TCP/IPネットワーク
参考
環境作成
vm構築
# vm作成
multipass launch 20.04 -n linux-network -c 1 -m 2G -d 20G
# ログイン
multipass shell linux-network
事前準備
sudo apt-get update
sudo apt-get -y install \
bash \
coreutils \
grep \
iproute2 \
iputils-ping \
traceroute \
tcpdump \
bind9-dnsutils \
dnsmasq-base \
netcat-openbsd \
python3 \
curl \
wget \
iptables \
procps \
isc-dhcp-client
プロトコル階層(レイヤー)
TCP/IPのプロトコル階層
- アプリケーション層 (HTTP)
- トランスポート層 (TCP, UDP, ICMP)
- インターネット層 (IP)
- リンク層 (イーサネット(MACアドレス))
※ 一応、OSI参照モデル
- アプリケーション層
- プレゼンテーション層
- セッション層
- トランスポート層 (TCP)
- ネットワーク層 (IP)
- データリンク層
- 物理層
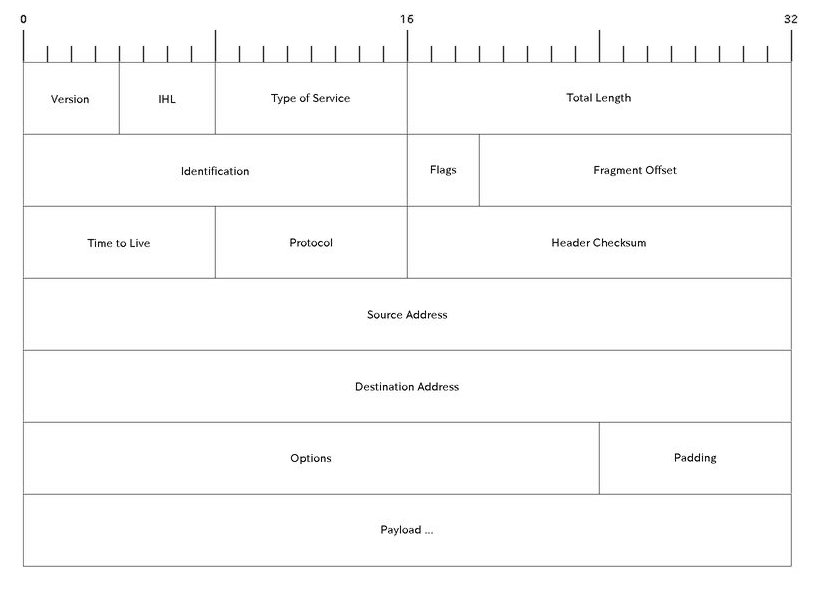
■ IP(インターネットプロトコル)のパケット構造
インターネット層のパケット構造
- Total Length
ペイロードを含めたパケットのサイズ - Time to Live
何回ルーターを経由したらパケットを破棄するか。(宛先に到達しないパケットがいつまでも残らないようにする) - Protocol
トランスポート層のプロトコル。TCPなら6、ICMPなら1、UDPなら17。 - Source Address
送信元のIPアドレス - Destination Address
送信先のIPアドレス
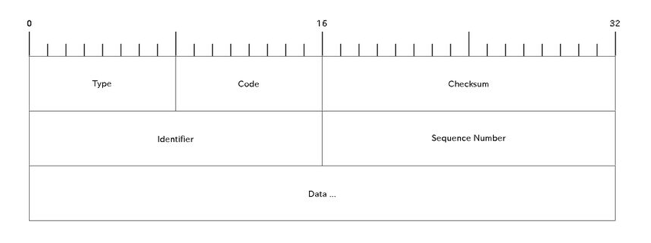
トランスポート層のパケット構造
上記、インターネット層のパケットの Payload にトランスポート層のヘッダが格納されます。
例えばICMPパケットの場合は下記のようなヘッダが Payload 部分に格納されます。
つまり、IPヘッダの末尾にICMPヘッダがくっつくことになるので、合わせると以下のような構造となります。
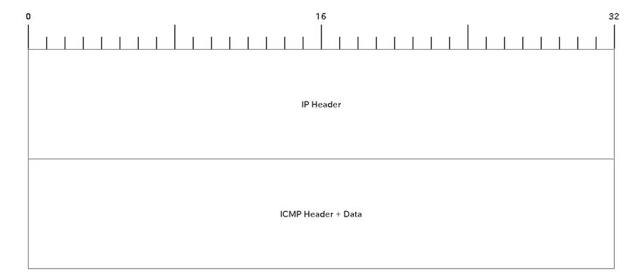
パケットを受け取ったコンピュータはIPヘッダの Protocol 部分を読み取ることで、後続の Payload をどう解釈するかを判断することができます。
パケット全体の長さも Total Length に書いてあるので、 Payload がどこまで続いているのかも判断できます。
このような通信の種類と長さに可変長のデータが続く形式のことを**LTV(Type-Length-Value)**といいます。
■ IPアドレスの確認
ネットワークインターフェース
lo や ens3 のことで、ざっくり言えばNICのこと。
ただし、NICをソフトウェアから扱うために抽象化したものなので、物理的なデバイスが存在しないネットワークインターフェースも存在します。
ループバックアドレス
lo に付与されている 127.0.0.1 はループバックアドレスという特殊なIPアドレスで、自分自身を表します。
ループバックアドレスが付与されている lo 仮想的なネットワークインターフェース。
$ ip address show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 52:54:00:68:e9:1c brd ff:ff:ff:ff:ff:ff
inet 10.194.185.50/24 brd 10.194.185.255 scope global ens3
valid_lft forever preferred_lft forever
inet6 fe80::5054:ff:fe68:e91c/64 scope link
valid_lft forever preferred_lft forever
■ IPパケットの確認
# -t 時刻に関する情報を出力しない
# -n IPアドレスを表示 (DNSのドメイン名を逆引きしない)
# -i <interface> パケットキャプチャ対象のネットワークインターフェース
# icmp パケットキャプチャ対象のプロトコル (icmp, tcp, udpなどが利用可能)
sudo tcpdump -tn -i any icmp
ping -c 3 8.8.8.8
tcpdumpの出力
ICMPでエコーリクエストとエコーリプライメッセージをやり取りしているのが確認できる。
※ 先頭のIP はIPパケットであることを示す
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on any, link-type LINUX_SLL (Linux cooked v1), capture size 262144 bytes
IP 10.194.185.50 > 8.8.8.8: ICMP echo request, id 2, seq 1, length 64
IP 8.8.8.8 > 10.194.185.50: ICMP echo reply, id 2, seq 1, length 64
IP 10.194.185.50 > 8.8.8.8: ICMP echo request, id 2, seq 2, length 64
IP 8.8.8.8 > 10.194.185.50: ICMP echo reply, id 2, seq 2, length 64
IP 10.194.185.50 > 8.8.8.8: ICMP echo request, id 2, seq 3, length 64
IP 8.8.8.8 > 10.194.185.50: ICMP echo reply, id 2, seq 3, length 64
IPアドレスについて詳しく
ネットワーク部とホスト部
IPアドレスはネットワーク部とホスト部という2つの要素から成り立っています。
これらは32ビットのアドレスを特定のビット数を境目にして前後にわけ、前半部分をネットワーク部、後半部分をホスト部とします。
また、IPアドレスのネットワーク部に対応する部分をネットワークアドレス 、ホスト部に対応する部分をホストアドレスとよびます。
例えば 192.168.0.2/24 であれば 192.0.2 がネットワークアドレスで、 .1 がホストアドレスです。
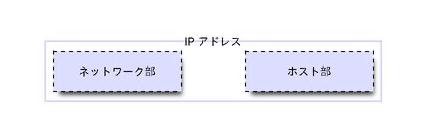
ネットワーク部はネットワークのセグメントを表すために存在し、同一セグメントに属するホストはルーターなしで通信可能です。(192.0.2.1/24と192.0.2.2/24はルーター無しで通信可能です)
ホスト部に利用可能なアドレス
下記の2アドレスはホストのアドレスとして設定できません
1. ネットワークアドレス
ホスト部のビットがすべて0のアドレス。(192.168.0.0/24における 192.168.0.0)
2. ブロードキャストアドレス
ホスト部のビットがすべて1のアドレス。 (192.168.0.0/24における192.168.0.255)
ブロードキャストアドレスはセグメントに所属しているノード全てに通信したいときの宛先として利用します。
■ traceroute
tracerouteコマンドはIPパケットのTTL(Time to Live)をうまく利用して、通信経路を表示します。
TTLはパケットが届く範囲を制限するためのフィールドで、0 - 255までの整数として解釈される値が格納されます。TTLの値はルーターを通過する事に1つづつ値が減っていき、0になるとそのパケットはルーターから破棄されます。
このとき、パケットはルーターは同時にICMPで時間切れ(TimeExceeded)のメッセージをパケットの送信元の送信します。
tracerouteコマンドはこの仕組みを利用し、TTLを1ずつ増やしたパケットを順番に送信することで、経路上のルーターからICMPのTimeExceededのメッセージを受け取り、それを表示します。
※ ルーターの中にはパケットを破棄したときにICMPのTimeExceededのメッセージを送信しない設定になっているものもあります。その場合、表示が * となります。
$ traceroute -n 8.8.8.8
traceroute to 8.8.8.8 (8.8.8.8), 30 hops max, 60 byte packets
1 10.194.185.1 0.184 ms 0.175 ms 0.170 ms
2 192.168.40.1 13.251 ms 13.411 ms 13.530 ms
3 * * *
4 10.202.106.131 37.200 ms 37.276 ms 37.271 ms
5 10.84.8.179 32.942 ms 32.980 ms 32.953 ms
6 10.84.8.187 37.315 ms 36.812 ms 36.672 ms
7 172.25.25.85 32.650 ms 172.25.25.81 27.427 ms 172.25.25.85 27.030 ms
8 10.1.11.253 27.002 ms 19.841 ms 10.1.11.249 21.317 ms
9 220.152.46.22 21.475 ms 220.152.46.26 21.662 ms 220.152.46.18 29.856 ms
10 142.250.163.198 30.237 ms 142.250.167.52 29.535 ms 29.368 ms
11 * * *
12 8.8.8.8 25.586 ms 25.282 ms 28.614 ms
■ ルートテーブル
ルートテーブルの表示
- 宛先IP
宛先IPに該当するルートが選択される。
defaultはどの宛先にも該当しない場合に使われる宛先。(デフォルトルート) - via xxx.xxx.xxx.xxx
ネクストホップ(ネクストホップとはパケットを次に渡す相手(ルーター)のこと)
宛先が同一セグメントではない場合、直接通信できないので、次にパケットを渡すルーターを指定しなければなりません。
※ 逆に宛先がホストのIPと同一セグメントであればネクストホップの指定は必要ありません。 - dev xxxxx
パケットを送信するデバイス - proto
- proto kernel: カーネルが自動生成した経路。
- proto dhcp: DHCPが自動生成した経路
- scope
- scope link: 直接 unicast/broadcastにて送信する経路。(自身が所属するネットワークなどが該当)
- scope host: 自分自身への経路
- scope global: ルーターを経由した他のネットワークへの経路。 (scopeオプションがない場合もこれに該当)
- src
送信元
$ ip route show
default via 10.194.185.1 dev ens3 proto dhcp src 10.194.185.50 metric 100
10.194.185.0/24 dev ens3 proto kernel scope link src 10.194.185.50
10.194.185.1 dev ens3 proto dhcp scope link src 10.194.185.50 metric 100
ルーティング
ルーティングテーブルを利用して、ネクストホップにパケットを転送する作業をルーティングという。
※ ネクストホップにバケットを渡す作業をフォワーディング(Forwarding)・ルートテーブルからネクストホップを調べる作業をルーティングと呼び、区別することもある。
■ 演習1
Network Namespace同士をvethで接続する簡単なネットワークを作ってみる
物理構成
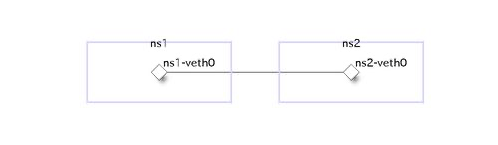
※ 同じネットワークセグメントに属するIPアドレス同士は、基本的にルーターがなくても通信可能です。(逆に言えばルーターが必要になるのは異なるセグメントの相手と通信したいときのみです。)
論理構成
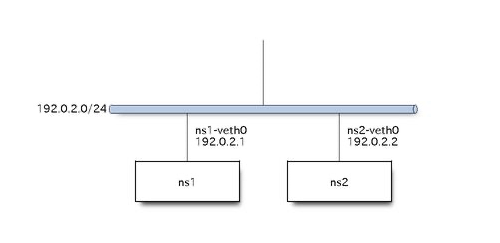
実装
# Network Namespace作成
sudo ip netns add ns1
sudo ip netns add ns2
# nsの一覧表示
sudo ip netns list
# veth (Virtual Ethenet Device | 仮想ネットワークインターフェース)を作成
sudo ip link add ns1-veth0 type veth peer name ns2-veth0
# vethの確認
sudo ip link show | grep veth
# vethをnsに接続
sudo ip link set ns1-veth0 netns ns1
sudo ip link set ns2-veth0 netns ns2
# nsに接続するとvethは見えなくなる
sudo ip link show | grep veth
# 代わりにns内からvethが見える様になる
sudo ip netns exec ns1 ip link show | grep veth
sudo ip netns exec ns2 ip link show | grep veth
# vethインターフェースにIPアドレスを付与。
sudo ip netns exec ns1 ip address add 192.0.2.1/24 dev ns1-veth0
sudo ip netns exec ns2 ip address add 192.0.2.2/24 dev ns2-veth0
# このままだとstateがDOWNになっているので、ネットワークインターフェースをUPする
sudo ip netns exec ns1 ip link set ns1-veth0 up
sudo ip netns exec ns2 ip link set ns2-veth0 up
# 確認
sudo ip netns exec ns1 ip a
sudo ip netns exec ns2 ip a
# 疎通確認 ns1 -> ns2
# -I: 送信元アドレスを指定する
# 指定しない場合はOSがソースアドレス選択(Source Address Selection)という仕組みで自動的に選ぶ
sudo ip netns exec ns1 ping -c 3 192.0.2.2 -I 192.0.2.1
# nsの全削除
sudo ip --all netns delete
# 一個づつ削除
sudo ip netns delete ns1
sudo ip netns delete ns2
その他
nsのshellにログイン
sudo ip netns exec <NetworkNamespace> /bin/bash
# shellからログアウトするとき
exit
■ 演習2
ルーターのあるネットワーク
物理構成
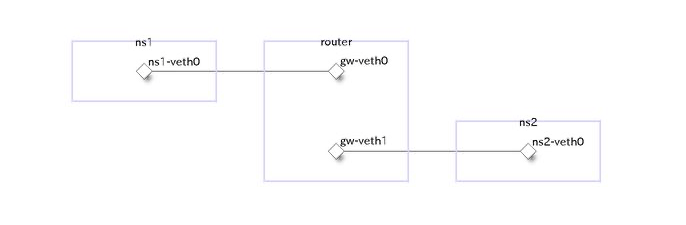
論理構成
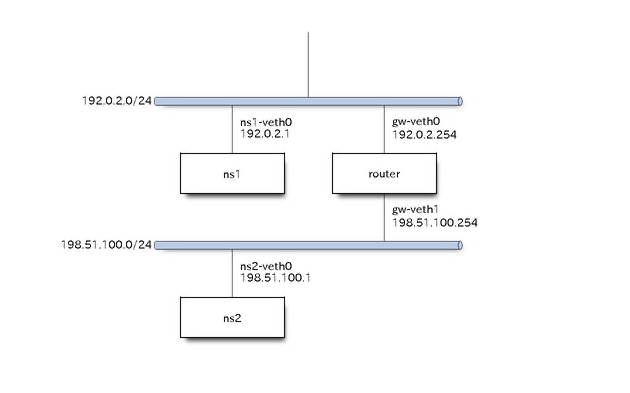
実装
# nsの作成
sudo ip netns add ns1
sudo ip netns add router
sudo ip netns add ns2
# vethの作成
sudo ip link add ns1-veth0 type veth peer name gw-veth0
sudo ip link add ns2-veth0 type veth peer name gw-veth1
# ns1とrouterを接続
sudo ip link set ns1-veth0 netns ns1
sudo ip link set gw-veth0 netns router
# ns2とrouterを接続
sudo ip link set gw-veth1 netns router
sudo ip link set ns2-veth0 netns ns2
# vethのup
sudo ip netns exec ns1 ip link set ns1-veth0 up
sudo ip netns exec router ip link set gw-veth0 up
sudo ip netns exec router ip link set gw-veth1 up
sudo ip netns exec ns2 ip link set ns2-veth0 up
# ns1側のipアドレス設定 (192.0.2.0/24)
sudo ip netns exec ns1 ip address add 192.0.2.1/24 dev ns1-veth0
sudo ip netns exec router ip address add 192.0.2.254/24 dev gw-veth0
# ns2側のipアドレス設定 (198.51.100.0/24)
sudo ip netns exec router ip address add 198.51.100.254/24 dev gw-veth1
