擬似ラベルのデータリークについて
タイムラインで擬似ラベルのリークについての話題がでたので整理してみる。
外部データに擬似ラベルをつける場合

内部データに擬似ラベルをつける場合
知識蒸留やリラベリングのケース。
参考
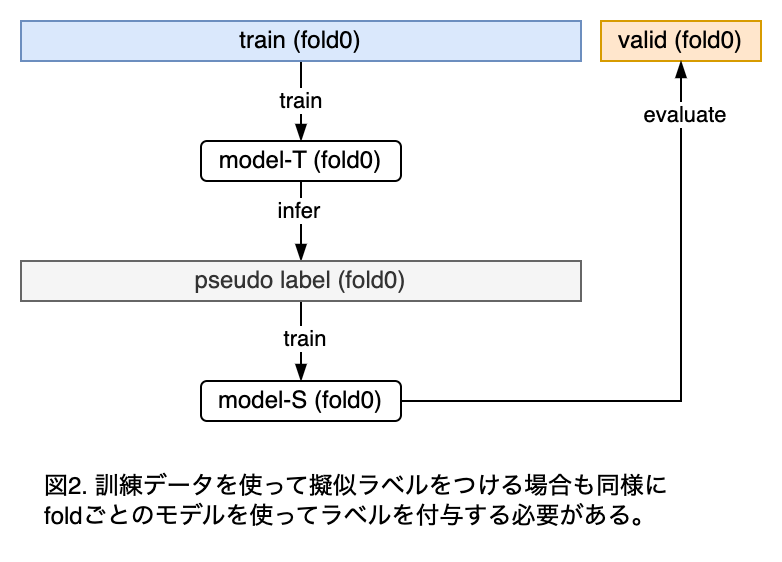
内部データに擬似ラベルを付加する場合のリークの影響について
個人的には、内部データに擬似ラベルをつけるケースでは問題はそんなに深刻化しないのではと思っている。外部データの場合に、擬似ラベル作成用のモデルの学習に評価データを使うことの問題点は、評価データと相関が高い外部データの正解がリークすることだった。内部データの場合は、このようなサンプルでは元々評価データの正解率が高いと考えられるため、リークによる影響は外部データの場合と比べて小さいはずだからである。ただし、リークの影響はゼロではないため、リークさせないに越したことはない。
評価データのリラベリングについて
リラベリングの場合は、評価データもリラベリングしたいケースがある(ラベルノイズの影響が無視できない場合など)。
この場合はどのモデルを使って評価データのラベルを作ったら良いだろうか?
前提として、LBのデータはラベルノイズが小さい、高品質なラベルを使っているとする。
このさい、目的は、LBの相関が良いCVデータラベルを作成すること。
ナイーブなラベリングスキーム
ラベルノイズが大きいデータセットが与えられているとする。目的は、ノイズの小さい(=似た特徴に対して一貫した)ラベルをつけることが目的である。
ナイーブな方針としては、「モデルの学習に利用したデータをそのままリラベルする」というのが考えられる(図3)。逆にいうと、「学習に利用していない未知のデータはリラベルしない」というポリシーである。
Q. そうする必要性はあるか?
A. 特にないが、未知データのラベリングは必ずしも一貫したものになるとは限らないため、既知データのみリラベルする方がラベルノイズ軽減の効果が高いと思う。
Q. この場合においてfoldを分けることのメリットは?
A. 期待する効果は、「データに意図的に揺らぎを加えることによる正則化」である。
ラベルノイズを軽減する目的でリラベリングする場合は、全データを使った学習(図3-a)で十分かもしれない。ただし、trainに過剰適合したラベルになりやすいので、cross foldのモデルのアンサンブルよって正則化すると、より汎用的な(=保守的な?)ラベル付が行われると思う。
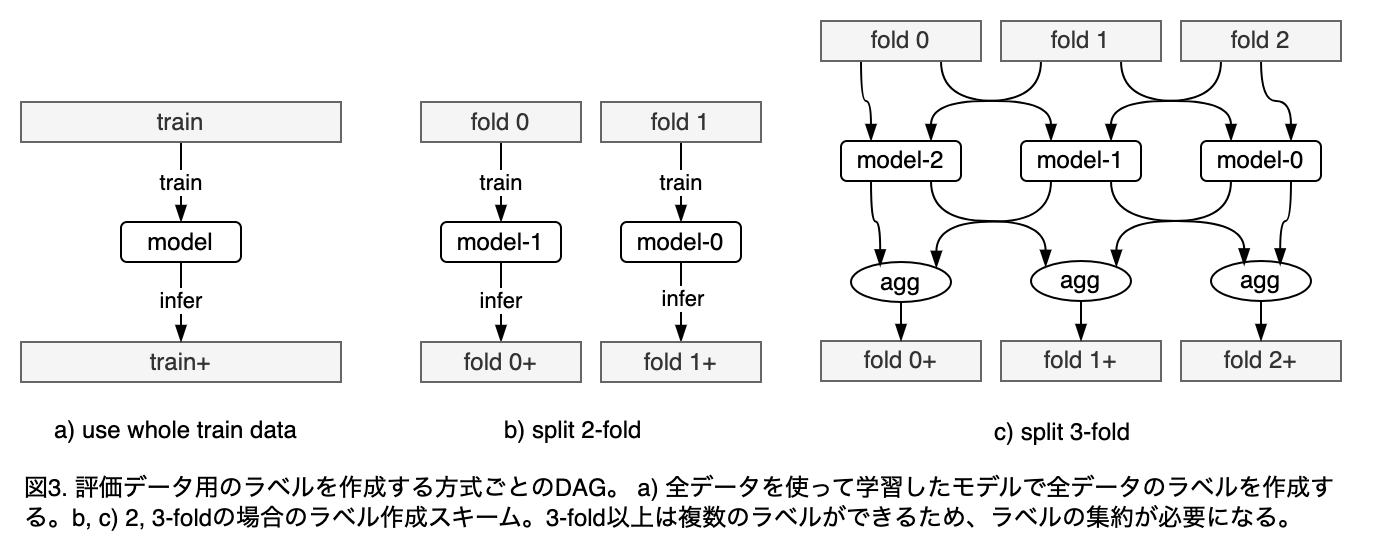
「trainデータ内部で情報のリークなしに評価データをリラベリングする」というポリシーだとどうなるか?
