AWS Lambdaの忘れそうなところまとめ
はじめに
こんにちは、山田です。
今回は、AWS Lambdaの個人的に忘れそうなところを記載していきます。
よろしくお願いします。
Lambda関数の実行環境
LAmbda関数は何かのイベントをトリガーとして実行されます。
イベントが発生するとLambdaランタイムと呼ばれる実行環境が構成された仮想マシンの中にLambda関数がロードされて実行されます。
Lambdaランタイムの正体は、隔離されたLinuxコンテナ環境になります。

Lambdaランタイム環境の取得
Lambda関数の書式は以下の通りになっています。
def 関数名(event, context):
関数処理
return 戻り値
Lambdaランタイム環境の情報は、context引数を通じて取得できます。
取得できる情報は主に以下の通りです。
| プロパティ | 詳細 |
|---|---|
| function_name | Lambda関数の名前 |
| function_version | Lambda関数のバージョン |
| invoked_function_arn | Lambda関数の呼び出しに使用されたARN |
| memory_limit_in_mb | 割り当てらているメモリ量 |
| aws_request_id|リクエストに関連付けられたリクエストID | |
| log_group_name | CloudWatchLogsのロググループ名 |
| log_stream_name | CloudWatchLogsのログストリーム名 |
Lambda関数再利用
Lambda関数を実行環境にロードする際は、ある程度時間がかります。イベント発生のたびにロードしていると十分なパフォーマンスが発揮できなくなります。そこで、作成した実行環境をしばらくとっておき再利用することで、2回目以降の実行を高速化します。

再利用する際は、以下の点に注意する必要があります。
①前に実行したデータが残っている。
前に実行したデータが残っていると、書き込み処理を実行した際に同名のファイルが存在しま すとエラーになる可能性があります。
②イベントハンドラ以外に、毎回実行するコードが存在する。
イベント発生ごとに呼びだしが確証されるのは、イベントハンドラだけであり、それ以外のグローバルな場所にコードを記載しても初回ロード時のみしか実行されない。
(例)
import datatime
today = datatime.data.today() ←初回ロード時にのみ実行される
def lambda_handler(event, context):
msg = str(today)
return msg
プロビジョニング
Lmabda関数の初回実行時のランタイム環境の準備には時間がかかります。
これを回避する方法として、あらかじめ指定した個数のランタイム環境を準備しておくことができます。
この設定は「プロビジョニングされた同時実行設定」から設定できます。

イベントモデル
Lambda関数が呼び出されるイベントは大きく2種類に分かれます。
| イベント種類 | 詳細 |
|---|---|
| プッシュモデル | イベントソースがLambdaを呼び出す |
| ストリームベース | Lambda関数側が、イベントソースを流れるデータをポーリングし、データを取得する |

プッシュモデル
プッシュモデルには、以下の2つの種類があります。
| 種類 | 詳細 |
|---|---|
| 同期呼び出し | Lambda関数の実行が終わるまで、呼び出し元は戻らない。実行が完了するとLambda関数の戻り値(returnした値)が、呼び出し元に渡される。同時実行数の制限にかかると、再試行されない。 |
| 非同期呼び出し | イベントはイベントキューに格納され、呼び出し元に戻らない。同時実行数の制限にかかると、実行を遅らせながら、最大6時間の間に再試行される。 |

イベントをキューから取り出してLambda関数を実行したとき、実行がエラーになった場合その記録がCLoudWatchLogに記録され、しばらく待って最大「2回」試行されます。再試行回数に関しては変更する可能です。
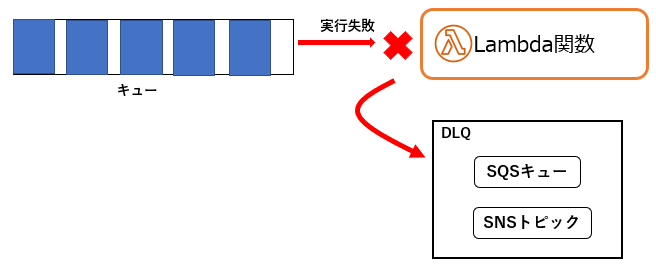
全ての試行に失敗したときは、イベントは消失します。DLQ(DeadLetterQueue) を構成しておけば、すべての試行に失敗したときは、そのイベントをあらかじめ作成しておいた「SQSキュー」に溜めたり、「SNSトピック」に通知したりできます。
非同期処理の注意点として以下の2点があります。
①実行順序が保証されない
②正常な時もタイミングによっては2回以上呼び出されることがある
→何度実行しても同じ結果に実装しておく必要がある。(冪等性)
ストリームベース
ストリームベースは流れるデータをLambda側で監視する方式です。
例えばDynamoDBのストリームに関してLambda関数を設定すると、ストリームが監視され、レコードの「追加」「更新」「削除」の際にLambda関数が実行されるようになります。

ストリームベースでは、Lambda処理が失敗した際はストリームの有効期間の間、ずっと再試行を続けます。エラーが解決されるまで、新しいデータは受信されません。
なのでストリームデータは、順に処理することを確実にします。
ストリームベースの同時実行数は、シャード数(同時に並列実行される数) により決定します。

おわりに
今回は、Lambdaの個人的に忘れそうなところについて記載しました。
新しい知識をつけても実践しないと、忘れていくなあと常々感じています。
今後も復習がてら以前つけた知識について記載してこうと思います。
拝見いただきありがとうございます。
以上
Discussion