sudo ip netns exec ns2 ip address add 198.51.100.1/24 dev ns2-veth0
# ルートテーブルの確認 (ns1->ns2, ns2->ns1へのルートが存在しない)
$ sudo ip netns exec ns1 ip route show
192.0.2.0/24 dev ns1-veth0 proto kernel scope link src 192.0.2.1
$ sudo ip netns exec ns2 ip route show
198.51.100.0/24 dev ns2-veth0 proto kernel scope link src 198.51.100.1
$ sudo ip netns exec router ip route show
192.0.2.0/24 dev gw-veth0 proto kernel scope link src 192.0.2.254
198.51.100.0/24 dev gw-veth1 proto kernel scope link src 198.51.100.254
# ルーティング設定
# ns1にns1 -> ns2 へのルートを追加
sudo ip netns exec ns1 ip route add default via 192.0.2.254
# ns2にns2 -> ns1 へのルートを追加
sudo ip netns exec ns2 ip route add default via 198.51.100.254
# 複数のネットワークインターフェース間でパケットを転送する設定。(ルーターとして動かすための設定)
sudo ip netns exec router sysctl net.ipv4.ip_forward=1
# MACアドレスの設定 (※ 別にやらなくてもOK)
sudo ip netns exec ns1 ip link set dev ns1-veth0 address 00:00:5E:00:53:11
sudo ip netns exec router ip link set dev gw-veth0 address 00:00:5E:00:53:12
sudo ip netns exec router ip link set dev gw-veth1 address 00:00:5E:00:53:21
sudo ip netns exec ns2 ip link set dev ns2-veth0 address 00:00:5E:00:53:22
# 疎通確認
# ns1 -> ns2
sudo ip netns exec ns1 ping -c 3 198.51.100.1 -I 192.0.2.1
# ns2 -> ns1
sudo ip netns exec ns2 ping -c 3 192.0.2.1 -I 198.51.100.1
# nsの削除
sudo ip --all netns delete
ダイナミックルーティング
今回はスタティックルーティングを利用しましたが、インターネット上ではBGP(Border Gateway Protocol) を利用して、動的にルーティング情報を交換し、更新するのが標準になっています。
■ 演習3
ルーターが2つある構成
物理構成
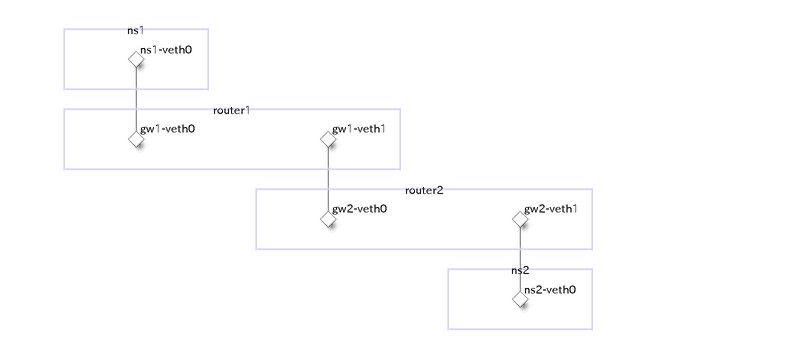
論理構成
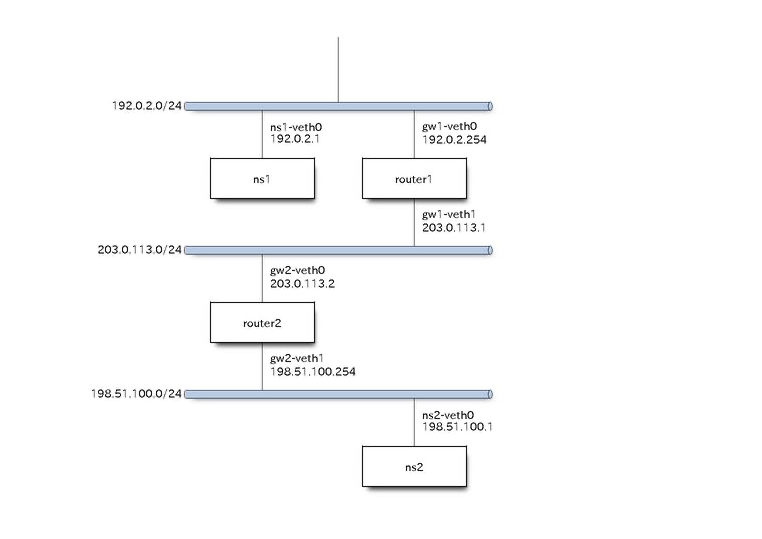
実装
# nsの作成
sudo ip netns add ns1
sudo ip netns add router1
sudo ip netns add router2
sudo ip netns add ns2
# vethの作成
sudo ip link add ns1-veth0 type veth peer name gw1-veth0
sudo ip link add gw1-veth1 type veth peer name gw2-veth0
sudo ip link add gw2-veth1 type veth peer name ns2-veth0
# ns1とrouter1を接続
sudo ip link set ns1-veth0 netns ns1
sudo ip link set gw1-veth0 netns router1
# router1とrouter2を接続
sudo ip link set gw1-veth1 netns router1
sudo ip link set gw2-veth0 netns router2
# router2とns2を接続
sudo ip link set gw2-veth1 netns router2
sudo ip link set ns2-veth0 netns ns2
# vethのup
sudo ip netns exec ns1 ip link set ns1-veth0 up
sudo ip netns exec router1 ip link set gw1-veth0 up
sudo ip netns exec router1 ip link set gw1-veth1 up
sudo ip netns exec router2 ip link set gw2-veth0 up
sudo ip netns exec router2 ip link set gw2-veth1 up
sudo ip netns exec ns2 ip link set ns2-veth0 up
# ns1-router1間のセグメント(192.0.2.1/24)のIPアドレスを設定
sudo ip netns exec ns1 ip address add 192.0.2.1/24 dev ns1-veth0
sudo ip netns exec router1 ip address add 192.0.2.254/24 dev gw1-veth0
# router1-router2間のセグメント(203.0.113.1/24)のIPアドレスを設定
sudo ip netns exec router1 ip address add 203.0.113.1/24 dev gw1-veth1
sudo ip netns exec router2 ip address add 203.0.113.2/24 dev gw2-veth0
# router2-ns2間のセグメント(198.51.100.0/24)のIPアドレスを設定
sudo ip netns exec router2 ip address add 198.51.100.254/24 dev gw2-veth1
sudo ip netns exec ns2 ip address add 198.51.100.1/24 dev ns2-veth0
# ルーティング設定
# ns1のデフォルトルートとしてrouter1を設定
sudo ip netns exec ns1 ip route add default via 192.0.2.254
# ns2のデフォルトルートとしてrouter2を設定
sudo ip netns exec ns2 ip route add default via 198.51.100.254
# router1にns2のセグメントへのルートを設定
# デフォルトルートを使ってもOK: sudo ip netns exec router1 ip route add default via 203.0.113.2
sudo ip netns exec router1 ip route add 198.51.100.0/24 via 203.0.113.2
# router2にns1のセグメントへのルートを設定
# デフォルトルートを使ってもOK: sudo ip netns exec router2 ip route add default via 203.0.113.1
sudo ip netns exec router2 ip route add 192.0.2.0/24 via 203.0.113.1
# router1とrouter2にip_forwardを許可
sudo ip netns exec router1 sysctl net.ipv4.ip_forward=1
sudo ip netns exec router2 sysctl net.ipv4.ip_forward=1
# 疎通確認
# ns1 -> ns2
sudo ip netns exec ns1 ping -c 3 198.51.100.1 -I 192.0.2.1
# ns2 -> ns1
sudo ip netns exec ns2 ping -c 3 192.0.2.1 -I 198.51.100.1
# 削除
sudo ip --all netns delete
イーサネット
イーサネットは、プロトコル階層に置いてIPの下に位置しています。OSI参照モデルであれば、下から2総文のデータリンク層と物理層に対応します。
イーサネットの役割
メタ的な説明
イーサネットの役割は「近隣までの荷物の配達」で、IPパケットが荷物の入った段ボールだとするならば、イーサネットはそれを運ぶためのトラックです。ダンボール箱のにもつはICMPのメッセージなどになるでしょう。(ただし、トラック1台にダンボール箱は1個しか積めません)
イーサネットではデータを送る単位、つまりトラック1台分のことをFrame(フレーム)といいます。
実際の説明
同一セグメント内でMACアドレスを利用して、フレームの送受信を行う仕組みです。
MACアドレスはNICごとに割り振られるアドレスで、ハードウェアアドレスとも呼ばれます。
MACアドレスは48ビットの正の整数で、上位24ビットがベンダーID、下位24ビットが機器のIDとなります。
※ 昨今は仮想化などでVMが利用するNICのMACアドレスがランダムに割り振られるので、重複する可能性が無くはないですが、基本的にはブロードキャストドメインの範囲で重複しなければ大丈夫なので、ほとんど問題ないです。
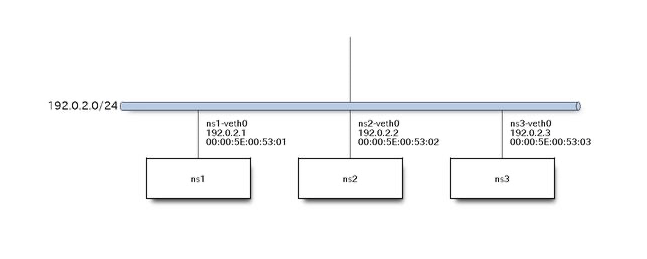
イーサネットフレームを観察する
検証用にセグメントが一つだけのネットワークを作成します。
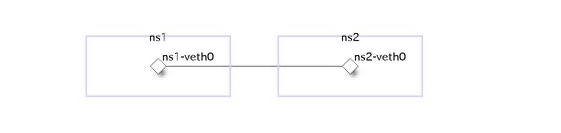
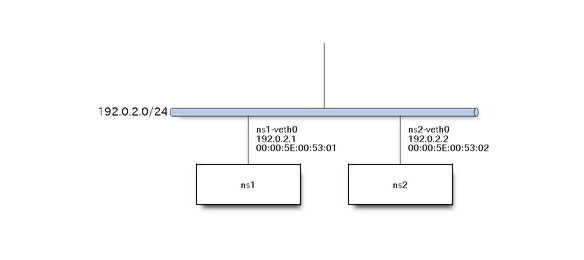
# nsの全削除
sudo ip --all netns delete
# nsの作成
sudo ip netns add ns1
sudo ip netns add ns2
# vethの作成
sudo ip link add ns1-veth0 type veth peer name ns2-veth0
# vethをnsに接続
sudo ip link set ns1-veth0 netns ns1
sudo ip link set ns2-veth0 netns ns2
# vethインターフェースにIPアドレスを付与。
sudo ip netns exec ns1 ip address add 192.0.2.1/24 dev ns1-veth0
sudo ip netns exec ns2 ip address add 192.0.2.2/24 dev ns2-veth0
# ネットワークインターフェースをUPする
sudo ip netns exec ns1 ip link set ns1-veth0 up
sudo ip netns exec ns2 ip link set ns2-veth0 up
# イーサネットを観察するためにMACアドレスをわかりやすい値に変更
sudo ip netns exec ns1 ip link set dev ns1-veth0 address 00:00:5E:00:53:01
sudo ip netns exec ns2 ip link set dev ns2-veth0 address 00:00:5E:00:53:02
# 疎通確認 ns1 -> ns2
sudo ip netns exec ns1 ping -c 3 192.0.2.2 -I 192.0.2.1
tcpdumpを利用してフレームを観察
# -t タイムスタンプを表示しない
# -n アドレスをそのまま表示。DNSで逆引きしない
# -e イーサネットのヘッダ情報を表示する
# -l 標準出力をバッファリングする (tcpdumpの出力結果をパイプ(|)を通じてほかのプログラムへ渡す際に必要となるオプション)
sudo ip netns exec ns1 tcpdump -tnel -i ns1-veth0 icmp
別のターミナルからpingを実行
# ns1 -> ns2
sudo ip netns exec ns1 ping -c 3 192.0.2.2 -I 192.0.2.1
出力
-eオプションを付けたことで、最初に表示される列がイーサネットに関する情報になっており、更に右の列にはIPとICMPに関する情報があります。
これは、イーサネットフレームによってIPのパケットが運ばれている様子を示しています。
ns1のvethインターフェースに設定したMACアドレス (00:00:5e:00:53:01) とns2のvethインターフェースに設定したMACアドレス(00:00:5e:00:53:02) 間でフレームの通信が行われているのがわかります。
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on ns1-veth0, link-type EN10MB (Ethernet), capture size 262144 bytes
00:00:5e:00:53:01 > 00:00:5e:00:53:02, ethertype IPv4 (0x0800), length 98: 192.0.2.1 > 192.0.2.2: ICMP echo request, id 16727, seq 1, length 64
00:00:5e:00:53:02 > 00:00:5e:00:53:01, ethertype IPv4 (0x0800), length 98: 192.0.2.2 > 192.0.2.1: ICMP echo reply, id 16727, seq 1, length 64
00:00:5e:00:53:01 > 00:00:5e:00:53:02, ethertype IPv4 (0x0800), length 98: 192.0.2.1 > 192.0.2.2: ICMP echo request, id 16727, seq 2, length 64
00:00:5e:00:53:02 > 00:00:5e:00:53:01, ethertype IPv4 (0x0800), length 98: 192.0.2.2 > 192.0.2.1: ICMP echo reply, id 16727, seq 2, length 64
00:00:5e:00:53:01 > 00:00:5e:00:53:02, ethertype IPv4 (0x0800), length 98: 192.0.2.1 > 192.0.2.2: ICMP echo request, id 16727, seq 3, length 64
00:00:5e:00:53:02 > 00:00:5e:00:53:01, ethertype IPv4 (0x0800), length 98: 192.0.2.2 > 192.0.2.1: ICMP echo reply, id 16727, seq 3, length 64
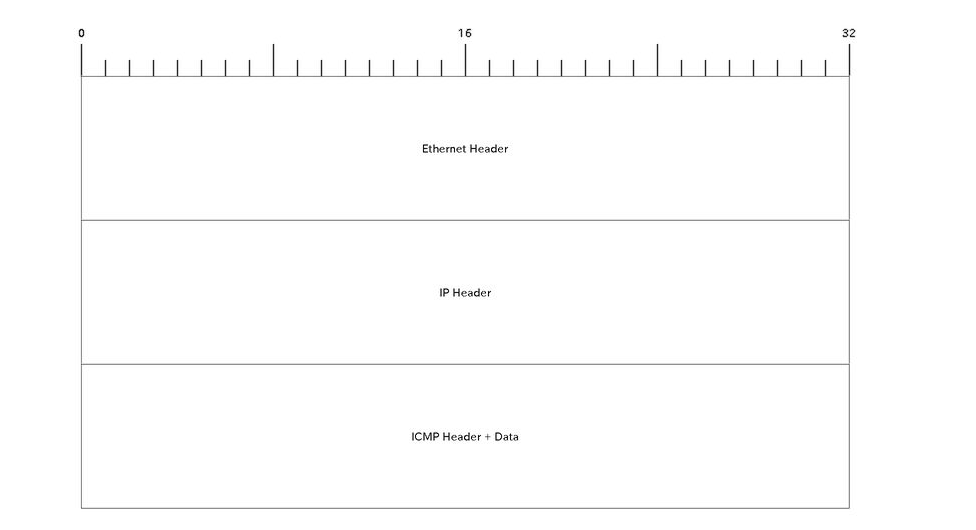
やり取りされているフレームを図示すると下記のようになります。
フレームの中にIPパケットが格納されており、IPパケットのパイロードにICMPヘッダ+データが格納されています。(低レイヤーから順に入れ子構造になります。)
※ イーサネットのヘッダがビット列のどこから始まるのかを知る方法は、イーサネットの企画によって異なります。古い規格ではプリアンブルと呼ばれる特定のビット列をフレームの直前に置くことで始まる場所を識別したりしていました。
MACアドレスを知るには
ns1からns2に通信するときに指定したのは192.0.2.2というIPだけですが、イーサネットで通信するには何らかの方法で相手のMACアドレスを知る必要があります。
このIPアドレスに対応するMACアドレスを解決するプロトコルをARP(Address Resolution Protocol) といいます。
ARPをtcpdumpで確認してみましょう
# ARPによって解決されたMACアドレスのキャッシュを一旦すべて削除します。
sudo ip netns exec ns1 ip neigh flush all
# tcpdumpの対象にARPを追加します。
sudo ip netns exec ns1 tcpdump -tnel -i ns1-veth0 icmp or arp
pingを打ちます。
sudo ip netns exec ns1 ping -c 3 192.0.2.2 -I 192.0.2.1
tcpdumpの出力
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on ns1-veth0, link-type EN10MB (Ethernet), capture size 262144 bytes
