_="ln")
if spans:
last_id = spans[-1].text
return last_id.split(".")[-1][0:4]
return None
def main():
vols = ["05", "06", "07"]
for vol in vols:
process_volume(vol)
if __name__ == "__main__":
main()
上記の処理により、HTMLファイルをダウンロードすることができます。
HTMLファイルの解析
以下のプログラムを実行し、IDごとのテキストを取得します。
import glob
import json
from bs4 import BeautifulSoup
from tqdm import tqdm
def read_html_file(filepath):
"""Reads HTML content from a file."""
with open(filepath, "r") as file:
return BeautifulSoup(file.read(), "html.parser")
def extract_mappings(soup):
"""Extracts mappings from BeautifulSoup object."""
mappings = {}
text_blocks = str(soup).split("<span class=\"ln\">")[1:] # Skip the first split as it does not contain relevant data
for block in text_blocks:
ln = block.split("</span>")[0].strip()[:-1]
text = block.split("</span>")[1].split("<span class=\"tx\">")[1].split("</span>")[0].strip()
mappings[ln] = text
return mappings
def save_to_json(data, filename):
"""Saves the dictionary to a JSON file."""
with open(filename, "w") as file:
json.dump(data, file, indent=4, sort_keys=True, ensure_ascii=False)
def main():
files = sorted(glob.glob("html/*.html"))
overall_mappings = {}
for file in tqdm(files):
soup = read_html_file(file)
mappings = extract_mappings(soup)
overall_mappings.update(mappings) # Update the overall dictionary with new mappings
save_to_json(overall_mappings, "mappings.json")
if __name__ == "__main__":
main()
結果、以下のようなJSONデータが得られます。
{
"T0220_.05.0001a01": "",
"T0220_.05.0001a02": "No.220.",
"T0220_.05.0001a03": "",
"T0220_.05.0001a04": "大般若經初會序",
"T0220_.05.0001a05": "<button class=\"ftntf\" style=\"font-size:8px;padding:2px\" title=\"(唐)+西<明>\">\n 1\n </button>\n 西明寺沙門玄則製",
"T0220_.05.0001a06": "大般若經者。乃希代之絶唱。曠劫之遐津。光",
"T0220_.05.0001a07": "被人天。括嚢眞俗。誠入神之奧府。有國之靈",
...
分析例
文字の出現頻度を分析してみます。
import json
from collections import Counter
def load_data(filepath):
"""Loads JSON data from a file."""
with open(filepath, "r") as file:
return json.load(file)
def count_characters(data):
"""Counts the frequency of each character in the provided data."""
freq = Counter()
for text in data.values():
freq.update(text)
return freq
def get_top_characters(freq, top_n=30):
"""Returns the top N characters by frequency."""
return freq.most_common(top_n)
def print_top_characters(top_chars):
"""Prints the top characters and their frequencies."""
for char, count in top_chars:
print(f"{char},{count}")
def main():
path = "mappings.json"
data = load_data(path)
freq = count_characters(data)
top_chars = get_top_characters(freq)
print_top_characters(top_chars)
if __name__ == "__main__":
main()
結果、以下のような結果が得られました。前のステップでHTMLタグなどを完全に除去できていないため、正確な結果ではありませんが、どのような文字がよく使われているのかを概観することができます。
。,468928
無,181480
若,120870
不,114409
淨,103570
故,88018
薩,86213
清,85740
智,71457
空,69488
一,67606
菩,63463
是,61219
切,59426
,56781
羅,55111
法,54864
所,53651
界,53392
有,52919
性,52075
如,51931
爲,50332
多,49391
善,48412
波,46373
蜜,46066
摩,43507
諸,43002
得,39413
まとめ
「SAT大蔵経DB 2018」で公開されているテキストに対して、ごく簡単な分析例を紹介しました。
本DBの公開に関わるすべての方々に感謝いたします。
Discussion