ポケモンWordleの回答を補助するコードを書いた(Pythonにおけるargparse, re, csvモジュールを使った習作)
はじめに
Wordleというゲームをご存知だろうか。
固定長の枠に単語を当てはめると、当てはめた文字が「正解(正しい位置にあり、文字も正しい)」なのか、「惜しい(その文字が含まれるが場所が違う)」、「間違い(その文字は含まれない)」の状態で表され
それを元に正解の単語を探し当てるという言葉遊びだ。
一時期流行し、各国版が作られたり、特定ジャンルに特化したものが作られたりと派生したが、
そのうちの一つが「ポケモンWordle」だ。
これを解くには、かなりの数のポケモンの名前を把握している必要があり
ポケモンに全然詳しくない、にわかトレーナーのわたしにとっては、資料なしで正解するのはほぼ不可能だ。
しかし、資料があったとてその中から条件に合う名前を検索するのは容易ではない。
普通に検索(Ctrl+F)するだけでは文字の場所などを指定することができず、膨大な数がマッチするので結局は目grep頼りだ。
そこで、スクリプトの力を使ってチートすることにした。
環境
- Windows 10 Pro
- Python 3.9.13 (Windows Store)
設計とコード
要件としては
- 「含まれる文字」「含まれない文字」「正解の位置と文字」をスクリプトに渡し、正答の可能性があるポケモンの名前を一覧表示する
- オプションとして、世代と文字数を指定できるようにする
の2点に絞ることができるため、比較的シンプルだ。
データの蒐集
とにもかくにも、正答であるポケモンの名前を収集する必要がある。
幸いにして、超人気コンテンツであることからWeb上の情報も充実しており、第9世代(スカーレット・バイオレット)までのポケモン一覧を容易に蒐集することができた。
No Name English Name Gen
1 フシギダネ Bulbasaur 1
2 フシギソウ Ivysaur 1
3 フシギバナ Venusaur 1
4 ヒトカゲ Charmander 1
・
・
・
1005 トドロクツキ Roaring Moon 9
1006 テツノブジン Iron Valiant 9
1007 コライドン Koraidon 9
1008 ミライドン Miraidon 9
……今って1000種類も居るんですね。
コーディング
構造的にシンプルであるため、コマンドラインで動作するスクリプトとして実装することとした。
また、必要なモジュールとして下記を選定した。
- argparse … コマンドラインにおける引数の解釈・必須項目指定・ヘルプ表示など、包括的にサポートしてくれる神モジュール
- re … 正規表現モジュール(標準)
- csv … カンマやタブなど、特定の文字で区切られたテキストデータをハンドリングするモジュール
設計
動作内容についてもシンプルだ。
- コマンドライン引数をパースする
- 辞書データを読みこんで準備する
- それぞれのデータ(ポケモンの名前)について、引数で指定した条件に合致するか検査する。合致していれば表示する。
コード
上記を実際のコードに落とすと下記のようになる。
import argparse
import csv
import re
# サブルーチン:文字列の中で指定した文字がすべて含まれる場合にTrue
def contains_chars_and(string, chars):
matchcnt=0
for char in chars:
if char in string:
matchcnt +=1
if matchcnt >= len(chars):
return True
else:
return False
# サブルーチン:文字列の中で指定した文字が1つでも含まれていればTrue
def contains_chars_or(string, chars):
for char in chars:
if char in string:
return True
return False
# 引数の定義
argparser = argparse.ArgumentParser()
argparser.add_argument("--len", help='character length. default=5', type=int, default=5)
argparser.add_argument("--gen", help='Max Generation. default=9', type=int, default=9)
argparser.add_argument("--exact", help="exact character in exact position. use . for unknown characters.", type=str, default="")
argparser.add_argument("--include", help="include characters.", type=str, default="")
argparser.add_argument("--exclude", help="exclude characters.", type=str, default="")