00:00:5e:00:53:01 > ff:ff:ff:ff:ff:ff, ethertype ARP (0x0806), length 42: Request who-has 192.0.2.2 tell 192.0.2.1, length 28
00:00:5e:00:53:02 > 00:00:5e:00:53:01, ethertype ARP (0x0806), length 42: Reply 192.0.2.2 is-at 00:00:5e:00:53:02, length 28
00:00:5e:00:53:01 > 00:00:5e:00:53:02, ethertype IPv4 (0x0800), length 98: 192.0.2.1 > 192.0.2.2: ICMP echo request, id 17365, seq 1, length 64
00:00:5e:00:53:02 > 00:00:5e:00:53:01, ethertype IPv4 (0x0800), length 98: 192.0.2.2 > 192.0.2.1: ICMP echo reply, id 17365, seq 1, length 64
00:00:5e:00:53:01 > 00:00:5e:00:53:02, ethertype IPv4 (0x0800), length 98: 192.0.2.1 > 192.0.2.2: ICMP echo request, id 17365, seq 2, length 64
00:00:5e:00:53:02 > 00:00:5e:00:53:01, ethertype IPv4 (0x0800), length 98: 192.0.2.2 > 192.0.2.1: ICMP echo reply, id 17365, seq 2, length 64
00:00:5e:00:53:01 > 00:00:5e:00:53:02, ethertype IPv4 (0x0800), length 98: 192.0.2.1 > 192.0.2.2: ICMP echo request, id 17365, seq 3, length 64
00:00:5e:00:53:02 > 00:00:5e:00:53:01, ethertype IPv4 (0x0800), length 98: 192.0.2.2 > 192.0.2.1: ICMP echo reply, id 17365, seq 3, length 64
00:00:5e:00:53:02 > 00:00:5e:00:53:01, ethertype ARP (0x0806), length 42: Request who-has 192.0.2.1 tell 192.0.2.2, length 28
00:00:5e:00:53:01 > 00:00:5e:00:53:02, ethertype ARP (0x0806), length 42: Reply 192.0.2.1 is-at 00:00:5e:00:53:01, length 28
IPの通信に先駆けてARPがやり取りされている様子が確認できます。
次のフレームではARPで192.0.2.2というIPアドレスを持った機器のMACアドレスを192.0.2.1に教えてほしいと要求しています。 (ARPリクエスト)
ff:ff:ff:ff:ff:ffはMACアドレスのブロードキャストアドレスで、送信先がブロードキャストアドレスのフレームは、「フレームが届く範囲のすべての機器に受け取ってほしい」という意味になります。
※ 送信先がブロードキャストアドレスになっているフレームをブロードキャストフレームといいます。
00:00:5e:00:53:01 > ff:ff:ff:ff:ff:ff, ethertype ARP (0x0806), length 42: Request who-has 192.0.2.2 tell 192.0.2.1, length 28
それに対して次のフレームで応答が得られています。内容は192.0.2.2というIPアドレスは 00:00:5e:00:53:02 というMACアドレスの危機が持っていますよ、というものです。 (ARPリプライ)
00:00:5e:00:53:02 > 00:00:5e:00:53:01, ethertype ARP (0x0806), length 42: Reply 192.0.2.2 is-at 00:00:5e:00:53:02, length 28
これを見ると、ARPもIPと同じようにイーサネットフレームで運ばれていることがわかります。
ARPもIPと同じようにイーサネットフレームというトラックで運ばれる荷物の一種というわけです。
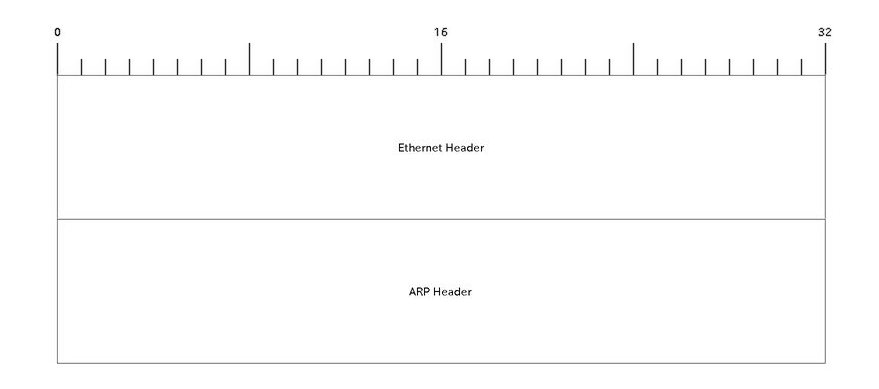
ARPテーブルの確認
$ sudo ip netns exec ns1 ip neigh show
192.0.2.2 dev ns1-veth0 lladdr 00:00:5e:00:53:02 STALE
パケットの積替え
送信先となるIPアドレスを持ったノードが、送信元と同じブロードキャストドメインにいる場合は一つのフレームでパケットを直接送り届けられます。
一般的に、ブロードキャストドメインの範囲は、ネットワークのセグメント同じになります。なので先程の実験では、パケットが異なるフレームに積み替えられる様子を観察できませんでした。
ネットワーク作成
今回は、ルーターを挟んだ2つのセグメントから構成されるネットワークで、パケットが異なるフレームに積み替えられる様子を観察します。
物理構成
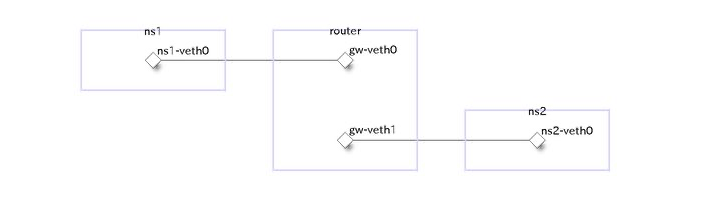
論理構成
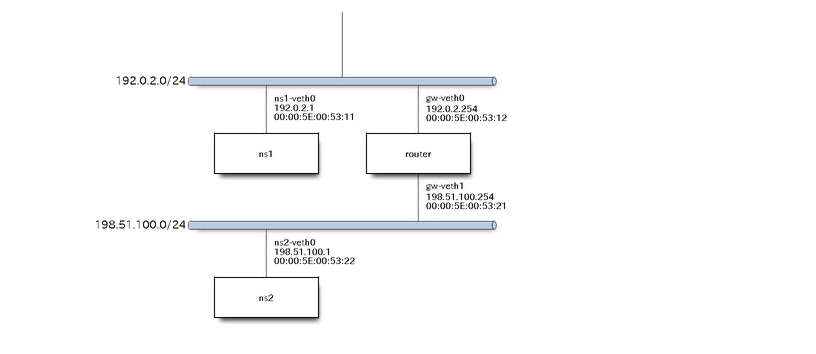
実装
# nsの削除
sudo ip --all netns delete
# nsの作成
sudo ip netns add ns1
sudo ip netns add router
sudo ip netns add ns2
# vethの作成
sudo ip link add ns1-veth0 type veth peer name gw-veth0
sudo ip link add ns2-veth0 type veth peer name gw-veth1
# ns1とrouterを接続
sudo ip link set ns1-veth0 netns ns1
sudo ip link set gw-veth0 netns router
# ns2とrouterを接続
sudo ip link set gw-veth1 netns router
sudo ip link set ns2-veth0 netns ns2
# vethのup
sudo ip netns exec ns1 ip link set ns1-veth0 up
sudo ip netns exec router ip link set gw-veth0 up
sudo ip netns exec router ip link set gw-veth1 up
sudo ip netns exec ns2 ip link set ns2-veth0 up
# ns1側のipアドレス設定 (192.0.2.0/24)
sudo ip netns exec ns1 ip address add 192.0.2.1/24 dev ns1-veth0
sudo ip netns exec router ip address add 192.0.2.254/24 dev gw-veth0
# ns2側のipアドレス設定 (198.51.100.0/24)
sudo ip netns exec router ip address add 198.51.100.254/24 dev gw-veth1
sudo ip netns exec ns2 ip address add 198.51.100.1/24 dev ns2-veth0
# ルーティング設定
# ns1にns1 -> ns2 へのルートを追加
sudo ip netns exec ns1 ip route add default via 192.0.2.254
# ns2にns2 -> ns1 へのルートを追加
sudo ip netns exec ns2 ip route add default via 198.51.100.254
# 複数のネットワークインターフェース間でパケットを転送する設定。(ルーターとして動かすための設定)
sudo ip netns exec router sysctl net.ipv4.ip_forward=1
# MACアドレスの設定 (※ 別にやらなくてもOK)
sudo ip netns exec ns1 ip link set dev ns1-veth0 address 00:00:5E:00:53:11
sudo ip netns exec router ip link set dev gw-veth0 address 00:00:5E:00:53:12
sudo ip netns exec router ip link set dev gw-veth1 address 00:00:5E:00:53:21
sudo ip netns exec ns2 ip link set dev ns2-veth0 address 00:00:5E:00:53:22
# 疎通確認
# ns1 -> ns2
sudo ip netns exec ns1 ping -c 3 198.51.100.1 -I 192.0.2.1
# ns2 -> ns1
sudo ip netns exec ns2 ping -c 3 192.0.2.1 -I 198.51.100.1
tcpdumpでパケットの積替えを確認
tcpdump
# ARPによって解決されたMACアドレスのキャッシュを一旦すべて削除します。
sudo ip netns exec router ip neigh flush all
sudo ip netns exec ns1 ip neigh flush all
sudo ip netns exec ns2 ip neigh flush all
# routerのns1側のネットワークインターフェースをパケットキャプチャ
sudo ip netns exec router tcpdump -tnel -i gw-veth0 icmp or arp
# routerのns2側のネットワークインターフェースをパケットキャプチャ
sudo ip netns exec router tcpdump -tnel -i gw-veth1 icmp or arp
別ターミナルからpingを実行
# ns1 -> ns2
sudo ip netns exec ns1 ping -c 3 198.51.100.1 -I 192.0.2.1
routerのns1側のネットワークインターフェース
$ sudo ip netns exec router tcpdump -tnel -i gw-veth0 icmp or arp
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on gw-veth0, link-type EN10MB (Ethernet), capture size 262144 bytes
00:00:5e:00:53:11 > ff:ff:ff:ff:ff:ff, ethertype ARP (0x0806), length 42: Request who-has 192.0.2.254 tell 192.0.2.1, length 28
00:00:5e:00:53:12 > 00:00:5e:00:53:11, ethertype ARP (0x0806), length 42: Reply 192.0.2.254 is-at 00:00:5e:00:53:12, length 28
00:00:5e:00:53:11 > 00:00:5e:00:53:12, ethertype IPv4 (0x0800), length 98: 192.0.2.1 > 198.51.100.1: ICMP echo request, id 17999, seq 1, length 64
00:00:5e:00:53:12 > 00:00:5e:00:53:11, ethertype IPv4 (0x0800), length 98: 198.51.100.1 > 192.0.2.1: ICMP echo reply, id 17999, seq 1, length 64
00:00:5e:00:53:11 > 00:00:5e:00:53:12, ethertype IPv4 (0x0800), length 98: 192.0.2.1 > 198.51.100.1: ICMP echo request, id 17999, seq 2, length 64
00:00:5e:00:53:12 > 00:00:5e:00:53:11, ethertype IPv4 (0x0800), length 98: 198.51.100.1 > 192.0.2.1: ICMP echo reply, id 17999, seq 2, length 64
00:00:5e:00:53:11 > 00:00:5e:00:53:12, ethertype IPv4 (0x0800), length 98: 192.0.2.1 > 198.51.100.1: ICMP echo request, id 17999, seq 3, length 64
00:00:5e:00:53:12 > 00:00:5e:00:53:11, ethertype IPv4 (0x0800), length 98: 198.51.100.1 > 192.0.2.1: ICMP echo reply, id 17999, seq 3, length 64
00:00:5e:00:53:12 > 00:00:5e:00:53:11, ethertype ARP (0x0806), length 42: Request who-has 192.0.2.1 tell 192.0.2.254, length 28
00:00:5e:00:53:11 > 00:00:5e:00:53:12, ethertype ARP (0x0806), length 42: Reply 192.0.2.1 is-at 00:00:5e:00:53:11, length 28
routerのns2側のネットワークインターフェース
$ sudo ip netns exec router tcpdump -tnel -i gw-veth1 icmp or arp
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on gw-veth1, link-type EN10MB (Ethernet), capture size 262144 bytes
00:00:5e:00:53:21 > ff:ff:ff:ff:ff:ff, ethertype ARP (0x0806), length 42: Request who-has 198.51.100.1 tell 198.51.100.254, length 28
00:00:5e:00:53:22 > 00:00:5e:00:53:21, ethertype ARP (0x0806), length 42: Reply 198.51.100.1 is-at 00:00:5e:00:53:22, length 28
00:00:5e:00:53:21 > 00:00:5e:00:53:22, ethertype IPv4 (0x0800), length 98: 192.0.2.1 > 198.51.100.1: ICMP echo request, id 17999, seq 1, length 64
00:00:5e:00:53:22 > 00:00:5e:00:53:21, ethertype IPv4 (0x0800), length 98: 198.51.100.1 > 192.0.2.1: ICMP echo reply, id 17999, seq 1, length 64
00:00:5e:00:53:21 > 00:00:5e:00:53:22, ethertype IPv4 (0x0800), length 98: 192.0.2.1 > 198.51.100.1: ICMP echo request, id 17999, seq 2, length 64
00:00:5e:00:53:22 > 00:00:5e:00:53:21, ethertype IPv4 (0x0800), length 98: 198.51.100.1 > 192.0.2.1: ICMP echo reply, id 17999, seq 2, length 64
00:00:5e:00:53:21 > 00:00:5e:00:53:22, ethertype IPv4 (0x0800), length 98: 192.0.2.1 > 198.51.100.1: ICMP echo request, id 17999, seq 3, length 64
