機械学習におけるバリデーションとは

本記事は「Kaggleで磨く機械学習の実践力」という書籍を参考に書いています。主にP72〜P74を参考にしています。
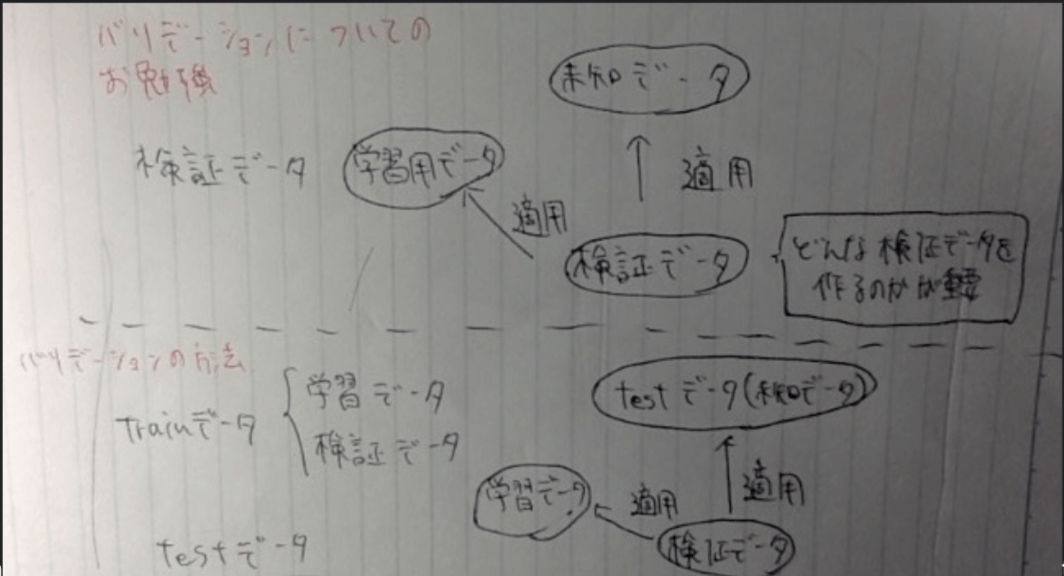
バリデーションについてのお勉強
・バリデーションの目的:機械学習モデルの性能を手元のデータで判断する(KaggleでSubmitはしない)
・そのため、手元のデータを用いて擬似的に機械学習モデルの性能を測るためのデータ「検証データ」を作成し、「未知のデータ」に「検証データ」を適用したときの精度を確認する
・バリデーション設計がうまくいかないと、学習用データにしか通用しないモデルになってしまう(いわゆる過学習)。そして検証用データにはうまく通用しないモデルになってしまう。
・バリデーション設計で重要なのはどのように検証データを作成するか。「実際の適用シーン(つまり未来)と同じ状況を仮想的に再現する」ことが理想
・ただ未来のことはわからないので検証データは「こうなるだろう」という仮説をもろに用意する
バリデーションの方法2つ
・学習データと検証データの分割方法
・分割時に重要なのは「こうなるだろう」という推論時と同じケースを学習データから擬似的に生成する
・例えばtrainデータを「学習データ」と「検証データ」に分割して、testデータ(推論時に用いるデータ)を「検証データ」で再現できればOK
例
・目的変数(予測の対象となっている変数)が0か1で、10万件のうち、五千件だけが1だったとする。つまり「1」である割合がたったの5%。このtrainデータを学習データと検証データに分ける際、次の2パターンにする。
- パターン1:検証データのうち「1」の割合が5%
- パターン2:検証データのうち「1」の割合が15%
・testデータ(trainデータをコンピュータに何が正しくて何が間違っているのかを学ばせる。その知識をもとにtestデータで何が正しくて、何が間違っているかの予測する)における「1」の割合はわからない。でもtrainデータと同じ傾向にあるとは予想できる。なのでtrainデータと検証データでは「1」の割合を揃えた方が良い。(←なんで??)
・ここを揃えないとモデルが正しくチューニング(調整)されず、検証データで評価値(どゆいみ?)とtestデータで予想される評価値に乖離が出る
Discussion