図のb)のような方法が考えられるが、これだと学習に利用できるデータが訓練データの1/N(N: fold数)となるので、ラベルの品質は低下するだろう。逆に図3-c)のように「学習に使ったデータをリラベルする」方針だと学習に利用できるデータはN-1/Nだが、情報漏洩が発生する。
したがって、訓練データ全体をリラベルする場合は、情報漏洩とラベル品質の間でトレードオフとなる。
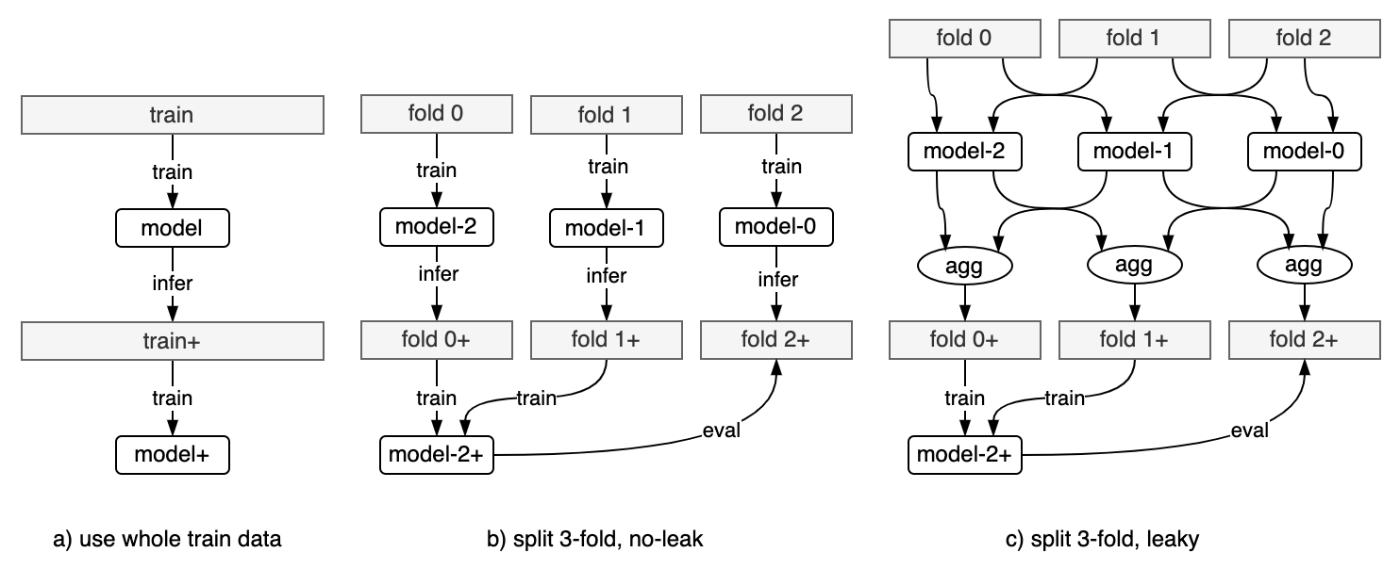
ちゃんと考えると結構複雑だが、大まかに以下の2種類のリークができる。
- 評価用ラベルの情報が訓練データに漏洩する
- 訓練用のラベルの情報が訓練データに漏洩する
1のケースのリーク経路を赤線で示し、2のケースのリークを青線で示した。

多分この種のリークが深刻な問題になることはほぼない。
したがって実用上はa)かc)のスキームで十分ではないかと思う。
TODO: リラベルとリークの関連について先行研究があれば知りたい。