00:00:5e:00:53:22 > 00:00:5e:00:53:21, ethertype IPv4 (0x0800), length 98: 198.51.100.1 > 192.0.2.1: ICMP echo reply, id 17999, seq 3, length 64
00:00:5e:00:53:22 > 00:00:5e:00:53:21, ethertype ARP (0x0806), length 42: Request who-has 198.51.100.254 tell 198.51.100.1, length 28
00:00:5e:00:53:21 > 00:00:5e:00:53:22, ethertype ARP (0x0806), length 42: Reply 198.51.100.254 is-at 00:00:5e:00:53:21, length 28
tcpdumpの内容を読み解く
ns1がPingを送信したいあいては 198.51.100.1 なので、ns1はパケットの送信先IPアドレスにに一致する宛先をルーティングテーブルから調べます。
ルートテーブルからデフォルトルートのネクストホップである 192.0.2.254 に送信すればいいことがわかります。
$ sudo ip netns exec ns1 ip route show
default via 192.0.2.254 dev ns1-veth0
192.0.2.0/24 dev ns1-veth0 proto kernel scope link src 192.0.2.1
ns1はデフォルトルートのネクストホップである 192.0.2.254 のMACアドレスを知るためにARPを使って、IPアドレスに紐づくMACアドレスを解決します。
00:00:5e:00:53:11 > ff:ff:ff:ff:ff:ff, ethertype ARP (0x0806), length 42: Request who-has 192.0.2.254 tell 192.0.2.1, length 28
00:00:5e:00:53:12 > 00:00:5e:00:53:11, ethertype ARP (0x0806), length 42: Reply 192.0.2.254 is-at 00:00:5e:00:53:12, length 28
解決したMACアドレス(00:00:5e:00:53:12)にフレームを送信します。
- イーサネットフレーム
- 送信元:
00:00:5e:00:53:11(ns1-veth0) - 送信先:
00:00:5e:00:53:12(gw-veth0)
- 送信元:
- パケット
- 送信元:
192.0.2.1 - 送信先:
198.51.100.1
- 送信元:
00:00:5e:00:53:11 > 00:00:5e:00:53:12, ethertype IPv4 (0x0800), length 98: 192.0.2.1 > 198.51.100.1: ICMP echo request, id 17999, seq 1, length 64
routerはns1からICMPのエコーリクエストを受け取ると、このパケットの次の送信先をルーティングテーブルで調べます。
$ sudo ip netns exec router ip route show
192.0.2.0/24 dev gw-veth0 proto kernel scope link src 192.0.2.254
198.51.100.0/24 dev gw-veth1 proto kernel scope link src 198.51.100.254
宛先 198.51.100.1 は 198.51.100.0/24 に該当するので gw-veth1を使えばパケットをそのまま送り届けられそうです。
routerは 198.51.100.1 のMACアドレスをARPで解決しようと試みます。
00:00:5e:00:53:21 > ff:ff:ff:ff:ff:ff, ethertype ARP (0x0806), length 42: Request who-has 198.51.100.1 tell 198.51.100.254, length 28
00:00:5e:00:53:22 > 00:00:5e:00:53:21, ethertype ARP (0x0806), length 42: Reply 198.51.100.1 is-at 00:00:5e:00:53:22, length 28
解決できたMACアドレスを使ってgw-veth1のネットワークインターフェースからns2側にフレームを送信します。
※ ここで新しいフレームにパケットが詰め替えられます (イーサネットフレームの積替えが起こると送信元と送信先のMACアドレスが変わります)
※ IPパケットが変わっていないことにも注目してください。文字通りパケットが新しいイーサネットフレームに積み替えられています。
- イーサネットフレーム
- 送信元:
00:00:5e:00:53:21(gw-veth1) - 送信先:
00:00:5e:00:53:22(ns2-veth0)
- 送信元:
- パケット
- 送信元:
192.0.2.1 - 送信先:
198.51.100.1
- 送信元:
00:00:5e:00:53:21 > 00:00:5e:00:53:22, ethertype IPv4 (0x0800), length 98: 192.0.2.1 > 198.51.100.1: ICMP echo request, id 17999, seq 1, length 64
ブリッジ
いわゆるL2スイッチのこと
- ブリッジ: データリンク層でフレームを転送する機械
- ルーター: ネットワーク層でパケットを転送する機械
物理構成
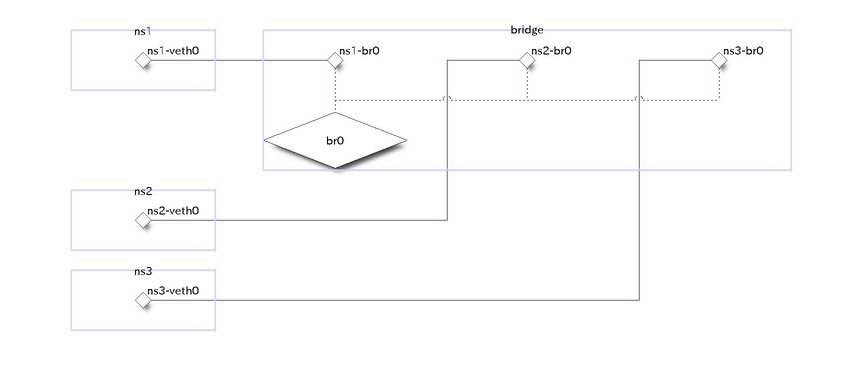
論理構成
実装
# nsの全削除
sudo ip --all netns delete
# nsの作成
sudo ip netns add ns1
sudo ip netns add ns2
sudo ip netns add ns3
sudo ip netns add bridge
# vethの作成
sudo ip link add ns1-veth0 type veth peer name ns1-br0
sudo ip link add ns2-veth0 type veth peer name ns2-br0
sudo ip link add ns3-veth0 type veth peer name ns3-br0
# bridgeとnsを接続
sudo ip link set ns1-veth0 netns ns1
sudo ip link set ns2-veth0 netns ns2
sudo ip link set ns3-veth0 netns ns3
sudo ip link set ns1-br0 netns bridge
sudo ip link set ns2-br0 netns bridge
sudo ip link set ns3-br0 netns bridge
# vethのup
sudo ip netns exec ns1 ip link set ns1-veth0 up
sudo ip netns exec ns2 ip link set ns2-veth0 up
sudo ip netns exec ns3 ip link set ns3-veth0 up
sudo ip netns exec bridge ip link set ns1-br0 up
sudo ip netns exec bridge ip link set ns2-br0 up
sudo ip netns exec bridge ip link set ns3-br0 up
# ipアドレス設定
sudo ip netns exec ns1 ip address add 192.0.2.1/24 dev ns1-veth0
sudo ip netns exec ns2 ip address add 192.0.2.2/24 dev ns2-veth0
sudo ip netns exec ns3 ip address add 192.0.2.3/24 dev ns3-veth0
# MACアドレスの設定 (なくても良い)
sudo ip netns exec ns1 ip link set dev ns1-veth0 address 00:00:5E:00:53:01
sudo ip netns exec ns2 ip link set dev ns2-veth0 address 00:00:5E:00:53:02
sudo ip netns exec ns3 ip link set dev ns3-veth0 address 00:00:5E:00:53:03
# bridgeの作成
sudo ip netns exec bridge ip link add dev br0 type bridge
# bridgeをup
sudo ip netns exec bridge ip link set br0 up
# bridgeにvethを接続
sudo ip netns exec bridge ip link set ns1-br0 master br0
sudo ip netns exec bridge ip link set ns2-br0 master br0
sudo ip netns exec bridge ip link set ns3-br0 master br0
sudo ip netns exec ns1 ping -c 3 192.0.2.2 -I 192.0.2.1
sudo ip netns exec ns1 ping -c 3 192.0.2.3 -I 192.0.2.1
確認
ブリッジに接続されているネットワークインターフェースを確認
$ sudo ip netns exec bridge bridge link show br0
27: ns1-br0@if28: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master br0 state forwarding priority 32 cost 2
29: ns2-br0@if30: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master br0 state forwarding priority 32 cost 2
31: ns3-br0@if32: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master br0 state forwarding priority 32 cost 2
スイッチングハブには自身のポートに接続されている機器のMACアドレスを学習する機能があり、このポートとMACアドレスの対応関係はMACアドレステーブルと言う台帳で管理されています。
なので、スイッチングハブとして動作するブリッジは通信相手がいないポートに無駄なフレームを転送することがありません。
ちなみに、bridge fdb show コマンドでMACアドレステーブルを確認することができます。
$ sudo ip netns exec bridge bridge fdb show br br0 | grep -i "00:00:5e"
00:00:5e:00:53:01 dev ns1-br0 master br0
00:00:5e:00:53:02 dev ns2-br0 master br0
00:00:5e:00:53:03 dev ns3-br0 master br0
■ ブリッジの操作コマンド
| 概要 | bridge-utils(brctl) | iproute2(ip/bridge) |
|---|---|---|
| ブリッジ追加 | brctl addbr <bridge> |
ip link add <bridge> type bridge |
| ブリッジ削除 | brctl delbr <bridge> |
ip link del <bridge> |
| IF追加 | brctl addif <bridge> <if> |
ip link set dev <if> master <bridge> |
| IF削除 | brctl delif <bridge> <if> |
ip link set dev <if> nomaster |
| 対象のブリッジのIF表示 | brctl show <bridge> |
ip link show master <bridge> または bridge link show <bridge>
|
| 全てのブリッジのIF表示 | brctl show |
bridge link show |
| STP 有効 | brctl stp <bridge> on |
bridge link set dev <if> guard off |
| STP 無効 | brctl stp <bridge> on |
bridge link set dev <if> guard on |
トランスポート層のプロトコル
プロトコルの階層構造でIPの更に上位に位置するプロトコル。
IPのペイロードとなるプロトコルで、OSI参照モデルであればトランスポート層に相当します。
代表的なものとしてTCP(Transmission Control Protocol) と UDP (UserDatazgram Protocol)がある。
UDP (UserDatagram Protocol)
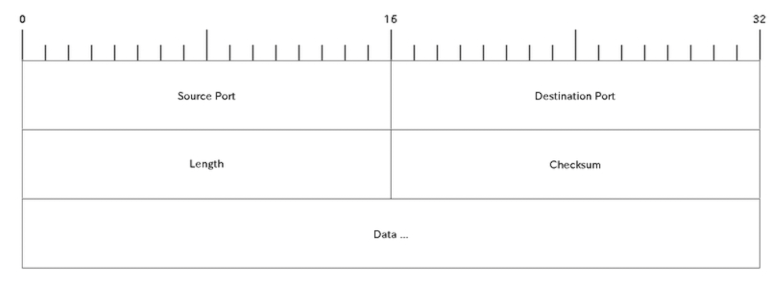
UDPのフォーマット
UDPのヘッダはIPヘッダの直後にペイロードとして連結されます。
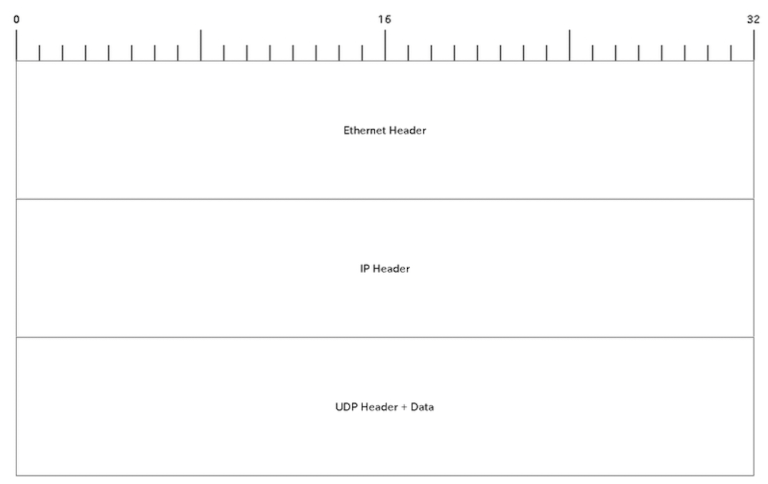
データグラム
UDPでやり取りするデータの単位はデータグラムといいます。
- Source Port: 送信元ポート
- Destination Port: 送信先ポート
- Data...: ペイロード
ポート
- 0 ~ 1023: (システムポート、ウェルノウンポート)
IANA (Internet Assigned Numbers Authority) がそれぞれのポート番号の用途を管理している。自分では使わない。 - 1024 ~ 49151: (ユーザーサポート、レジスタードポート)
IANA (Internet Assigned Numbers Authority) がそれぞれのポート番号の用途を管理している。自分では使わない。 - 49152 ~ 65535 (ダイナミックポート、プライベートポート)
自分で新たな用途に使うのであれば、この範囲を利用する。
ncコマンドでUDPを体験してみる
netcatの準備 netcat-openbsd と netcat-traditional が2種類あるが、 netcat-openbsd を利用します。
UDPサーバーを起動
# -u UDPで通信する
# -l サーバーとして動作させる
# -n IPアドレスを名前解決しない
# -v 詳細表示
nc -ulnv 127.0.0.1 54321
UDPクライアントを起動
# -u UDPで通信する
nc -u 127.0.0.1 54321
tcpdumpでUDPサーバーを監視
# -i <interface> パケットキャプチャ対象のネットワークインターフェース
# -t タイムスタンプを表示しない
# -n アドレスをそのまま表示。DNSで逆引きしない
# -l 標準出力を行でバッファリングする
# -A キャプチャした内容をASCII文字として表示する
sudo tcpdump -i lo -tnlA "udp and port 54321"
UDPクライアントでメッセージを送信
$ nc -u 127.0.0.1 54321
hello world
サーバーに送信されたことを確認
$ nc -ulnv 127.0.0.1 54321
Bound on 127.0.0.1 54321
Connection received on 127.0.0.1 43058
hello world
tcpdumpでパケットを確認。
送信先のポートはサーバーの54321、送信元のポートはOSが自動で採番したポート番号となります。
パケットのペイロードはUDPのデータグラムになっています。
$ sudo tcpdump -i lo -tnlA "udp and port 54321"
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on lo, link-type EN10MB (Ethernet), capture size 262144 bytes
IP 127.0.0.1.43058 > 127.0.0.1.54321: UDP, length 12
E..(0.@.@............2.1...'hello world
サーバーからクライアントに向けてメッセージを送信することもできます。
$ nc -ulnv 127.0.0.1 54321
Bound on 127.0.0.1 54321
Connection received on 127.0.0.1 43058
hello world
reply, hello
クライアントに送信されたことを確認。
$ nc -u 127.0.0.1 54321
