PythonでAzureのblobストレージでParquetファイルを読み書きする方法
Python で Azure の blob ストレージで Parquet ファイルを読み書きする方法を紹介します。
ストレージアカウントを作成する
blob ストレージは、Azure ストレージアカウントサービスに含まれるサービスです。blob ストレージを使うには Azure にストレージアカウントを作成する必要があります。ストレージアカウントを作成しましょう。
1.リソースの作成
Microsoft Azureへアクセスし、Azure サービスの「リソースの作成」をクリックします。

2.ストレージアカウント選ぶ
Marketplace へ移動するので、検索窓に「ストレージ」と入力して「ストレージ アカウント」を探して選択します。
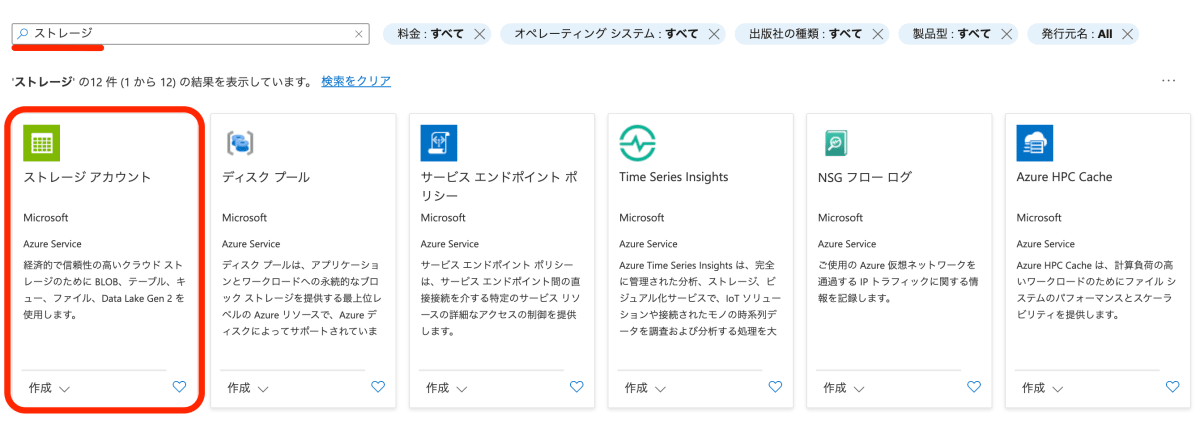
3.ストレージアカウントの作成を開始
ストレージアカウントが表示されるので、間違いがないか確認して「作成」をクリックします。

4.ストレージアカウントの初期設定
基本設定以外は変更不要です。
基本設定
基本設定では、以下を設定します。
- リソースグループ:なければ作成しましょう。
- ストレージカウント名:アカウント名を決めます。
- 地域(リージョン):日本にしておきましょう。

確認および作成
基本設定以外は変更不要なので、そのまま進んで、最後「作成」をクリックすれば、ストレージアカウントが作成されます。

5.デプロイ
作成すると、デプロイ画面が表示されます。「デプロイが完了しました」と表示されたら完了です。
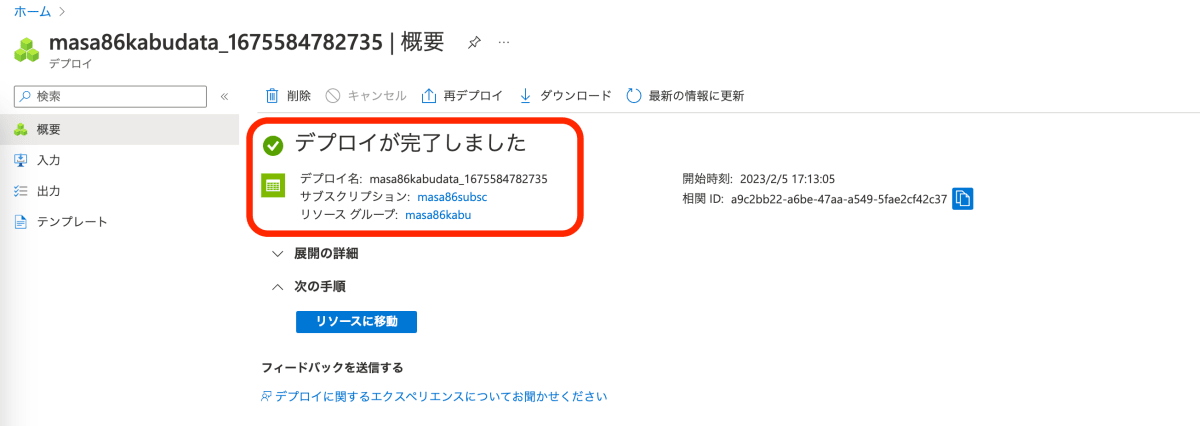
6.リソース確認
「すべてのリソース」の一覧でストレージアカウントができていることが確認できます。