args = argparser.parse_args()
# 辞書データ(TSV形式)の読み込み
with open('dic.tsv', 'r', encoding='utf8') as fh:
csvreader = csv.reader(fh, delimiter='\t')
dic = [row for row in csvreader] # リストに変換する
# メインループ:1行ごとに条件にマッチするか調べる
total = 0
match = 0
for row in dic:
# 文字数、世代による初期フィルタリング
if(len(row[1]) != args.len) : continue
if(int(row[3]) > args.gen) : continue
total += 1
if(args.include != "" and contains_chars_and(row[1], list(args.include)) != True) : continue # 惜しい文字がすべて含まれていなければスキップ
if(args.exclude != "" and contains_chars_or(row[1], list(args.exclude)) == True) : continue # 含まれない文字が1つでも含まれていればスキップ
if args.exact != "" and not re.match("^"+args.exact+"$", row[1] ) : continue # 正規表現にマッチしなければスキップ
match += 1
if match <= 50: print(row[1]) # 最大50件の可能性を表示
print("Match: {}/{}".format(match, total))
動作確認
実際に動作させてみよう。
初手は何でもよいので、好きなポケモンの名前を入力する。
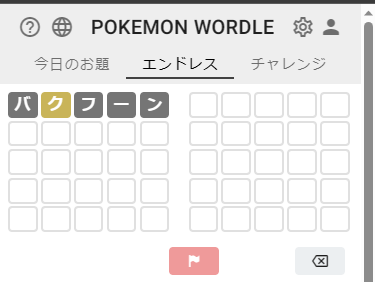
正解に「バ」「フ」「ー」「ン」は含まれず、「ク」は含まれるが位置が異なるという結果になった。
これを上記スクリプトに投入する。
> python.exe .\solver.py --exclude バフーン --include ク
ストライク
アルクジラ
(中略)
ノノクラゲ
ナゾノクサ
Match: 32/562
562個のレコードから32個まで絞り込むことができたようだ。
次の手として、条件に合致した「ストライク」を入力してみる。

あら、またダメでしたね。
今回の不正解文字を追加して、もう1回スクリプトに投げてみる。
> python.exe .\solver.py --exclude バフーンストライ --include ク
ドクロッグ
マクノシタ
レジロック
ゴルダック
ソルロック
マルヤクデ
(中略)
ナゾノクサ
Match: 14/562
さらに14個まで絞り込むことができた。
「マクノシタ」では「ク」と位置が「バクフーン」のそれと同じであるため、確実に不正解であることが分かる。
同様に「レジロック」も「ストライク」と「ク」の位置が同じであるため省くことができる。
次手「マルヤクデ」を入力してみる。
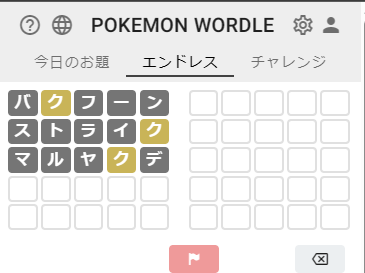
> python.exe .\solver.py --exclude バフーンストライマルヤデ --include ク
ドクロッグ
レジロック
レックウザ
クレセリア
コソクムシ
ビクティニ
ナゾノクサ
Match: 7/562
同様に、惜しい文字の位置に注意しつつ候補を選択する。
次は「レックウザ」を入力してみる。
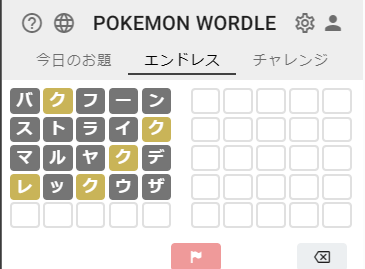
> python.exe .\solver.py --exclude バフーンストライマルヤデッウザ --include クレ
クレセリア
Match: 1/562
ここまで絞り込むことができれば「クレセリア」で確定である。

今回は「正解の文字」が出てこなかったので例示することができなかったが
正規表現を応用して文字と位置が合致するか検査することができる。
また、このスクリプトの問題として、「惜しい」文字の位置を省くことができず
ここだけ目視での確認とピックアップが必要になってしまうものがある。
これについてはコマンドライン引数のみで対応することが困難であることから、致し方ない仕様として残すこととした。
所感
- argparseモジュールはコマンドライン引数をパースするという地味だがとてもめんどくさい作業を一挙に引き受けてくれるため、これからも重宝することになるだろう。
- CSV/TSVデータについては、データ構造としてかなり古く、制約も多いためあまり使いたくはないという思いはあるが、手軽に扱えることから未だに現役であり、それらのハンドリングについてもテストしておいて損はないだろう。
- 正規表現については、PHPやJavaScriptのものと似たような取り扱いができ、また標準で使えることから今後多用していくだろうと思われる。
- 辞書データだが、実は文字ごとの出現頻度の合計で並び替えており、図鑑番号順になってはいない。それによりマッチする可能性を高めるよう工夫している。
Discussion