hello world
reply, hello
tcpdumpを確認すると、送信先・送信元ポートが先ほどと入れ替わっています。
$ sudo tcpdump -i lo -tnlA "udp and port 54321"
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on lo, link-type EN10MB (Ethernet), capture size 262144 bytes
IP 127.0.0.1.43058 > 127.0.0.1.54321: UDP, length 12
E..(0.@.@............2.1...'hello world
IP 127.0.0.1.54321 > 127.0.0.1.43058: UDP, length 13
E..)t1@.@............1.2...(reply, hello
TCP (Transmission Control Protocol)
TCPはUDPと異なり、データが相手までちゃんと届いたことを確認しながら通信を進めます。 (コネクション型のプロトコルと呼びます)
パケットが経路上で破棄されるなどして、相手に届かなかった場合は同じデータを再び送ります。(再送制御)
また、パケットは到着順序が入れ替わる(アウトオブオーダー)こともありますが、TCPはデータの順序を正しく認識して通信できます。
TCPを使えば、パケットのロストやアウトオブオーダーを考慮する必要がなくなり、信頼性のある通信が可能なため、HTTPやSMTPといった様々なプロトコルの下位層として採用されています。
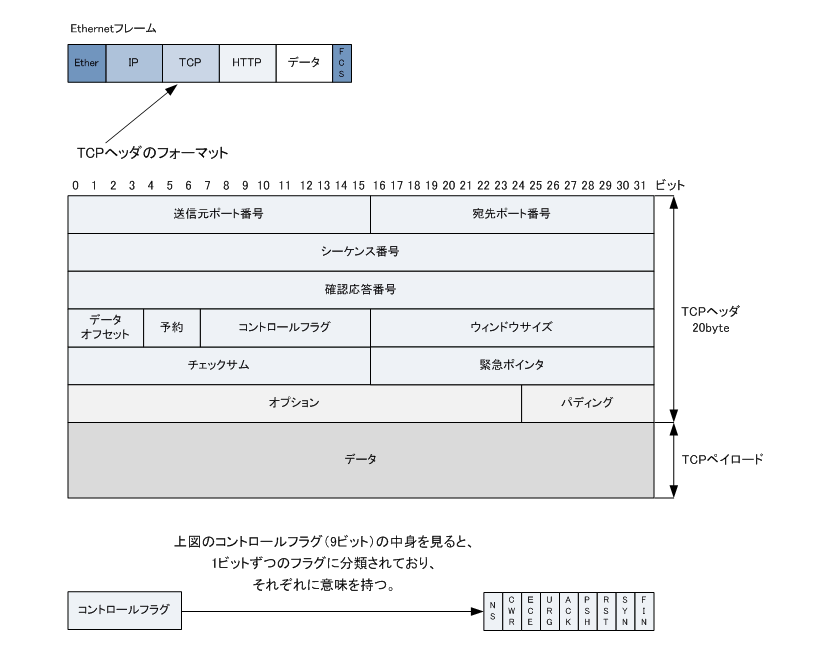
TCPのヘッダフォーマット
- 送信元ポート(16bit)
- 送信先ポート(16bit)
- シーケンス番号(32bit): 送信したデータの順序を示す値。(相手から受診した確認応答番号の値)
- 確認応答番号(32bit): 確認応答番号の値。(相手から受診したシーケンス番号+データサイズ)
- データオフセット(4bit): TCPヘッダの長さを表す値
- 予約(3bit): 将来の拡張のための領域
- コントロールフラグ(9bit):
- NS: 輻輳制御
- CWR: 輻輳制御ウィンドウ縮小
- ECE: ECN-Echo を示す。SYNフラグがセットされている場合、ECNが利用であることを意味する。
- URG: 緊急に処理すべきデータ含まれていることを示す。
- ACK: 確認応答番号のフィールドが有効であることを示す。コネクション確立時以外は値が「1」。
- PSH (push): 受信したデータをバッファリングせずに、即座にアプリケーション(上位)に渡すことを示す。
- RST (reset): コネクションが強制的に切断されることを示す。何らかの異常を検出した場合に送信される。
- SYN (synchronize): コネクションの確立を要求することを示す。シーケンス番号の同期を要求。
- FIN (finish): コネクションの正常な終了を要求することを示す。
- ウィンドウサイズ(16bit): 受信側が一度に受診できるデータ量を送信側に通知するために使用される
- チェックサム(16bit): TCPヘッダとデータ部分のエラーチェック用の値
- 緊急ポインタ(16bit): コントロールフラグURGのビットが立っているときのみ利用される。緊急データの開始位置を示す情報が入る
- オプション(可変長): TCPの通信において、性能を向上させるために利用する
- パディング(可変長): TCPヘッダの長さを32bitに調整するためのパディング
ncコマンドでTCPを体験してみる
TCPサーバーを起動
# -l サーバーとして動作させる
# -n IPアドレスを名前解決しない
# -v 詳細表示
nc -lnv 127.0.0.1 54321
tcpdumpでTCPサーバーを監視
# -i <interface> パケットキャプチャ対象のネットワークインターフェース
# -t タイムスタンプを表示しない
# -n アドレスをそのまま表示。DNSで逆引きしない
# -l 標準出力を行でバッファリングする
# -A キャプチャした内容をASCII文字として表示する
sudo tcpdump -i lo -tnlA "tcp and port 54321"
クライアントの準備
nc 127.0.0.1 54321
TCPでは接続した時点から通信が始まります。
サーバー側にクライアントからの接続を示すログが出力される
$ nc -lnv 127.0.0.1 54321
Listening on 127.0.0.1 54321
Connection received on 127.0.0.1 44760
tcpdumpにはクライアントがサーバーに接続した時点で3つのパケットがやり取りされます。(3wayハンドシェイク)このやり取りが完了するとTCPのコネクションが確立したとみなされます。
3wayハンドシェイクではコントロールフラグのSYNとACKが立ったセグメントを送ります。
-
SYN (Synchronize sequence number)
このビットが立ったパケットを送り合うことで、お互いにシーケンス番号を同期します。 -
ACK (Acknowledgment field significant)
TCPセグメントを受信した側が、正しくセグメントを受け取ったことを示すためのフラグ。
ACKが返ってこなければ、送信側は何度か同じセグメントを送信します。
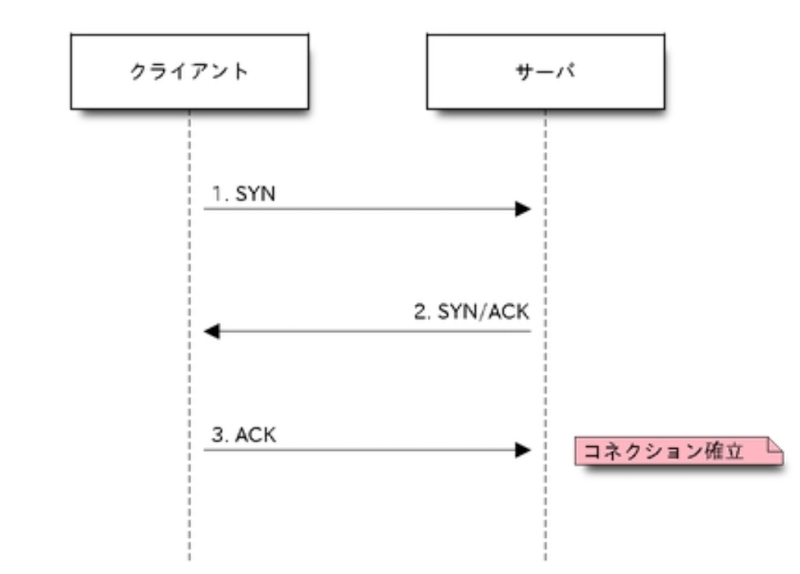
Flags [S] なら SYN が 、Flags [.] なら ACK のフラグが立っています。
$ sudo tcpdump -i lo -tnlA "tcp and port 54321"
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on lo, link-type EN10MB (Ethernet), capture size 262144 bytes
IP 127.0.0.1.44760 > 127.0.0.1.54321: Flags [S], seq 1295360057, win 65495, options [mss 65495,sackOK,TS val 4208188012 ecr 0,nop,wscale 7], length 0
E..<.5@.@.L............1M5.9.........0.........
...l........
IP 127.0.0.1.54321 > 127.0.0.1.44760: Flags [S.], seq 3835090924, ack 1295360058, win 65483, options [mss 65495,sackOK,TS val 4208188012 ecr 4208188012,nop,wscale 7], length 0
E..<..@.@.<..........1......M5.:.....0.........
...l...l....
IP 127.0.0.1.44760 > 127.0.0.1.54321: Flags [.], ack 1, win 512, options [nop,nop,TS val 4208188012 ecr 4208188012], length 0
E..4.6@.@.L............1M5.:.........(.....
...l...l
クライアント側からデータを送信してみます。
nc 127.0.0.1 54321
Hello, World!
サーバー側には受診した文字列が表示されます。
$ nc -lnv 127.0.0.1 54321
Listening on 127.0.0.1 54321
Connection received on 127.0.0.1 44760
Hello, World!
tcpdumpを確認すると、1つ目の通信でクライアントからサーバーに Hello, World! が送信されていることがわかります。
その後、サーバーからクライアントにデータをちゃんと受け取ったことを示すACKを送っています。
※ ack の後ろの数字は現在のシーケンス番号です。つまり、「ここまではちゃんと届いている」ということをクライアントに伝えています。
$ sudo tcpdump -i lo -tnlA "tcp and port 54321"
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on lo, link-type EN10MB (Ethernet), capture size 262144 bytes
// ... 略 ...
IP 127.0.0.1.44760 > 127.0.0.1.54321: Flags [P.], seq 1:15, ack 1, win 512, options [nop,nop,TS val 4210427304 ecr 4208188012], length 14
E..B.7@.@.L|...........1M5.:.........6.....
.......lHello, World!
IP 127.0.0.1.54321 > 127.0.0.1.44760: Flags [.], ack 15, win 512, options [nop,nop,TS val 4210427304 ecr 4210427304], length 0
E..4.k@.@.8W.........1......M5.H.....(.....
........
アプリケーション層のプロトコル
HTTP
試してみる
サーバー起動
# htmlファイル作成
mkdir -p ~/tmp/http-home
cat <<'EOF' > ~/tmp/http-home/index.html
<h1>Hello World</h1>
EOF
# サーバー起動
(cd ~/tmp/http-home; sudo python3 -m http.server -b 127.0.0.1 80)
クライアントからアクセス
ncコマンドでHTTPリクエスト
$ echo -en "GET / HTTP/1.0\r\n\r\n" | nc 127.0.0.1 80
HTTP/1.0 200 OK
Server: SimpleHTTP/0.6 Python/3.8.10
Date: Sun, 31 Mar 2024 08:22:58 GMT
Content-type: text/html
Content-Length: 21
Last-Modified: Sun, 31 Mar 2024 08:06:27 GMT
<h1>Hello World</h1>
もちろん対話形式で実行してもOK
$ nc 127.0.0.1 80
GET / HTTP/1.0
HTTP/1.0 200 OK
Server: SimpleHTTP/0.6 Python/3.8.10
Date: Sun, 31 Mar 2024 08:22:34 GMT
Content-type: text/html
Content-Length: 21
Last-Modified: Sun, 31 Mar 2024 08:06:27 GMT
<h1>Hello World</h1>
ncコマンドの内容を一つの文字列として表現したフォーマットがURLです。
# -X メソッド
# -D <filename> ファイルでヘッダ指定
$ curl -X GET -D - "http://127.0.0.1/"
HTTP/1.0 200 OK
Server: SimpleHTTP/0.6 Python/3.8.10
Date: Sun, 31 Mar 2024 08:28:03 GMT
Content-type: text/html
Content-Length: 21
Last-Modified: Sun, 31 Mar 2024 08:06:27 GMT
<h1>Hello World</h1>
テキストベースのブラウザを使ってみる
sudo apt install -y w3m
w3m http://127.0.0.1/
DNS
ドメイン名の解決手順
ネームサーバーを使った名前解決を体験してみる
tcpdumpでUDPの53番ポート(DNSプロトコル)を監視
sudo tcpdump -tnl -i any "udp and port 53"
ネームサーバー 8.8.8.8 に example.org の名前解決をリクエストする
$ dig +short @8.8.8.8 example.org A
93.184.216.34
tcpdumpを確認すると、ネームサーバーのIPアドレスに対して、DNSのペイロードを含んだパケットが送られ、解決されたIPv4アドレスがネームサーバーから返ってきていることがわかります。
$ sudo tcpdump -tnl -i any "udp and port 53"
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on any, link-type LINUX_SLL (Linux cooked v1), capture size 262144 bytes
IP 10.194.185.50.57230 > 8.8.8.8.53: 62760+ [1au] A? example.org. (52)
IP 8.8.8.8.53 > 10.194.185.50.57230: 62760$ 1/0/1 A 93.184.216.34 (56)
DHCP
DHCPを試してみる
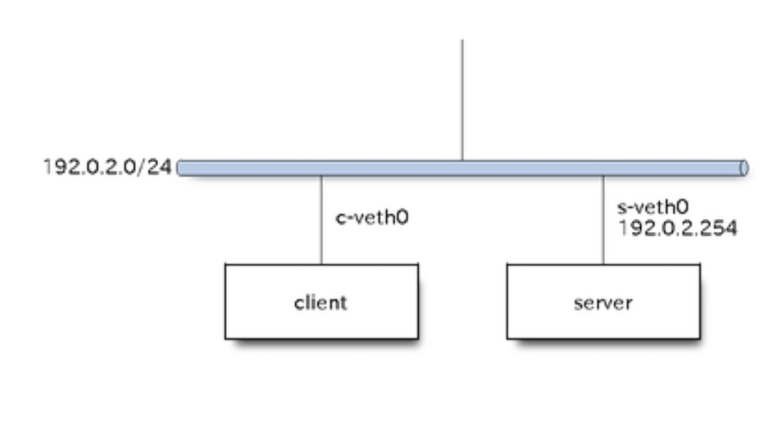
物理構成
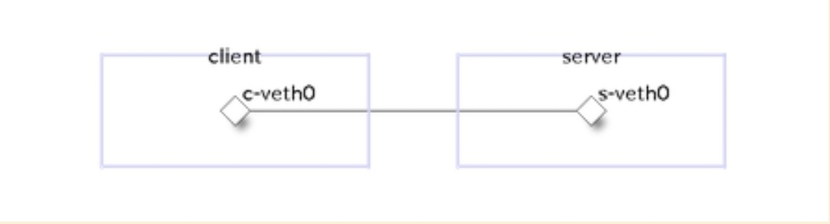
論理構成
作成
# nsを作成
sudo ip netns add server
sudo ip netns add client
# serverとclientを接続するvethを作成
sudo ip link add s-veth0 type veth peer name c-veth0
# serverとclientにvethを割り当てる
sudo ip link set s-veth0 netns server
sudo ip link set c-veth0 netns client
# MACアドレスを設定
sudo ip netns exec server ip link set dev s-veth0 address 00:00:5E:00:53:01
sudo ip netns exec client ip link set dev c-veth0 address 00:00:5E:00:53:02
# network interfaceをUPにする
sudo ip netns exec server ip link set s-veth0 up
sudo ip netns exec client ip link set c-veth0 up
# serverにIPアドレスを割り当てる
sudo ip netns exec server ip address add 192.0.2.254/24 dev s-veth0
server でdnsmasqコマンドを実行し、DNSキャッシュサーバー兼DHCPサーバーを起動
$ sudo ip netns exec server dnsmasq \
--dhcp-range=192.0.2.100,192.0.2.200,255.255.255.0 \
--interface=s-veth0 \
--port 0 \
--no-resolv \
--no-daemon
dnsmasq: started, version 2.90 DNS disabled
dnsmasq: compile time options: IPv6 GNU-getopt DBus no-UBus i18n IDN DHCP DHCPv6 no-Lua TFTP conntrack ipset no-nftset auth cryptohash DNSSEC loop-detect inotify dumpfile
dnsmasq-dhcp: DHCP, IP range 192.0.2.100 -- 192.0.2.200, lease time 1h
dnsmasq-dhcp: DHCPDISCOVER(s-veth0) 00:00:5e:00:53:02
dnsmasq-dhcp: DHCPOFFER(s-veth0) 192.0.2.177 00:00:5e:00:53:02
dnsmasq-dhcp: DHCPREQUEST(s-veth0) 192.0.2.177 00:00:5e:00:53:02
dnsmasq-dhcp: DHCPACK(s-veth0) 192.0.2.177 00:00:5e:00:53:02 linux-network
client でDHCPクライアントを実行すると、先程 server 側で設定した範囲内のIPアドレスが付与されます。
$ sudo ip netns exec client dhclient -d c-veth0
Internet Systems Consortium DHCP Client 4.4.1
Copyright 2004-2018 Internet Systems Consortium.