読み書き用のコンテキストを作成する
blob ストレージでは、コンテナという単位でファイルを管理します。コンテナ単位でアクセス権を付与することができます。ファイルを読み書きするコンテナを作成しましょう。
例として、マスタデータを保管するコンテナ「master」を作成します。
1.コンテナーの追加
ストレージアカウントにアクセスし、「+コンテナー」をクリックしてコンテナ作成を開始します。
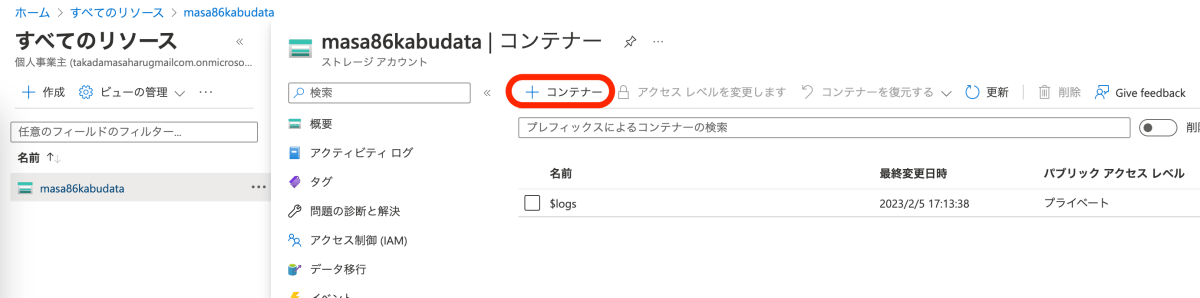
2.コンテナーの作成
名前に「master」を入力し、「作成」をクリックすればコンテナーが作成されます。

3.コンテナーの確認
ストレージアカウントにアクセスすれば、「master」コンテナが作成されていることが確認できます。

これで、Azure でファイルを読み書きできる blob ストレージを作ることができました。blob ストレージに書き込む python コードを書いていきましょう。
azure-storage-blobモジュールをインストールする
Azure の blob ストレージを扱う Python モジュールはazure-storage-blobです。以下のコマンドでインストールしましょう。
python -m pip install azure-storage-blob
テキストファイルを書き込んで見る
書き込みサンプル
blob ストレージにテキストファイルを書き込むサンプルは以下です。
環境変数から読み込んでいる接続文字列は後述します。
import os
from azure.storage.blob import BlobClient, BlobServiceClient, ContainerClient
# 接続文字列
connection_str = os.environ["AzureWebJobsKabuDataStorage"]
# 接続文字列からサービスクライアントを取得
blob_service_client: BlobServiceClient = BlobServiceClient.from_connection_string(connection_str)
# サービスクライアントからコンテナクライアントを取得
blog_container_client: ContainerClient = blob_service_client.get_container_client("master")
# コンテナクライアントからBlobクライアントを取得
blob_client: BlobClient = blog_container_client.get_blob_client("sample.txt")
# 書き込み
blob_client.upload_blob("This is Test.".encode("utf-8"), overwrite=True)
接続文字列はストレージアカウントの「アクセスキー」にアクセスして、「接続文字列」を参照すれば値をコピーできます。

読み込みサンプル
blob ストレージにテキストファイルを読み込むサンプルは以下です。
blob クライアントを作成するまでのステップは書き込みサンプルと同じです。
import os
from azure.storage.blob import BlobClient, BlobServiceClient, ContainerClient
# 接続文字列
connection_str = os.environ["AzureWebJobsKabuDataStorage"]
# 接続文字列からサービスクライアントを取得
blob_service_client: BlobServiceClient = BlobServiceClient.from_connection_string(connection_str)
# サービスクライアントからコンテナクライアントを取得
blog_container_client: ContainerClient = blob_service_client.get_container_client("master")
# コンテナクライアントからBlobクライアントを取得
blob_client: BlobClient = blog_container_client.get_blob_client("sample.txt")
# 読み込み
sample_text = blob_client.download_blob().content_as_bytes().decode("utf-8")
print(sample_text)
テキストファイルの読み書きができたので、次は Parquet ファイルの読み書きをしてみましょう。
Parquet ファイルを読み書き
pandas のデータフレームをバイトストリームに書き込んで、そこからバイト配列を取得すればよいです。読み込みはその逆です。
# 書き込みサンプル
blob_client: BlobClient = blog_container_client.get_blob_client("sample.parquet")
parquet_data = io.BytesIO()
df.to_parquet(parquet_data)
blob_client.upload_blob(parquet_data.getvalue(), overwrite=True)
# 読み込みサンプル
blob_client: BlobClient = blog_container_client.get_blob_client("sample.parquet")
parquet_data = io.BytesIO(blob_client.download_blob().content_as_bytes())
df = pd.read_parquet(parquet_data)
print(df)
Discussion