All rights reserved.
For info, please visit https://www.isc.org/software/dhcp/
Listening on LPF/c-veth0/00:00:5e:00:53:02
Sending on LPF/c-veth0/00:00:5e:00:53:02
Sending on Socket/fallback
DHCPDISCOVER on c-veth0 to 255.255.255.255 port 67 interval 3 (xid=0x5d148c1a)
DHCPOFFER of 192.0.2.177 from 192.0.2.254
DHCPREQUEST for 192.0.2.177 on c-veth0 to 255.255.255.255 port 67 (xid=0x1a8c145d)
DHCPACK of 192.0.2.177 from 192.0.2.254 (xid=0x5d148c1a)
bound to 192.0.2.177 -- renewal in 1512 seconds.
# Ctrl + C でコマンドを終了
# IPアドレスが付与されていることを確認
$ sudo ip netns exec client ip address show dev c-veth0
44: c-veth0@if45: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 00:00:5e:00:53:02 brd ff:ff:ff:ff:ff:ff link-netns server
inet 192.0.2.177/24 brd 192.0.2.255 scope global dynamic c-veth0
valid_lft 3325sec preferred_lft 3325sec
inet6 fe80::200:5eff:fe00:5302/64 scope link
valid_lft forever preferred_lft forever
NAT (Network Address Translation)
Source NAT
一般的にNATまたはNAPTと合ったときは多くの場合、このSource NATを示しています。
Source NATはパケットの送信元IPアドレスを変換します。
Source NATを試してみる
このネットワークでは 192.0.2.0/24 のセグメントをLAN、 203.0.113.0./24 のセグメントを仮想的なインターネットと見立てています。
今回は LANで使われる 192.0.2.0/24 セグメントをSource NATで 203.0.113.254 へと書き換えます。
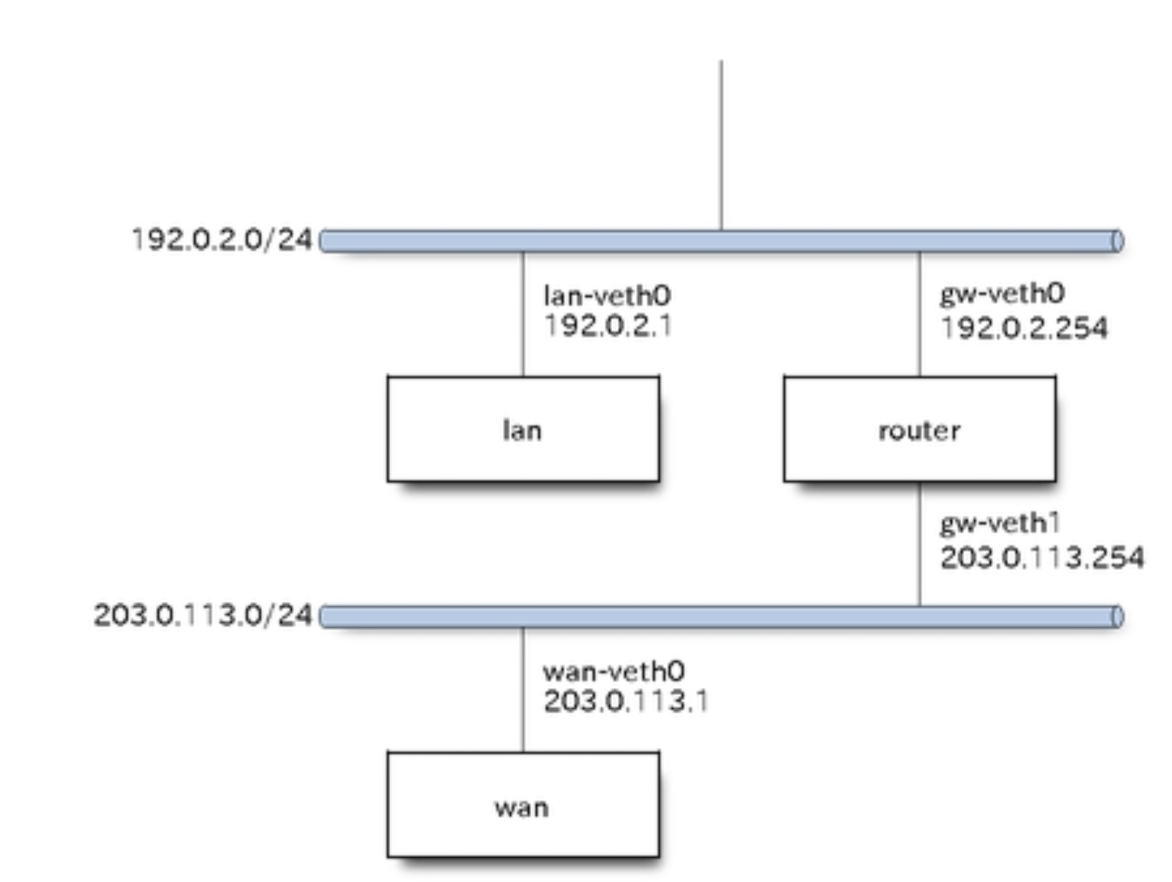
物理構成
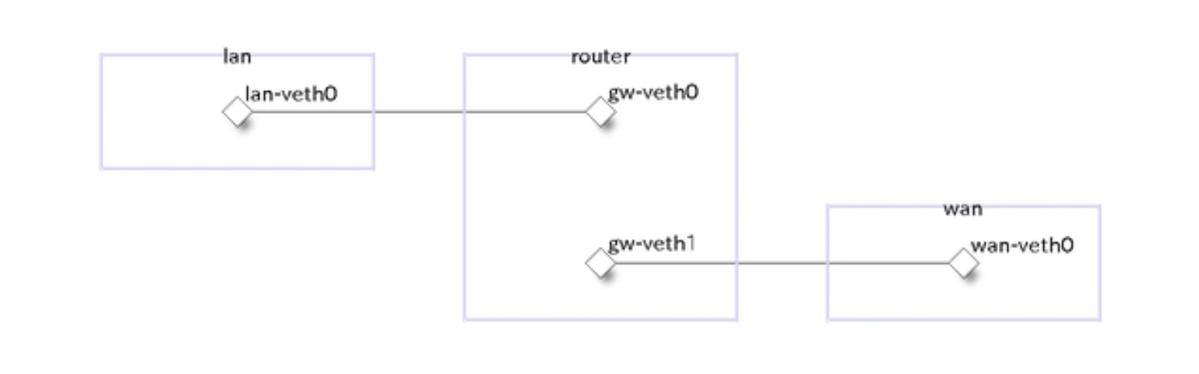
論理構成
実装
事前準備
sudo ip --all netns delete
# ns作成
sudo ip netns add lan
sudo ip netns add router
sudo ip netns add wan
# veth作成
sudo ip link add lan-veth0 type veth peer name gw-veth0
sudo ip link add wan-veth0 type veth peer name gw-veth1
# vethをnsに接続
sudo ip link set lan-veth0 netns lan
sudo ip link set gw-veth0 netns router
sudo ip link set gw-veth1 netns router
sudo ip link set wan-veth0 netns wan
# vethをup
sudo ip netns exec lan ip link set lan-veth0 up
sudo ip netns exec router ip link set gw-veth0 up
sudo ip netns exec router ip link set gw-veth1 up
sudo ip netns exec wan ip link set wan-veth0 up
# lanのIPアドレス設定
sudo ip netns exec lan ip address add 192.0.2.1/24 dev lan-veth0
sudo ip netns exec lan ip route add default via 192.0.2.254
# routerのIPアドレス設定
sudo ip netns exec router ip address add 192.0.2.254/24 dev gw-veth0
sudo ip netns exec router ip address add 203.0.113.254/24 dev gw-veth1
sudo ip netns exec router sysctl net.ipv4.ip_forward=1
# wanのIPアドレス設定
sudo ip netns exec wan ip address add 203.0.113.1/24 dev wan-veth0
sudo ip netns exec wan ip route add default via 203.0.113.254
iptablesコマンドで現状のNATの設定を確認。
※ iptablesでは処理を適用するタイミングのことをチェインと呼びます。
※ iptablesの仕組みを図解
$ sudo ip netns exec router iptables -t nat -L
Chain PREROUTING (policy ACCEPT)
target prot opt source destination
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
Chain POSTROUTING (policy ACCEPT)
target prot opt source destination
# -A 指定のチェインに新しいルールを指定。
# POSTROUTINGはルーティングが終わってパケットがインターフェースから出ていく直前
# -s 処理対象となる送信元IPアドレスの範囲
# -o 処理対象とする出力先にネットワークインターフェース
# -j 条件に一致したパケットをどのように処理するか。
# MASQUERADEはパケットに適用するターゲットがSource Natであることを示す
sudo ip netns exec router iptables -t nat \
-A POSTROUTING \
-s 192.0.2.0/24 \
-o gw-veth1 \
-j MASQUERADE
新しいSouceNATのルールが追加されたことを確認
$ sudo ip netns exec router iptables -t nat -L
Chain PREROUTING (policy ACCEPT)
target prot opt source destination
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
Chain POSTROUTING (policy ACCEPT)
target prot opt source destination
MASQUERADE all -- 192.0.2.0/24 anywhere
lanからwanに向けてpingを送信
$ sudo ip netns exec lan ping -c 3 203.0.113.1
PING 203.0.113.1 (203.0.113.1) 56(84) bytes of data.
64 bytes from 203.0.113.1: icmp_seq=1 ttl=63 time=0.095 ms
64 bytes from 203.0.113.1: icmp_seq=2 ttl=63 time=0.050 ms
64 bytes from 203.0.113.1: icmp_seq=3 ttl=63 time=0.044 ms
tcpdumpで通信を確認
# lan側の監視
sudo ip netns exec lan tcpdump -tnl -i lan-veth0 icmp
# wan側の監視
sudo ip netns exec wan tcpdump -tnl -i wan-veth0 icmp
# ping
sudo ip netns exec lan ping -c 1 203.0.113.1
lan側のtcpdumpの出力
lan側の通信は特に変化はない。
$ sudo ip netns exec lan tcpdump -tnl -i lan-veth0 icmp
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on lan-veth0, link-type EN10MB (Ethernet), capture size 262144 bytes
IP 192.0.2.1 > 203.0.113.1: ICMP echo request, id 46949, seq 1, length 64
IP 203.0.113.1 > 192.0.2.1: ICMP echo reply, id 46949, seq 1, length 64
wan側のtcpdumpの出力
wan側の通信
- 「行き」の送信元IPアドレスはlan側の
192.0.2.1から203.0.113.254に書き換えられています。 - 「戻り」の送信先IPアドレスが
203.0.113.254となっており、lan側に渡る際に192.0.2.1に書き換えられています。
$ sudo ip netns exec wan tcpdump -tnl -i wan-veth0 icmp
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on wan-veth0, link-type EN10MB (Ethernet), capture size 262144 bytes
IP 203.0.113.254 > 203.0.113.1: ICMP echo request, id 46949, seq 1, length 64
IP 203.0.113.1 > 203.0.113.254: ICMP echo reply, id 46949, seq 1, length 64
Destination NAT
いわゆる「ポートを空ける」という操作。
Destination NATを試してみる
環境は先ほどSourceNATで作成したものをそのまま流用します。
設定の追加
routerのwan側の IP (203.0.113.254) の 54321 ポートに来た通信を、lanの 192.0.2.1 にNATする設定を追加します。
# -A 指定のチェインに新しいルールを指定。
# PREROUTINGはネットワークインターフェースからパケットが入ってきた直後を表します。
# -p 処理対象となるトランスポート層のプロトコル
# --dport 処理対象のポート番号
# -d 書き換える前の送信元IPアドレス
# -j 条件に一致したパケットをどのように処理するか。
# DNATはパケットに適用するターゲットがDestination NATであることを示します
# --to-destination 書き換えたあとの送信先IPアドレス
sudo ip netns exec router iptables -t nat \
-A PREROUTING \
-p tcp \
--dport 54321 \
-d 203.0.113.254 \
-j DNAT \
--to-destination 192.0.2.1
設定を確認
$ sudo ip netns exec router iptables -t nat -L
Chain PREROUTING (policy ACCEPT)
target prot opt source destination
DNAT tcp -- anywhere 203.0.113.254 tcp dpt:54321 to:192.0.2.1
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
Chain POSTROUTING (policy ACCEPT)
target prot opt source destination
MASQUERADE all -- 192.0.2.0/24 anywhere
動作確認
lanにTCPの54321ポートを待ち受けるサーバーを起動します。
$ sudo ip netns exec lan nc -lnv 54321
Listening on 0.0.0.0 54321
wanからサーバーに接続します (クライアント)
$ sudo ip netns exec wan nc 203.0.113.254 54321
wanの通信内容をキャプチャします
$ sudo ip netns exec wan tcpdump -tnl -i wan-veth0 "tcp and port 54321"
lanの通信内容をキャプチャします。
$ sudo ip netns exec lan tcpdump -tnl -i lan-veth0 "tcp and port 54321"
wanからサーバーに文字列を送信します
$ sudo ip netns exec wan nc 203.0.113.254 54321
Hello, World
wan側の通信内容を確認します。
「行き」のパケットの送信先が 203.0.113.254.54321 から 192.0.2.1.54321 にNATされており、「帰り」のパケットの送信元が 192.0.2.1.54321 から 203.0.113.254.54321 にNATされているのが確認できます。
# wan側の通信内容
$ sudo ip netns exec wan tcpdump -tnl -i wan-veth0 "tcp and port 54321"
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on wan-veth0, link-type EN10MB (Ethernet), capture size 262144 bytes
IP 203.0.113.1.42964 > 203.0.113.254.54321: Flags [P.], seq 3993911778:3993911791, ack 1842736089, win 502, options [nop,nop,TS val 2003302218 ecr 2965997151], length 13
IP 203.0.113.254.54321 > 203.0.113.1.42964: Flags [.], ack 13, win 509, options [nop,nop,TS val 2966114284 ecr 2003302218], length 0
# lan側の通信内容
$ sudo ip netns exec lan tcpdump -tnl -i lan-veth0 "tcp and port 54321"
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on lan-veth0, link-type EN10MB (Ethernet), capture size 262144 bytes
IP 203.0.113.1.42964 > 192.0.2.1.54321: Flags [P.], seq 3993911778:3993911791, ack 1842736089, win 502, options [nop,nop,TS val 2003302218 ecr 2965997151], length 13
IP 192.0.2.1.54321 > 203.0.113.1.42964: Flags [.], ack 13, win 509, options [nop,nop,TS val 2966114284 ecr 2003302218], length 0
HTTPクライアント
HTTPサーバー
cat <<EOF > ~/tmp/http-home/index.html
<h1>Hello, World</h1>
EOF
# サーバー起動
(cd ~/tmp/http-home; sudo python3 -m http.server -b 127.0.0.1 80)
HTTPクライアント
- socket()
- ソケットでどんな種類の通信をするか指定する
- connect()
- 通信したいサーバーとポートを指定して接続を開く
- send() / recv()
- バイト列を送受信する
- close()
- 接続を閉じる
httpclient.py
#!/usr/bin/env python3
"""ソケットを使って HTTP クライアントを実装したスクリプト"""
import socket
def send_msg(sock, msg):
"""ソケットに指定したバイト列を書き込む関数"""
# これまでに送信できたバイト数
total_sent_len = 0
# 送信したいバイト数
total_msg_len = len(msg)
# まだ送信したいデータが残っているか判定する
while total_sent_len < total_msg_len:
# ソケットにバイト列を書き込んで、書き込めたバイト数を得る
sent_len = sock.send(msg[total_sent_len:])
print(f"send message: {msg[total_sent_len:total_sent_len + sent_len]}")
# まったく書き込めなかったらソケットの接続が終了している
if sent_len == 0:
raise RuntimeError('socket connection broken')
# 書き込めた分を加算する
total_sent_len += sent_len
def recv_msg(sock, chunk_len=1024):
"""ソケットから接続が終わるまでバイト列を読み込むジェネレータ関数"""
while True:
# ソケットから指定したバイト数を読み込む
received_chunk = sock.recv(chunk_len)
print(f"received chunk: {received_chunk}")
# まったく読めなかったときは接続が終了している
if len(received_chunk) == 0:
break
# 受信したバイト列を返す
yield received_chunk
def main():
"""スクリプトとして実行されたときに呼び出されるメイン関数"""
# IPv4 / TCP で通信するソケットを用意する
client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# ループバックアドレスの TCP/80 ポートに接続する
client_socket.connect(('127.0.0.1', 80))
# HTTP サーバからドキュメントを取得するための GET リクエスト
request_text = 'GET / HTTP/1.0\r\n\r\n'
# 文字列をバイト列にエンコードする
request_bytes = request_text.encode('ASCII')
# ソケットにリクエストのバイト列を書き込む
send_msg(client_socket, request_bytes)
# ソケットからレスポンスのバイト列を読み込む
received_bytes = b''.join(recv_msg(client_socket))
# 読み込んだバイト列を文字列にデコードする
received_text = received_bytes.decode('ASCII')
# 得られた文字列を表示する
print(received_text)
# 使い終わったソケットを閉じる
client_socket.close()
if __name__ == '__main__':
"""スクリプトのエントリーポイントとしてメイン関数を実行する"""
main()
$ python3 httpclient.py
send message: b'GET / HTTP/1.0\r\n\r\n'
received chunk: b'HTTP/1.0 200 OK\r\nServer: SimpleHTTP/0.6 Python/3.8.10\r\nDate: Tue, 02 Apr 2024 06:05:52 GMT\r\nContent-type: text/html\r\nContent-Length: 21\r\nLast-Modified: Sun, 31 Mar 2024 08:06:27 GMT\r\n\r\n'
received chunk: b'<h1>Hello World</h1>\n'
received chunk: b''
HTTP/1.0 200 OK
Server: SimpleHTTP/0.6 Python/3.8.10
Date: Tue, 02 Apr 2024 06:05:52 GMT
Content-type: text/html
Content-Length: 21
Last-Modified: Sun, 31 Mar 2024 08:06:27 GMT
<h1>Hello World</h1>
エコーサーバー
- socket()
- ソケットでどんな種類の通信をするかを指定する
- bind()
- 接続を待ち受けるIPアドレスとポート番号を指定する
- listen()
- 接続の待受を開始する
- accept()
- 接続してきたクライアントを処理する
- send() / recv()
- バイト列を送受信する
- close()
- 接続を閉じる
echoserver.py
#!/usr/bin/env python3
"""ソケットを使ってエコーサーバを実装したスクリプト"""
import socket
def send_msg(sock, msg):
"""ソケットに指定したバイト列を書き込む関数"""
# これまでに送信できたバイト数
total_sent_len = 0
# 送信したいバイト数
total_msg_len = len(msg)
# まだ送信したいデータが残っているか判定する
while total_sent_len < total_msg_len:
# ソケットにバイト列を書き込んで、書き込めたバイト数を得る
sent_len = sock.send(msg[total_sent_len:])
# まったく書き込めなかったらソケットの接続が終了している
if sent_len == 0:
raise RuntimeError('socket connection broken')
# 書き込めた分を加算する
total_sent_len += sent_len
def recv_msg(sock, chunk_len=1024):
"""ソケットから接続が終わるまでバイト列を読み込むジェネレータ関数"""
while True:
# ソケットから指定したバイト数を読み込む
received_chunk = sock.recv(chunk_len)
# まったく読めなかったときは接続が終了している
if len(received_chunk) == 0:
break
# 受信したバイト列を返す
yield received_chunk
def main():
"""スクリプトとして実行されたときに呼び出されるメイン関数"""
# IPv4 / TCP で通信するソケットを用意する
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# setsockopt() はソケットの挙動を変更するオプションを指定するメソッド。 'Address already in use' を回避する。
server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, True)
# クライアントから接続を待ち受ける IP アドレスとポート番号を指定する
server_socket.bind(('127.0.0.1', 54321))
# 接続の待ち受けを開始する
server_socket.listen()
# サーバが動作を開始したことを表示する
print('starting server ...')
# accept() はクライアントからの接続を待ち受けるメソッド。接続があると新しいソケットとクライアントの情報を返す。
# ※ クライアントからの接続があるまでこの部分で一旦処理がストップします。(ブロッキング)
client_socket, (client_address, client_port) = server_socket.accept()
# 接続してきたクライアントの情報を表示する
print(f'accepted from {client_address}:{client_port}')
# ソケットからバイト列を読み込む
for received_msg in recv_msg(client_socket):
# 読み込んだ内容をそのままソケットに書き込む (エコーバック)
send_msg(client_socket, received_msg)
# 送受信した内容を出力しておく
print(f'echo: {received_msg}')
# 使い終わったソケットをクローズする
client_socket.close()
server_socket.close()
if __name__ == '__main__':
"""スクリプトのエントリーポイントとしてメイン関数を実行する"""
main()
サーバーを起動
$ python3 echoserver.py
starting server ...
クライアントとしてサーバーに接続すると、サーバー側にクライアントが接続した旨のメッセージが表示されます。
# クライアント側
$ nc 127.0.0.1 54321
# サーバー側
$ python3 echoserver.py
starting server ...
accepted from 127.0.0.1:40794
クライアントからメッセージを送信すると、同じ内容がサーバーから返却されます。
# クライアント側
$ nc 127.0.0.1 54321
Hello, World!
Hello, World!
# サーバー側
$ python3 echoserver.py
starting server ...
accepted from 127.0.0.1:40794
echo: b'Hello, World!\n'
バイナリベースのプロトコル
コンピュータはCPUのアーキテクチャや動作モードによってビッグエンディアンかリトルエンディアン可が異なりますが、TCP/IPの世界ではバイトオーダーをビッグエンディアンに統一しています。
※ ネットワークにおけるビッグエンディアンをネットワークバイトオーダーと呼ぶことがあります。
なので、バイナリデータをTCP/IPで送受信するとき、コンピュータは自身のCPUアーキテクチャや動作モードによって、バイトオーダーを変換しなければなりません。
足し算をサーバーに依頼するプロトコルを作ってみる (ADDプロトコル)
リクエストフォーマット
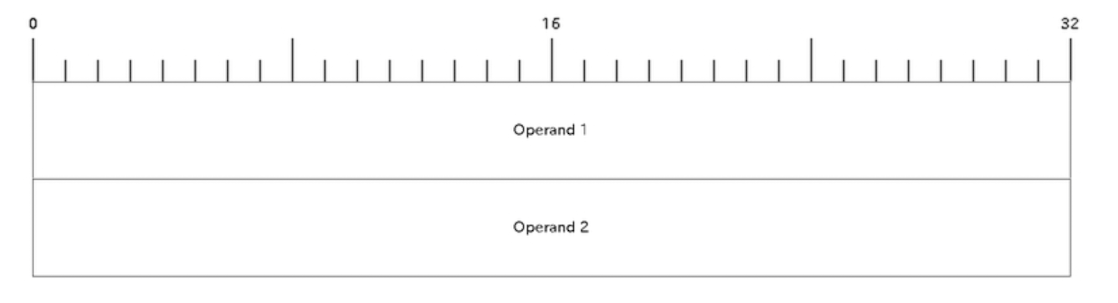
レスポンスフォーマット
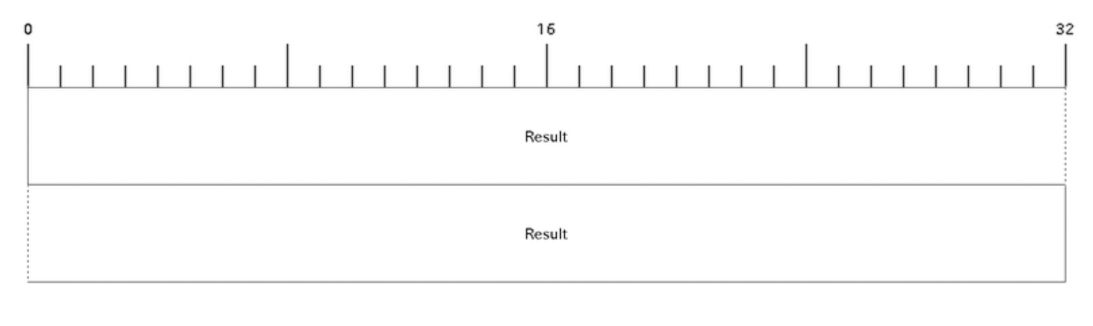
ADDプロトコルで通信するときのパケット
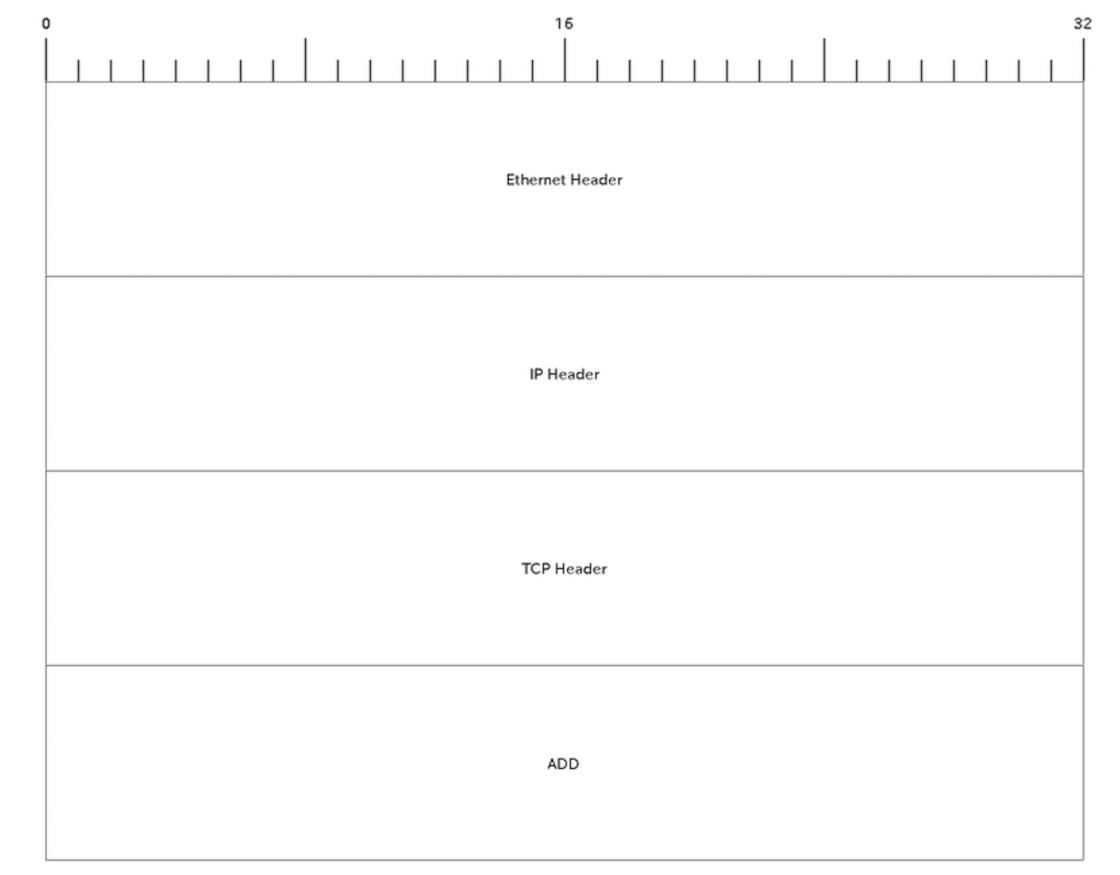
サーバー
addserver.py
#!/usr/bin/env python3
"""ソケットを使って ADD プロトコルを実装したサーバのスクリプト"""
import socket
import struct
def send_msg(sock, msg):
"""ソケットに指定したバイト列を書き込む関数"""
# これまでに送信できたバイト数
total_sent_len = 0
# 送信したいバイト数
total_msg_len = len(msg)
# まだ送信したいデータが残っているか判定する
while total_sent_len < total_msg_len:
# ソケットにバイト列を書き込んで、書き込めたバイト数を得る
sent_len = sock.send(msg[total_sent_len:])
# まったく書き込めなかったらソケットの接続が終了している
if sent_len == 0:
raise RuntimeError('socket connection broken')
# 書き込めた分を加算する
total_sent_len += sent_len
def recv_msg(sock, total_msg_size):
"""ソケットから特定のバイト数を読み込む関数"""
# これまでに受信できたバイト数
total_recv_size = 0
# 指定したバイト数を受信できたか判定する
while total_recv_size < total_msg_size:
# 残りのバイト列を受信する
received_chunk = sock.recv(total_msg_size - total_recv_size)
# 1 バイトも読めなかったときはソケットの接続が終了している
if len(received_chunk) == 0:
raise RuntimeError('socket connection broken')
# 受信したバイト列を返す
yield received_chunk
# 受信できたバイト数を加算する
total_recv_size += len(received_chunk)
def main():
"""スクリプトとして実行されたときに呼び出されるメイン関数"""
# IPv4 / TCP で通信するソケットを用意する
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 'Address already in use' の回避策
server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, True)
# ループバックアドレスの TCP/54321 ポートを使う
server_socket.bind(('127.0.0.1', 54321))
# 接続を待ち受ける
server_socket.listen()
# サーバが動作を開始したことを表示する
print('starting server ...')
# クライアントからの接続を処理する
client_socket, (client_address, client_port) = server_socket.accept()
# 接続してきたクライアントの情報を表示する
print(f'accepted from {client_address}:{client_port}')
# バイト列を受信する (total_msg_size=8 は 1byte * 8 で 32 ビットの整数 2 つ分)
received_msg = b''.join(recv_msg(client_socket, total_msg_size=8))
# 受信したバイト列を表示する
print(f'received: {received_msg}')
# バイト列を 2 つの 32 ビットの整数として解釈する
# バイトオーダー、サイズ、アライメント - struct - python3: https://docs.python.org/ja/3/library/struct.html#byte-order-size-and-alignment
# !: ネットワークバイトオーダー (ビッグエンディアン)
# i: 32 ビットの符号付き整数
(operand1, operand2) = struct.unpack('!ii', received_msg)
# 解釈した値を表示する
print(f'operand1: {operand1}, operand2: {operand2}')
# 計算する
result = operand1 + operand2
# 計算した値を表示する
print(f'result: {result}')
# 計算した値を 64 ビットの整数としてネットワークバイトオーダーのバイト列に変換する
# バイトオーダー、サイズ、アライメント - struct - python3: https://docs.python.org/ja/3/library/struct.html#byte-order-size-and-alignment
# !: ネットワークバイトオーダー (ビッグエンディアン)
# q: 64 ビットの符号付き整数
result_msg = struct.pack('!q', result)
# ソケットにバイト列を書き込む
send_msg(client_socket, result_msg)
# 書き込んだバイト列を表示する
print(f'sent: {result_msg}')
# ソケットの接続を終了する
client_socket.close()
server_socket.close()
if __name__ == '__main__':
"""スクリプトのエントリーポイントとしてメイン関数を実行する"""
main()
クライアント
addclient.py
#!/usr/bin/env python3
"""ソケットを使って ADD プロトコルを実装したクライアントのスクリプト"""
import socket
import struct
def send_msg(sock, msg):
"""ソケットに指定したバイト列を書き込む関数"""
# これまでに送信できたバイト数
total_sent_len = 0
# 送信したいバイト数
total_msg_len = len(msg)
# まだ送信したいデータが残っているか判定する
while total_sent_len < total_msg_len:
# ソケットにバイト列を書き込んで、書き込めたバイト数を得る
sent_len = sock.send(msg[total_sent_len:])
# まったく書き込めなかったらソケットの接続が終了している
if sent_len == 0:
raise RuntimeError('socket connection broken')
# 書き込めた分を加算する
total_sent_len += sent_len
def recv_msg(sock, total_msg_size):
"""ソケットから特定のバイト数を読み込む関数"""
# これまでに受信できたバイト数
total_recv_size = 0
# 指定したバイト数を受信できたか判定する
while total_recv_size < total_msg_size:
# 残りのバイト列を受信する
received_chunk = sock.recv(total_msg_size - total_recv_size)
# 1 バイトも読めなかったときはソケットの接続が終了している
if len(received_chunk) == 0:
raise RuntimeError('socket connection broken')
# 受信したバイト列を返す
yield received_chunk
# 受信できたバイト数を加算する
total_recv_size += len(received_chunk)
def main():
"""スクリプトとして実行されたときに呼び出されるメイン関数"""
# IPv4 / TCP で通信するソケットを用意する
client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# ループバックアドレスの TCP/54321 ポートに接続する
client_socket.connect(('127.0.0.1', 54321))
# 足し算したい値を用意する
operand1, operand2 = 1000, 2000
# 送信する値を確認する
print(f'operand1: {operand1}, operand2: {operand2}')
# ネットワークバイトオーダーのバイト列に変換する
# バイトオーダー、サイズ、アライメント - struct - python3: https://docs.python.org/ja/3/library/struct.html#byte-order-size-and-alignment
# !: ネットワークバイトオーダー (ビッグエンディアン)
# i: 32 ビットの符号付き整数
request_msg = struct.pack('!ii', operand1, operand2)
# ソケットにバイト列を書き込む
send_msg(client_socket, request_msg)
# 書き込んだバイト列を表示する
print(f'sent: {request_msg}')
# ソケットからバイト列を読み込む
received_msg = b''.join(recv_msg(client_socket, 8))
# 読み込んだバイト列を表示する
print(f'received: {received_msg}')
# 64 ビットの整数として解釈する
# バイトオーダー、サイズ、アライメント - struct - python3: https://docs.python.org/ja/3/library/struct.html#byte-order-size-and-alignment
# !: ネットワークバイトオーダー (ビッグエンディアン)
# q: 64 ビットの符号付き整数
(added_value, ) = struct.unpack('!q', received_msg)
# 解釈した値を表示する
print(f'result: {added_value}')
# ソケットを閉じる
client_socket.close()
if __name__ == '__main__':
"""スクリプトのエントリーポイントとしてメイン関数を実行する"""
main()
実行
サーバーを起動
$ python3 addserver.py
starting server ...
クライアントスクリプトを実行すると、サーバーがパケットを受診し、結果を返します。
# クライアント側
$ python3 addclient.py
operand1: 1000, operand2: 2000
sent: b'\x00\x00\x03\xe8\x00\x00\x07\xd0'
received: b'\x00\x00\x00\x00\x00\x00\x0b\xb8'
result: 3000
# サーバー側
$ python3 addserver.py
starting server ...
accepted from 127.0.0.1:59992
received: b'\x00\x00\x03\xe8\x00\x00\x07\xd0'
operand1: 1000, operand2: 2000
result: 3000
sent: b'\x00\x00\x00\x00\x00\x00\x0b\xb8'
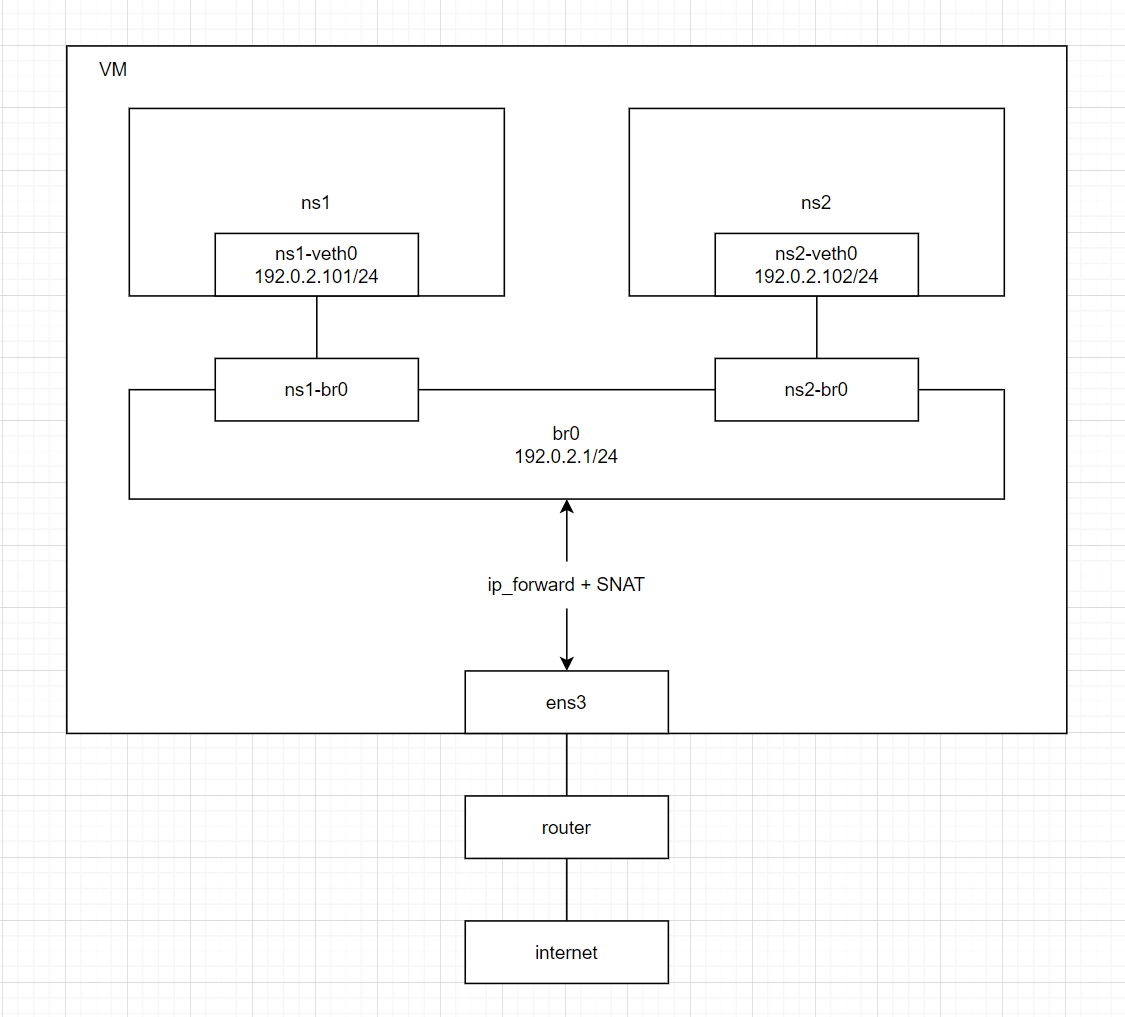
【発展】ブリッジを経由してインターネットに接続する
IPフォワーディング・SourceNATを利用して、nsからホスト側に作成されたブリッジを経由してインターネットと接続します。
物理構成
実装
# nsの全削除
sudo ip --all netns delete
# nsの作成
sudo ip netns add ns1
sudo ip netns add ns2
# vethの作成
sudo ip link add ns1-veth0 type veth peer name ns1-br0
sudo ip link add ns2-veth0 type veth peer name ns2-br0
# bridgeとnsを接続
sudo ip link set ns1-veth0 netns ns1
sudo ip link set ns2-veth0 netns ns2
# vethのup
sudo ip netns exec ns1 ip link set ns1-veth0 up
sudo ip netns exec ns2 ip link set ns2-veth0 up
sudo ip link set ns1-br0 up
sudo ip link set ns2-br0 up
# ipアドレス設定
sudo ip netns exec ns1 ip address add 192.0.2.101/24 dev ns1-veth0
sudo ip netns exec ns2 ip address add 192.0.2.102/24 dev ns2-veth0
# ルーティング設定
# ns1のデフォルトルートにbr0を設定
sudo ip netns exec ns1 ip route add default via 192.0.2.1
# ns2のデフォルトルートにbr0を設定
sudo ip netns exec ns2 ip route add default via 192.0.2.1
# MACアドレスの設定 (なくても良い)
sudo ip netns exec ns1 ip link set dev ns1-veth0 address 00:00:5E:00:53:01
sudo ip netns exec ns2 ip link set dev ns2-veth0 address 00:00:5E:00:53:02
# bridgeの作成
sudo ip link add dev br0 type bridge
# bridgeをup
sudo ip link set br0 up
# bridgeにvethを接続
sudo ip link set ns1-br0 master br0
sudo ip link set ns2-br0 master br0
# bridgeにIPアドレスを設定
sudo ip addr add 192.0.2.1/24 dev br0
# ip_forwardを許可
sudo sysctl net.ipv4.ip_forward=1
# Source NAT (192.0.2.0/24からens3を通って外部に出る通信)
# -A 指定のチェインに新しいルールを指定。
# POSTROUTINGはルーティングが終わってパケットがインターフェースから出ていく直前
# -s 処理対象となる送信元IPアドレスの範囲
# -o 処理対象とする出力先のネットワークインターフェース
# -j 条件に一致したパケットをどのように処理するか。
# MASQUERADEはパケットに適用するターゲットがSource Natであることを示す
sudo iptables -t nat \
-A POSTROUTING \
-s 192.0.2.0/24 \
-o ens3 \
-j MASQUERADE
疎通確認
# ns1 -> ns2
sudo ip netns exec ns1 ping -c 3 192.0.2.102 -I 192.0.2.101
# ns1 -> bridge
sudo ip netns exec ns1 ping -c 3 192.0.2.1 -I 192.0.2.101
# ns1 -> internet
sudo ip netns exec ns1 ping -c 3 8.8.8.8 -I 192.0.2.101
パケットキャプチャ
# ns1-veth0の監視
$ sudo ip netns exec ns1 tcpdump -tnl -i ns1-veth0 icmp
# br0の監視
$ sudo tcpdump -tnl -i br0 icmp
# ens3の監視
$ sudo tcpdump -tnl -i ens3 icmp
pingの送信
$ sudo ip netns exec ns1 ping -c 1 8.8.8.8 -I 192.0.2.101
PING 8.8.8.8 (8.8.8.8) from 192.0.2.101 : 56(84) bytes of data.
64 bytes from 8.8.8.8: icmp_seq=1 ttl=114 time=6.58 ms
--- 8.8.8.8 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 6.580/6.580/6.580/0.000 ms
「行き」のパケットの送信元IPはens3で 192.0.2.101 から 10.194.185.50 に書き換えられていることが確認できます。
「帰り」のパケットの送信先IPはbr0で 10.194.185.50 から 192.0.2.101 に書き換えられていることが確認できます。
# ns1-veth0の監視
$ sudo ip netns exec ns1 tcpdump -tnl -i ns1-veth0 icmp
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on ns1-veth0, link-type EN10MB (Ethernet), capture size 262144 bytes
IP 192.0.2.101 > 8.8.8.8: ICMP echo request, id 57472, seq 1, length 64
IP 8.8.8.8 > 192.0.2.101: ICMP echo reply, id 57472, seq 1, length 64
# br0の監視
$ sudo tcpdump -tnl -i br0 icmp
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on br0, link-type EN10MB (Ethernet), capture size 262144 bytes
IP 192.0.2.101 > 8.8.8.8: ICMP echo request, id 57472, seq 1, length 64
IP 8.8.8.8 > 192.0.2.101: ICMP echo reply, id 57472, seq 1, length 64
# ens3の監視
$ sudo tcpdump -tnl -i ens3 icmp
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on ens3, link-type EN10MB (Ethernet), capture size 262144 bytes
IP 10.194.185.50 > 8.8.8.8: ICMP echo request, id 57472, seq 1, length 64
IP 8.8.8.8 > 10.194.185.50: ICMP echo reply, id 57472, seq 1, length 64
削除
# nsの全削除
sudo ip --all netns delete
# ブリッジ削除
sudo ip link del dev br0